
Data integration was the earliest form of integration. Data files were moved between systems in batch mode. Corporate information was consolidated in the form of data warehouses, data marts, and operational data stores. While these physical consolidated data sources continue to be important to organizations, real-time integration technologies became much more attractive solutions.
Data integration has matured dramatically in the last few years. In the past it was a point-to-point solution, strictly focused on moving blocks of information from one system to another. With the movement to real time, a focus on the importance of metadata and the need to integrate all forms of content, we find that data integration is a subset of the larger area of information integration. For the sake of clarity, we define data integration to mean structured data, managed by databases. Information integration includes both the structured data and unstructured information such as documents, graphics, and streaming media. For example, a Web site or portal could aggregate data from multiple databases and synchronize updates to all of them, as well as present other types of unstructured data, such as graphics and audio. Because Web and portal applications are becoming more robust and include multiple capabilities, information integration is likely to become extremely important.
The workhorse of data integration has been ETL tools. They were created to extract the information, transform it into a consolidated view, and then load it into a data warehouse in a batch mode. The data volumes involved were generally large, the load cycles long, and information in the data warehouse typically a day to a week old. For synchronizing data across operational systems, operational data stores were created, which enabled the real-time update of information. But the problem with each of these solutions was the need to physically move large volumes of data from source systems to multiple consolidated data stores including the data warehouse, distributed data marts, operational data stores, and analytical multidimensional databases. Latencies and inconsistencies are pretty much a given with such an architecture.
Enterprise application integration (EAI) resolved the latency problem by synchronizing changes across systems in real time, but less adequately addressed the needs aggregating and consolidating data and information across the enterprise. EAI maps source data to a canonical data format and enables exchanging data among systems, but does not define an aggregated view of the data objects or business entities. However, a customer service representative on the phone wants to be able to ask a question about the customer, and have the response come from the appropriate system—without needing to know what that system is. This requires the ability to make a query across distributed data sources as if they were a single database. EAI does not address this problem at all. Enterprise information integration (EII) does.
EII is simultaneously an old and new idea. It provides the data aggregation capabilities of the old ETL tools, but provides real-time access to accurate information, much like EAI. It also provides an infrastructure for integrated enterprise data management. With EAI, the semantic meaning of data, valuable corporate information required for enterprise data quality management is stored in proprietary mapping tools. These tools are designed to make it easy to map data formats between applications. They were not designed to provide enterprise information management. Metadata repositories are designed for this purpose. Yet the information discovered to enable the transformations is the same information required for the metadata repository. In an ideal world, the metadata repository would manage the data that is used by the transformation engine. In the real world semantic metadata is in multiple places, and not centrally managed. Metadata management is an issue for long-term quality of distributed information (see Chapter 8).
The other pressing need is to integrate and manage unstructured information. Documents, e-mail, graphics, streaming media, and other types of electronic data might be included in Web applications. Enterprise content management (ECM) provides these capabilities. ECM systems may also provide some application integration and workflow capabilities, redundantly providing these integration services also provided by other technologies in the infrastructure. While many large organizations will require ECM, EAI, and EII, there is little integration across these technologies today. They can all be services on an enterprise service bus, but a move toward common metadata will help companies manage both enterprise information and enterprise integration much more easily.
This chapter focuses on technologies and architectures for implementing and operating applications built upon an enterprise information integration infrastructure. Information integration can be used to deploy the following kinds of applications
Creating a single view of a customer or other business entity
Enterprise data inventory and management
Real time reporting and analysis, and creating management dashboards
Updating a data warehouse
Creating a virtual data warehouse
Updating common information across information sources
Creating portal applications containing both structured and unstructured data from disparate systems
Integrating unstructured data, including documents, audio, video and other electronic media, into applications.
Providing an infrastructure for enterprise information management, including all forms of digital media
Information integration simplifies the creation of all these applications by enabling the information so that it can be accessed and managed as if it came from a single data source.
While information integration has tactical benefits for providing a fast and easy way to access back-end data sources, the strategic benefit is the role it can play in long-term data management. An Aberdeen research report states that database administration costs now dominate the total cost of ownership (TCO) of applications below the 500-user level, and they continue to increase in importance for all sizes of applications (Kernochan 2003). Information integration enables a company to take an enterprise approach to managing information.
Information integration is an emerging market sector. Currently the major categories of information integration technology are split between structured and unstructured data. Extract, transform, and load (ETL) tools are the most popular method of integration for synchronizing data. However, two areas that seem to be clearly emerging are EII and ECM.
ETL and EII focus on structured data integration. The difference being that ETL is a batch oriented tool and EII is real time. In addition, while EII product offerings focus on consolidating information contained in structured databases, a few also support unstructured content. ECM provides management and integration of unstructured information contained in documents, audio, video, and graphic files. While either EII or ECM may solve your current information integration requirements, in the future, the content managed by these different technologies might need to be integrated into rich media applications. Furthermore, compliance regulations such as Sarbanes-Oxley stipulate storage requirements and management of other enterprise information and communications including e-mail. This has led some BPM vendors to partner with ECM vendors. The information integration market is sure to evolve and consolidate to cover the full range and more solutions that integrate both structured and unstructured information over the next couple of years.
Currently, for the most part these different technologies are not integrated, and each provides overlapping and redundant services including application adapters and metadata repositories. While the current technology choices might make it impossible to avoid redundancy, an integrated enterprise metadata repository will go a long way to enabling rapid information integration in the future. The evolving metadata standards (see Chapter 8) as well as the acceptance of XML as the canonical data format will enable the convergence of different types of metadata into a single enterprise-wide repository. Companies should begin capturing metadata about integrated solutions in a common format on a common platform so this information can be leveraged and reused in the future. Leaving this information in proprietary data mapping tools constrains future business agility.
ETL tools are broadly available although there are neither standards nor common architecture among ETL solutions. Each product has a different environment where it excels. While most perform very well with modern relational databases, there are very real differences in products in regard to which legacy systems they will support in a mainframe environment. Furthermore, integration with packaged applications will be different among the offerings. ETL tools tend to be stand-alone and batch oriented, focused on the data warehouse market. Some provide additional features and functions to synchronize databases and packaged applications.
The EII market is just emerging. The focus of tools in this market is to access information in real time from across multiple information systems. At the heart of these solutions is a metadata repository that contains the data definitions for all existing systems as well as the access mechanisms for retrieving the information. In most cases, these are a one-way delivery of information. However, new implementations are providing two-way integration. The other major feature of an EII tool is the data aggregation service that allows new data structures to be created from existing structures. Data lineage and impact reporting allows the system to ensure that changes can be evaluated and managed to existing systems. XML and Web services are rapidly becoming the standards on which these products are based. Case Study 11.1 revisits the CompuCredit case study to look at the business benefits of an EII approach (CIO Magazine 2003).
Most organizations spend their money on managing their structured information while the vast amount of their unstructured information is stored on hard drives of personal computers without any mechanism to find and reuse this information. The ECM market is oriented at providing solutions to solve this problem. There is no common acceptable product architecture or standards under which these are developed. However, a metadata repository is a core of any solution. The architectures often use the same application integration components to access information on disparate platforms and systems. Case Study 11.2 looks at how the State of North Dakota applied an ECM approach to help their legislators (Software AG n.d.).
This specification provides implementation guidance for the development of an information integration-based solution. The information integration architecture from Chapter 8 will form the basis for the implementation. This section describes the specific technical problems that are being addressed in the implementation to give context to the specific implementation. See Appendix I for the full specification.
The scope of an Information Integration specification is limited to the specifics of the information and systems that are being integrated. It should cover organizations, information, systems, and the expected end result.
This section identifies all stakeholders in the implementation, including business managers who control all or part of the systems, data stewards or those responsible for data quality, system designers and architect(s), and the development team who will execute the implementation. Any other participants or stakeholders should also be identified, including their roles.
There are several basic implementation patterns for an information integration solution. These information integration patterns are
Data Integration
Unstructured Content Integration
Metadata Repository Integration
This section defines the particular pattern that is being used and provides details on the configuration of the specific components of the implementation.
Data integration involves structured data, generally found in different databases across the organization. As previously stated, ETL solutions have given rise to real-time enterprise information integration (EII). Solutions may provide a virtual data warehouse with integrated access across distributed data sources, mid-tier caching, or a physical mid-tier data store for real-time data aggregation and reporting. If batch synchronization is acceptable then the architecture can be simplified by choosing a specific ETL product. However, an EII-based architecture provides a more robust architecture upon which to build an integrated enterprise architecture.
The best examples for the use of simple data integration is to batch-synchronize two databases. For example, setting up a process to take a set of orders entered for a day and load this data into the fulfillment system. This is the traditional use of ETL technology.
EII vendors have technology for providing real-time access to data from multiple operational data stores. This includes optimizing distributed queries through proprietary indexing technology and/or distributed query optimization, caching data, and/or creating a mid-tier data store. In addition, EII provides the ability to aggregate data into a single logical view. The ability to create different views of consolidated information to support different applications increases ease of use. Data cleansing was generally part of the older ETL tools and some EII vendors are including the capability to support enterprise data quality management. A great example of the use of this technology is to create a single view of a customer. Most organizations struggle to understand the relationship they have with a customer. Data exists across multiple systems with conflicting definitions. The desire to create a marketing campaign that is distributed through e-mail is often difficult when there is multiple conflicting e-mail addresses entered into different systems. Trying to value customers is impossible without creating a single view of the information to determine whether clients are profitable and where to spend effort. This single view becomes reusable and can be utilized in portal applications or in call center operations.
Distributed transaction management may be necessary when updates are made to distributed data sources. The EII tool may include transaction management, support the XA transaction management standard, or integrate with a transaction processing (TP) monitor. This becomes critical when the single view is used not only to view, but also to update information. For example, the ability to update customer information from a single aggregated view allows for improved accuracy across systems. It enables updating a customer's address or e-mail information across systems from a single unified view.
While data warehouses will continue to exist to provide summary and historical data, EII can be used to integrate real-time business events with the historical data in warehouses to implement real-time BAM and decision support systems. For example, after a single view has been created, the information can be tied into a business intelligence tool that can operate in real time on data rather than only in a historical mode. The nature of BAM is real time. Any scheduling activity where changes can have significant impacts, such as airlines or delivery operations, can benefit from real time activity monitoring.
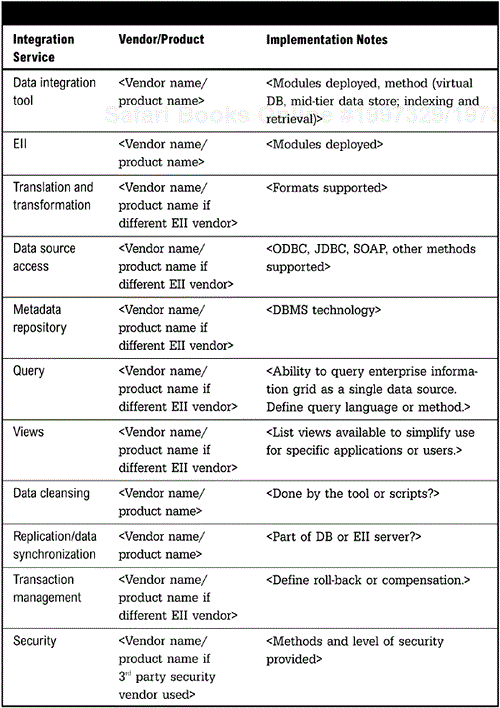
The Data Integration Reference Architecture (Figure 11-1) depicts the required and optional services for data integration. The query service represents the ability to access disparate data sources as if they were a single database (including the ability to make a single SQL call across databases) and support real-time queries of consolidated and federated data. Indexing and caching represents methods to enable fast real time queries. Views represents the ability to create different virtual views of consolidated information to simplify access and support specific applications or users. The metadata repository stores all relevant information about the data objects. Data translation and transformation is required to map information into the consolidated view and make updates to the sources. Data cleansing, often part of a data warehouse, is very important for maintaining the accuracy of integration data. Data replication and synchronization has been available from database vendors for a while, and is a very useful service for data integration. The data source access layer includes application adapters and database gateways such as ODBC and JDBC.

The Implementation Table (Figure 11-2, page 224) specifies all the integration services provided in the Information Integration Architecture, along with relevant implementation details.
While data integration provides integrated access to information in databases, there is a vast amount of unstructured data that all needs to be integrated with Web portals and applications, including documents, images, photos, audio, video, and other digital media. This unstructured information requires the same management and query capabilities as structured information management and integration. ECM solutions provide this capability.
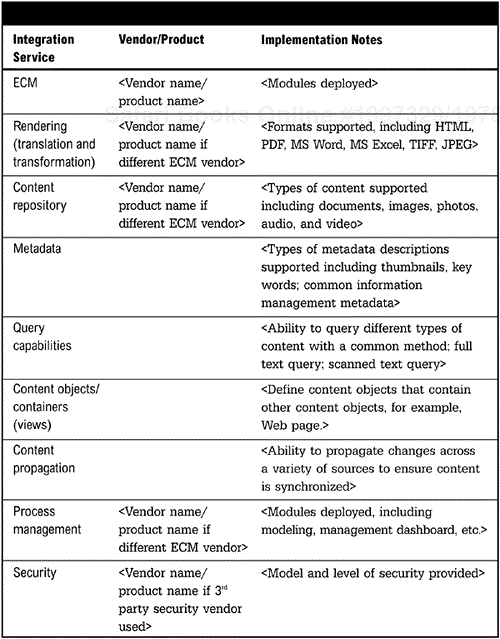
The services provided by ECM solutions (Figure 11-3, page 225) include content repository, search (query) capability, version control (check in/out), replication of content changes, integration, content rendering (translation/transformation), security, process management, and content delivery. The future direction is to have both unstructured and structured data accessible and managed through one tool. A few EII vendors already offer it. Organizations that create content from existing information assets can benefit from ECM. For example, the creation and management of product labels may seem easy, but when a label needs to be managed for different markets with different regulations with different languages, but with a single brand image, an ECM solution becomes mandatory.

The Unstructured Information Table (Figure 11-4, page 226) details the implementation. All the services may come from a single ECM vendor, or from a combination of vendors. ECM vendors typically have multiple modules and capabilities that can be flexibly deployed, so even when using a single vendor it is useful to specify the services or modules implemented.
Metadata repositories are often part of both EII and ECM solutions. However, they are also listed separately here to call attention to their importance and to the fact that common information metadata is an essential part of the integration infrastructure. A metadata repository is essentially a database that contains information about data sources (see Chapter 8 for more information regarding metadata). Unfortunately, much integration metadata is buried in proprietary tools. In order to maximize reuse and business agility, metadata should be managed consistently as a valuable enterprise resource.
The enterprise metadata repository contains all of the metadata on information and application sources. An active metadata repository contains the access mechanisms as well. The metadata repository also contains new metadata descriptions, such as canonical format, that can be mapped onto the source metadata either directly or applying transformation or calculation rules. Adapters or other integration technologies, including database gateways and Web service interfaces, are used to connect to the existing sources.
Active data access services within a repository provide the capabilities to query the repository in a common way, and access the information source through this abstraction layer. The repository provides a common mechanism for creating a single view of a customer or other resource, enterprise data inventory and management, real-time reporting and analysis, creating a “virtual data warehouse,” and updating common information across information sources.
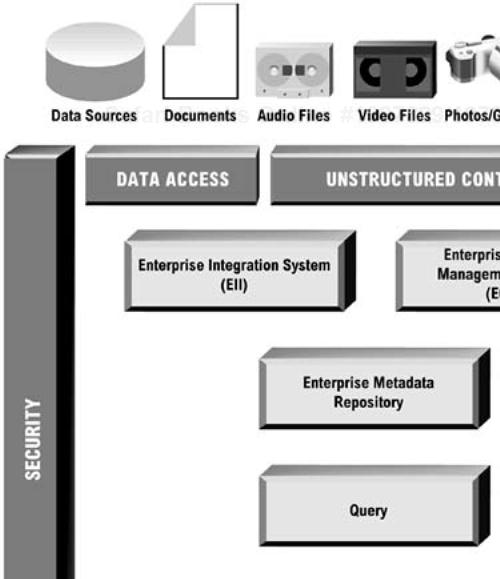
Because EII and ECM solutions could each have their own metadata repositories, a company could wind up with multiple repositories to manage, and metadata that needs to be synchronized and integrated. In principle, the metadata repository should provide a level of abstraction that makes it easier to consolidate, integrate, and manage distributed information. In practice, the company may need to create a multi-tiered metadata architecture to provide the levels of abstraction necessary to deliver this agility. The architecture diagram and specification table should include all metadata sources. Figure 11-5 (page 228) shows how an enterprise metadata repository would work with EII and ECM solutions to provide access to different types of enterprise information.
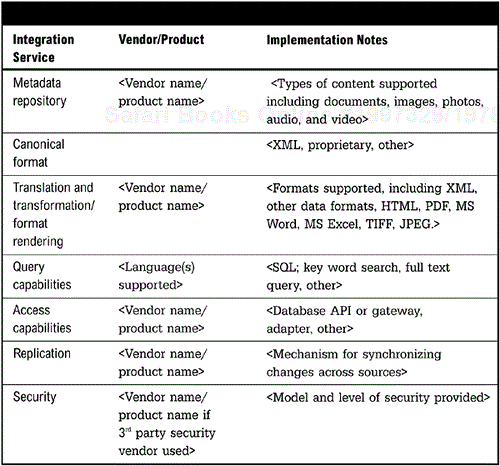
The Metadata Repository Implementation Table (Figure 11-6, page 229) defines the critical services for supporting real-time distributed data access. While the list below defines a checklist to look for in a solution, the success of the metadata repository will depend more on the processes and culture of the organization. High-level support and commitment are often the defining factors for success.
Create an EMR. Create a comprehensive enterprise metadata repository that provides information about different types of enterprise information sources.
Organize a “center of excellence.”. Create an enterprise integration competency center. Creating the metadata repository incrementally, on a project-by-project basis, will work well as long as a centralized group manages it so overlaps and inconsistencies can quickly be identified and resolved.
Focus on data quality. Appoint information stewards who are responsible for the quality of data in source systems. The information stewards are also responsible for participating in design reviews and ensuring the semantic meaning of data is correctly mapped to the canonical format.
Identify “gold standards” for data. Create an enterprise information architecture that includes information on sources of record (authoritative data sources) for each business entity that must be consistent across the enterprise.
Ensure appropriate testing is accomplished. Create a test plan to ensure that queries to a consolidated data view will return correct responses.
The next step in information integration is to implement the solution. However many information integration solutions are part of a larger integration initiative. If you are interested in composite applications, see Chapter 12. If you are interested in process management, see Chapter 13. If the project requires real time updates to back-end systems and distributed transaction management across systems, see Chapter 10 on application integration. (See Figure 11-7.)
