
When the application needs performance, you have to choose the right distribution tool. In this example, we will show the differences between publishing a message between a mirrored queue and non-mirrored one.
You can use the source code from the Improving bandwidth recipe, then you have to create a RabbitMQ cluster with two nodes.
A cluster using HA mirrored queues is slower than a single broker. Higher the number of mirroring servers, slower the application will be because the producer can send more messages only after the message being sent is stored to all the mirrors.
Note
That's not as bad as it might seem. On one side, the distribution toward the nodes of the cluster is performed in parallel, so the overhead does not grow linearly with the number of nodes. On the other side, the replication is usually limited to two or three replicas at the most, as we saw in Chapter 7, Developing High-availability Applications.
We performed a test using the following environment:
- https://www.digitalocean.com/ as cloud
- Two Debian machines in a RabbitMQ cluster, as shown in the following screenshot:

- One Debian machine with the same characteristics as the Java client
The tests performed are as follows:
- Test 1: Create a mirror (as we saw in Chapter 7, Developing High-availability Applications) using the configuration, as shown in the following screenshot:
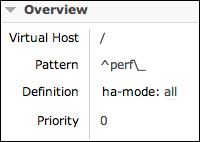
So. the cluster will mirror all queues with the
perf_prefix.The producer is run with the following command:
java -cp rmqAckTest.jar rmqexample.ProducerMain 1 100000 640
The consumer is run with the following command:
java -cp rmqAckTest.jar rmqexample.ConsumerMain 1 0 0 0
The clients exchange messages through the
perf_queue_08/03queue, on which the observed performance is as follows:
- Test 2: We removed the HA policy and tried again. The result, in this case, was similar to the following screenshot:

- Conclusion: By using small-sized messages, we have amplified the differences. For larger messages, they are much less evident. In Test 2, we have observed about 2.000 mgs/s more than Test 1, but as you can see, the rate dropped because the producer is faster than the consumer.
In this example, we have gone to try the highest performance and in this context, we have seen the impact of queue mirroring. If we need a level of replication, but without the strict requirements of mirroring, it is possible to use a shovel plugin or simply publish the message to two independent brokers in parallel. In this example, the messages aren't persistent and don't use the tx-transaction.
Finding the right compromise between performance and reliability is very hard because there are lots of variables inside a distributed application. A typical error is trying to optimize each single application flow losing scalability or eventually high-availability benefits. This chapter presents extreme situations, but as we have seen, there are margins for improvement.
Performance is a hot topic in the RabbitMQ mailing list. You can search and find a lot of useful information in the archives at http://rabbitmq.markmail.org/.