
Chapter 4. The Java Language
This chapter begins our introduction to the Java language syntax. Because readers come to this book with different levels of programming experience, it is difficult to set the right level for all audiences. We have tried to strike a balance between giving a thorough tour with several examples of the language syntax for beginners and providing enough background information so that a more experienced reader can quickly gauge the differences between Java and other languages. Since Java’s syntax is derived from C, we make some comparisons to features of that language, but no prior knowledge of C is necessary. Chapter Chapter 5 will build on this chapter by talking about Java’s object-oriented side and complete the discussion of the core language. Chapter 7 discusses generics, a feature that enhances the way types work in the Java language, allowing you to write certain kinds of classes more flexibly and safely. After that, we dive into the Java APIs and see what we can do with the language. The rest of this book is filled with concise examples that do useful things in a variety of areas. If you are left with any questions after these introductory chapters, we hope they’ll be answered as you look at the code. There is always more to learn, of course! We’ll try to point out other resources along the way that might benefit folks looking to continue their Java journey beyond the topics we cover.
For readers just beginning their programming journey, the web will likely be a constant companion. Many, many sites, Wikipedia article, blog posts, and, well, the entirety of Stack Overflow can help you dig into particular topics or answer small questions that might arise. For example, while this book covers the Java language and how to start writing useful programs with Java and its tools, we don’t cover lower, core components of programming such as algorithms. These programming fundamentals will naturally appear in our discussions and code examples, but you might enjoy a few hyperlink tangents to help cement certain details or fill in gaps we must necessarily leave.
Text Encoding
Java is a language for the Internet. Since the citizens of the Net speak and write in many different human languages, Java must be able to handle a large number of languages as well. One of the ways in which Java supports internationalization is through the Unicode character set. Unicode is a worldwide standard that supports the scripts of most languages.1 The latest version of Java bases its character and string data on the Unicode 6.0 standard, which uses at least two bytes to represent each symbol internally.
Java source code can be written using Unicode and stored in any number of character encodings, ranging from a full binary form to ASCII-encoded Unicode character values. This makes Java a friendly language for non-English-speaking programmers who can use their native language for class, method, and variable names just as they can for the text displayed by the application.
The Java char type and String class natively support Unicode values. Internally, the text is stored using either char[] or byte[]; however, the Java language and APIs make this transparent to you and you will not generally have to think about it. Unicode is also very ASCII-friendly (ASCII is the most common character encoding for English). The first 256 characters are defined to be identical to the first 256 characters in the ISO 8859-1 (Latin-1) character set, so Unicode is effectively backward-compatible with the most common English character sets. Furthermore, one of the most common file encodings for Unicode, called UTF-8, preserves ASCII values in their single byte form. This encoding is used by default in compiled Java class files, so storage remains compact for English text.
Most platforms can’t display all currently defined Unicode characters. As a result, Java programs can be written with special Unicode escape sequences. A Unicode character can be represented with this escape sequence:
uxxxx
xxxx is a sequence of one to four hexadecimal digits. The escape sequence indicates an ASCII-encoded Unicode character. This is also the form Java uses to output (print) Unicode characters in an environment that doesn’t otherwise support them. Java also comes with classes to read and write Unicode character streams in specific encodings, including UTF-8.
As with many long-lived standards in the tech world, Unicode was originally designed with so much extra space that no conceivable character encoding could ever possibly require more than 64K characters. Sigh. Naturally we have sailed past that limit and some UTF-32 encodings are in popular circulation. Most notably, emoji characters scattered throughout messaging apps are encoded beyond the standard range of Unicode characters. (For example, the canonical smiley emoji has the Unicode value 1F600.) Java supports multi-byte UTF-16 escape sequences for such characters. Not every platform that supports Java will support emoji output, but you can fire up jshell to find out if your environment can show emoji characters.

Figure 4-1. Printing emoji in the macOS Terminal app
Be careful about using such characters, though. We had to use a screenshot to make sure you could see the little cuties in jshell running on a Mac. But fire up a Java desktop app on that same system with a JFrame and JLabel like we did in Chapter 3 and you get Figure 4-2.
jshell> import javax.swing.*
jshell> JFrame f = new JFrame("Emoji Test")
f ==> javax.swing.JFrame[frame0,0,23,0x0,invalid,hidden ... tPaneCheckingEnabled=true]
jshell> JLabel l = new JLabel("Hi uD83DuDE00")
l ==> javax.swing.JLabel[,0,0,0x0,invalid,alignmentX=0. ... rticalTextPosition=CENTER]
jshell> f.add(l)
$12 ==> javax.swing.JLabel[,0,0,0x0,invalid,alignmentX= ... rticalTextPosition=CENTER]
jshell> f.setSize(300,200)
jshell> f.setVisible(true)
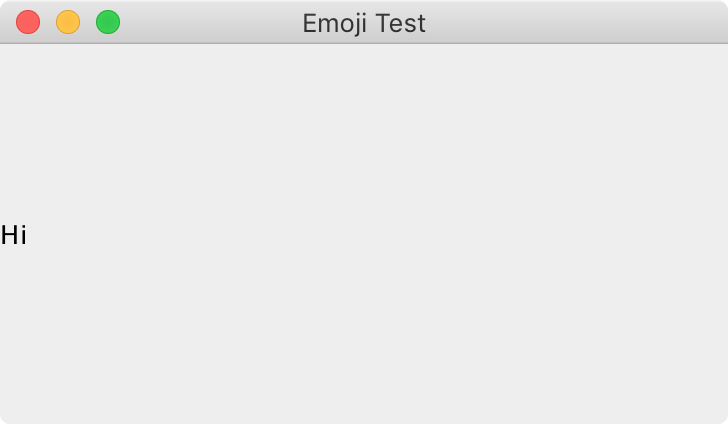
Figure 4-2. Failing to show emoji in a JFrame
It’s not that you can’t use or support emoji in your applications, you just have to be aware of differences in output features. Make sure your users have a good experience wherever they are running your code.
Comments
Java supports both C-style block comments delimited by /* and */ and C++-style line comments indicated by //:
/* This is amultilinecomment. */// This is a single-line comment// and so // is this
Block comments have both a beginning and end sequence and can cover large ranges of text. However, they cannot be “nested,” meaning that you can’t have a block comment inside of a block comment without the compiler getting confused. Single-line comments have only a start sequence and are delimited by the end of a line; extra // indicators inside a single line have no effect. Line comments are useful for short comments within methods; they don’t conflict with block comments, so you can still comment out larger chunks of code in which they are nested.
Javadoc Comments
A block comment beginning with /** indicates a special doc comment. A doc comment is designed to be extracted by automated documentation generators, such as the JDK’s javadoc program or the context-aware tooltips in many IDEs. A doc comment is terminated by the next */, just as with a regular block comment. Within the doc comment, lines beginning with @ are interpreted as special instructions for the documentation generator, giving it information about the source code. By convention, each line of a doc comment begins with a *, as shown in the following example, but this is optional. Any leading spacing and the * on each line are ignored:
/*** I think this class is possibly the most amazing thing you will* ever see. Let me tell you about my own personal vision and* motivation in creating it.* <p>* It all began when I was a small child, growing up on the* streets of Idaho. Potatoes were the rage, and life was good...** @see PotatoPeeler* @see PotatoMasher* @author John 'Spuds' Smith* @version 1.00, 19 Nov 2019*/classPotato{
javadoc creates HTML documentation for classes by reading the source code and pulling out the embedded comments and @ tags. In this example, the tags cause author and version information to be presented in the class documentation. The @see tags produce hypertext links to the related class documentation.
The compiler also looks at the doc comments; in particular, it is interested in the @deprecated tag, which means that the method has been declared obsolete and should be avoided in new programs. The fact that a method is deprecated is noted in the compiled class file so a warning message can be generated whenever you use a deprecated feature in your code (even if the source isn’t available).
Doc comments can appear above class, method, and variable definitions, but some tags may not be applicable to all of these. For example, the @exception tag can only be applied to methods. Table 4-1 summarizes the tags used in doc comments.
| Tag | Description | Applies to |
|---|---|---|
|
Associated class name |
Class, method, or variable |
|
Source code content |
Class, method, or variable |
|
Associated URL |
Class, method, or variable |
|
Author name |
Class |
|
Version string |
Class |
|
Parameter name and description |
Method |
|
Description of return value |
Method |
|
Exception name and description |
Method |
|
Declares an item to be obsolete |
Class, method, or variable |
|
Notes API version when item was added |
Variable |
Javadoc as metadata
Javadoc tags in doc comments represent metadata about the source code; that is, they add descriptive information about the structure or contents of the code that is not, strictly speaking, part of the application. Some additional tools extend the concept of Javadoc-style tags to include other kinds of metadata about Java programs that are carried with the compiled code and can more readily be used by the application to affect its compilation or runtime behavior. The Java annotations facility provides a more formal and extensible way to add metadata to Java classes, methods, and variables. This metadata is also available at runtime.
Annotations
The @ prefix serves another role in Java that can look similar to tags. Java supports the notion of annotations as a means of marking certain content for special treatment. You apply annotations to code outside of comments. The annotation can provide information useful to the compiler or to your IDE. For example, the @SuppressWarnings annotation causes the compiler (and often your IDE as well) to hide warnings about things such as unreachable code. As you get into creating more interesting classes in “Advanced Class design”, you may see your IDE add @Overrides annotations to your code. This annotation tells the compiler to perform some extra checks; these checks are meant to help you write valid code and catch errors before you (or your users) run your program.
You can even create custom annotations to work with other tools or frameworks. While a deeper discussion of annotations is beyond the scope of this book, we will take advantage of some very handy annotations for web programming in Chapter 12.
Variables and Constants
While commenting your code is critical to producing readable, maintainable files, at some point you have to start writing some compilable content. Programming is manipulating that content. In just about every language, such information is stored in variables and constants for easier use by the programmer. Java has both. Variables store information that you plan to change and reuse over time (or information that you don’t know ahead of time such as a user’s email address). Constants store information that is, well, constant. We’ve seen examples of both elements even in our tiny starter programs. Recall our simple graphical label from “HelloJava”:
importjavax.swing.*;publicclassHelloJava{publicstaticvoidmain(String[]args){JFrameframe=newJFrame("Hello, Java!");JLabellabel=newJLabel("Hello, Java!",JLabel.CENTER);frame.add(label);frame.setSize(300,300);frame.setVisible(true);}}
In this snippet, frame is a variable. We load it up in line 5 with a new instance of the JFrame class. Then we get to reuse that same instance in line 7 to add our label. We reuse the variable again to set the size of our frame in line 8 and to make it visible in line 9. All that reuse is exactly where variable shine.
Line 6 contains a constant: JLabel.CENTER. Constants contain some value that never changes throughout your program. Information that doesn’t change may seem like a strange thing to store—why not just use the information itself each time? Since the programmer writing the code gets to select the name of the constant, one immediate benefit is that you can describe the information in a useful way. JLabel.CENTER may seem a little opaque still, but the word “CENTER” at least gives you a hint about what’s happening.
The use of named constants also allows for simpler changes down the road. If you code something like the maximum number of some resource you use, altering that limit is much easier if all you have to do is change the initialized value of the constant. If you use a literal number like “5”, you would have to hunt through all of your Java files to track down every occurrence of a 5 and change it as well—if that particular 5 was in fact referring to the resource limit. That type of manual search and replace is prone to error quite above and beyond being tedious.
We’ll see more details on the types and initial values of variables and constants later in the next section. As always, feel free to use jshell to explore and discover some of those details on your own! Although a quick warning that due to interpreter limitations, you cannot declare your own top-level constants in jshell. You can still use constants defined for classes like JLabel.CENTER above or define them in your own classes you might type into jshell. The Math class has all sorts of nifty functions and a constant for π. Try calculating and storing the area of a circle in a variable. Then prove to yourself that reassigning constants won’t work.
jshell> double radius = 42.0; radius ==> 42.0 jshell> Math.PI $2 ==> 3.141592653589793 jshell> Math.PI = 3; | Error: | cannot assign a value to final variable PI | Math.PI = 3; | ^-----^ jshell> double area = Math.PI * radius * radius; area ==> 5541.769440932396 jshell> radius = 6; radius ==> 6.0 jshell> area = Math.PI * radius * radius; area ==> 113.09733552923255 jshell> area area ==> 113.09733552923255
Notice the compiler error when we try to set π to 3. Also notice that both radius and area can be changed after they were declared and intialized. But variables only hold one value at a time. The latest calculation is the only thing that remains in the variable area.
Types
The type system of a programming language describes how its data elements (the variables and constants we just touched on) are associated with storage in memory and how they are related to one another. In a statically typed language, such as C or C++, the type of a data element is a simple, unchanging attribute that often corresponds directly to some underlying hardware phenomenon, such as a register or a pointer value. In a more dynamic language such as Smalltalk or Lisp, variables can be assigned arbitrary elements and can effectively change their type throughout their lifetime. A considerable amount of overhead goes into validating what happens in these languages at runtime. Scripting languages such as Perl achieve ease of use by providing drastically simplified type systems in which only certain data elements can be stored in variables, and values are unified into a common representation, such as strings.
Java combines many of the best features of both statically and dynamically typed languages. As in a statically typed language, every variable and programming element in Java has a type that is known at compile time, so the runtime system doesn’t normally have to check the validity of assignments between types while the code is executing. Unlike traditional C or C++, Java also maintains runtime information about objects and uses this to allow truly dynamic behavior. Java code may load new types at runtime and use them in fully object-oriented ways, allowing casting and full polymorphism (extending of types). Java code may also “reflect” upon or examine its own types at runtime, allowing advanced kinds of application behavior such as interpreters that can interact with compiled programs dynamically.
Java data types fall into two categories. Primitive types represent simple values that have built-in functionality in the language; they represent simple values such as numbers, booleans, and characters. Reference types (or class types) include objects and arrays; they are called reference types because they “refer to” a large data type that is passed “by reference,” as we’ll explain shortly. Generic types and methods define and operate on objects of various types while providing compile-time type safety. For example, a List<String> is a List that can only contain Strings. These are also reference types and we’ll see much more of them in Chapter 7.
Primitive Types
Numbers, characters, and Boolean values are fundamental elements in Java. Unlike some other (perhaps more pure) object-oriented languages, they are not objects. For those situations where it’s desirable to treat a primitive value as an object, Java provides “wrapper” classes. (More on this later.) The major advantage of treating primitive values as special is that the Java compiler and runtime can more readily optimize their implementation. Primitive values and computations can still be mapped down to hardware as they always have been in lower-level languages. Indeed, if you work with native libraries using the Java Native Interface (JNI) to interact with other languages or services, these primitive types will figure prominently in your code.
An important portability feature of Java is that primitive types are precisely defined. For example, you never have to worry about the size of an int on a particular platform; it’s always a 32-bit, signed, two’s complement number. The “size” of a numeric type determines how big (or how precise) a value you can store. For example, the byte type is for small numbers, from -128 to 127 while the int type can handle most numeric needs storing values between (roughly) +/- two billion. Table 4-2 summarizes Java’s primitive types.
| Type | Definition | Approximate Range or Precision |
|---|---|---|
|
logical value |
|
|
16-bit, Unicode character |
64K characters |
|
8-bit, signed, two’s complement integer |
-128 to 127 |
|
16-bit, signed, two’s complement integer |
-32,768 to 32,767 |
|
32-bit, signed, two’s complement integer |
-2.1e9 to 2.1e9 |
|
64-bit, signed, two’s complement integer |
-9.2e18 to 9.2e18 |
|
32-bit, IEEE 754, floating-point value |
6-7 signifcant decimal places |
|
64-bit, IEEE 754 |
15 significant decimal places |
Note
Those of you with a C background may notice that the primitive types look like an idealization of C scalar types on a 32-bit machine, and you’re absolutely right. That’s how they’re supposed to look. The 16-bit characters were forced by Unicode, and ad hoc pointers were deleted for other reasons. But overall, the syntax and semantics of Java primitive types derive from C.
But why have sizes at all? Again, that goes back to efficiency and optimization. The number of goals for a soccer match rarely crest the single digits—they would fit in a byte variable. The number of fans watching that match, however, would need something bigger. The total amount of money spent by all of the fans at all of the soccer matches in all of the World Cup countries would need something bigger still. By picking the right size, you give the compiler the best chance at optimizing your code thus making your application run faster or consume fewer system resources or both.
If you do need bigger numbers than the primitive types offer, you can check out the BigInteger and BigDecimal classes in the java.Math package. These classes offer near-infinite size or precision. Some scientific or cryptographic applications require you to store and manipulate very large (or very small) numbers and value accuracy over performance. We won’t cover those classes in this book, but store their names away in the back of your brain for a rainy day’s research.
Floating-point precision
Floating-point operations in Java follow the IEEE 754 international specification, which means that the result of floating-point calculations is normally the same on different Java platforms. However, Java allows for extended precision on platforms that support it. This can introduce extremely small-valued and arcane differences in the results of high-precision operations. Most applications would never notice this, but if you want to ensure that your application produces exactly the same results on different platforms, you can use the special keyword strictfp as a class modifier on the class containing the floating-point manipulation (we cover classes in the next chapter). The compiler then prohibits these platform-specific optimizations.
Variable declaration and initialization
Variables are declared inside of methods and classes with a type name followed by one or more comma-separated variable names. For example:
intfoo;doubled1,d2;booleanisFun;
Variables can optionally be initialized with an expression of the appropriate type when they are declared:
intfoo=42;doubled1=3.14,d2=2*3.14;booleanisFun=true;
Variables that are declared as members of a class are set to default values if they aren’t initialized (see Chapter 5). In this case, numeric types default to the appropriate flavor of zero, characters are set to the null character (�), and Boolean variables have the value false. (Reference types also get a default value, null, but more on that soon in “Reference Types”.) Local variables, which are declared inside a method and live only for the duration of a method call, on the other hand, must be explicitly initialized before they can be used. As we’ll see, the compiler enforces this rule so there is no danger of forgetting.
Integer literals
Integer literals can be specified in binary (base 2), octal (base 8), decimal (base 10), or hexadecimal (base 16). Binary, octal, and hexadecimal bases are mostely used when dealing with low-level file or network data. They represent useful groupings of individual bits: 1, 3, and 4 bits, respectively. Decimal values have no such mapping, but they are much more human-friendly for most numeric information. A decimal integer is specified by a sequence of digits beginning with one of the characters 1–9:
inti=1230;
A binary number is denoted by the leading characters 0b or 0B (zero “b”), followed by a combination of zeros and ones:
inti=0b01001011;// i = 75 decimal
Octal numbers are distinguished from decimal numbers by a simple leading zero:
inti=01230;// i = 664 decimal
A hexadecimal number is denoted by the leading characters 0x or 0X (zero “x”), followed by a combination of digits and the characters a–f or A–F, which represent the decimal values 10–15:
inti=0xFFFF;// i = 65535 decimal
Integer literals are of type int unless they are suffixed with an L, denoting that they are to be produced as a long value:
longl=13L;longl=13;// equivalent: 13 is converted from type intlongl=40123456789L;longl=40123456789;// error: too big for an int without conversion
(The lowercase letter l is also acceptable but should be avoided because it often looks like the number 1.)
When a numeric type is used in an assignment or an expression involving a “larger” type with a greater range, it can be promoted to the bigger type. In the second line of the previous example, the number 13 has the default type of int, but it’s promoted to type long for assignment to the long variable. Certain other numeric and comparison operations also cause this kind of arithmetic promotion, as do mathematical expressions involving more than one type. For example, when multiplying a byte value by an int value, the compiler promotes the byte to an int first:
byteb=42;inti=43;intresult=b*i;// b is promoted to int before multiplication
A numeric value can never go the other way and be assigned to a type with a smaller range without an explicit cast, however:
inti=13;byteb=i;// Compile-time error, explicit cast neededbyteb=(byte)i;// OK
Conversions from floating-point to integer types always require an explicit cast because of the potential loss of precision.
Finally, we should note that if you are using Java 7 or later, you can add a bit of formatting to your numeric literals by utilizing the “_” underscore character between digits. So if you have particularly large strings of digits, you can break them up as in the following examples:
intRICHARD_NIXONS_SSN=567_68_0515;intfor_no_reason=1___2___3;intJAVA_ID=0xCAFE_BABE;longgrandTotal=40_123_456_789L;
Underscores may only appear between digits, not at the beginning or end of a number or next to the “L” long integer signifier. Try out some big numbers in jshell. Notice that if you try to store a long value without the signifier, you’ll get an error. You can all see how the formatting really is just for your convenience. It is not stored; only the value is kept in your variable or constant.
jshell> long m = 41234567890; | Error: | integer number too large | long m = 41234567890; | ^ jshell> long m = 40123456789L; m ==> 40123456789 jshell> long grandTotal = 40_123_456_789L; grandTotal ==> 40123456789
Try some other examples. It can be useful to get a sense of what is readable to you. It can also help drive home the kinds of promotions and castings that are available or required. Nothing like immediate feedback to help learn these subtleties!
Floating-point literals
Floating-point values can be specified in decimal or scientific notation. Floating-point literals are of type double unless they are suffixed with an f or F denoting that they are to be produced as a float value. And just as with integer literals, in Java 7 you may use “_” underscore characters to format floating-point numbers—but only between digits, not at the beginning, end, or next to the decimal point or “F” signifier of the number.
doubled=8.31;doublee=3.00e+8;floatf=8.31F;floatg=3.00e+8F;floatpi=3.14_159_265_358;
Character literals
A literal character value can be specified either as a single-quoted character or as an escaped ASCII or Unicode sequence:
chara='a';charnewline=' ';charsmiley='u263a';
Reference Types
In an object-oriented language like Java, you create new, complex data types from simple primitives by creating a class. Each class then serves as a new type in the language. For example, if we create a new class called Foo in Java, we are also implicitly creating a new type called Foo. The type of an item governs how it’s used and where it can be assigned. As with primitives, an item of type Foo can, in general, be assigned to a variable of type Foo or passed as an argument to a method that accepts a Foo value.
A type is not just a simple attribute. Classes can have relationships with other classes and so do the types that they represent. All classes in Java exist in a parent-child hierarchy, where a child class or subclass is a specialized kind of its parent class. The corresponding types have the same relationship, where the type of the child class is considered a subtype of the parent class. Because child classes inherit all of the functionality of their parent classes, an object of the child’s type is in some sense equivalent to or an extension of the parent type. An object of the child type can be used in place of an object of the parent’s type. For example, if you create a new class, Cat, that extends Animal, the new type, Cat, is considered a subtype of Animal. Objects of type Cat can then be used anywhere an object of type Animal can be used; an object of type Cat is said to be assignable to a variable of type Animal. This is called subtype polymorphism and is one of the primary features of an object-oriented language. We’ll look more closely at classes and objects in Chapter 5.
Primitive types in Java are used and passed “by value.” In other words, when a primitive value like an int is assigned to a variable or passed as an argument to a method, its value is simply copied. Reference types (class types), on the other hand, are always accessed “by reference.” A reference is a handle or a name for an object. What a variable of a reference type holds is a “pointer” to an object of its type (or of a subtype, as described earlier). When the reference is assigned to a variable or passed to a method, only the reference is copied, not the object to which it’s pointing. A reference is like a pointer in C or C++, except that its type is strictly enforced. The reference value itself can’t be explicitly created or changed. A variable acquires a reference value only through assignment to an appropriate object.
Let’s run through an example. We declare a variable of type Foo, called myFoo, and assign it an appropriate object:2
FoomyFoo=newFoo();FooanotherFoo=myFoo;
myFoo is a reference-type variable that holds a reference to the newly constructed Foo object. (For now, don’t worry about the details of creating an object; again, we’ll cover that in Chapter 5.) We declare a second Foo type variable, anotherFoo, and assign it to the same object. There are now two identical references : myFoo and anotherFoo, but only one actual Foo object instance. If we change things in the state of the Foo object itself, we see the same effect by looking at it with either reference. We can see behind the scenes a little bit by trying this with jshell:
jshell> class Foo {}
| created class Foo
jshell> Foo myFoo = new Foo()
myFoo ==> Foo@21213b92
jshell> Foo anotherFoo = myFoo
anotherFoo ==> Foo@21213b92
jshell> Foo notMyFoo = new Foo()
notMyFoo ==> Foo@66480dd7
Notice the result of the creation and assignments. Here you can see that notion that Java reference types come with a pointer value (21213b92, the right side of the @) and their type (Foo, the left side of the @). When we create a new Foo object, notMyFoo, we get a different pointer value. myFoo and anotherFoo point to the same object; notMyFoo points to a second, separate object.
Inferring Types
Modern versions of Java have continually improved the ability to infer variable types in many situations. You can use the var keyword in conjunction with the declaration and intiation of a variable and allow the compiler to infer the correct type:
jshell> class Foo2 {}
| created class Foo2
jshell> Foo2 myFoo2 = new Foo2()
myFoo2 ==> Foo2@728938a9
jshell> var myFoo3 = new Foo2()
myFoo3 ==> Foo2@6433a2
Notice the (admittedly ugly) output when you create myFoo3 in jshell, although we did not explicitly give the type as we did for myFoo2, the compiler can easily understand the correct type to use and we do in fact get a Foo2 object.
Passing References
Object references are passed to methods in the same way. In this case, either myFoo or anotherFoo would serve as equivalent arguments:
myMethod(myFoo);
An important, but sometimes confusing, distinction to make at this point is that the reference itself is a value and that value is copied when it is assigned to a variable or passed in a method call. Given our previous example, the argument passed to a method (a local variable from the method’s point of view) is actually a third reference to the Foo object, in addition to myFoo and anotherFoo. The method can alter the state of the Foo object through that reference (calling its methods or altering its variables), but it can’t change the caller’s notion of the reference to myFoo: that is, the method can’t change the caller’s myFoo to point to a different Foo object; it can change only its own reference. This will be more obvious when we talk about methods later. Java differs from C++ in this respect. If you need to change a caller’s reference to an object in Java, you need an additional level of indirection. The caller would have to wrap the reference in another object so that both could share the reference to it.
Reference types always point to objects (or null), and objects are always defined by classes. Similar to native types, instance or class variables that are not explicitly initialized when they are declared will be assigned the default value of null. Also like native types, local variables that have a reference type are not initialized by default so you must set your own value before using them. However, two special kinds of reference types—arrays and interfaces—specify the type of object they point to in a slightly different way.
Arrays in Java have a special place in the type system. They are a special kind of object automatically created to hold a collection of some other type of object, known as the base type. Declaring an array type reference implicitly creates the new class type designed as a container for its base type, as you’ll see later in this chapter.
Interfaces are a bit sneakier. An interface defines a set of methods and gives it a corresponding type. An object that implements the methods of the interface can be referred to by that interface type, as well as its own type. Variables and method arguments can be declared to be of interface types, just like other class types, and any object that implements the interface can be assigned to them. This adds flexibility in the type system and allows Java to cross the lines of the class hierarchy and make objects that effectively have many types. We’ll cover interfaces in the next chapter as well.
Generic types or parameterized types, as we mentioned earlier, are an extension of the Java class syntax that allows for additional abstraction in the way classes work with other Java types. Generics allow for specialization of classes by the user without changing any of the original class’s code. We cover generics in detail in Chapter 7.
A Word About Strings
Strings in Java are objects; they are therefore a reference type. String objects do, however, have some special help from the Java compiler that makes them look more like primitive types. Literal string values in Java source code are turned into String objects by the compiler. They can be used directly, passed as arguments to methods, or assigned to String type variables:
System.out.println("Hello, World...");Strings="I am the walrus...";Stringt="John said: "I am the walrus..."";
The + symbol in Java is “overloaded” to perform string concatenation as well as regular numeric addition. Along with its sister +=, this is the only overloaded operator in Java:
Stringquote="Four score and "+"seven years ago,";Stringmore=quote+" our"+" fathers"+" brought...";
Java builds a single String object from the concatenated strings and provides it as the result of the expression. We discuss the String class and all things text-related in great detail in Chapter 8.
Statements and Expressions
Java statements appear inside methods and classes; they describe all activities of a Java program. Variable declarations and assignments, such as those in the previous section, are statements, as are basic language structures such as if/then conditionals and loops. (More on these structures later in this chapter.)
intsize=5;if(size>10)doSomething();for(intx=0;x<size;x++){...}
Expressions produce values; an expression is evaluated to produce a result that is to be used as part of another expression or in a statement. Method calls, object allocations, and, of course, mathematical expressions are examples of expressions.
newObject()Math.sin(3.1415)42*64
One of the tenets of Java is to keep things simple and consistent. To that end, when there are no other constraints, evaluations and initializations in Java always occur in the order in which they appear in the code—from left to right, top to bottom. We’ll see this rule used in the evaluation of assignment expressions, method calls, and array indexes, to name a few cases. In some other languages, the order of evaluation is more complicated or even implementation-dependent. Java removes this element of danger by precisely and simply defining how the code is evaluated. This doesn’t mean you should start writing obscure and convoluted statements, however. Relying on the order of evaluation of expressions in complex ways is a bad programming habit, even when it works. It produces code that is hard to read and harder to modify.
Statements
In any program, statements perform the real magic. Statements help us implement those algorithms we mentioned at the beginning of this chapter. In fact, they don’t just help, they are precisely the programming ingredient we use; each step in an algorithm will correspond to one or more statements. Statements generally do one of four things: gather input to assign to a variable, write output, (to your terminal, to a JLabel, etc.), make a decision about which statements to execute, or repeat one or more other statements. Let’s look at examples of each category in Java.
Statements and expressions in Java appear within a code block. A code block is syntactically a series of statements surrounded by an open curly brace ({) and a close curly brace (}). The statements in a code block can include variable declarations and most of the other sorts of statements and expressions we mentioned earlier:
{intsize=5;setName("Max");...}
Methods, which look like C functions, are in a sense just code blocks that take parameters and can be called by their names—for example, the method setUpDog():
setUpDog(Stringname){intsize=5;setName(name);...}
Variable declarations are limited in scope to their enclosing code block—that is, they can’t be seen outside of the nearest set of braces:
{inti=5;}i=6;// Compile-time error, no such variable i
In this way, code blocks can be used to arbitrarily group other statements and variables. The most common use of code blocks, however, is to define a group of statements for use in a conditional or iterative statement.
if/else conditionals
One of the key concepts in programming is the notion of making a decision. “If this file exists…” or “If the user has a wi-fi connection…” are examples of the decisions computer programs and apps make all the time. We can define an if/else clause as follows:
if (condition)statement; elsestatement;
The whole of the preceding example is itself a statement and could be nested within another if/else clause. The if clause has the common functionality of taking two different forms: a “one-liner” or a block. The block form is as follows:
if (condition) { [statement; ] [statement; ] [ ... ] } else { [statement; ] [statement; ] [ ... ] }
The condition is a Boolean expression. A Boolean expression is a true or false value or an expression that evaluates to one of those. For example i == 0 is a Boolean expression that tests whether the integer i holds the value 0.
In the second form, the statements are in code blocks, and all their enclosed statements are executed if the corresponding (if or else) branch is taken. Any variables declared within each block are visible only to the statements within the block. Like the if/else conditional, most of the remaining Java statements are concerned with controlling the flow of execution. They act for the most part like their namesakes in other languages.
switch statements
Many languages support a “one of many” conditional commonly known as a “switch” or “case” statements. Given one variable or expression, a switch statement provides multiple options that might match. The first match wins, so ordering is important. And we do mean might. A value does not have to match any of the switch options; in that case nothing happens.
The most common form of the Java switch statement takes an integer (or a numeric type argument that can be automatically “promoted” to an integer type), a string type argument, or an “enum” type (discussed shortly) and selects among a number of alternative, constant case branches:3
switch (expression) { caseconstantExpression:statement; [ caseconstantExpression :statement; ] ... [ default :statement; ] }
The case expression for each branch must evaluate to a different constant integer or string value at compile time. Strings are compared using the String equals() method, which we’ll discuss in more detail in Chapter 8. An optional default case can be specified to catch unmatched conditions. When executed, the switch simply finds the branch matching its conditional expression (or the default branch) and executes the corresponding statement. But that’s not the end of the story. Perhaps counterintuitively, the switch statement then continues executing branches after the matched branch until it hits the end of the switch or a special statement called break. Here are a couple of examples:
intvalue=2;switch(value){case1:System.out.println(1);case2:System.out.println(2);case3:System.out.println(3);}// prints 2, 3!
Using break to terminate each branch is more common:
intretValue=checkStatus();switch(retVal){caseMyClass.GOOD:// something goodbreak;caseMyClass.BAD:// something badbreak;default:// neither onebreak;}
In this example, only one branch—GOOD, BAD, or the default—is executed. The “fall through” behavior of the switch is justified when you want to cover several possible case values with the same statement without resorting to a bunch of if/else statements:
intvalue=getSize();Stringsize="Unknown";switch(value){caseMINISCULE:caseTEENYWEENIE:caseSMALL:size="Small";break;caseMEDIUM:size="Medium";break;caseLARGE:caseEXTRALARGE:size="Large";break;}System.out.println("Your size is: "+size);
This example effectively groups the six possible values into three cases. And this grouping feature can now appear directly in expressions. Java 12 offers a preview of a switch expression. For example, rather than printing out the size names in the example above, we could create a new variable for the size like this:
intvalue=getSize();Stringsize=switch(value){caseMINISCULE:caseTEENYWEENIE:caseSMALL:break"Small";caseMEDIUM:break"Medium";caseLARGE:caseEXTRALARGE:break"Large";}System.out.println("Your size is: "+size);
Note how we used the break statement with a value this time. You can also use a new syntax within the switch statement to make things a little more compact and maybe more readable:
intvalue=getSize();Stringsize=switch(value){caseMINISCULE,TEENYWEENIE,SMALL->"Small";caseMEDIUM->"Medium";caseLARGE,EXTRALARGE->"Large";}System.out.println("Your size is: "+size);
These expressions are obviously new to the language (Java 12 even requires you to compile with the --enable-preview flag to use them) so you might not find them used very often in the online resources and examples we noted earlier. But you will definitely find good examples devoted to explaining the power of switch expressions if this statement tickles your conditional fancy.
do/while loops
The other major concept in controlling which statement gets executed next (“control flow” in computer programmerese) is repetition. Computers are really good at doing things over and over. Repeating a block of code is done with a loop. There are two main varieties of loop in Java. The do and while iterative statements run while a Boolean expression returns a true value:
while (condition)statement; dostatement; while (condition);
A while loop is perfect for waiting on some external condition, for example, getting email:
while(mailQueue.isEmpty())wait();
Of course, the wait() method needs to have a limit (typically a time limit such as waiting for one second) so that it finishes and gives the loop another chance to run. But once you do have some email, you also want to process all of the messages that arrived, not just one. Again, a while loop is perfect:
while(!mailQueue.isEmpty()){EmailMessagemessage=mailQueue.takeNextMessage();Stringfrom=message.getFromAddress();System.out.println("Processing message from "+from);message.doSomethingUseful();}
In this little snippet, we use the boolean ! operator to negate the previous test. We want to keep working while there is something in the queue. That question is often expressed in programming as “not empty” rather than “has something”. Also, note that the body of the loop is more than one statement so we put it inside the curly braces. Inside those braces, we remove the next message from the queue and store it in a local variable (message above). Then we do a few things with our message and “loop back” to the condition to see if the queue is empty yet. If it is not empty, we repeat the whole process starting with taking the next available message.
Unlike while or for loops (which we’ll see next) that test their conditions first, a do-while loop (or more often just a do loop) always executes its statement body at least once. A classic example is validating input from a user or maybe a web site. You know you need to get some information, so request that information in the body of the loop. The loop’s condtion can test for errors. If there’s a problem, the loop will start over and request the infomration again. That process can repeat until your request comes back without an error and you know you have good information.
The for loop
The most general form of the for loop is also a holdover from the C language:
for (initialization;condition;incrementor)statement;
The variable initialization section can declare or initialize variables that are limited to the scope of the for statement. The for loop then begins a possible series of rounds in which the condition is first checked and, if true, the body statement (or block) is executed. Following each execution of the body, the incrementor expressions are evaluated to give them a chance to update variables before the next round begins:
for(inti=0;i<100;i++){System.out.println(i);intj=i;...}
This loop will execute 100 times, printing values from 0 to 99. Note that the variable j is local to the block (visible only to statements within it) and will not be accessible to the code “after” the for loop. If the condition of a for loop returns false on the first check, the body and incrementor section will never be executed.
You can use multiple comma-separated expressions in the initialization and incrementation sections of the for loop. For example:
for(inti=0,j=10;i<j;i++,j--){System.out.println(i+" < "+j);...}
You can also initialize existing variables from outside the scope of the for loop within the initializer block. You might do this if you wanted to use the end value of the loop variable elsewhere, but generally this practice is frowned upon as prone to mistakes; it can make your code difficult to reason about. Nonetheless, it is legal and you may hit a situation where this behavior makes the most sense to you.
intx;for(x=0;hasMoreValue();x++){getNextValue();}// x is still valid and availableSystem.out.println(x);
The enhanced for loop
Java’s auspiciously dubbed “enhanced for loop” acts like the “foreach” statement in some other languages, iterating over a series of values in an array or other type of collection:
for (varDeclaration:iterable)statement;
The enhanced for loop can be used to loop over arrays of any type as well as any kind of Java object that implements the java.lang.Iterable interface. This includes most of the classes of the Java Collections API. We’ll talk about arrays in this and the next chapter; Chapter 7 covers Java Collections. Here are a couple of examples:
int[]arrayOfInts=newint[]{1,2,3,4};for(inti:arrayOfInts)System.out.println(i);List<String>list=newArrayList<String>();list.add("foo");list.add("bar");for(Strings:list)System.out.println(s);
Again, we haven’t discussed arrays or the List class and special syntax in this example. What we’re showing here is the enhanced for loop iterating over an array of integers and also a list of string values. In the second case, the List implements the Iterable interface and thus can be a target of the for loop.
break/continue
The Java break statement and its friend continue can also be used to cut short a loop or conditional statement by jumping out of it. A break causes Java to stop the current loop (or switch) statement and resume execution after it. In the following example, the while loop goes on endlessly until the condition() method returns true, triggering a break statement that stops the loop and proceeds at the point marked “after while.”
while(true){if(condition())break;}// after while
A continue statement causes for and while loops to move on to their next iteration by returning to the point where they check their condition. The following example prints the numbers 0 through 99, skipping number 33.
for(inti=0;i<100;i++){if(i==33)continue;System.out.println(i);}
The break and continue statements look like those in the C language, but Java’s forms have the additional ability to take a label as an argument and jump out multiple levels to the scope of the labeled point in the code. This usage is not very common in day-to-day Java coding, but may be important in special cases. Here is an outline:
labelOne:
while ( condition ) {
...
labelTwo:
while ( condition ) {
...
// break or continue point
}
// after labelTwo
}
// after labelOne
Enclosing statements, such as code blocks, conditionals, and loops, can be labeled with identifiers like labelOne and labelTwo. In this example, a break or continue without argument at the indicated position has the same effect as the earlier examples. A break causes processing to resume at the point labeled “after labelTwo”; a continue immediately causes the labelTwo loop to return to its condition test.
The statement break labelTwo at the indicated point has the same effect as an ordinary break, but break labelOne breaks both levels and resumes at the point labeled “after labelOne.” Similarly, continue labelTwo serves as a normal continue, but continue labelOne returns to the test of the labelOne loop. Multilevel break and continue statements remove the main justification for the evil goto statement in C/C++.4
There are a few Java statements we aren’t going to discuss right now. The try , catch, and finally statements are used in exception handling, as we’ll discuss in Chapter 6. The synchronized statement in Java is used to coordinate access to statements among multiple threads of execution; see Chapter 9 for a discussion of thread synchronization.
Unreachable statements
On a final note, we should mention that the Java compiler flags “unreachable” statements as compile-time errors. An unreachable statement is one that the compiler determines won’t be called at all. Of course, many methods may never actually be called in your code, but the compiler detects only those that it can “prove” are never called by simple checking at compile time. For example, a method with an unconditional return statement in the middle of it causes a compile-time error, as does a method with a conditional that the compiler can tell will never be fulfilled:
if(1<2){// This branch always runsSystem.out.println("1 is, in fact, less than 2");return;}else{// unreachable statements, this branch never runsSystem.out.println("Look at that, seems we got "math" wrong.");}
Expressions
An expression produces a result, or value, when it is evaluated. The value of an expression can be a numeric type, as in an arithmetic expression; a reference type, as in an object allocation; or the special type, void, which is the declared type of a method that doesn’t return a value. In the last case, the expression is evaluated only for its side effects; that is, the work it does aside from producing a value. The type of an expression is known at compile time. The value produced at runtime is either of this type or in the case of a reference type, a compatible (assignable) subtype.
We’ve seen several expressions already in our example programs and code snippets. We’ll also see many more examples of expressions in the “Assignment” section below.
Operators
Operators help you combine or alter expressions in various ways. They “operate” expressions. Java supports almost all standard operators from the C language. These operators also have the same precedence in Java as they do in C, as shown in Table 4-3.
| Precedence | Operator | Operand type | Description |
|---|---|---|---|
1 |
++, — |
Arithmetic |
Increment and decrement |
1 |
+, - |
Arithmetic |
Unary plus and minus |
1 |
~ |
Integral |
Bitwise complement |
1 |
! |
Boolean |
Logical complement |
1 |
|
Any |
Cast |
2 |
*, /, % |
Arithmetic |
Multiplication, division, remainder |
3 |
+, - |
Arithmetic |
Addition and subtraction |
3 |
+ |
String |
String concatenation |
4 |
<< |
Integral |
Left shift |
4 |
>> |
Integral |
Right shift with sign extension |
4 |
>>> |
Integral |
Right shift with no extension |
5 |
<, <=, >, >= |
Arithmetic |
Numeric comparison |
5 |
|
Object |
Type comparison |
6 |
==, != |
Primitive |
Equality and inequality of value |
6 |
==, != |
Object |
Equality and inequality of reference |
7 |
& |
Integral |
Bitwise AND |
7 |
& |
Boolean |
Boolean AND |
8 |
^ |
Integral |
Bitwise XOR |
8 |
^ |
Boolean |
Boolean XOR |
9 |
| |
Integral |
Bitwise OR |
9 |
| |
Boolean |
Boolean OR |
10 |
&& |
Boolean |
Conditional AND |
11 |
|| |
Boolean |
Conditional OR |
12 |
?: |
N/A |
Conditional ternary operator |
13 |
= |
Any |
Assignment |
We should also note that the percent (%) operator is not strictly a modulo, but a remainder, and can have a negative value. Try playing with some of these operators in jshell to get a better sense of their effects. If you’re new to programming, it is particularly useful to get comfortable with operators and their order of precedence. You’ll regularly encounter expressions and operators even when performing mundane tasks in your code.
jshell> int x = 5 x ==> 5 jshell> int y = 12 y ==> 12 jshell> int sumOfSquares = x * x + y * y sumOfSquares ==> 169 jshell> int explictOrder = (((x * x) + y) * y) explictOrder ==> 444 jshell> sumOfSquares % 5 $7 ==> 4
Java also adds some new operators. As we’ve seen, the + operator can be used with String values to perform string concatenation. Because all integral types in Java are signed values, the >> operator can be used to perform a right-arithmetic-shift operation with sign extension. The >>> operator treats the operand as an unsigned number and performs a right-arithmetic-shift with no sign extension. We don’t manipulate the individual bits in our variable nearly as much as we used to, so you likely won’t see those shift operators very often. If they do crop up in some code you read online, feel free to pop into jshell to see how they work or figure out just what the example code is up to. (This is one of our favorite uses for jshell!) The new operator is used to create objects; we will discuss it in detail shortly.
Assignment
While variable initialization (i.e., declaration and assignment together) is considered a statement with no resulting value, variable assignment alone is an expression:
inti,j;// statementi=5;// both expression and statement
Normally, we rely on assignment for its side effects alone, but an assignment can be used as a value in another part of an expression:
j=(i=5);
Again, relying on order of evaluation extensively (in this case, using compound assignments in complex expressions) can make code obscure and hard to read.
The null value
The expression null can be assigned to any reference type. It means “no reference.” A null reference can’t be used to reference anything and attempting to do so generates a NullPointerException at runtime. Recall from “Reference Types” that null is the default value assigned to uninitialized class and instance variables; be sure to perform your initializations before using reference type variables to avoid that exception.
Variable access
The dot (.) operator is used to select members of a class or object instance. (We’ll talk about those in detail in the following chapters.) It can retrieve the value of an instance variable (of an object) or a static variable (of a class). It can also specify a method to be invoked on an object or class:
inti=myObject.length;Strings=myObject.name;myObject.someMethod();
A reference-type expression can be used in compound evaluations by selecting further variables or methods on the result:
intlen=myObject.name.length();intinitialLen=myObject.name.substring(5,10).length();
Here we have found the length of our name variable by invoking the length() method of the String object. In the second case, we took an intermediate step and asked for a substring of the name string. The substring method of the String class also returns a String reference, for which we ask the length. Compounding operations like this is also called chaining method calls, which we’ll mention later. One chained selection operation that we’ve used a lot already is calling the println() method on the variable out of the System class:
System.out.println("calling println on out");
Method invocation
Methods are functions that live within a class and may be accessible through the class or its instances, depending on the kind of method. Invoking a method means to execute its body statements, passing in any required parameter variables and possibly getting a value in return. A method invocation is an expression that results in a value. The value’s type is the return type of the method:
System.out.println("Hello, World...");intmyLength=myString.length();
Here, we invoked the methods println() and length() on different objects. The length() method returned an integer value; the return type of println() is void (no value). It’s worth emphasizing that println() produces output but no value. We can’t assign that method to a variable like we did above with length().
jshell> String myString = "Hi there!"
myString ==> "Hi there!"
jshell> int myLength = myString.length()
myLength ==> 9
jshell> int mistake = System.out.println("This is a mistake.")
| Error:
| incompatible types: void cannot be converted to int
| int mistake = System.out.println("This is a mistake.");
| ^--------------------------------------^
Methods make up the bulk of a Java program. While you could write some trivial applications that exist entirely inside a lone main() method of a class, you will quickly find you need to break things up. Methods not only make your application more readable, they also open the doors to complex, interesting, and useful applications that simply are not possible without them. Indeed, look back at our graphical Hello World applications in “HelloJava”. We used several methods defined for the JFrame class.
These are simple examples, but in Chapter 5 we’ll see that it gets a little more complex when there are methods with the same name but different parameter types in the same class or when a method is redefined in a child class.
Statements, expressions, and algorithms
Let’s assemble a collection of statements and expressions of these different types to accomplish an actual goal. In other words, let’s write some Java code to implement an algorithm. A classic example of an algorithm is Euclid’s process for finding the greatest common denominator of two numbers using a simple (if tedious) process of repeated subtraction. We can use Java’s while loop, if/else conditional, and some assignments to get the job done:
inta=2701;intb=222;while(b!=0){if(a>b){a=a-b;}else{b=b-a;}}System.out.println("GCD is "+a);
It’s not fancy, but it works and it is exactly the type of task a computer program is great at performing. This is what you’re here for! Well, you’re probably not here for the greatest common denominator of 2701 and 222 (37, by the way) but you are here to start formulating the solutions to problems as algorithms and translating those algorithms into executable Java code in turn. Hopefully a few more pieces of the programming puzzle are starting to fall into place. But don’t worry if these ideas are still fuzzy. This whole coding process takes a lot of practice. Try getting that block of code above into a real Java class inside the main() method. Try changing the values of a and b. In Chapter 8 we’ll look at converting strings to numbers so that you could find the GCD simply by running the program again passing two numbers as parameters to the main() method as we showed in Figure 2-9 without recomiling.
Object creation
Objects in Java are allocated with the ++new++ operator:
Objecto=newObject();
The argument to new is the constructor for the class. The constructor is a method that always has the same name as the class. The constructor specifies any required parameters to create an instance of the object. The value of the new expression is a reference of the type of the created object. Objects always have one or more constructors, though they may not always be accessible to you.
We look at object creation in detail in Chapter 5. For now, just note that object creation is a type of expression and that the result is an object reference. A minor oddity is that the binding of new is “tighter” than that of the dot (.) selector. So you can create a new object and invoke a method in it without assigning the object to a reference type variable if you have some reason to:
inthours=newDate().getHours();
The Date class is a utility class that represents the current time. Here we create a new instance of Date with the new operator and call its getHours() method to retrieve the current hour as an integer value. The Date object reference lives long enough to service the method call and is then cut loose and garbage-collected at some point in the future (see “Garbage Collection” for more information about garbage collection).
Calling methods in object references in this way is, again, a matter of style. It would certainly be clearer to allocate an intermediate variable of type Date to hold the new object and then call its getHours() method. However, combining operations like this is common. As you learn Java and get comfortable with its classes and types, you’ll probably take up some of these patterns. Until that time, however, don’t worry about being “verbose” in your code. Clarity and readability are more important as you work through this book.
The instanceof operator
The instanceof operator can be used to determine the type of an object at runtime. It tests to see if an object is of the same type or a subtype of the target type. (Again, more on this class hierarchy to come!) This is the same as asking if the object can be assigned to a variable of the target type. The target type may be a class, interface, or array type as we’ll see later. instanceof returns a boolean value that indicates whether the object matches the type:
Booleanb;Stringstr="foo";b=(strinstanceofString);// true, str is a Stringb=(strinstanceofObject);// also true, a String is an Object//b = ( str instanceof Date ); // The compiler is smart enough to catch this!
instanceof also correctly reports whether the object is of the type of an array or a specified interface (as we’ll discuss later):
if(fooinstanceofbyte[])...
It is also important to note that the value null is not considered an instance of any class. The following test returns false, no matter what the declared type of the variable:
Strings=null;if(sinstanceofString)// false, null isn't an instance of anything
Arrays
An array is a special type of object that can hold an ordered collection of elements. The type of the elements of the array is called the base type of the array; the number of elements it holds is a fixed attribute called its length. Java supports arrays of all primitive and reference types.
If you have done any programming in C or C++, the basic syntax of arrays looks similar. We create an array of a specified length and access the elements with the index operator, []. Unlike other languages, however, arrays in Java are true, first-class objects. An array is an instance of a special Java array class and has a corresponding type in the type system. This means that to use an array, as with any other object, we first declare a variable of the appropriate type and then use the new operator to create an instance of it.
Array objects differ from other objects in Java in three respects:
-
Java implicitly creates a special array class type for us whenever we declare a new type of array. It’s not strictly necessary to know about this process in order to use arrays, but it helps in understanding their structure and their relationship to other objects in Java later.
-
Java lets us use the
[]operator to access array elements so that arrays look as we expect. We could implement our own classes that act like arrays, but we would have to settle for having methods such asget()andset()instead of using the special[]notation. -
Java provides a corresponding special form of the
newoperator that lets us construct an instance of an array with a specified length with the[]notation or initialize it directly from a structured list of values.
Array Types
An array type variable is denoted by a base type followed by the empty brackets, ++[]++. Alternatively, Java accepts a C-style declaration with the brackets placed after the array name.
The following are equivalent:
int[]arrayOfInts;// preferredintarrayOfInts[];// C-style
In each case, arrayOfInts is declared as an array of integers. The size of the array is not yet an issue because we are declaring only the array type variable. We have not yet created an actual instance of the array class, with its associated storage. It’s not even possible to specify the length of an array when declaring an array type variable. The size is strictly a function of the array object itself, not the reference to it.
An array of reference types can be created in the same way:
String[]someStrings;Button[]someButtons;
Array Creation and Initialization
The new operator is used to create an instance of an array. After the new operator, we specify the base type of the array and its length with a bracketed integer expression:
arrayOfInts=newint[42];someStrings=newString[number+2];
We can, of course, combine the steps of declaring and allocating the array:
double[]someNumbers=newdouble[20];Component[]widgets=newComponent[12];
Array indices start with zero. Thus, the first element of someNumbers[] is 0, and the last element is 19. After creation, the array elements are initialized to the default values for their type. For numeric types, this means the elements are initially zero:
int[]grades=newint[30];grades[0]=99;grades[1]=72;// grades[2] == 0
The elements of an array of objects are references to the objects—just like individual variables they point to—but do not actually contain instances of the objects. The default value of each element is therefore null until we assign instances of appropriate objects:
Stringnames[]=newString[4];names[0]=newString();names[1]="Walla Walla";names[2]=someObject.toString();// names[3] == null
This is an important distinction that can cause confusion. In many other languages, the act of creating an array is the same as allocating storage for its elements. In Java, a newly allocated array of objects actually contains only reference variables, each with the value null.5 That’s not to say that there is no memory associated with an empty array; memory is needed to hold those references (the empty “slots” in the array). Figure 4-3 illustrates the names array of the previous example.
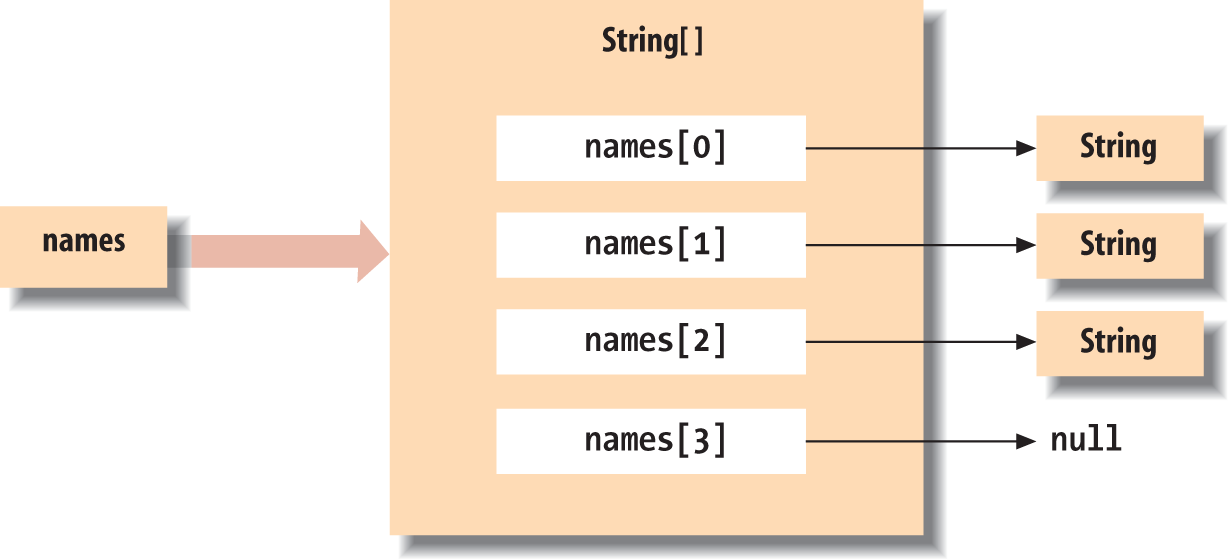
Figure 4-3. A Java array
names is a variable of type String[] (i.e., a string array). This particular String[] object contains four String type variables. We have assigned String objects to the first three array elements. The fourth has the default value null.
Java supports the C-style curly braces {} construct for creating an array and initializing its elements:
int[]primes={2,3,5,7,7+4};// e.g., primes[2] = 5
An array object of the proper type and length is implicitly created, and the values of the comma-separated list of expressions are assigned to its elements. Note that we did not use the new keyword or the array type here. The type of the array was inferred from the assignment.
We can use the {} syntax with an array of objects. In this case, each expression must evaluate to an object that can be assigned to a variable of the base type of the array or the value null. Here are some examples:
String[]verbs={"run","jump",someWord.toString()};Button[]controls={stopButton,newButton("Forwards"),newButton("Backwards")};// All types are subtypes of ObjectObject[]objects={stopButton,"A word",null};
The following are equivalent:
Button[]threeButtons=newButton[3];Button[]threeButtons={null,null,null};
Using Arrays
The size of an array object is available in the public variable ++length++:
char[]alphabet=newchar[26];intalphaLen=alphabet.length;// alphaLen == 26String[]musketeers={"one","two","three"};intnum=musketeers.length;// num == 3
length is the only accessible field of an array; it is a variable, not a method. (Don’t worry; the compiler tells you when you accidentally use parentheses as if it were a method, as everyone does now and then.)
Array access in Java is just like array access in other languages; you access an element by putting an integer-valued expression between brackets after the name of the array. The following example creates an array of Button objects called keyPad and then fills the array with Button objects:
Button[]keyPad=newButton[10];for(inti=0;i<keyPad.length;i++)keyPad[i]=newButton(Integer.toString(i));
Remember that we can also use the enhanced for loop to iterate over array values. Here we’ll use it to print all the values we just assigned:
for(Buttonb:keyPad)System.out.println(b);
Attempting to access an element that is outside the range of the array generates an ArrayIndexOutOfBoundsException. This is a type of RuntimeException, so you can either catch and handle it yourself if you really expect it, or ignore it, as we will discuss in Chapter 6. Here’ a taste of the try/catch syntax Java uses to wrap such potentially problematic code:
String[]states=newString[50];try{states[0]="California";states[1]="Oregon";...states[50]="McDonald's Land";// Error: array out of bounds}catch(ArrayIndexOutOfBoundsExceptionerr){System.out.println("Handled error: "+err.getMessage());}
It’s a common task to copy a range of elements from one array into another. One way to copy arrays is to use the low-level arraycopy() method of the System class:
System.arraycopy(source,sourceStart,destination,destStart,length);
The following example doubles the size of the names array from an earlier example:
String[]tmpVar=newString[2*names.length];System.arraycopy(names,0,tmpVar,0,names.length);names=tmpVar;
A new array, twice the size of names, is allocated and assigned to a temporary variable, tmpVar. The arraycopy() method is then used to copy the elements of names to the new array. Finally, the new array is assigned to names. If there are no remaining references to the old array object after names has been copied, it is garbage-collected on the next pass.
An easier way is to use the java.util.ArrayscopyOf() and copyOfRange() methods:
byte[]bar=newbyte[]{1,2,3,4,5};byte[]barCopy=Arrays.copyOf(bar,bar.length);// { 1, 2, 3, 4, 5 }byte[]expanded=Arrays.copyOf(bar,bar.length+2);// { 1, 2, 3, 4, 5, 0, 0 }byte[]firstThree=Arrays.copyOfRange(bar,0,3);// { 1, 2, 3 }byte[]lastThree=Arrays.copyOfRange(bar,2,bar.length);// { 3, 4, 5 }byte[]lastThreePlusTwo=Arrays.copyOfRange(bar,2,bar.length+2);// { 3, 4, 5, 0, 0 }
The copyOf() method takes the original array and a target length. If the target length is larger than the original array length, then the new array is padded (with zeros or nulls) to the desired length. The copyOfRange() takes a starting index (inclusive) and an ending index (exclusive) and a desired length, which will also be padded if necessary.
Anonymous Arrays
Often it is convenient to create “throwaway” arrays, arrays that are used in one place and never referenced anywhere else. Such arrays don’t need a name because you never need to refer to them again in that context. For example, you may want to create a collection of objects to pass as an argument to some method. It’s easy enough to create a normal, named array, but if you don’t actually work with the array (if you use the array only as a holder for some collection), you shouldn’t need to do this. Java makes it easy to create “anonymous” (i.e., unnamed) arrays.
Let’s say you need to call a method named setPets(), which takes an array of Animal objects as arguments. Provided Cat and Dog are subclasses of Animal, here’s how to call setPets() using an anonymous array:
Dogpokey=newDog("gray");Catboojum=newCat("grey");Catsimon=newCat("orange");setPets(newAnimal[]{pokey,boojum,simon});
The syntax looks similar to the initialization of an array in a variable declaration. We implicitly define the size of the array and fill in its elements using the curly-brace notation. However, because this is not a variable declaration, we have to explicitly use the new operator and the array type to create the array object.
Anonymous arrays were sometimes used as a substitute for variable-length argument lists to methods. Perhaps familiar to C programmers, a variable-length argument list allows you to send an arbitrary amount of data to a method. An example might be a method that calculates an average of a batch of numbers. You could put all the numbers into one array or you could allow your method to accept one or two or three or many numbers as arguments. With the introduction of variable-length argument lists in Java6, the usefulness of anonymous arrays has diminished.
Multidimensional Arrays
Java supports multidimensional arrays in the form of arrays of array type objects. You create a multidimensional array with C-like syntax, using multiple bracket pairs, one for each dimension. You also use this syntax to access elements at various positions within the array. Here’s an example of a multidimensional array that represents a chess board:
ChessPiece[][]chessBoard;chessBoard=newChessPiece[8][8];chessBoard[0][0]=newChessPiece.Rook;chessBoard[1][0]=newChessPiece.Pawn;...
Here, chessBoard is declared as a variable of type ChessPiece[][] (i.e., an array of ChessPiece arrays). This declaration implicitly creates the type ChessPiece[] as well. The example illustrates the special form of the new operator used to create a multidimensional array. It creates an array of ChessPiece[] objects and then, in turn, makes each element into an array of ChessPiece objects. We then index chessBoard to specify values for particular ChessPiece elements. (We’ll neglect the color of the pieces here.)
Of course, you can create arrays with more than two dimensions. Here’s a slightly impractical example:
Color[][][]rgbCube=newColor[256][256][256];rgbCube[0][0][0]=Color.black;rgbCube[255][255][0]=Color.yellow;...
We can specify a partial index of a multidimensional array to get a subarray of array type objects with fewer dimensions. In our example, the variable chessBoard is of type ChessPiece[][]. The expression chessBoard[0] is valid and refers to the first element of chessBoard, which, in Java, is of type ChessPiece[]. For example, we can populate our chess board one row at a time:
ChessPiece[]homeRow={newChessPiece("Rook"),newChessPiece("Knight"),newChessPiece("Bishop"),newChessPiece("King"),newChessPiece("Queen"),newChessPiece("Bishop"),newChessPiece("Knight"),newChessPiece("Rook")};chessBoard[0]=homeRow;
We don’t necessarily have to specify the dimension sizes of a multidimensional array with a single new operation. The syntax of the new operator lets us leave the sizes of some dimensions unspecified. The size of at least the first dimension (the most significant dimension of the array) has to be specified, but the sizes of any number of trailing, less significant array dimensions may be left undefined. We can assign appropriate array-type values later.
We can create a checkerboard of Boolean values (which is not quite sufficient for a real game of checkers either) using this technique:
boolean[][]checkerBoard;checkerBoard=newboolean[8][];
Here, checkerBoard is declared and created, but its elements, the eight boolean[] objects of the next level, are left empty. Thus, for example, checkerBoard[0] is null until we explicitly create an array and assign it, as follows:
checkerBoard[0]=newboolean[8];checkerBoard[1]=newboolean[8];...checkerBoard[7]=newboolean[8];
The code of the previous two examples is equivalent to:
boolean[][]checkerBoard=newboolean[8][8];
One reason we might want to leave dimensions of an array unspecified is so that we can store arrays given to us by another method.
Note that because the length of the array is not part of its type, the arrays in the checkerboard do not necessarily have to be of the same length; that is, multidimensional arrays don’t have to be rectangular. Here’s a defective (but perfectly legal in Java) checkerboard:
checkerBoard[2]=newboolean[3];checkerBoard[3]=newboolean[10];
And here’s how you could create and initialize a triangular array:
int[][]triangle=newint[5][];for(inti=0;i<triangle.length;i++){triangle[i]=newint[i+1];for(intj=0;j<i+1;j++)triangle[i][j]=i+j;}
Types and Classes and Arrays, oh my!
Java has a wide variety of types for storing information, each with their own way of representing literal bits of that information. Over time, you’ll gain a familiarity and comfort with ints and doubles and chars and Strings. But don&t rush—these fundamental building blocks are exactly the kind of thing jshell was designed to help you explore. It’s always worth a moment to check your understanding of what a variable can store. Arrays in particular might benefit from a little experimentation. You can try out the different declaration techniques and confirm that you have a grasp of how to access the individual elements inside single- and multi-dimensional structures.
You can also play with simple flow of control statements in jshell like our if branching and while looping statements. It requires a little patience to type in the occasional multiline snippet, but we can’t overstate how useful play and practice like this is as you load more and more details of Java into your brain. Programming languages are certainly not as complex as human languages, but they still have many similarities. You can gain a literacy in Java just as you have in English (or the language you’re using to read this book if you have a translation). You start to get a feel for what the code is meant to do even if you don’t immediately understand the particulars.
And some parts of Java, like arrays, are definitely full of particulars. We noted earlier that arrays are instances of special array classes in the Java language. If arrays have classes, where do they fit into the class hierarchy and how are they related? These are good questions, but we need to talk more about the object-oriented aspects of Java before answering them. That’s the subject of the next chapter. For now, take it on faith that arrays fit into the class hierarchy.
1 For more information about Unicode, see http://www.unicode.org. Ironically, one of the scripts listed as “obsolete and archaic” and not currently supported by the Unicode standard is Javanese—a historical language of the people of the Island of Java.
2 The comparable code in C++ would be: Foo& myFoo = *(new Foo());Foo& anotherFoo = myFoo;
3 Strings in switch statements were added in Java 7.
4 Jumping to named labels is still considered bad form.
5 The analog in C or C++ is an array of pointers to objects. However, pointers in C or C++ are themselves two- or four-byte values. Allocating an array of pointers is, in actuality, allocating the storage for some number of those pointer objects. An array of references is conceptually similar, although references are not themselves objects. We can’t manipulate references or parts of references other than by assignment, and their storage requirements (or lack thereof) are not part of the high-level Java language specification.
6 If this idea is interesting to you, check out Oracle’s technote on the topic. You can also use the shorthand name “varargs” in searches.