Approaches and practices in integration have changed over the last decade, but what was old is new again. Integration technology and techniques related to both unstructured information in reports and digital media, and structured data in databases, are becoming an important part of the integration landscape once again. This is due to a variety of factors, including the emergence of XML as a data format standard, a realization that there will not be a single approach to solve all integration requirements, and the fact that at the heart of every integration project is a need to access, aggregate, propagate, and publish information. Lastly, organizations are realizing that their data is their business and they need to get more control of and use out of this asset to improve their business.
Information and data are at the heart of every integration project. Ultimately, integration is about different types of data exchange, in many different formats. The problem that lies at the heart of all integration projects is how to enable interoperability among systems with data in different structures and formats. The Information Integration Architecture defines the infrastructure and processes for enabling information to be accessible across systems.
The EAI solution to this problem is to represent data in a canonical format. The canonical format greatly increases reusability and decreases implementation and operational costs and time. Each system needs to be mapped only once into the canonical format; then it can interoperate with other systems in the same canonical format. While there are a number of benefits to a canonical format, most of these benefits are lost if the format is proprietary and can't interoperate with other vendor solutions.
That is the reason XML is so important today. The widespread acceptance and adoption of XML has been largely due to the tremendous need to describe data in a common format to reduce the time and cost of integration, and the fact that there really is no other alternative. XML is the best and only. (See sidebar on XML.)
However, while XML provides a standards-based canonical format, the real value of the data is dependent on maintaining the integrity of data across systems. Propagating incorrect data throughout multiple systems in a fraction of the time it would have taken with nonintegrated systems provides little value to the enterprise. The solution to maintaining the value, meaning, and integrity of data across applications is metadata. Metadata is information about the data. The more descriptive, accurate, and complete the metadata is, the better the integration can be. While a great deal of metadata already exists in systems, and there are a number of tools on the market that can automatically extract metadata from source systems, the quality of the metadata the tool can produce depends very much on what is available in the source system. To achieve the full benefits of metadata, organizations must ensure that all metadata is accurate and complete. This will likely require significant investment. However, down the line, the investment will pay off through increased quality and reuse of data, and decreased implementation time and cost.
Metadata is not just a nice-to-have in the enterprise architecture. It is an absolute necessity. It is how the information in and about systems can be represented independently from all systems, enabling interoperability between and among systems. Good metadata is the foundation for long-term successful integration.
The Information Integration Architecture defines enterprise metadata independent of technologies or platforms, in a manner usable by all integration projects.
Data in systems represents business entities, such as customers, employees, products, etc., and provides a persistent record of business events. Metadata, the information describing this data, enables the information to be queried, reported on, consolidated, synchronized, and integrated.
However, as the saying goes, garbage in—garbage out. For integration to provide any business value at all, the information needs to be accurate, and correctly applied in different applications. The long-term value of the data to the enterprise depends on ensuring the integrity of systems information. This requires both semantic and syntactic validation. Semantic validation ensures the information makes sense. Syntactic validation ensures that data is correctly formatted. Data integrity requires both.
A standard metadata model includes information to enable syntactic validation, and enables automation of translation, transformation, and delivery of data to the target systems in the native format. However, it does not include metadata that defines the semantic meaning, including the context, relationships, and dependencies. Entity-Relationship (E-R) diagrams are often used for this purpose. However, E-R diagrams are used in the discovery and design phase. The integrity rules revealed by the E-R diagram need to be added as code in the application or triggers and stored procedures in the database. The semantic meaning has not traditionally been part of the metadata, and this limitation has had a number of implications, especially when data transactions cross applications. There are no built-in cross-application integrity rules. That means that for transaction level integration, additional processing rules will need to be custom coded. This significantly slows the implementation of Web commerce solutions.
Because of the great importance and value in maintaining and communicating the semantic meaning of data in a portable and reusable manner, there are a number of efforts underway to define a semantic metadata model. While many of these efforts are still in the early stages, it is important to know they exist, if only to understand that the metadata created to aggregate data for data and application integration is only the beginning of the Information Integration Architecture. Over time, organizations will need to create richly layered metadata architectures to fully express and protect the meaning and value of business information.
There are different types of metadata for describing different aspects of the system. Most system developers are familiar with metadata that describes the information in the system. However, this type of metadata does not define transaction and processing rules. These must be defined in the application itself. But in enterprise integration solutions, transactions often cross multiple systems. It would be better to capture the integrity requirements in the metadata so it is available to all systems, rather than coding it in each system. Then, when distributed transaction rules are changed, they only need to be changed in the enterprise metadata, rather then each system. Business agility requires different types of metadata to fully represent the business meaning of data, transactions, and system interactions.
A useful framework for understanding the different possible layers of metadata is the Object Management Group (OMG) Four Layer Metadata Architecture. The Metadata Architecture definition is part of the OMG Model Driven Architecture (MDA), a framework for designing systems that can run on any platform with native look and feel, without any recoding or recompiling. Each layer of the Metadata Architecture provides a higher level of functionality. (For more information, see OMG Meta Object Facility (MOF) Specification, http://www.omg.org/cwm/.)
The bottom layer, Layer 0, is the actual information and data values. Level 1 is the metadata layer that is comprised of information describing this data. A data integration model supports the aggregation of data from disparate back-end systems and defines the attributes of the data to enable automatic validation and cleansing. The metadata about each business entity is aggregated into a metadata model, which is about a system and the information in the system. The OMG examples of metadata models include Unified Modeling Language (UML) models and interface definition language (IDL) interfaces.
Level 2, the metamodel layer, is where semantic meaning is added. The metamodel is an abstract language that defines both the structure and semantics of the metadata. Adding semantics to the model means that integrity and business rules do not need to be coded in proprietary triggers and stored procedures, or in application code. At the metadata level, the business rules and meaning of the data are contained in the metadata and are available to all systems. The OMG lists UML metamodels and IDL metamodels as examples.
Level 3 is the meta-metamodel, an abstract language for defining different kinds of metadata. This is equivalent to the metadata repository. The OMG example is the Meta Object Facility (MOF). MOF defines an abstract language and framework for specifying, constructing, and managing technology neutral metamodels, and a framework for implementing metadata repositories.
Each layer in the OMG metadata architecture increases the level of reuse and efficiency, and makes integration an easier task. While the OMG metadata framework is part of the MOF Specification, it is also useful for understanding the metadata standards being developed by other standards bodies.
As the metadata architecture becomes more complete, the cost, time, and complexity of integrating systems will decrease. Metadata is the key to the future integration of automation and management.
Standards are extremely important for enabling metadata interoperability. However, there are so many of them it is difficult to understand how they relate to each other. Different metadata standards are being defined by standards organizations, including: the World Wide Web Consortium (W3C), leading the way for XML and Web-related standards; the Organization for the Advancement of Structured Information Standards (OASIS), an international consortium focused on e-business standards; the Object Management Group (OMG), focusing on design and development; and the Open Application Group (OAG), creating industry-focused metadata models. This section presents an overview of the standards each of these organizations is responsible for, and provides guidelines for which standards may be most important to your organization.
The W3C is responsible for a number of Web standards. Here we focus on evolving metadata standards for the Semantic Web. The Semantic Web ensures that Web information makes sense by providing a representation of data on the Web that includes the meaning. “The Semantic Web is an extension of the current Web in which information is given well-defined meaning, better enabling computers and people to work in cooperation” ( Berners-Lee, Hendler, and Lassila 2001). Part of the Semantic Web is the notion of an ontology. An ontology defines a common set of terms to describe and represent a particular domain—a specific subject or knowledge area such as retail, manufacturing, or medicine. Ontologies include computer-usable definitions of business entities, relationships, and properties or attributes. They capture valuable business knowledge in a reusable and adaptable format, and are the framework for implementing the Semantic Web. Ontologies represent Level 2 metadata. They contain both the structure and semantics of the metadata. Ontologies are usually expressed in a logic-based language to provide detailed, consistent, and meaningful distinctions among the classes, properties, and relations. The languages being specified by the W3C are RDF and OWL (see sidebar). Companies interested in advanced Web development and functionality will want to look more closely into ontologies and the metadata standards being proposed by the W3C.
OASIS is a not-for-profit, worldwide consortium focused on e-business standards for “security, Web services, XML conformance, business transactions, electronic publishing, topic maps, and interoperability within and between marketplaces” (http://www.oasis-open.org). OASIS has more than 600 corporate and individual members in 100 countries around the world. For that reason, ebXML is an important B2B metadata standard. OASIS and the United Nations jointly sponsor ebXML. Companies engaging in global e-commerce will want to pay attention to the ebXML standard.
The OMG Metadata Architecture described above is part of the Model Driven Architecture (MDA) initiative. The goal of MDA is to enable complete technology independence from systems design and implementation. An application developed using MDA could be deployed on multiple platforms without changing the code. The OMG is also responsible for the UML standard, which is widely used for application development. The two OMG metadata standards to watch are XMI, which will enable portability of UML design models, and the Common Warehouse MetaModel (CWM). (See sidebar.) Companies that have adopted UML as a development standard will be interested in XMI and CWM.
The OAG is a not-for-profit industry consortium focused on promoting interoperability among business applications and creating business language standards to support this goal. According to the website (http://www.openapplications.org), it is the largest publisher of XML-based content for business software interoperability in the world. It has published numerous industry schemas and the OAGIS, which contains a standards-based canonical business language. (see sidebar). The OAG will be of importance to companies in industries heavily involved in implementing industry-specific B2B transactions through the OAGIS framework.
Metadata management is becoming essential for business agility and enabling rapid integration and systems interoperability. Standards-based solutions help maximize reuse and decrease operational costs. While most companies will begin by focusing on the first two layers of the metadata architecture, it is important to understand the evolving standards in other areas. These efforts will eventually transform the way we build and implement applications, enabling rapid integration and automation. The creation of metadata models represents both a considerable investment and a valuable corporate asset. Ultimately, good metadata will decrease implementation time and cost, increase reuse, and maximize ROI for integration investments.
There are two types of information integration: aggregation and publishing. Information aggregation is bringing together information for multiple sources into a single metadata model that provides a single view of the data across systems. A good example of a need for aggregation is the creation of a call-center application that provides a unified view of the relationship with a customer rather than requiring the operators to use a variety of systems and interfaces coupled with their own innate ability to aggregate the information together to perform the same task.
Information publishing is pushing information into multiple back-end systems. There are multiple different models for publishing including one-to-one publishing, one-to-many publishing. and multiple-step publishing. One-to-one publishing is the most simplistic. Allowing a customer to change his or her address online and updating a system with this information is a common example. One-to-many publishing may require transactional support across systems if there are dependencies that must be maintained. However there are instances where there is no dependency and failure to publish with one node does not impact the other nodes. For example, if a customer has several different relationships with a business, such as having a checking account and loan through a bank, it is reasonable to assume that each system is updated with the address information. This may not require transactional integrity. However, if money were transferred from a checking account to pay off a loan then transactional integrity would be required. The final model is a multiple-step publishing where the information is published to nodes in a series of steps. Each step occurs only after a successful conclusion to a prior step. For example, updating an address followed by sending a written confirmation could be done as two-step publishing.
Enterprise information integration (EII) technology is one of the fastest growing sectors in the integration market. EII technology provides a faster and easier way to consolidate information from multiple sources into a single interface, as if all the information came from a single database. EII creates an aggregated and federated information architecture.
Customer and self-service solutions can be made much more user friendly from a single view of customers, patients, or other business entities. The consolidated metadata enables real-time feeds to management dashboards and analytical tools. It provides a virtual data warehouse for real-time reporting. EII allows all back-end information to be seen as if it came from one unified database. Unified access to data in disparate databases simplifies many applications, providing faster, cheaper integration for a number of different business solutions.
EII is focused on Levels 0 and 1 of the OMG Four Layer Metadata Architecture. At this level, semantic meaning needs to be represented and preserved through integrity rules. Integrity rules would need to include cross-application relationships. Level 1 metadata is appropriate for information-driven integration, but less so for transaction-driven integration.
EII solutions typically contain a metadata repository—a data aggregation service that can pull data from multiple back-end systems and aggregate it according to the common metadata model, querying disparate data as if it came from a single source—and management capabilities including data lineage and impact analysis. Data lineage provides the ability to trace back the data values to the source systems they came from. This is very helpful for maintaining data quality across systems. Impact analysis helps determine how downstream systems are affected by any changes. This is very helpful for optimizing systems and performing systems maintenance. The metadata repository and management capabilities of EII are important for all types of integrated data management. Therefore, we expect EII to become an important part of the integrated architecture.
A full copy of the specification is in Appendix F.
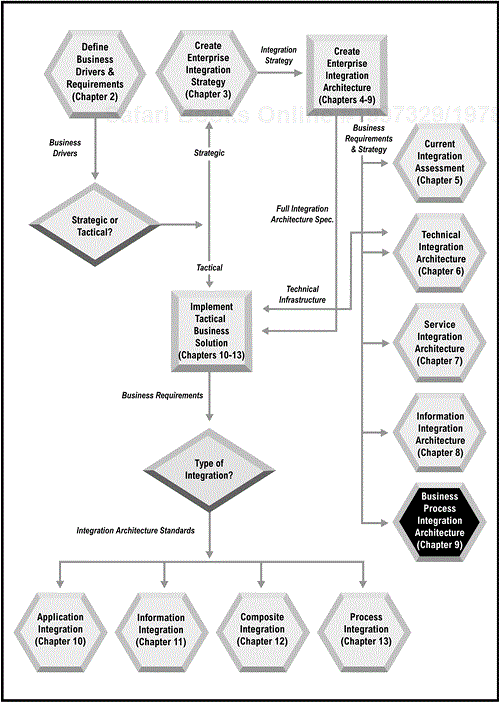
This document is a guide to creating the information integration architecture specification for information-driven business solutions.
The scope of the Information Architecture Specification can be enterprise-wide or limited to a single integration project. The document should define the business information needs, the relevant metadata, and the underlying integration architecture. The scope should describe the breath of business information covered as well as the systems and data sources involved in the process.
This section identifies all stakeholders in the business information being integrated, including business managers who control all or part of the information, system designers and architect(s), and the development team who will execute the implementation. Any other participants or stakeholders should also be identified, including their roles.
This section is used to identify and map all of the requirements to the design patterns for information integration (see Figure 8-1, page 152). The two basic design patterns are information aggregation and publishing. To identify the business information requirements that need to be defined as part of this specification, start with the Statement of Purpose and the scope of responsibilities defined in the Business Strategies and Initiatives Specification. Then use the design patterns to identify the best approach for implementation.
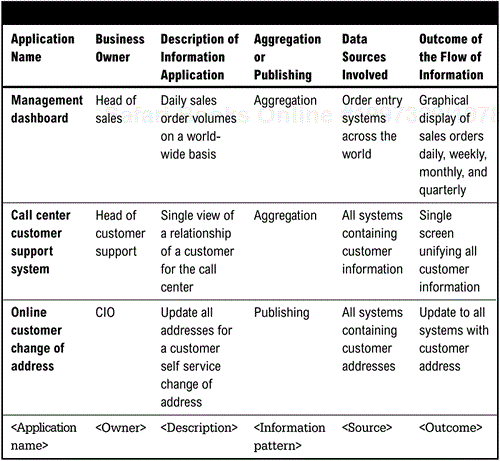
Examples of requirements that are suited for information integration include creation of management dashboards, single views of customers or other business resources, propagation of information to reduce the retyping of information into systems, virtual-data warehouse, real-time feeding of analytical tools, or automating the use of Microsoft Office documents (or other desktop tools). These types of requirements focus on the real-time aggregation of sources where information is collected and combined together to feed the creation of new bundles of information or the ability to publish a document into several information sources to provide a single update across data sources.
The Data Flow Diagram (Figure 8-2, page 153) depicts the flow of information. Usually the flow of information is depicted within a single system between processes and one or more data stores, with external systems depicted outside the circle. In integration, we are primarily interested in the flow of information between systems, so essentially all systems are external. Therefore, we have adapted the traditional data-flow diagram for the purpose of identifying systems sharing a type of information. External systems (depicted as shaded boxes) are systems outside of the enterprise.

The purpose of creating the data flow diagram is to determine which systems are involved in the data flow in order to later determine the integrity rules across systems (which is done in the Relationship Model shown in Figure 8-4).

Effective metadata management is critical to information-driven architecture. Each application will require a metadata model that combines the new model for the application with the existing models of each of the data sources that is used. The Metadata Model is used to define access and transformation rules. It establishes data lineage and enables impact analysis.
The model can also be used as a strategic asset, lowering the cost of operational management and new implementations. It helps ensure data quality by managing data access and integrity. It helps maximize the investment in systems knowledge.
Metadata for existing data sources must be captured for each element. The model shown in Figure 8-3 (page 154) can be used as a starting point. Many of the enterprise information integration tools currently on the market include metadata repositories that provide their own metadata models. Additionally, if you are using a standards-based approach or an industry-specific ontology model, that will also have its own metadata. Figure 8-3 defines the types of metadata you might consider as part of the overall information-integration architecture.

The Relationship Model defines the integrity rules across data objects and systems. If implementing a Level 1 metadata model, the integrity rules will need to be explicitly defined in routing logic or database triggers and procedures. Level 2 metadata models contain semantic meaning within the model itself.
The Relationship Model defines dependencies and rules for cascading deletes, roll backs, and compensating transactions; defines data lineage; and enables impact analysis. Figure 8-4 describes the type of information required. As previously stated, evolving metadata standards will more fully describe these relationships.
Information design reviews are critical to the overall success and agility of the system. The design reviews should include all relevant stakeholders, defined above in the Key Participants section (8.7.3). All parts of the model need to be reviewed and verified. Participants need to verify the portions of the information they are responsible for, including the definition of all elements, how they are created and updated, the formats, and access mechanisms. The business users need to provide the definitions for the information required in the new application. In addition, it will be critical for the stakeholders to ensure they deal with discrepancies on which data source contains the “gold standard” for the organization when there are conflicts or duplications. This is often the most difficult task that the group will face. The overall process should be reviewed for opportunities to improve consistency and quality of information across the organization.
Use the following guidelines for successful design reviews:
Make sure all the stakeholders are present.
Explain the process and ground rules before the design review.
Criticize the design, not the person.
Designers may only speak to clarify the design and provide background information. They should not “defend” the design.
Identify “owners” of information.
Identify systems of record for information.
Define a process for data quality.
Conduct design reviews. A metadata model represents an aggregated definition of data from different systems in a canonical format. The only way to ensure the common definition is correct is to have the model verified by all the stakeholders—those who have knowledge of each of the systems, and those who need to utilize and integrate the data.
Create a metadata repository. A metadata repository, based on standards, provides a platform for storing, accessing, and managing metadata, and provides access to information across the organization. It is the Rosetta stone to disparate enterprise data. The repository can grow over time, on a project-by-project basis. However, it needs to be actively managed to ensure integrity and data quality and maximize reuse.
Manage the repository in the competency center. There are different types of integration, and different types of metadata. However, the work of researching, defining, and verifying the intent and meaning of data in systems, which forms the foundation for integration, needs to be managed and leveraged. It represents a considerable investment and a valuable and reusable resource for the organization. While different projects may work with different data or levels of metadata, the competency center can track and manage how the metadata is used across projects, how the different levels of metadata relate, and which standards are most appropriate.
Add semantic meaning to the metadata. The more meaning the metadata contains, the less work the programmers need to do. Semantically rich metadata enables electronic transactions to be implemented across systems without needing to add additional application or database code to ensure the integrity of the data. It is the key to enabling e-commerce faster and cheaper than ever before.
Information and data are at the heart of all integration projects. Defining the information independent of technology or tools is a much better approach for long-term agility and reuse. It enables the work done on one project to be available for the next. Companies interested in long-term business agility will invest in all aspects of the enterprise integration architecture, including defining the process integration architectures (Chapter 9). Companies focused on pressing tactical needs, will define only what is absolutely necessary and move on to implementation (Part III). See Figure 8-5.