
Chapter 1 – The Aster Data Architecture
“Design is not just what it looks like and feels like. Design is how it works.”
- Steve Jobs
What is Parallel Processing?
“After enlightenment, the laundry”
- Zen Proverb
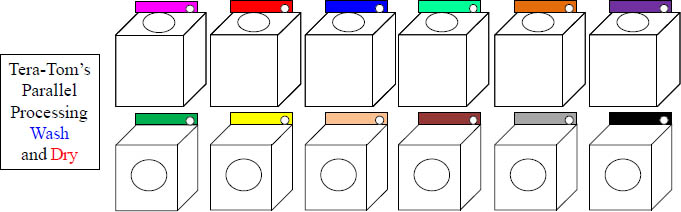
“After parallel processing the laundry, enlightenment!”
-Aster Zen Proverb
Two guys were having fun on a Saturday night when one said, “I’ve got to go and do my laundry.” The other said, “What?!” The man explained that if he went to the laundry mat the next morning, he would be lucky to get one machine and be there all day. But, if he went on Saturday night, he could get all the machines. Then, he could do all his wash and dry in two hours. Now that’s parallel processing mixed in with a little dry humor!
Aster Data is a Parallel Processing System
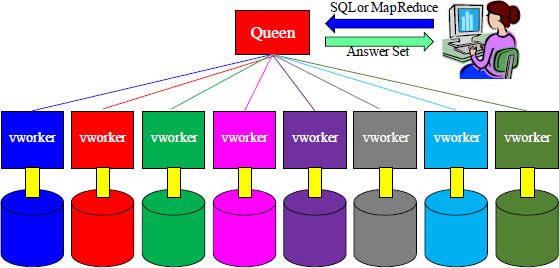
The queen takes the request from the user and builds the plan for the vworkers. The vworkers retrieve their portion of the data and pass the results to the queen. The queen delivers the answer set to the user.
Each vworker holds a portion of every table and is responsible for reading and writing the data that it is assigned to and from its disk. Queries are submitted to the queen who plans, optimizes, and manages the execution of the query by sending the necessary subqueries to each vworker. Each vworker performs its subquery or subqueries independent of the others, completely following only the queen’s plan. The final results of queries performed on each vworker is returned to the queen where they can be combined and delivered back to the user.
Each vworker holds a Portion of Every Table
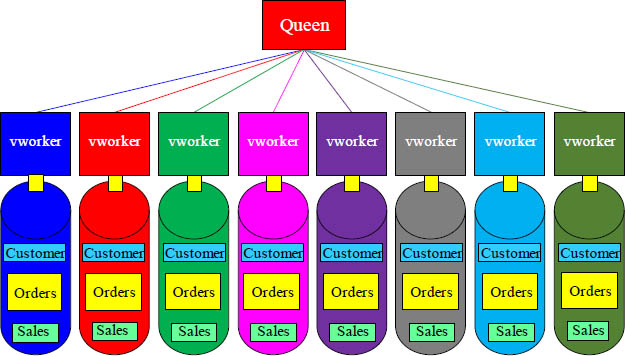
Every vworker has the exact same tables, but each vworker holds different rows of those tables.
When a table is created on Aster, each vworker receives that table. When data is loaded, the rows are hashed by a distribution key so each vworker holds a certain portion of the rows. If the queen orders a full table scan of a particular table, then all vworkers simultaneously read their portion of the data. This is the concept of parallel processing.
The Rows of a Table are Spread Across All vworkers
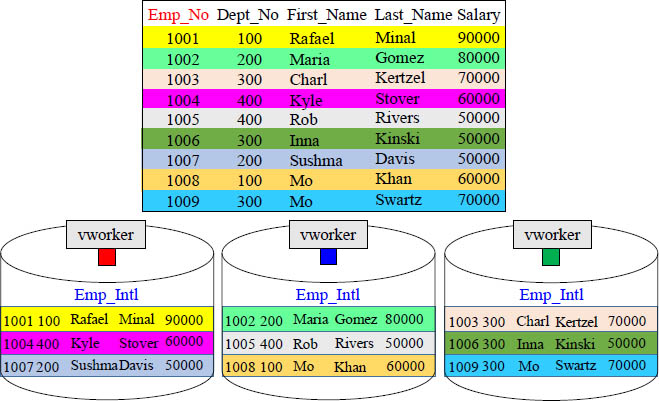
A Distribution Key will be hashed to distribute the rows among the vworkers. Each vworker will hold a portion of the rows. This is the concept behind parallel processing.
Aster Tables are defined as Fact or Dimension when Created
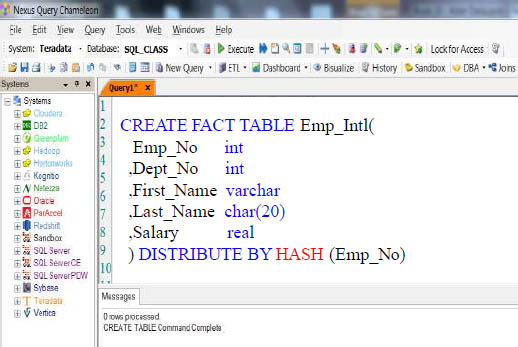
An Aster Table will be either a Fact or Dimension Table. Fact tables are usually large, and dimension tables are relatively smaller. Fact tables will generally be distributed by hash on a distribution key which is a key column in the table. Dimension tables are usually distributed by replicating the table across all vworkers.
Fact Table
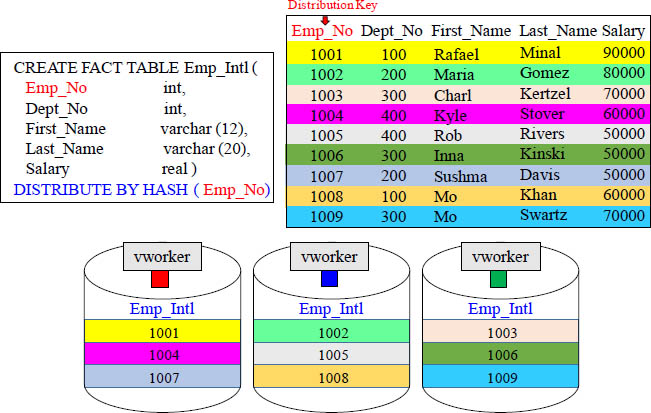
A Distribution Key will be hashed to distribute the rows among the vworkers.
A More Detailed Look at the Fact Table Distribution
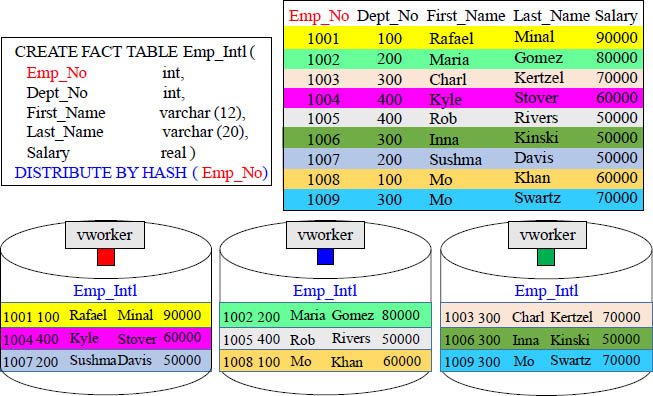
A Distribution Key will be hashed to distribute the rows among the vworkers. The entire row will be held by the vworker, but the row finds its vworker based on hash.
Dimension Table are Replicated
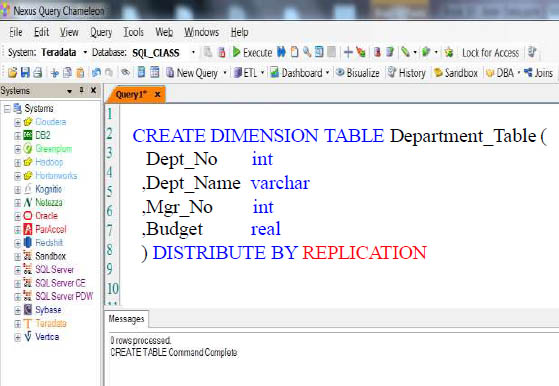
Dimension tables are relatively smaller than the large fact table they join to. Dimension tables are usually, but not always, distributed by replicating the table across all vworkers. That means that each vworker has the exact same copy of the entire table.
A Dimension Table is often Replicated across vworkers
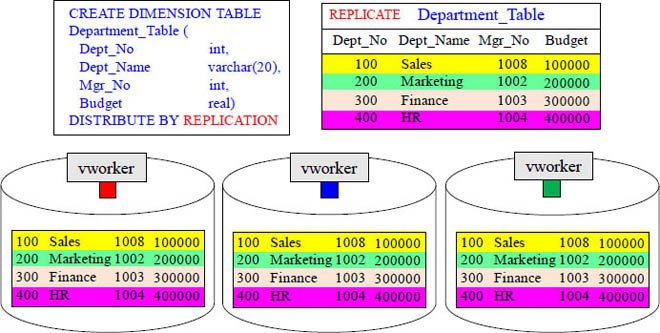
A replicated table is copied in its entirety to all vworkers.
Fact and Dimension tables are created in this manner for join purposes. Dimension tables are smaller so they are replicated, but Fact tables are distributed by a hash key.
Aster Data has Fact and Dimension Tables
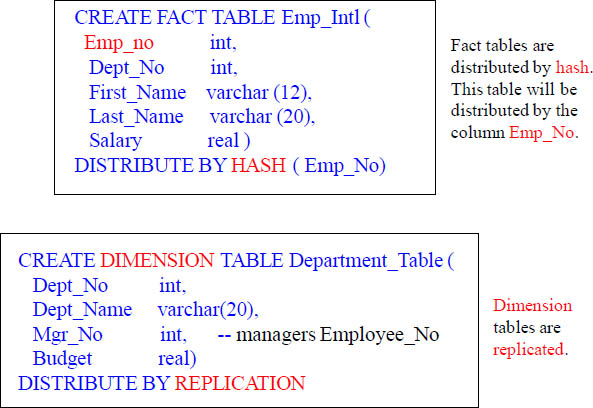
Fact Tables in Aster will have a Distribution Key. Dimension Tables will be replicated.
Aster Tables are defined as Fact or Dimension when Created
An Aster Table will be either a Fact or Dimension Table. Fact tables are usually large, and dimension tables are relatively smaller. Fact tables will generally be distributed by hash on a distribution key which is a key column in the table. Dimension tables are usually distributed by replicating the table across all vworkers.
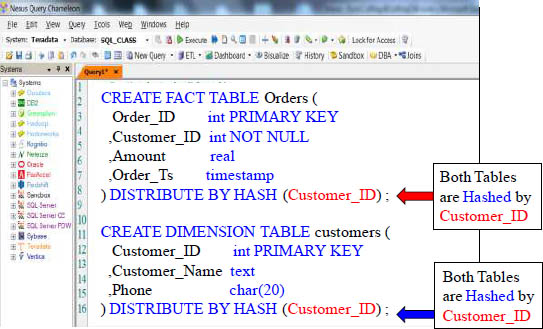
Fact and Dimension Tables can be Hashed by the same Key
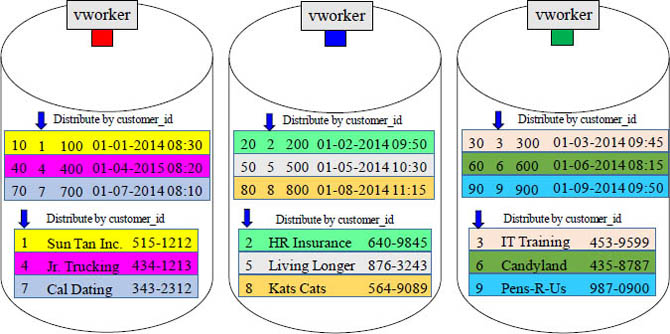
Fact tables are large and usually distributed by hash. Dimension tables are usually small and often distributed by replication, but dimension tables can be distributed by hash. This is done to get vworker co-location. Above, you can see that both tables were distributed by hash on the customer_id column. This locates the joining rows on the same vworker. Distribution design is based on what joins to what.
Distribution Key Rules
Every fact table must have a distribution key including logically partitioned tables. If there is no distribution key, the statement will fail.
Dimension tables optionally can have distribution keys or be replicated. If no distribution key is defined, the table will by default be replicated.
The distribution key can only consist of a single column.
No null values are allowed in the distribution key column, so it cannot be Nullable.
If the table has a primary key, the distribution key must be one of the columns from the primary key.
No modifications allowed. Once you have declared your distribution key:
1. you cannot specify a new distribution key for the table.
2. you cannot modify the distribution key column by dropping or renaming it, nor can you change its type.
3. you cannot update a value in the distribution key column.
Above are the distribution key rules.
Aster Data Uses a Hash Formula

![]() There is only one Hashing Formula.
There is only one Hashing Formula.
![]() A row’s Distribution Key value is hashed, and the output is its Row Hash.
A row’s Distribution Key value is hashed, and the output is its Row Hash.
![]() The Row Hash will be stored with the row (on disk) in numeric form.
The Row Hash will be stored with the row (on disk) in numeric form.
![]() If the Hashing Formula hashes value 1001, and gets a row hash of 13, then it will produce a 13 every time it hashes a 1001 value. It's consistent!
If the Hashing Formula hashes value 1001, and gets a row hash of 13, then it will produce a 13 every time it hashes a 1001 value. It's consistent!
There is one Hashing Formula in Aster Data and it is consistent. The concept is to take the value of a row’s Distribution Key and run it through the Hash Formula. It will produce a Row Hash number. That Row Hash will stay with the row and reside as the Row_ID. The Row Hash also determines which vworker owns the row.
The Hash Map Determines which vworker will own the Row
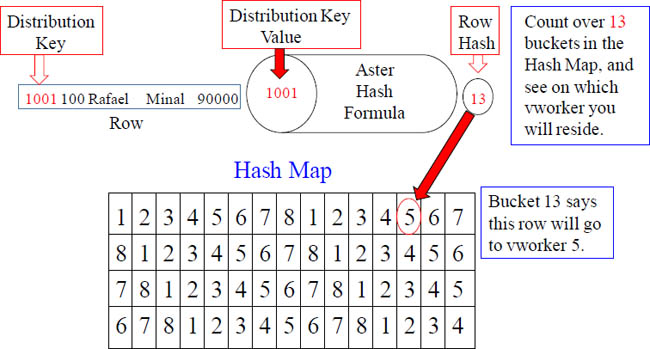
This Hash Map is for a 8-vworker system
A row will be placed on a vworker after the loading node hashes the row’s Distribution key value. The output of the Hashing Algorithm is a numeric number. The numeric number goes to a bucket in the Hash Map and is assigned to a vworker.
The Hash Formula, Hash Map and vworker
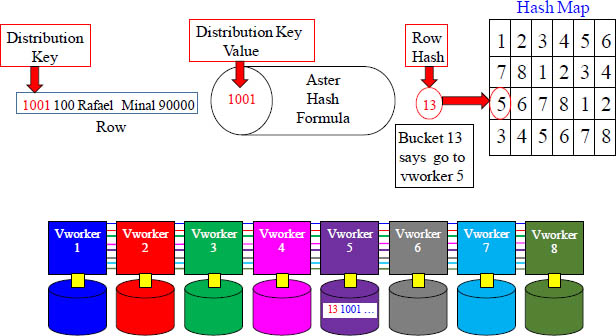
The above example hashed Emp_No 1001 (Distribution Key value), and the output was a numeric number of 13. Aster counted over to bucket 13 in the Hash Map, and it has the number five (5) inside that bucket. This means that this row will go to vworker 5.
Placing rows on the vworker
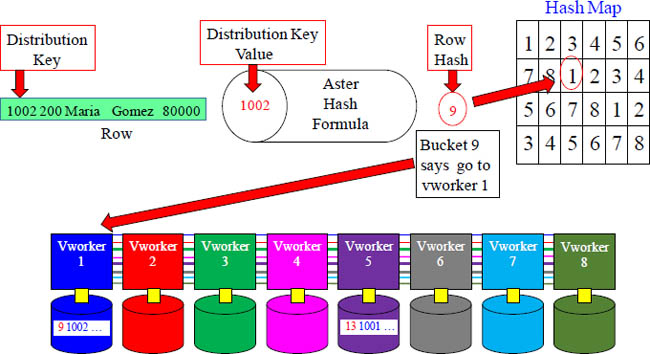
The above example hashed Emp_No 1002 (Distribution Key value), and the output was a numeric number of 9. Aster counted over to bucket 9 in the Hash Map, and it has the number one (1) inside that bucket. This means that this row will go to vworker 1.
Placing rows on the vworker Continued
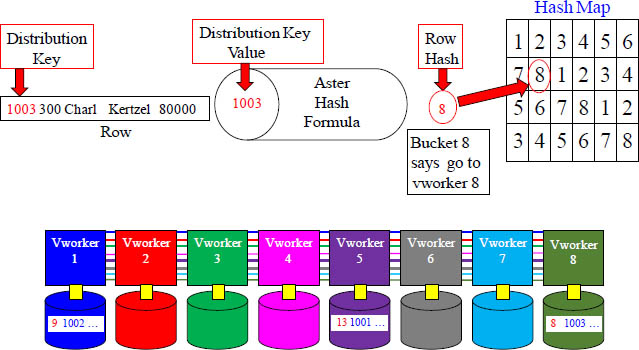
The above example hashed Emp_No 1003 (Primary Index value), and the output was a numeric number of 8. Aster counted over to bucket 8 in the Hash Map, and it has the number eight (8) inside that bucket. This means that this row will go to vworker 8.
A Review of the Hashing Process
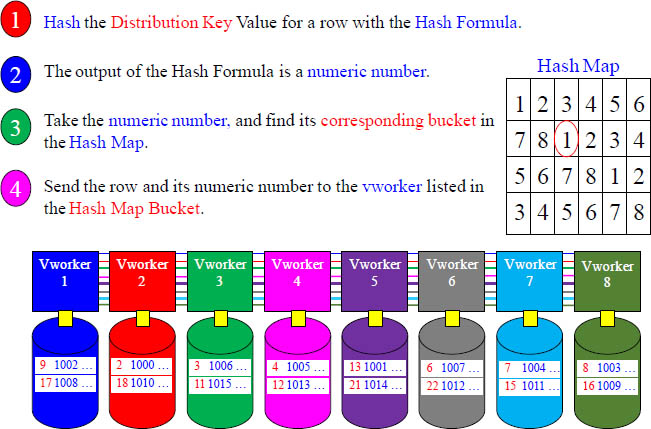
Take a look at the row hash for each row, and notice it corresponds with the Hash Map. Data that is unique will provide perfectly even distribution.
Like Data Hashes to the Same vworker
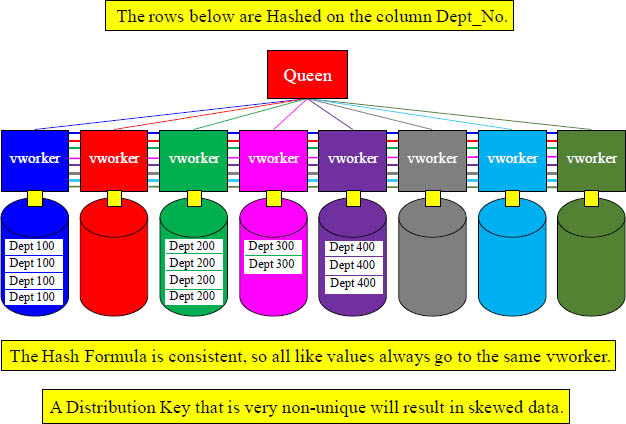
Aster Hashes the Distribution Key with a single formula, and then distributes the rows among the vworkers. All like values go to the same vworker. Be careful what Distribution Key you choose.
Distribution Key Data Types
Distribution Keys can only be these data types:
• int
• smallint
• bigint
• numeric
• numeric(p)
• numeric(p,a)
• text
• varchar
• varchar(n)
• UUID
• bytea
Above are the distribution key data types.
Run ANALYZE to COLLECT STATISTICS on a Table
ANALYZE collects statistics about the contents of tables and stores the results in Aster internal tables. The query planner then uses these statistics to help determine the most efficient execution plans for queries.
You should run the ANALYZE statement after all data loads. You should also consider running ANALYZE after modifying tables. This includes:
• CREATE TABLE AS SELECT (CTAS)
• INSERT
• UPDATE
• DELETE
• COPY or ALTER
Analyze runs three ways:
1. With no parameter, ANALYZE examines all tables in the current database.
2. With a tablename parameter, ANALYZE examines only that table.
3. With tablename and column parameters, only the statistics for those columns are collected.
Some Examples of ANALYZE
This example will ANALYZE all tables in the current database. This can be turned off by the DBA.
ANALYZE ;
This example will ANALYZE all columns in the Employee_Table.
ANALYZE Employee_Table ;
This example will ANALYZE only the Employee_No column in the Employee_Table.
ANALYZE Employee_Table ( Employee_No) ;
This example will ANALYZE both the Employee_No and Dept_No columns in the Employee_Table.
ANALYZE Employee_Table ( Employee_No, Dept_No) ;
What Columns to Analyze
Aster allows you to Analyze (COLLECT STATISTICS) on all columns, but you can choose only the most important columns.
• All Distribution Keys of a table.
• Columns used in the WHERE or ON condition of a join.
• All columns of small tables.
• Columns that frequently appear in WHERE search conditions.
• Columns that are indexed.
Analyze each time a table’s data changes by 10%.