
Chapter 11. Service Composition with Java

11.1 Inside Service Compositions
11.2 Java Service Composition Design and Implementation
11.3 Service and Service Composition Performance Guidelines
Decomposing a system into units of service-oriented logic and recomposing the units into new compounds of solution logic results in a higher degree of code reuse and greater flexibility in response to change. This chapter acts as a continuation of Chapter 10 to focus on the design and implementation considerations specific to service composition with Java.
11.1 Inside Service Compositions
The following sections highlight key service composition terms and concepts in preparation for the Java Service Composition Design and Implementation section.
Service Composition Roles
A service invoked as part of a composition is a composition member, and a service that invokes other services as part of its processing is a composition controller. A service should ideally be a member of and built for more than one composition. As per the Service Composability principle, a service’s composability is not an explicit design step or implementation detail but a manifestation of the extent to which service-orientation principles were applied during design, such as how reusable and autonomous the service is and whether or not it deals with standardized data types.
The composition controller sits on top of and invokes composition members in a defined sequence. Therefore, the composition controller must be aware of the context around individual service invocations, and may have to store state across invocations as well as provide transactional and/or security context. The composition members must be fully decoupled from the controller’s service consumers, because the fact that a service composes other services must be hidden from service consumers, as per the Service Abstraction principle.
Within the composition logic, the controller must determine which protocol to use when synchronously or asynchronously invoking a composition member. Both the composition controller and member implemented in Java can be deployed into the same process, in which case service invocation becomes a local Java call. Beyond the composition controller and composition member, two additional roles are relevant to service composition:
• A composition initiator is the service consumer that triggers the execution of the composition.
• A composition sub-controller is a service that acts as a composition member but also delegates some or all of the processing to other services. This second composition becomes a sub-composition.
See Figure 11.1 for a visual illustration of a service composition hierarchy that includes a sub-controller.

Figure 11.1 A service composition encompasses a composition controller and a composition sub-controller.
An entire chain of service compositions is possible, such as service sub-controllers invoking other service sub-controllers. However, the depth to which this can be done is often constrained by performance and other non-functional requirements.
Compositions and MEPs
The interaction between two services often involves using a message exchange pattern (MEP). MEPs describe whether an interaction occurs synchronously or asynchronously or in the form of a request/response sequence. Individual MEPs are often limited to point-to-point interactions between a service consumer and a service.
In a given service composition, several different MEPs can exist. For example, if Service A invokes Service B as part of a composition, where Service A is the composition controller and Service B is a composition member, Service B can then invoke Services C and D, which makes Service B a composition sub-controller. The interactions between A and B and between B and C and D may use different MEPs, as shown in Figure 11.2.
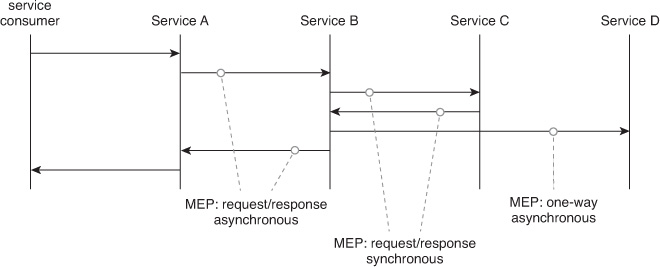
Figure 11.2 An invocation of Service A leads to the usage of several message exchange patterns within the service composition.
Messages that are part of such a service composition must be correlated somehow to identify which instance of a composition corresponds to each message. Differentiating messages from the composition instances is often a challenge when asynchronous messaging is used.
Synchronous and Asynchronous Invocation
Services often separate their functional interface from the network invocation or binding, as is common for Web services in particular. While the functional interface may support what is needed for the composition, careful analysis of the supported binding is required.
Some services may only support an asynchronous invocation, which means that the request message is sent on a different thread than where the response message is received. The response message must be correlated with the request message, which often happens via a unique message identifier copied into the header of each message. Each participant in the asynchronous exchange agrees on the chosen mechanism. The invoked service copies the message ID of the incoming request message into the header of the outgoing response message.
The composition controller does not have to wait for the request to be processed by the composition member. Utilizing asynchronous invocation allows the composition controller to do other work in parallel until the response arrives. This can be useful in cases where several composition members are invoked simultaneously, because they perform work that does not require sequential execution.
For example, a task service is part of an order management system that offers a promised completion date for a new order based on availability of material in a number of warehouses. Each warehouse exposes a set of entity services that return that quantity of a certain material that is currently in stock. To calculate a completion date, the task service can send parallel requests to each warehouse for each of the required materials and collect all responses before running its calculation. Requests to each warehouse can be sent without waiting for the response, which improves the performance of the overall service. If offered by the warehouse services with the applicable correlation mechanism, the asynchronous invocation protocol is an appropriate design choice.
Service Level Agreements (SLAs)
A composition controller’s SLA is dependent on its composition members’ SLAs. Any scheduled downtime of a composed service is also a scheduled downtime for the entire composition. Therefore, the SLA offered by the composition controller service is constrained by the SLAs of the composition members.
An existing service may be unsuitable in a composition because of incompatible SLAs, even though its functional interface meets the requirements. For example, if a service’s minimum response time is longer than the minimum response time for the overall composition, than this service cannot be reused. Either a different service that offers better performance must be found, or the candidate service’s owner can be pushed to improve its response time to the required level.
Some business-centric services may be need to be auditable down to individual messages, which means that no message can be lost during processing. If a potential composition member service can only be accessed over HTTP as the network protocol, messages can be lost, since HTTP is not a reliable transport. Therefore, various techniques can be applied to achieve different levels of reliability.
Service implementations based on SOAP and WS-* can benefit from the WS-ReliableMessaging standard to ensure reliable delivery of messages with various degrees of QoS support, such as at-most-once, at-least-once, exactly-once, or in-order delivery. REST services can resubmit a message until successful acknowledgement is received, which requires the message recipient to be capable of handling duplicate messages.
The weakest composition member defines the minimum support offered by the composition as a whole. The composition controller’s SLA can be defined as the sum of all composition member SLAs. Note that this does not mean that all response times of composition member services are added together to calculate the expected response time of the composition. Remember that asynchronous, parallel invocations of services can shorten the processing time. To create the SLA for the composition, thoroughly examine the impact each composition member SLA will have individually, taking into consideration how each service’s composed capability is invoked.
11.2 Java Service Composition Design and Implementation
Service composition not only affects the overall runtime behavior of a particular service, but also the implementing, packaging, deploying, and testing of composed services. The following sections highlight a number of considerations and challenges.
Composition Logic: Coding vs. Orchestration
Hand-coding service composition logic is common with task services. It provides a low barrier to entry; however, the long-term costs for complex service compositions can be high and pose the following challenges:
• A tight coupling is created between the composition controller and the composition members. Even minor changes to the invocation sequence results in a need to re-program the composing service.
• The composing service implementation can become highly complex. For example, if the task service must perform parallel queries or updates or asynchronous invocations, it may need to manage all the threading and/or parallel messaging itself. For long-running service compositions, programmatic composition logic may need to include routines for canceling service invocations, managing long-running conversational state, and performing conditional joins on parallel execution sequences.
• For complex transactional services, programmatic management of transactional integrity between various composition members may introduce additional complexity.
An alternative to hand-coding is to consider orchestration via the use of standards like WS-BPEL, which typically lead to the creation of orchestrated task services. With WS-BPEL, the sequence of interactions can be modified by making changes to the WS-BPEL flow rather than to the actual implementation code. The decision as to whether to incorporate orchestrated task services into service composition design is often dependent on the complexity and potential execution duration of service composition instances and service activities.
Note
This book does not cover orchestration in detail or the use of any high-level declarative language for the expression of service composition logic.
REST Service Composition Considerations
In a REST service composition, the composition controller coordinates the actions of various member resources. New resources may be created, and existing resources may be updated or removed. This dynamic nature of the service composition results in potential changes to the member resources and their resource URIs.
The uniform contract constraint still applies to all member resources. The interaction between the composition controller and member resources will be restricted to the well-known HTTP verbs and/or a subset of those verbs as permitted by the resources themselves. The REST-style architecture characteristics also apply for all composition members. Each composition member will have its own media types (standard or custom), resource URIs that identifies the resources, and resource representations that may explicitly outline allowable resource transitions from a given resource state as per the hypermedia constraint.
For programmatic REST services, composition controllers have a choice of using various low-level HTTP-based Java APIs, such as the HTTPURLConnection or Apache HttpClient classes. However, the HTTP-based Java APIs do not deal with resources as an abstraction and have an RPC-centric focus based on request/response messages, which limits the usefulness of these APIs for building REST service consumers. Alternatively, the JAX-RS 2.0 Client API offers a set of Java APIs for communication with REST services irrespective of whether those services are implemented with the JAX-RS. The Client APIs provide resource-based abstractions and a more natural programming model centered on resources, URIs, and the uniform contract constraint. The JAX-RS client APIs can consume any Web service exposed over an HTTP protocol.
Under the covers, the client API implementation can use any low-level HTTP communication libraries. For example, the Jersey implementation provides a pluggable architecture where the application developer is free to choose any one of a number of different Java-based HTTP library implementations, such as JDK HTTPURLConnection or the Apache HTTPClient utilities. The JAX-RS 2.0 client programming model can be utilized to build REST service consumers, including composition controllers. With the JAX-RS client programming model, the central entity is a resource. The resource is modeled as a javax.ws.rs.WebTarget class that encapsulates a URI. The WebTarget resource class supports the fixed set of HTTP methods, and resource representations are modeled as Java types that may contain link relations to other WebTarget resources.
The starting point for coding a REST service consumer with JAX-RS is the javax.ws.rs.client.Client interface. A request is created based on the target, and the invocation is performed on the request as seen in Example 11.1.
Client c = ClientBuilder.newClient();
WebTarget order = c.target("http://com.soaj.restful/resources/order");
WebTarget invoice = c.target("http://com.soaj.restful/resources/
invoice");
...
The request method on the WebTarget interface allows media-type specification for the request, and returns an Invocation.Builder object in Example 11.2.
Invocation.Builder builder = order.request(MediaType.TEXT_PLAIN);
Invocation.Builder builder2 = invoice.request(MediaType.
APPLICATION_XML);
The Invocation.Builder object supports the HTTP methods. After the Media type is set, the request is invoked by calling the HTTP methods seen in Example 11.3.
String response = builder.get(String.class);
...
Invoice inv = new Invoice(); //Invoice is a JAXB bean
//call POST passing in the serialized inv via javax.ws.rs.client.
Entity
String conirmationNumber = builder2.post(Entity.xml(inv), String.
class);
A POST is made to the WebTarget that accepts a media type of application/xml. In this case, the POST method takes an unmarshaled JAXB Invoice object. The implementation is flexible in handling different media types, and built-in content handlers manage the translation of media types and their Java counterparts.
The HTTP methods can be chained together to allow a fluent API style of programming where the sequence of calls from Example 11.3 can be replaced, as seen in Example 11.4.
String response = order.request(MediaType.TEXT_PLAIN).get(String.
class);
Note
For a more detailed exploration of REST service composition, read the following three chapters in the SOA with REST: Principles, Patterns & Constraints for Building Enterprise Solutions with REST series title:
• Chapter 11: Fundamental Service Composition with REST
• Chapter 12: Advanced Service Composition with REST
• Chapter 13: Service Composition with REST Case Study
Composition Member Endpoints
For SOAP-based Web services, tooling is used to generate some form of code artifact that acts as a local representation of the remote service. For example, JAX-WS employs the wsimport tool to generate a client-side SEI, which is of type javax.xml.ws.Service. This class can be invoked like any other local Java class, and works with the underlying JAX-WS runtime to create an appropriate wire message to send out over the network.
A JAX-WS client-side proxy is usually obtained by calling one of the Service.getPort() methods defined in the generated SEI. The endpoint address of the used port is derived from the WSDL for the target service, and the location of this WSDL can be dynamically set. A default WSDL location is created when the code is first generated. The location of the WSDL and the endpoint address of the target service is either hardcoded in the proxy or set dynamically at runtime.
The resolution of the endpoint address used to invoke a service should be delegated to a registry that can change the endpoint address whenever a service is moved, without recompiling or reinstalling any code or restarting a server. While the resolution of endpoint address is true of any service consumer, extra care must be taken because a composition controller is eventually exposed as a service with potentially numerous service consumers. Composition member services can be invoked many times, and caching the endpoint information avoids having to perform a lookup every time. The exact endpoint used for a composition member depends on the context of the composition controller.
For example, an end user can have gold or silver status with a company that correlates to faster or slower service. A composition controller may have to select endpoints for its composition members based on the identity of the original caller. Most registries allow the endpoint address of a service to be queried based on more information than just the service name, such as information about caller identity. Determining which criteria affects the endpoint selection for composition members is part of the design process of a composition and should be documented accordingly.
For REST services, the composition controller resource can be looked up by service consumers via a well-known entry point or the URI of the controller resource. However, the controller resource must maintain a list of URIs for the composite member resources. A service registry can be used for storing REST service endpoint information, such as resource URIs, and can be used to look up such composition member endpoints. The need to store multiple resource URIs can be mitigated by the hypermedia constraint, where the composition controller can perform dynamic composition by navigating linked resource URIs and their associated link relations.
Error Handling
Each service operation should define the possible fault messages that can occur. A composition controller must decide how to handle errors, both service-generated and infrastructure-based.
Invoking a number of other services can return any fault message defined by these services. The composition controller could copy all of the downstream fault messages into its own service contract and then pass fault messages to its own service consumers unchanged, although this method is not considered good practice. Copying faults into the service contract exposes details about composed services to the service consumer, which may run contrary to the objectives of the Service Abstraction principle.
Infrastructure errors can also cause problems with the invocation, such as when the network is down and a target service cannot be reached. An infrastructure error should not be modeled in the service contract of the target composition member. When a fault message is received from a downstream service invocation or when an infrastructure problem occurs, the composition controller must explicitly catch and transform error messages into the appropriate functional context. Rather than passing error messages through to its service consumers, the composition controller should capture the fact that an error has occurred in a way that makes sense to its own service consumer. Translating the error to the service consumer might include removing technical details of a message that may be appropriate to the service consumer of a utility service but not to the service consumer of a task service.
For SOAP-based Web services, a modeled fault in the wsdl:operation is mapped to a declared exception in the Java service endpoint interface. Any non-modeled errors are often mapped to a javax.xml.ws.WebServiceException, which is a subclass of java.lang.RuntimeException. Both types of errors can be caught by framing the invocation with a try/catch block. The error message can then transform to the appropriate format and throw the new exception type defined in the composition controller’s WSDL.
For REST services, error handling is captured with HTTP response codes. Any REST-based composition member that fails to perform an expected operation should return an appropriate HTTP status code such as 500, which can also “bubble up” from the composition controller. Similar to fault translation for SOAP-based Web services, status code translations may be necessary in situations where the composition controller is unable to look up composition member resources, resulting in a 404 code. Rather than expose an implementation detail to the composite service consumer, the composition controller can choose to return the internal server error 500 status code.
The following case study examples illustrate how NovoBank and SmartCredit approach error handling for their respective services.
Schema Type Reuse
During execution, a composition controller invokes a number of its composition members. With the exception of one-way operations, each composition member returns some data to the controller to calculate the result that the composition controller returns to its service consumer. There are many cases where the returned data can also be viewed as a composition, such as a composition of the members’ response data.
For example, consider a composition member that is a entity service. Following the design and implementation practices for entity services established in Chapter 9, the service offers a business-relevant, shallow representation of the underlying data. A composition controller acts as the implementation for a task service that will later be used within a business process. The message entity exposed in the entity service contract will be useful as it remains unchanged within the context of the business process. Therefore, the service composition has no reason to redefine the respective message entity.
The message entity of one service can be wrapped into a larger message entity that includes data from other composition members. The composition controller aggregates the returned data from its members into one object that it returns to its clients. Reusing data returned unchanged from a composition member allows more efficient code to be written, and reduces the number of defined complex types in the schema. However, direct reuse may not be possible if the composition service interface is already fixed before the composition members are identified. Converter code must then handle the transformation between the data types used in composition members and the data types required for the composition controller.
Reusing composed data types reveals implementation details about a composition to its service consumers, such as the dependencies between the Process Customer Account service and Customer and Account entity services. Any change in the schema of the message entity for either of the entity services affects the service consumers of the task service. The following case study example illustrates how NovoBank manages the unwanted dependencies created in composition.
Web-Based Services vs. Java Components
A Java-based service can generally be used in a variety of ways, all of which have already been described in previous chapters:
• In-Process – as a local Java class
• In-Process – as a stateless session EJB via its local interface
• Cross-Process – as a stateless session EJB via its remote interface (RMI/IIOP)
• Cross-Process – as a Web-based service via its service interface (SOAP or REST)
The choice of which mechanisms should be used in case of a service composition depends on a number of factors, all of which must be assessed during the design of the composition controller.
An in-process invocation is faster than crossing process boundaries or going across a network. When a service composition has non-functional requirements, support for extremely high-request loads, a large number of concurrent service consumers, and/or short response times may only be achievable by invoking composition members locally.
Developing in Java involves one language, which removes the need to create a language-neutral representation of parameters and return values. With Java, the use of a local stateless session EJB uses a local invocation model while taking advantage of the EJB container for instance pooling and transaction.
Locally invoking a service has an additional side effect as parameters locally passed into the service are not copied to new object instances. Instead, parameters are passed by reference, and any manipulation of these instance references affects the Java code within the caller. Call-by-value semantics apply when calling a service remotely, which means that all parameters are copied and any changes to them are invisible to the calling application.
Invoking a composition member via its Java interface creates a tight coupling between the composition controller and composition member that is generally undesirable. The composition controller directly depends on Java artifacts from the composition member implementation, specifically on its Java interface and any related classes and interfaces. Any change in these artifacts can require a complete recompile of the composition controller implementation. The direct invocation model makes rerouting the request/response message to insert additional processing for logging and auditing impossible.
Whether or not a Java interface is utilized instead of a Web service interface is a choice made based on non-functional requirements such as performance, and the necessity to support key service-orientation principles, such as Standardized Service Contract, Service Loose Coupling, and Service Abstraction, as well as associated design standards. Therefore, when considering the use of native Java interfaces, it is important to also consider the application of the Dual Protocols pattern to ensure that standardized access and communication are also supported within the service inventory.
Either way, it may be beneficial to implement the service logic within a stateless session EJB to add support for transactions, security, and other functionality offered by the Java EE application server environment. Employing an EJB to manage infrastructure-level functionality allows the developer to focus on implementing the business logic for the service.
Installing the service implementation logic on an application server achieves scalability of the service once its usage increases. Application servers can be clustered to offer load-balancing capabilities to spread client load across multiple instances of the same server, and expose several copies of the same service to service consumers. A Java EE application server has the ability to redirect service consumer requests from one server instance to another if a particular instance, or the server it runs on, is unavailable. Highly available services can remain active even in case of server hardware problems.
Packaging, Testing and Deploying Composed Services
How a composition is packaged and installed into a runtime environment depends on how the composition members are invoked. If the composition members are invoked via a SOAP-based Web service interface, then the appropriate client-side artifacts should be generated from the service contract. An example is how the WSDL is generated via the wsimport tool. For REST services, the absence of a machine-readable service contract means there are no artifacts to be generated.
Even if the service invoked is developed in Java, never reuse any of the code or generated service interfaces directly from the service implementation. The client-side artifacts should all be generated for a particular service consumer, such as the composition controller, and packaged with its service implementation. Reusing code creates a level of coupling and dependency that should be avoided.
For SOAP-based Web services, the wsimport tool generates the Java service interface, JAXB-based classes representing the schema types referenced in the WSDL, and a number of other utility classes that depend on the exact JAX-WS implementation used. All of these artifacts can be packaged in a single utility JAR file and added to the classpath for development of the composition controller. Each composition member is represented by one JAR file. For final packaging, the utility JAR files can be added to the EAR file containing the entire composition implementation.
For REST services, the resource classes can be packaged inside a regular Web application WAR file. The JAX-RS implementation often provides a servlet or filter, such as in Jersey, that intercepts HTTP requests, performs request redirection to the JAX-RS resources, maps the HTTP methods to resource methods, and marshals/unmarshals resource method parameters to and from content in the HTTP request/response messages. The JAX-RS implementation servlet or filter is declared in the Web application’s web.xml file.
Case Study Example
• Customer Entity Service
• Account Entity Service
• E-Mail Utility Service
• GenericLogger Utility Service

Figure 11.3 The ProcessCustomerAccount EAR file structure includes individual JAR files for each of the composition members.
When a composition member is invoked using a Java call, either the entire composition member implementation can be packaged for local invocation, or the pieces required for a remote invocation can be selectively packaged. For example, a target composition member is invoked using the remote EJB interface and the appropriate client package containing all required artifacts packaged with the composition controller must be generated. Artifacts can be packed separately in a utility JAR file to avoid cluttering the code. References must be generated to the target EJB invoked in the composition’s deployment descriptor or as annotations in the code. Packaging code artifacts that belong to different services into different JAR files keeps the services as separate as possible.
The techniques of creating local stubs for task services discussed in Chapter 10 equally apply to the composition members when testing a service composition. The composition controller code can be tested without requiring the invoked services to be available or even exist. Difficulties in tracking where and what has caused errors occur often when testing a distributed system, such as a service composition with many members. A transactional view of the system can help manage errors by adding trace points to the code that track the original request that was carried out when the trace information was written.
Traced messages must carry information that allows them to be properly correlated. The original request message often contains data forwarded to each composition member that can serve as the correlating element. For example, a customer ID is passed to a service composition for the invocation of each composition member, and all trace messages with the same customer ID belong to the same original request.
In cases where a correlating parameter does not exist, a message ID can be added to each message. The message ID is generated once in the composition controller and then passed with every message to each composition member. The creation and handling of the message ID should be delegated either to underlying middleware or to a separate component, such as an enterprise service bus.
For example, the JAX-WS defines the concept of handlers, which are invoked before a message is sent out and right after a message was received. Handlers enable the insertion and processing of message IDs to allow correlation of messages that belong to the same original transaction. Similarly, the JAX-RS implementations offer constructs called filters, which are inserted in the request/response chain and can be utilized to communicate such contextual information.
Test performance as early as possible, especially for service compositions, when the composition members are deployed in the same way as in the production environment. Early performance testing can reveal further changes to the way services are implemented and/or deployed, solely based on non-functional characteristics like response time or message throughput.
Additional performance for service compositions can be achieved via regular tuning of both the code and the environment that it runs in. In some cases, an invocation of a remote Web service that normally results in a call being made over the network can be served from a local cache to avoid the remote call altogether by applying advanced caching mechanisms.
11.3 Service and Service Composition Performance Guidelines
Previous sections have already touched upon various performance-related considerations. This remaining section highlights a number of further guidelines that are applicable to services acting as composition controllers or composition members.
Measuring Performance
When assessing the performance of a service composition, it is helpful to establish a set of baseline metrics that can be individually measured for each service, as well as collectively for the composition controller, on behalf of an entire service composition. The following are examples of common metrics that address runtime performance as well as reliability:
• Response Time – A service’s response time is a measure of how quickly a response is returned to the caller. Stakeholders often outline their response expectations in the form of an SLA that states what the mean service response time or a percentile response time should be, such as “80% of the service invocations should return in less than three seconds.” The service should maintain its desired level of SLAs when the system is under maximum expected load. The desired response times are commonly stated in the context of a peak concurrent load, such as “a service must return results within three seconds or less with 600 peak concurrent users using the system.”
• Throughput – A service’s throughput is the possible number of service requests served in a given time as expressed in units, such as a number of messages or service invocations in a given time interval. The SLA guarantees related to throughput may be expressed in terms of the system needing to support a specific number of service invocations in a given time window, such as 10,000 service invocations in one hour.
• Resource Utilization – An operational service consumes a certain amount of resources, such as memory, at the system level, or resources associated with managed environments like application servers, such as JVM threads, database connections, JVM heap memory, or a number of managed objects in a pool. Well-performing services exhibit a stable pattern of resource usage under expected load conditions. A stable pattern does not imply the resource consumption stays constant at a certain level, but indicates the trend does not fluctuate wildly under varying loads. Fluctuations in resource consumption could indicate instabilities within services or the system.
• Capacity – A service’s capacity measures the maximum levels of load services can maintain. An in-depth capacity assessment measures how a service degrades in performance with increasing load. A well-designed and tuned service would experience gradual degradation in performance when load is increased beyond its projected capacity, but a sub-optimal service might experience severe degradation with temporary spikes in load beyond its expected capacity. Capacity planning tests are an important component of an overall scalability and performance testing initiative.
• Availability – Service availability means the percentage of time a service is available in a year. For example, an availability of five nines indicates the service is available 99.999% of the time during a year, which translates to approximately 5.26 minutes of downtime throughout the year. It is important to avoid guaranteeing the “four nines” (99.99% or 52.56 minutes of downtime) or the “three nines” (99.9% or 8.76 hours of downtime) of service availability before determining the realistic availability requirements of a service composing others.
Testing Performance
Various types of testing are carried out to measure the performance and scalability characteristics of services and service compositions. In this section we highlight considerations specific to load testing, stress testing, and soak testing methods.
Performance testing measures different aspects of system behavior that can be corrected or tuned for optimization. Load testing of services is carried out during routine performance testing to simulate load on services and measure performance and stability characteristics. Gradually increasing the load determines how well the services and system comply with the SLAs as the load increases. Workload characterization is also considered during load testing. Workload characterization determines a realistic mix of service invocations.
For example, the peak operational hours in a typical retail banking IT system might experience a mix of 40% customer account inquiry, 30% debits, credits, and transfers, and 30% miscellaneous CRM operations. Before performing load tests, an appropriate workload characterization should be determined, and the load test profile should accurately reflect the workload seen in production. The performance SLAs of services must be captured in the same context, such as 90% of the customer account inquiry service invocations should return in no less than 3 seconds when the system is being used by 600 concurrent users (peak load), and the workload consists of 40% account inquiries, 30% update transactions, and 30% CRM services.
Stress testing ascertains what the breaking point of a service is, and how well the service behaves near the breaking point. Continuing to increase load on a system increases the response time and/or decreases the throughput. However, a buckle point occurs when the performance suffers a dramatic degradation to the point of rendering the system unusable. The operational goal is to ensure the system operates well below this buckle point, and can scale to meet the projected demand. Stress testing is documented in the service SLAs with a clear statement of the load limits the service can withstand and maintain acceptable performance.
Soak testing tracks the resource utilization patterns of services by subjecting them to normal load for extended durations, such as days and months. The system or services often exhibit resource leaks where used resources, such as memory, database connections, file handles, or open sockets, are not reclaimed or cleaned in a timely manner that can lead to the eventual starvation of resources. Systems can exhibit slow but gradual degradation of performance under normal load over days or weeks.
Caching
Caching is an implementation technique to store service computation results in some form of volatile storage for return when the same information is requested. However, caching is also a significant architectural decision for performance-sensitive parts of the system. Stringent response time SLA requirements may be adversely affected by expensive processing, I/O latency, and excessive network round trips.
Caching unchanged or infrequently changed data spares the effort of repeatedly retrieving the same data from the source system, such as a database or ERP system. Reference data, such as country or currency codes, are commonly cached in read-only caches. To avoid a single point of failure and improve system availability, caches are often distributed across physical nodes. Keeping all copies of the caches in sync can be challenging.
Periodic cache refresh and notification techniques for cache invalidation can help maintain cache consistency across multiple cache nodes. However, building such caching utilities in-house is expensive and error-prone. Instead, open-source frameworks, such as Memcached, provide a distributed, in-memory object cache. Service implementations can use Memcached APIs to store and retrieve read-mostly objects from a distributed cache.
Data Grids
Implementing a distributed read-write cache for frequently updated data is a challenge in software engineering compounded by the emergence of extreme transaction processing (XTP). Applications, such as realtime trading systems, generating large volumes of transactions, often encounter I/O bottlenecks because of excessive database reads/writes and the associated network and I/O costs. Besides high performance and scalability requirements, maintaining high levels of system availability are critical for such demanding services. In response, architectural patterns and software products have emerged that are collectively referred to as in-memory data grids.
An in-memory data grid provides a distributed read-write cache, and can effectively serve as the logical persistence layer for services to interact with the data grid to cache data. The data grid is responsible for synchronizing the data held in-memory with the persistence store, which can be a relational database, an ERP system, or any EIS system that provides integration APIs. The data grids write to the database or utilize the integration APIs to flush the data to the system in a synchronous (write-through) or asynchronous (write-behind) fashion.
The write-through approach has error handling and transaction rollback characteristics, in which cache updates can roll back in the event of a failure to write to the underlying store. If all the writes to the data in the persistent store are performed through the cache, the data in the cache will stay current. However, if persistent store data writes are performed through other channels, then the cache must refresh either periodically or by notification in the event of data updates happening via other mechanisms. Most data grid products allow registering notification listeners with persistent stores or back-end systems that can receive update event notifications and refresh the cache.
For services, implementations can plug into an in-memory data grid for data reads and writes offering better response times, scalability, and availability through a distributed set of nodes known as a cluster. The services and the service consumers can continue to function despite outages in the persistence layer. The data grid acts as the virtual persistence layer, which holds the information in memory across a cluster of nodes, receives updates, flushes, and synchronizes the data when the systems of record are brought back online.
Added complexity in the implementation results in managing what could be hundreds of cache nodes. The service implementations may require extensive use of proprietary data grid APIs. Careful design is necessary to keep the service business logic separate from the cache access code. The operations team should be trained in the administration and maintenance of data grids.
In-memory grids are not a replacement for disk-based transactional data systems such as databases, as the information is not persisted to disk or provided the same levels of transactional capabilities as relational databases. When performing multiple updates across different databases, a transaction management infrastructure and databases are required to handle data consistency and integrity issues.
REST Caching
Rather than requiring a service to use a caching library, the constraints of REST have promoted caching to an architectural construct. For example, the World Wide Web scaled because HTTP caching features have been successfully exploited by browsers, Web agents, proxy servers, and content delivery networks (CDN). Browsers cache Web content. Proxy servers and CDNs sit between and allow the content services and service consumers to intercept requests and provide content from their cache, rather than returning to the original server for the content. Proxy servers can perform the same role with REST services if the services are designed appropriately.
GET and HEAD requests are safe and idempotent, and make ideal candidates for caching the invocation results. The HTTP caching semantics provide fine-grained caching behavior that allows service designers to specify who is allowed to cache the results, how long a cache can remain valid, and what type of cache revalidation mechanism can be used. The HTTP 1.1 Cache-Control header specifies a number of directives that determine the exact caching behavior.
Some of the important directives include:
• public – Any entity in the request/response chain is allowed to cache the results, which allows proxy servers and CDNs to cache the results of a GET or HEAD invocation.
• no-cache – This directive indicates the response should not be cached.
• max-age – This directive determines the duration of the cache validity.
• must-revalidate – When this directive is present in the response, the cache must not use the entry after it becomes stale. Subsequent requests should be revalidated with the origin server.
A sample HTTP response with a cache-control directive is seen in Example 11.18.
HTTP/1.1 200 OK
Content-Type: application/xml
Cache-Control: public, max-age=600, must-revalidate
<Customer>
...
</Customer>
The Cache-Control directive indicates the response can be cached by any intermediaries for ten-minute durations.
REST services can also support cache revalidation, which is often seen with conditional GETs. The service returns an ETag header that acts as a unique fingerprint of the response at a given time. The service caller is expected to store the ETag value, and can conditionally request cache revalidation by sending an If-None-Match header in a subsequent GET request that carries the stored ETag value. If the service has a fresher value of the cache, it will detect that the value in the If-None-Match request header does not match the latest ETag value and respond with a 200 OK response with the new response and latest ETag value. If the content has not changed, the service returns a 304 'Not Modified' response, and the client can continue to use the cached result.
A typical cache exchange is illustrated in Example 11.19.
GET /customers/1234 HTTP/1.1
...
HTTP/1.1 200 OK
Content-Type: application/xml
Cache-Control: public, max-age=600
ETag: 123456789
<Customer>
...
</Customer>
If the client issues a request within ten minutes, an intermediary, such as a proxy server, can return a cached result without going back to the origin server. After ten minutes, the client issues a conditional GET request, as seen in Example 11.20.
GET /customers/1234 HTTP/1.1
If-None-Match: "123456789"
And receives a modified response:
HTTP/1.1 200 OK
Content-Type: application/xml
Cache-Control: public, max-age=600
ETag: 785634892
<Customer>
<!—a modified customer -->
</Customer>
The response header Last-Modified and the request header If-Modified-Since serve similar revalidation purposes to ETag and If-None-Match. Exploring caching possibilities in a REST service design should be undertaken before the implementation phase. APIs, such as the JAX-RS, provide support for implementing caching constructs.
Scaling Out Services with State
A stateless service can be deployed across multiple nodes. Requests to the services can be load balanced across the server farm. Some stateful services can still support a scale-out model by employing the State Repository pattern that assigns state management responsibilities to a dedicated storage, such as a database or file system. Such types of services refresh their state from the storage on every service request, which avoids storing state in memory and allows service requests to be appropriately load balanced.
Other types of stateful services, such as utility services, may need to maintain state information in memory, as per the Stateful Service pattern. In the absence of a centralized state repository, it becomes important to associate a service consumer with a specific service with the latest state information to ensure continuity of the conversational context. This “sticky” association breaks the load-balancing model, and has a negative effect on scalability.
The “sticky” association model introduces a single point of failure where an outage of the node hosting the stateful service results in a loss of availability. Infrastructure vendors mitigate this effect by introducing in-memory session replication where the state information held in memory is replicated to a secondary node. The secondary node acts as a backup when the primary node goes offline. However, in a typical application server deployment, this affects overall performance from replicating state changes across nodes that requires expensive broadcast message communications between nodes.
If there is a need to host large numbers of stateful services, consider the efficient support for maintaining cache consistencies offered by specialized solutions, such as in-memory data grids.
Handling Failures
Services may fail at multiple points in a service invocation, which complicates failure handling. A service invocation can fail in the middle of the call or network failures between the caller and the service could leave the service consumer uncertain of whether the request was serviced or not. The call may have successfully processed, but the network might have had an outage before the results were returned to the caller.
The caller often cannot resubmit a request in the event of failure without undesirable side effects, such as processing a payment multiple times. Idempotency ensures invoking a service multiple times has the same effect as invoking it once, and service safety ensures no side effects occur even when a service is invoked multiple times. Safe methods, such as HTTP GETs, are appropriate candidates for request resubmission in the event of failures, but idempotent services may not be side effect-free. To prevent the side effects from being triggered multiple times, refrain from resubmitting a request to a non-idempotent service.
Recovery is a key consideration of failure handling. How does a service recover from a failure in the middle of a transactional update? Many business services update multiple transactional systems, such as databases, messaging systems, and third party-packaged applications. In such situations, a call may only have made partial updates before failing, and may compromise the system integrity in the absence of a transaction recovery infrastructure.
Implementing a distributed transaction recovery protocol is provided by infrastructure vendors. Without requiring assistance from the developer, transactional integrity is managed by sophisticated, distributed, transaction recovery mechanisms, such as XA. Popular distributed transaction management protocols are designed to handle failures. However, XA recovery adversely affects performance by requiring extensive checkpoint-based logging.
When an application server is responsible for managing transactional integrity for components, such as EJBs, the container starts and manages a distributed transaction that can involve multiple data sources. For a full XA recovery, all participants in the distributed transaction must support XA and offer an XA-based adapter, such as an XA-aware JDBC driver. Various XA optimizations offer a relaxed recovery protocol, which is still open to small windows of failure, for a less expensive transaction. However, distributed transaction recovery using a protocol, such as XA, involves locking resources. This is inadvisable and often impossible in a large, distributed environment without control over all systems.
Some advanced Web services standards, such as WS-AtomicTransaction, mimic XA recovery, but compensation-based approaches where undo actions are used to roll back failed updates offer a more scalable option. Manual reconciliations can also manage failures and recovery when the alternatives prove unsuitable.
Parsing and Marshaling
This section considers different aspects of message parsing and marshaling/unmarshaling to illustrate how special handling can alleviate major performance problems in many situations, such as large message sizes, XML to Java marshaling and unmarshaling, and XML parsing.
Messages must often carry binary data, such as images, that can be substantial in size. A common practice is to Base64-encode the binary content and embed it in the message body, but this can result in poor performance as text-based serialization of binary data contributes an additional size bloat. The parser must perform unnecessary work to parse the entire payload, including the Base64-encoded content.
Instead, MTOM for SOAP-based Web services can be considered as a means of attaching binary data in a multipart MIME message. Attaching the binary data eliminates the size bloat and parsing overhead. Opaque data not requiring parsing or validation can be passed as attachments often in a compressed form. REST-style services can use MIME messages and attachments. The JAX-RS Jersey implementation facilitates construction and parsing of multipart messages. The JAX-RS implementation Jersey APIs help build multipart messages and submit them to the service. Example 11.21 uses Jersey 2.5.1 APIs for multipart support.
import javax.ws.rs.client.*;
import javax.ws.rs.client.WebTarget;
import org.glassfish.jersey.media.multipart.BodyPart;
import org.glassfish.jersey.media.multipart.MultiPart;
import javax.imageio.ImageIO;
import javax.ws.rs.core.MediaType;
import java.awt.image.BufferedImage;
import java.io.ByteArrayOutputStream;
import java.net.URL;
public class MultipartClient {
public static void main(String[] args) throws Exception {
...//construct a claim JAXB object
Claim cl = new Claim();
cl.setType("CarInsurance");
cl.setDescription("Accident claim");
//other properties of claim...
ByteArrayOutputStream bas = new ByteArrayOutputStream();
URL url = new URL("file:///claims/iamges/accident-image.png");
BufferedImage bi = ImageIO.read(url);
ImageIO.write(bi, "png", bas);
byte[] img = bas.toByteArray();
// Construct a MultiPart with two body parts
MultiPart multiPartEntity = new MultiPart().
bodyPart(new BodyPart(cl, MediaType.APPLICATION_XML_TYPE)).
bodyPart(new BodyPart(img, MediaType.
APPLICATION_OCTET_STREAM_TYPE));
// POST the request
WebTarget target = ClientBuilder.newClient()
.target("http://server/claim");
Response response = target.request().post(Entity.
entity(multiPartEntity, multipartEntity.getMediaType()));
System.out.println("Response Status : " + response.
getEntity(String.class));
}
}
In Example 11.21, the Jersey client multipart classes allow a multipart request to be constructed with a nested XML bodyPart that captures the details of a Claim object and an image of a vehicle. The org.glassfish.jersey.media.multipart.MultiPart class uses Builder to construct a multipart message with a chain of org.glassfish.jersey.media.multipart.BodyPart objects.