
Chapter 7 – SQL-MapReduce
“A bird does not sing because it has the answers, it sings because it has a song.”
-Anonymous
MapReduce History
MapReduce is a programming framework which is used to process enormous data sets. It began getting taken seriously in 2004 when Google released a paper “MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat”.
Since then, its use has grown exponentially, and today many of the largest companies in the world are using MapReduce technology in the form of Hadoop or Aster Data to solve some very complex problems traditional databases would find difficult. While MapReduce works elegantly in some situations, it is not a replacement for a traditional database. However, if implemented correctly, it can complement one beautifully.
MapReduce was designed to process extremely large data sets such as clickstream data from a website, large text files (html, logs etc.), or perhaps a digital version of every book housed in the Library of Congress! Google uses MapReduce to perform analytics on data entered into its search engine. If you have ever used the search engine of a tiny company named Google, your data has most likely been run through MapReduce!
What is MapReduce?
MapReduce does what it says it is going to do. It maps data and then reduces data by utilizing a Master node and one or more Worker nodes.
The Map Step
The Master node will take input data and it will slice and dice it into smaller sub-problems and then distributes these to Worker nodes. The Master node is also know as the Queen node in Aster Data.
The Worker nodes will then take these sub-problems and may decide to break these down into smaller sub-problems, but eventually they finish their processing and send their individual answers back to the Master node.
The Reduce Step
The Master node then takes all of the answers from the Worker nodes and combines them to form the answer to the problem which needed to be solved.
What is SQL-MapReduce?
SQL-MapReduce (SQL-MR) was created by Aster Data and it is referred to as an "In-Database MapReduce framework".
It is implemented using two basic steps.
|
Programmers write SQL-MR functions and then load them inside Aster Data using the Aster Command Line Tools (ACT). |
|
Programming languages which are supported are: |
|
• Java • C# • C++ • Python • R |
|
Analysts then call the SQL-MR functions using familiar SELECT query syntax, and data is returned as a set of rows. |
SQL-MapReduce Input
SQL-MapReduce will always take a set of rows as input. This could be one or more tables in a database, the results of a SELECT statement, or the output from another SQL-MR function. SQL-MR can also take input parameters from the calling query.
Aster Data 5.0 SQL-MR can accept multiple inputs gaining these benefits:
• Allows rows from different data sets to be analyzed in more complex ways inside the SQL-MR function.
• Avoid the issues of the past which required users to have to JOIN and UNION answer sets together to get only one input.
• Avoiding this additional processing reduces memory consumption and increases performance.
There are two types of input into SQL-MR:
1. Partitioned inputs which are split among the workers based on the PARTITION BY ANY or PARTITION BY clause.
2. Dimensional inputs using the DIMENSION keywords.
The function will combine the partitions and dimensions from multiple data sets and then create a single nested data set against which the SQL-MR function will run.
SQL-MapReduce Output
Here is the easy part. The output from a SQL-MR function will always be a single answer set.
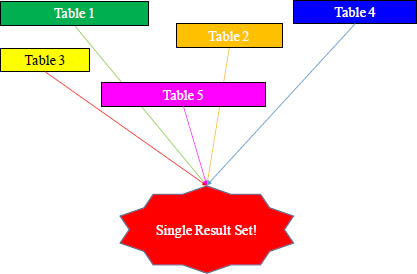
Using five tables as input into an Aster Data function may result in an Employee of the Year award.
Subtle SQL-MapReduce Processing
There are a few subtle events which can occur in SQL-MapReduce on Aster Data.
1. The data is partitioned by the partitioning attribute.
2. **Data is distributed to the worker nodes.
3. The Worker nodes return their result sets to the Queen node.
4. The Queen then processes the answer set which may include some additional calculations. For example, if the Workers have produced a sum for their records, the Queen will then need to perform a sum on the Worker’s sum to product a final answer set.
**If the data on your workers is already distributed on the workers the same as in your SQL-MR function, then no data distribution is needed, and you get a performance boost!
Aster Data Provides an Analytic Foundation
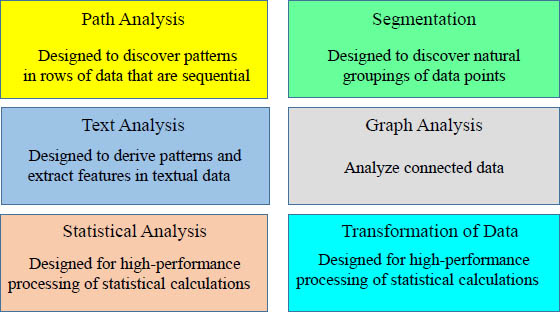
Over 50+ out-of-the-box analytic modules
Aster Data comes with over 50 MapReduce functions that have already been prepared for users. Above are just some of the categories that have MapReduce functions that come automatically with Aster Data.
Path Analysis
Path Analysis
Designed to discover patterns in rows of data that are sequential
nPath: complex sequential analysis for time series and behavioral pattern analysis.
nPath Extensions: count entrants, track exit paths, count children, and generate subsequences.
Sessionization: identifies sessions from time series data in a single pass.
Attribution: operator to help ad networks and websites to distribute "credit“.
Text Analysis
Text Analysis
Designed to derive patterns and extract features in textual data
Text Parser: Counts occurrences of words, identifies their roots, tracks relative positions of words, and even tracks multi-word phrases.
nGram: Generates ngrams based on textual input.
Levenshtein Distance: Computes the distance between two words.
Text Classifier: Classifies text content into categories (e.g. complaints, spam).
Sentiment Analysis: Classifies content to be either positive or negative (for product review, customer feedback).
Entity Recognition: identifies addresses, phone numbers, and names from textual data.
Statistical Analysis
Statistical Analysis
Designed for high-performance processing of statistical calculations
Histogram: Function to provide capability of generating based on history.
Approximate percentiles and distinct counts: Calculates percentiles and counts within a specific variance.
Correlation: Calculation that characterizes the strength of the relation between different columns.
Regression: Performs linear or logistic regression between an output variable and a set of input variables.
Averages: Calculate moving, weighted, exponential or volume weighted averages over a window of data.
GLM: Generalized linear model function that supports logistic, linear, log-linear and regression models.
PCA: (Principal Component Analysis) transforms a set of observations into a set of uncorrelated variables.
Segmentation (Data Mining)
Segmentation
Designed to discover natural groupings of data points
k-Means: Designed to cluster data into a specified number of groupings.
Canopy: Partitions data into overlapping subsets within which k-means is performed.
Minhash: Buckets highly-dimensional items for further cluster analysis.
Basket analysis: Creates configurable groupings of related items from transaction records in single pass.
Collaborative Filter: Predicts the interests of a user by collecting interest information from many users.
Decision Trees: Native implementation of parallel random forests.
K-Nearest Neighbor: Principal Component Analysis that transforms a set of observations into a set of uncorrelated variables.
Naïve Bayes Classifier: Simple probabilistic classifier that applies the Bayes Theorem to data sets.
Graph Analysis
Graph Analysis
Analyze connected data
nTree: Provides new function for performing operations on tree hierarchies.
Single shortest path: Will find the shortest paths from a given vertex to all the other vertices in the graph.
Beta: Page rank, eigenvector centrality, local clustering coefficient, shape finding.
Transformation of Data
Transformation of Data
Designed for high-performance processing of statistical calculations
Unpack: Extracts nested data for further analysis.
Pack: Compresses multi-column data into a single column.
Antiselect: Returns all columns except for specified columns.
Multicase: Case statement that supports row match for multiple cases.
Pivot: Convert columns to rows or rows to columns.
Apache log parser: Generalized tool for parsing Apache logs.
Sessionize
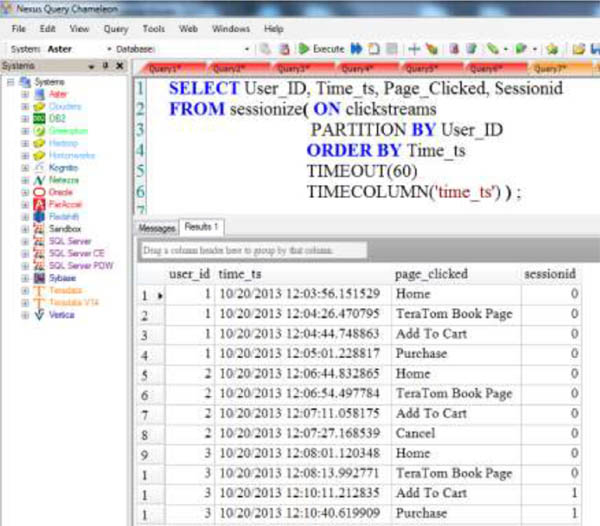
The SQL-MR function Sessionize shows a different session if a particular user took more than 60 seconds between clicks. If more than 60 seconds passed, it is assumed that the user left and a new session opened.
Tokenize
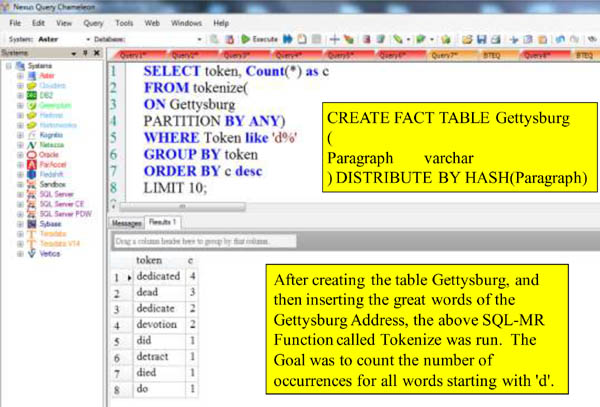
The SQL-MR function Tokenize works with text fields. Tokenize can take an input stream of words, optionally group them, and then deliver the individual words and counts for the each word appearance.
SQL-MapReduce Function . . . nPath

Aster Data nPath is a SQL-MapReduce function which is a close cousin of the programming function regular expressions with one major difference.
Regular Expressions are used to match a sequence of text in a string.
nPath is used to match a sequence of rows in a database!
Aster Data uses regular expressions for matching for three basics reasons:
1. The are very flexible and can be used to match a very simple pattern or a very complex pattern.
2. They are understood by a wide variety of people and used in probably every programming language, so the learning curve is small.
nPath SELECT Clause
SELECT *
FROM npath
(
ON SQL_CLASS.Emp_Job_Table
PARTITION BY Job_No
ORDER BY Emp_No
MODE( NONOVERLAPPING )
PATTERN( 'Emp.Job' )
SYMBOLS(Emp_no > 0 as Emp,
Job_No > 0 Job)
RESULT( First(Job_No of Emp) as Job_Number,
First(Emp_No of Job) as Employee_Number)
) ORDER BY Job_Number;
The SELECT statement in usually used to SELECT columns from a table or view. In this case, the SELECT statement is used to SELECT columns from a SQL-MapReduce function.
nPath is the name of the SQL-MR function which is being selected FROM.
This is the beauty of SQL-MapReduce! It uses familiar query syntax to access powerful analytic functions.
nPath ON Clause
SELECT *
FROM npath
(
ON SQL_CLASS.Emp_Job_Table
PARTITION BY Job_No
ORDER BY Emp_No
MODE( NONOVERLAPPING )
PATTERN( 'Emp.Job' )
SYMBOLS(Emp_no > 0 as Emp,
Job_No > 0 Job)
RESULT( First(Job_No of Emp) as Job_Number,
First(Emp_No of Job) as Employee_Number)
) ORDER BY Job_Number;
The ON clause defines the number of input streams into the nPath function. The on clause can reference a table, a view, and even a query. If you use a query as input, make sure you enclose the query in single quotes.
nPath PARTITION BY Expression
SELECT *
FROM npath
(
ON SQL_CLASS.Emp_Job_Table
PARTITION BY Job_No
ORDER BY Emp_No
MODE( NONOVERLAPPING )
PATTERN( 'Emp.Job' )
SYMBOLS(Emp_no > 0 as Emp,
Job_No > 0 Job)
RESULT( First(Job_No of Emp) as Job_Number,
First(Emp_No of Job) as Employee_Number)
) ORDER BY Job_Number;
The PARTITION BY expression defines how your data is partitioned before it is searched. SQL-MapReduce will only look at pattern matches for rows which are in the same partition.
If you have multiple inputs into the function, each input must be partitioned the same way.
You can have one or more PARTITION BY expressions in your functions.
nPath DIMENSION Expression
SELECT *
FROM nPath
(
ON SQL_CLASS.Web_Ads_Table PARTITION BY user_id ORDER BY dt
ON SQL_CLASS.Clicks_Table PARTITION BY user_id ORDER BY dt
ON SQL_CLASS.Radio_Ads_Table DIMENSION ORDER BY dt
MODE(NONOVERLAPPING)
SYMBOLS(true as ad, true as click, true as radio_ad)
PATTERN('(ad|radio_ad)*.click')
RESULT(COUNT(* of ad) as ads_before_click, COUNT(* of click) as num_click)
);
Using the DIMENSION expression will make input available on every partition.
It requires that you have at least two inputs. You can have zero or more DIMENSION expressions while you have to have at least one PARTITION BY expression.
Using the DIMENSION expression also requires your function call to have at least two ON clauses: One ON clause for the PARITITION BY expression and one ON clause for the DIMENSION expression.
nPath ORDER BY Expression
SELECT *
FROM npath
(
ON SQL_CLASS.Emp_Job_Table
PARTITION BY Job_No
ORDER BY Emp_No ASC
MODE( NONOVERLAPPING )
PATTERN( 'Emp.Job' )
SYMBOLS(Emp_no > 0 as Emp,
Job_No > 0 Job)
RESULT( First(Job_No of Emp) as Job_Number,
First(Emp_No of Job) as Employee_Number)
) ORDER BY Job_Number;
The ORDER BY expression specifies how the rows are ordered on the Workers. Descending order is the default. Use ASC after the ORDER BY expression to sort in ascending order.
nPath MODE Clause has Overlapping or NonOverlapping
SELECT *
FROM npath
(
ON SQL_CLASS.Emp_Job_Table
PARTITION BY Job_No
ORDER BY Emp_No ASC
MODE( NONOVERLAPPING )
PATTERN( 'Emp.Job' )
SYMBOLS(Emp_no > 0 as Emp,
Job_No > 0 Job)
RESULT( First(Job_No of Emp) as Job_Number,
First(Emp_No of Job) as Employee_Number)
) ORDER BY Job_Number;
• Overlapping mode will return every possible instance of a pattern match. If rows 1 and 2 match the pattern, then nPath will continue its search on rows 2 and 3.
• NonOverlapping mode says once a match is found, nPath will begin searching for the next pattern match at the next row. If row 1 and 2 match, then nPath will continue its pattern search on rows 3 and 4.
nPath PATTERN Clause
SELECT *
FROM npath
(
ON SQL_CLASS.Emp_Job_Table
PARTITION BY Job_No
ORDER BY Emp_No ASC
MODE( NONOVERLAPPING )
PATTERN( 'Emp.Job' )
SYMBOLS(Emp_no > 0 as Emp,
Job_No > 0 Job)
RESULT( First(Job_No of Emp) as Job_Number,
First(Emp_No of Job) as Employee_Number)
) ORDER BY Job_Number;
The Pattern clause defines the pattern which nPath searches on using these elements:
• Symbols - The symbols used are Emp and Job and are defined in the SYMBOLS clause.
• Operators - The operator used is the dot between Emp and Job. The dot can be translated as "is followed by" and looks for a pattern match on Emp followed by match on Job.
• Parentheses - These are used to nest patterns and are not pictured. (Pattern1 (Pattern 2) )
• Anchors — "^" and "$" define the start and the end of a sequence respectively. "^" is always used at the start of a sequence and "$" is always used at the end. Also, not pictured.
Pattern Operators
You can use the following operators in a pattern:
. The dot is known as the cascade operator. For A.B it means we have a pattern match when symbol A is followed by symbol B.
| The pipe is the or alternative operator. A|B would mean when either symbol A or B are true, then we have a match.
? Is a frequency operator and means the symbol occurs, at most, once.
* Is a frequency operator and means the symbol occurs zero or more times.
+ Is a frequency operator and means the symbol must occur at least once.
Pattern operators follow an order of precedence.
Pattern Operators Order of Precedence
Any patterns in parenthesis are calculated first.
Then, pattern operators follow this order.
![]() The frequency operators ?, * and + are figured first.
The frequency operators ?, * and + are figured first.
![]() The cascade or "dot" operator.
The cascade or "dot" operator.
![]() The or / alternative operator if determined.
The or / alternative operator if determined.
Here are some examples.
A.B? - B occurs, at most, once preceded by A. Equivalent to A.(B?).
A|B+ - B occurs at least once or A. Equivalent to A|(B+).
C|A.B - A is followed by B or C. Equivalent to C|(A.B).
A+.B*.C|D - A occurs at least once followed by B which occurs zero or more times followed by C or D. Equivalent to (A+B*.C)|D
A+.(B*.C)|D - B occurs zero or more times followed by C preceded by A occurring at least once or D. Equivalent to (A+(B*.C))|D.
Matching Patterns Which Repeat
If you match any section of a pattern which occur multiple times, you can use the following syntax:
pattern-section{n} or pattern-section{n,} are equivalent and it means the pattern should repeat n number of times.
pattern-section{n,m} means that a patterns should repeat n number of time, but no more than m number of times.
A.B|(C.D){2}
The pattern C.D must occur two times in order for a match to happen. You can also write this pattern section as (C.D){2,}
(A.B){3,6}|C.D
The pattern A.D must occur at least three times, but no more than six.
nPath SYMBOLS Clause
SELECT *
FROM npath
(
ON SQL_CLASS.Emp_Job_Table
PARTITION BY Job_No
ORDER BY Emp_No ASC
MODE( NONOVERLAPPING )
PATTERN( 'Emp.Job' )
SYMBOLS(Emp_no > 0 as Emp,
Job_No > 0 Job)
RESULT( First(Job_No of Emp) as Job_Number,
First(Emp_No of Job) as Employee_Number)
) ORDER BY Job_Number;
Symbols are the rows of a pattern. Multiple symbols are separated by commas. In the example above, we have two symbols Emp which is any employee number greater than zero, and Job which is any job number greater than zero.
Symbols have different context depending on where they are used. If the symbol is used in a pattern, then it represents the row of a type which you are performing a pattern search on.
If the symbol is used in the RESULTS clause, it represents all the rows which match the definition in the SYMBOLS clause as found in the pattern you are searching.
nPath RESULTS Clause
SELECT *
FROM npath
(
ON SQL_CLASS.Emp_Job_Table
PARTITION BY Job_No
ORDER BY Emp_No ASC
MODE( NONOVERLAPPING )
PATTERN( 'Emp.Job' )
SYMBOLS(Emp_no > 0 as Emp,
Job_No > 0 Job)
RESULT( First(Job_No of Emp) as Job_Number,
First(Emp_No of Job) as Employee_Number)
) ORDER BY Job_Number;
The RESULTS clause defines the columns used in the output of the function. Each column is separated by a comma.
The RESULTS clause is evaluated one-time for each matched pattern value per partition.
The alias is the name of the columns which will be returned, and you can refer to them in your SELECT clause.
Adding an Aggregate to nPath Results
The RESULTS clause of the nPath function will support the COUNT, SUM, MIN, MAX, and AVG SQL aggregates.
In addition, the following nPath aggregates are allowed:
• FIRST is the FIRST ( Column Of A ): Gets the first column in the pattern match for the symbol A.
• LAST is the LAST ( Column Of A): The last row which maps to symbol A in the pattern match.
• FIRST_NOTNULL as an example FIRST_NOTNULL (Column Of A): Gets the first non-NULL column in the pattern match for symbol A.
• LAST_NOTNULL as an example LAST_NOTNULL (Column A): Gets the last non-NULL column in the pattern match for symbol A.
• ACCUMULATE as an example ACCUMULATE (Column of A): This will concatenate every column which matches pattern A.
Adding an Aggregate to nPath Results (Continued)
• MAX_CHOOSE
MAX_CHOOSE(ColumnA, ColumnB of A): After determining the max value for ColumnA, the corresponding ColumnB value will be displayed.
MAX_CHOOSE(Max_Students, Course_Name of A) would return the Course Name for the course which has the maximum amount of student per partition, matching the pattern for symbol A.
• MIN_CHOOSE
MIN_CHOOSE(ColumnA, ColumnB of A): Does the same thing as MAX_CHOOSE, but uses the minimum value for ColumnA instead of the maximum value.
• DUPCOUNT
DUPCOUNT(<expression> OF ANY <list of symbols>): For each row in the <list of symbols> sequence, this aggregate will count the number of times the value has appeared preceding the row.
• DUPCOUNTCUM
DUPCOUNTCUM(<expression> OF ANY <list of symbols>): This will count the number of duplicate values of the <expression> which appear immediately preceding the row. When the <expression> used also matches the ORDER BY <expression>, it is the same as performing ROW_NUMBER() - DENSE_RANK() OLAP.
SQL-MapReduce Examples - Use Regular SQL
SELECT Cast(Job_Number AS VARCHAR(10))
FROM npath
(
ON SQL_CLASS.Emp_Job_Table
PARTITION BY Job_No
ORDER BY Emp_No ASC
MODE( NONOVERLAPPING )
PATTERN( 'Emp.Job' )
SYMBOLS(Emp_no > 0 as Emp, Job_No > 0 Job)
RESULT( First(Job_No of Emp) as Job_Number, First(Emp_No of Job) as Employee_Number)
) ORDER BY Job_Number
WHERE Job_Number = '10030';
Everything outside of the SQ-MR function behaves like normal SQL. You can have clauses and expressions such as WHERE, GROUP BY, HAVING, ORDER BY, LIMIT, and OFFSET.
SELECT * will select everything from the RESULTS clause, but you can also select individual columns such as Job_Number in this example and perform functions on them like TRIM, SUBSTRING, OR CAST.
SQL-MapReduce Examples - Create Objects
CREATE VIEW SQL_VIEWS.nPath_v AS
(
SELECT Job_Number, Employee_Number
FROM npath
(
ON SQL_CLASS.Emp_Job_Table
PARTITION BY Job_No
ORDER BY Emp_No ASC
MODE( NONOVERLAPPING )
PATTERN( 'Emp.Job' )
SYMBOLS(Emp_no < 0 as Emp, Job_No < 0 Job)
RESULT( First(Job_No of Emp) as Job_Number, First(Emp_No of Job) as
Employee_Number)
) ORDER BY Job_Number
);
You can create objects such as tables and views from SQL-MR functions you create. Just make sure you enclose the entire function in parenthesis.
SQL-MapReduce Examples - Subquery
SELECT Cast(Job_Number AS VARCHAR(10))
FROM npath
(
ON SQL_CLASS.Emp_Job_Table
PARTITION BY Job_No
ORDER BY Emp_No ASC
MODE( NONOVERLAPPING )
PATTERN( 'Emp.Job' )
SYMBOLS(Emp_no > 0 as Emp, Job_No > 0 Job)
RESULT( First(Job_No of Emp) as Job_Number, First(Emp_No of Job) as Employee_Number)
) ORDER BY Job_Number
WHERE Job_Number = '10030';
Everything outside of the SQ-MR function behaves like normal SQL. You can have clauses and expressions such as WHERE, GROUP BY, HAVING, ORDER BY, LIMIT, and OFFSET.
SELECT * will select everything from the RESULTS clause, but you can also select individual columns such as Job_Number in this example and perform functions on them like TRIM, SUBSTRING, OR CAST.
SQL-MapReduce Examples - Query as Input
SELECT *
FROM ANTISELECT
(ON (SELECT * FROM SQL_VIEWS.Employee_V)
EXCLUDE('lname', 'fname'));
You don't have to use a table or view as input. You can use a query!
Here, we are using the ANTISELECT function which takes the following parameters.
ON is the input. This can be a table a view or in the case SQL. EXCLUDE is used to simply not return the columns you specify in the result set.
Had we used EXCLUDE('Lname', 'Fname'), the function would have returned an error saying the columns are not present in the input table. Keep in mind these functions columns are case sensitive.
SQL-MapReduce Examples - Nesting Functions
SELECT *
FROM ANTISELECT
(ON (SELECT *
FROM ANTISELECT
(ON (SELECT * FROM SQL_VIEWS.Employee_v)
EXCLUDE ('fname'))
)
EXCLUDE('lname')
);
It is possible to nest two functions together. Remember, the ON clause is used to define inputs into the functions. In this case, the input is another function!
SQL-MapReduce Examples - Functions in Derived Tables
SELECT *
FROM
( SELECT Product_Id, Sale_Date, Daily_Sales
FROM SMAVG
(ON SQL_CLASS.Sales_Table
PARTITION BY Product_Id
ORDER BY Daily_Sales
WINDOW_SIZE(3) ) ) derived_table;
This query uses the Simple Moving Average function which allows us to see an average of our daily sales for each product id, resetting every three rows which, in this case, correspond to days.
Running this query by itself would be too easy, so we've decided to put it in its own derived table.
SQL-MapReduce Examples - SMAVG
SELECT Product_Id, Sale_Date, Daily_Sales
FROM SMAVG
(ON SQL_CLASS.Sales_Table
PARTITION BY Product_Id
ORDER BY Daily_Sales
WINDOW_SIZE(3)
RETURN_ALL('true'));
PARTITION BY is the columns your data is partitioned by.
ORDER BY is how the data is sorted inside the partition.
WINDOW_SIZE tells the function after how many rows to reset and start new calculations.
RETURN_ALL if set to true will return all columns including NULL for the very first window size.
COLUMN_NAMES (not pictured) are the column names you can defined when exponential moving average is required. If this is omitted, all input rows are returned "as is".
SQL-MapReduce Examples - Pack Function
SELECT *
FROM PACK
(
ON SQL_CLASS.Employee_Table
COLUMN_DELIMITER('|')
PACKED_COLUMN_NAME('my_packed_column')
INCLUDE_COLUMN_NAME('false')
COLUMN_NAMES('employee_no', 'dept_no', 'last_name', 'first_name', 'salary')
);
This will returns packed data in the form of column values separated by whatever delimiter you choose. Instead of writing SELECT statements, which cast numbers as text and use concatenation to delimit columns, a user can use this function.
This helps avoid SQL such as this where Column2 is an INTEGER column.
SELECT Column1 || '|' || TRIM(CAST (column2 As char10)) || '|' || Column2 FROM TableA;
Use the UNPACK function to unpack a column.
SQL-MapReduce Examples - Pack Function (Continued)
SELECT *
FROM PACK
(
ON SQL_CLASS.Employee_Table
COLUMN_DELIMITER('|')
PACKED_COLUMN_NAME('my_packed_column')
INCLUDE_COLUMN_NAME('false')
COLUMN_NAMES('employee_no', 'dept_no', 'last_name', 'first_name', 'salary')
);
COLUMN_DELIMITER is the character you've chosen to delimit your columns.
PACKED_COLUMN_NAME is the name you're giving to your final column.
INCLUDE_COLUMN_NAME if this is set to true, it will prepend your column name before your column value.
COLUMN_NAMES are the columns from the table specified in your ON clause.
Only the ON clause and the PACKED_COLUMN_NAME clause are required.
SQL-MapReduce Examples - Pivot Columns
SELECT * FROM PIVOT
(ON SQL_CLASS.Sales_Table
PARTITION BY product_id
PARTITIONS('product_id')
ROWS(7)
METRICS('daily_sales'));
The Pivot function will take table data and convert it into a new schema based on the arguments which are given. It handles Nulls.
PARTITION BY will define your rows.
PARTITIONS should have the same columns as your PARTITION BY statement, but they can be in a different order.
ROWS is the maximum number of rows which can be in each partition. In the example above, if we have more rows than 7 in a partition, then they are not shown. If we have less, then NULL values will be added to our answer.
PIVOT_KEYS & PIVOT_COLUMNS (not shown) You will either use PIVOT_KEY and PIVOT_COLUMNS together or you will use the ROWS clause. They cannot be combined. Any row that has a pivot_column value which is not in the pivot key will be omitted. NULL will be added if a partition does not contain a pivot key value.
METRICS contain the columns you want to pivot.
Workshop: Create This Table
CREATE FACT TABLE bank_web_clicks
(
customer_id INTEGER,
session_id INTEGER,
page VARCHAR(100),
datestamp TIMESTAMP
) DISTRIBUTE BY HASH (customer_id);
Create the table above using your Nexus. You can also do this in your ACT terminal on Linux. Create this in your beehive database.
Login to your GNOME Terminal

Create the table above using your Nexus. You can also do this in your ACT terminal on Linux. Create this in your beehive database.
Login to your Linux
Create the table above using your Nexus. You can also do this in your ACT terminal on Linux. Create this in your beehive database.
Using the GNOME Terminal Unzip the bank_web_data.zip

You have just unzipped the aster data bank data. Turn the page so we can load the data!
Use the Function ncluster_loader to Load the Bank Data
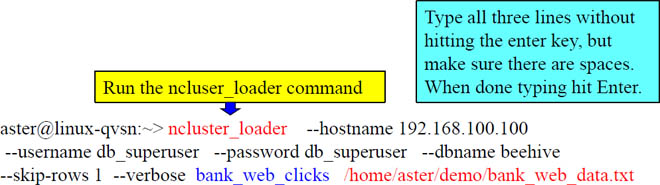
By running the command above, you just loaded over 1 million rows inside the bank_web_clicks table!
CREATE FACT TABLE bank_web_clicks
(
customer_id INTEGER,
session_id INTEGER,
page VARCHAR(100),
datestamp TIMESTAMP
) DISTRIBUTE BY HASH (customer_id);
At the Linux prompt, run the ncluser_loader command above. If it does not work, try it again.
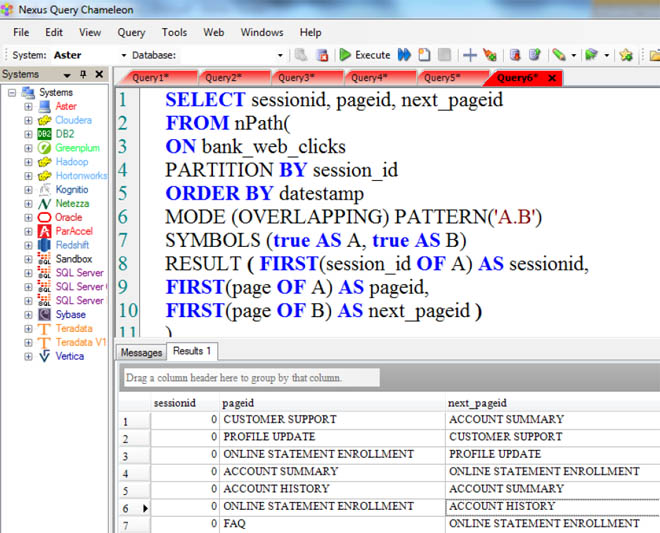
Run this nPath Map Reduce Function on your Table

The above nPath function is an example that works. Let's turn the page and check out our results on Nexus.
nPath in Action
Operators at their Simplest
Operator |
What it does |
. |
A.B means 'A' is followed by 'B' |
| |
A|B means 'A' OR 'B' |
? |
Occurs at most once (0 to 1 occurrence) |
* |
Occurs zero or more times |
+ |
Occurs at least once |
Operators are matched from left-to-right, and as many rows as possible that can fit in the wildcards will be retrieved.
Pattern

A.B? - B occurs, at most, once preceded by A. Equivalent to A.(B?).
A|B+ - B occurs at least once or A. Equivalent to A|(B+).
C|A.B - A is followed by B or C. Equivalent to C|(A.B).
A+.B*.C|D - A occurs at least once followed by B which occurs zero or more times followed by C or D. Equivalent to (A+B*.C)|D
A+.(B*.C)|D - B occurs zero or more times followed by C preceded by A occurring at least once or D. Equivalent to (A+(B*.C))|D.
Accumulate
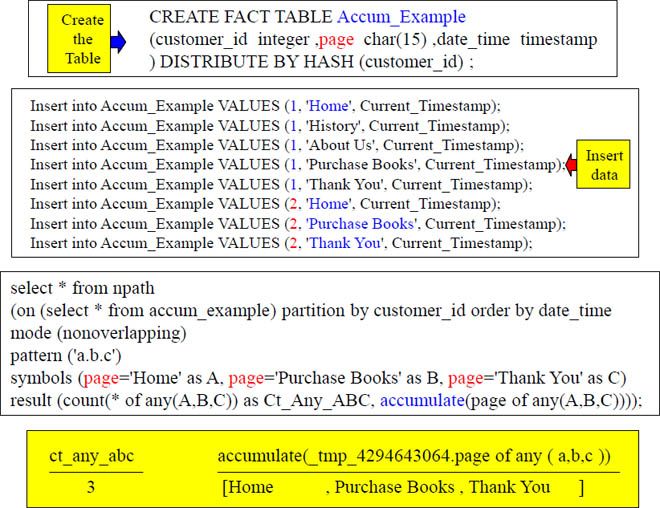
Show me a count and accumulate the pages for any customer who went from the Home page directly to the Purchase Books page and then went directly to the Thank You page (because they paid for a book).
Accumulate With All Pages
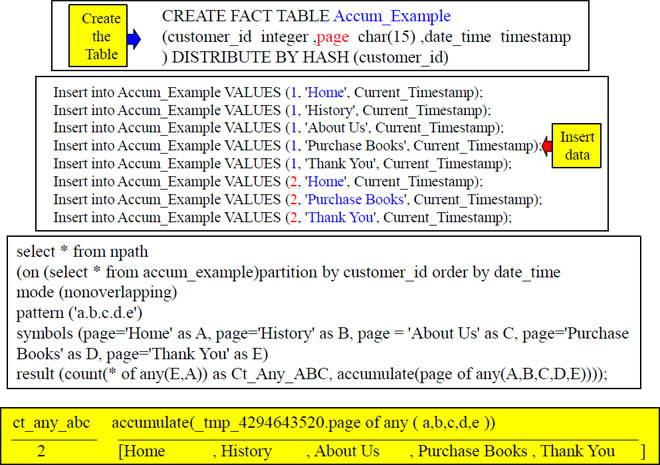
Accumulate showed that we did have a path through Home, History, About Us, Purchase Books and Thank You. It also accumulated those pages for us.
Accumulate – nPath with a WHERE Clause
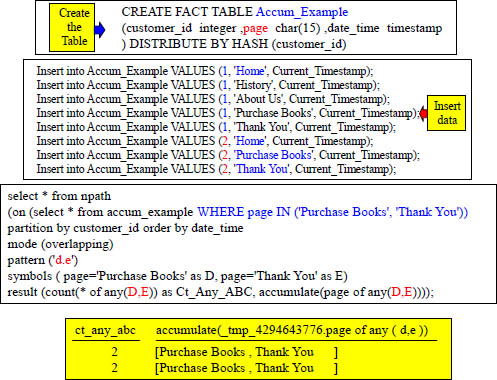
The WHERE clause filtered out the rows before the calculation. Now, we have two rows returning.
SQL-MapReduce Examples - Path Generator
SELECT *
FROM PATH_GENERATOR
(
ON (SELECT user_id, dt, path FROM Clicks_Path_v)
SEQ('path')
DELIMITER('/')
) ORDER BY 1;
The Path Generator function with take a sequence and it will show you all possible subsequences. In this case, the sequence we are looking for is the path a user could take starting from the home page on our website and then we'll generate all the possible subpaths or subsequences.
The ON clause in this instance has our three original columns user_id, dt and path as the input. The output will keep the values of the original columns and two columns will be appended to the data. They are prefix and sequence.
• The prefix column will be a list of all subsequences or subpaths in our case.
• The sequence is will list the sequence or path again.
Both the path sequence and the subpath subsequence will be prepended with the caret character ^. The ^ character simply let's us know we are dealing with a sequence.
SQL-MapReduce Examples - Path Generator (Continued)
SELECT *
FROM PATH_GENERATOR
(
ON (SELECT user_id, dt, path FROM Clicks_Path_v)
SEQ('path')
DELIMITER('/')
)
ORDER BY 1;
The SEQ clause is required takes as an argument the column which for which subsequences will be generated.
The DELIMITER clause is optional, and this represents the delimiter in your path. Since we are dealing with URLs, we want to set something other that comma which is the default delimiter.
SQL-MapReduce Examples - Path Generator (Continued)
The Path Generator function will create one row for each subsequence. So, given the input table below where path is the SEQ input (written SEQ('path') in the function).
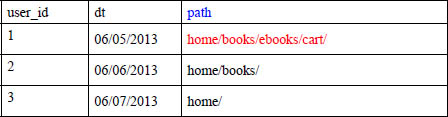
The path generator will create one row for each subsequence under the prefix column. It will also display the full sequence under the sequence column. In the case, of the first path, we will get four subsequences like this.
prefix |
sequence |
^, home |
home/books/ebooks/cart/ |
^, home, books |
home/books/ebooks/cart/ |
^, home, books, ebooks |
home/books/ebooks/cart/ |
^, home, books, ebooks, cart |
home/books/ebooks/cart/ |
SQL-MapReduce Examples - Path Generator (Continued)
Here is another example in Nexus how the prefix and sequence is displayed for the input home/books/ebooks/cart/ in the Path Generator function.
SELECT * FROM
PATH_GENERATOR
(ON (SELECT user_id, dt, path FROM Clicks_Path_v)
SEQ('path')
DELIMITER('/'))
ORDER BY 1;

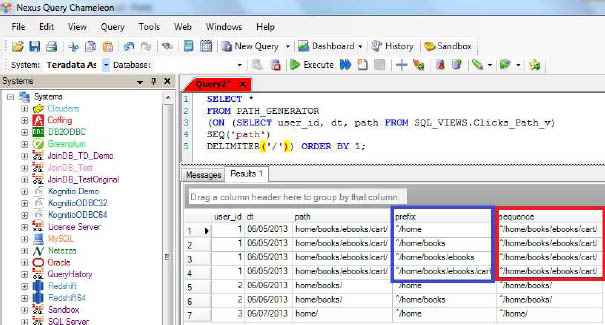
SQL-MapReduce Examples - Path Generator (Continued)
Here is another example in Nexus how the prefix and sequence is displayed for the input home/books/ebooks/cart/ in the Path Generator function.
SQL-MapReduce Examples - Linear Regression
Linear Regression is used to predict a relationships between two variables. For example, there may be a relationship between how many times a person visits an ATM and their ATM balance. Linear regression will help find a "best-fit" line to make sense of your data.
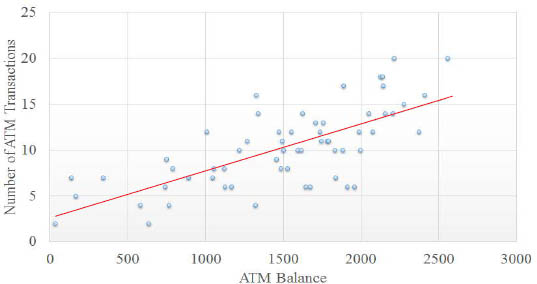
SQL-MapReduce Examples - Linear Regression (Continued)
SELECT *
FROM LINREG
(ON LINREGMATRIX
(ON (SELECT col1, col2, col3
FROM Stats_Table))
PARTITION BY 1);
The Linear Regression function uses the linear regression model to output coefficients based on an input matrix. The zeroth coefficient corresponding to the slope intercept (y=mx+b).
This is actually a nested function and calculates the input matrix based on the values returned from the LINREGMATRIX function. The LINREGMATRIX functions takes as input a table, view or sql.
Also, make sure that the last column of your input table, view or sql contains the Y component.
Finally, PARTITION BY 1 is a required clause because it tells Aster Data to submit the job to only one worker.
SQL-MapReduce Examples - Linear Regression (Continued)
Make sure the input is numeric data or you will receive an error. Also, if the input data set is perfectly linear in nature then you will also receive and error.
Below is an example of Linear Regression performed on the Stats_Table inside of Nexus.
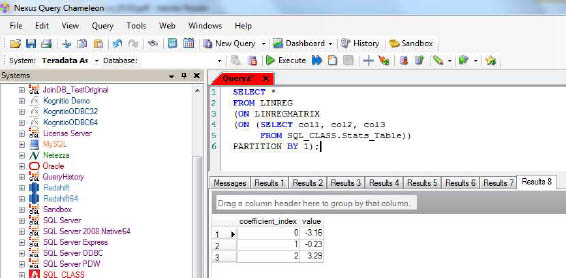
SQL-MapReduce Examples - Naive Bayes
Naive Bayes is a learning algorithm which allows you to create a model or training set of data based on known inputs. Once these inputs are "learned" you can then run new and different inputs through your model and it will predict the likelihood your data will be classified in a particular manner.
Three functions are involved in Naive Bays are:
• Naive Bayes Map takes your data and creates input for the Naive Bays Reduce Function.
• Naive Bayes Reduce creates your model based on input from the Naive Bayes Map function
• Naive Bayes Predict will then run new and different data through the model and produces output in the form of a probability that your new data falls under a particular classification.

SQL-MapReduce Examples - Naive Bayes (Continued)
The following query and training data will be used to create the model. We'll use this data later to predict the probability that a person with a particular set of characteristics own a home.
CREATE TABLE homeowner_model_table
(PARTITION KEY(class)) AS
SELECT * FROM NaiveBayesReduce(
ON(SELECT * FROM NaiveBayesMap(
ON HomeOwner_Table
RESPONSE('ownhome')
NUMERICINPUTS('age')
CATEGORICALINPUTS('employment_status', 'marital_status', 'education')))
PARTITION BY class);
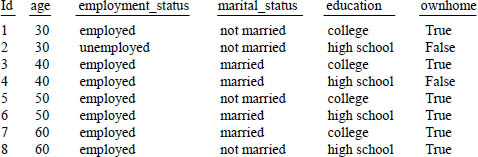
SQL-MapReduce Examples - Naive Bayes (Continued)
First, we'll take a look at the NaiveBayesMap function
which is used as input into the NaiveBayesReduce function.
SELECT * FROM NaiveBayesMap(
ON HomeOwner_Table
RESPONSE('ownhome')
NUMERICINPUTS('age')
CATEGORICALINPUTS('employment_status', 'marital_status', 'education')
The ON clause contains our original data set seen on the previous slide.
The RESPONSE clause has the final "result" which we will be trying to predict with our new data. In this case, the "ownhome" column tells us people who have a particular employment status, marital status, education and age tend to own a home. Valid data types for this column are varchar, int, short, long, or boolean. This clause is required.
At least one value for NUMERICINPUTS is required. You can specify the numeric columns as a list (col1, col2, col3), as a range ([1:3]) or a combination of both (col1, [2:3]).
At least one value for CATEGORICALINPUTS is required. Data types for this column must be varchar or integer. Categorical inputs can also be defined as a list, a range or both.
SQL-MapReduce Examples - Naive Bayes (Continued)
Now, we'll look at the NaiveBayesReduce function which the results from the NaiveBayesMap function as input.
CREATE TABLE SQL_CLASS.homeowner_model_table
(PARTITION KEY(class)) AS
SELECT * FROM NaiveBayesReduce(. . . Results of NaiveBayesMap Function . . .))
PARTITION BY class);
The PARTITION KEY is class, which is an output column of the NaiveBayesReduce function. Think of this as the classification column. In our case it will be true or false for home ownership.
We send the output of the NaiveBayesReduce function to a table which will serve as our model or training set. This table will be used in the NaiveBayesPredict function which we’ll explain on the next page.
SQL-MapReduce Examples - Naive Bayes (Continued)
Now that we have a training set of data we need to create a table with a new and different set of data. This table is defined below and will be the input into the next function.
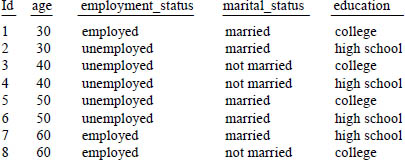
This is a new table we have created separate from the original.
The ownhome column is missing. That is because we don’t know this value and we will be using the NaiveBayesPredict function to predict it on the next page.
SQL-MapReduce Examples - Naive Bayes (Continued)
SELECT * FROM naiveBayesPredict
(ON HomeOwner_Candidates_Table
DOMAIN('192.168.100.100')
DATABASE('beehive')
USERID('beehive')
PASSWORD('beehive')
MODEL('homeowner_model_table')
IDCOL('id')
NUMERICINPUTS('age')
CATEGORICALINPUTS('employment_status', 'marital_status', 'education')
)ORDER BY 1;
The ON clause contains the table we just created on the previous page and is used as input into the naiveBayesPredict function.
The DOMAIN is the ip address of the QUEEN NODE.
DATABASE, USERID and PASSWORD contain our logon information to Aster Data.
The original training set of data is defined in the MODEL clause. SQL_CLASS.homeowner_model_table is the original table we created using the NaiveBayesMap and NaiveBayesReduce function.
SQL-MapReduce Examples - Naive Bayes (Continued)
SELECT * FROM naiveBayesPredict
(ON SQL_Class.HomeOwner_Candidates_Table
DOMAIN('192.168.100.100')
DATABASE('beehive')
USERID('beehive')
PASSWORD('beehive')
MODEL('SQL_CLASS.homeowner_model_table')
IDCOL('id')
NUMERICINPUTS('age')
CATEGORICALINPUTS('employment_status', 'marital_status', 'education')
)ORDER BY 1;

SQL-MapReduce Examples - Naive Bayes (Continued)
The output of the NaiveBayesFunction should look like something similar to this when completed.

These results tell us that home ownership is more likely for people with characteristics of testids 1 and 8. We could then act on this data such as sending out information on refinancing or home loans.
Join Aster, Teradata and Hadoop Tables; feed into MapReduce

Run Both of these Examples Together and Compare
SELECT sessionid, pageid, next_pageid
FROM nPath(
ON bank_web_clicks
PARTITION BY session_id
ORDER BY datestamp
MODE (OVERLAPPING) PATTERN('A.B')
SYMBOLS (true AS A, true AS B)
RESULT ( FIRST(session_id OF A) AS sessionid,
FIRST(page OF A) AS pageid,
FIRST(page OF B) AS next_pageid ) );
SELECT sessionid, pageid, next_pageid
FROM nPath(
ON bank_web_clicks
PARTITION BY session_id
ORDER BY datestamp
MODE (OVERLAPPING) PATTERN('A.B?')
SYMBOLS (true AS A, true AS B)
RESULT ( FIRST(session_id OF A) AS sessionid,
FIRST(page OF A) AS pageid,
FIRST(page OF B) AS next_pageid ) ) ;
Only bring back the first 200 rows on both answer sets and then compare them. What is different?
Run this nPath Map Reduce Function

The above nPath function is an example that works. Let’s turn the page and check out our results on Nexus.
nPath in Action

Another nPath Example
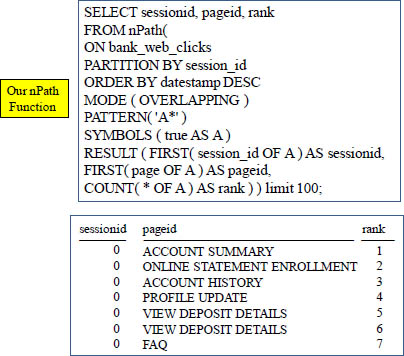
For each row, count the number of preceding rows including this row in a given sequence.
Finding Out What Functions You Have Installed
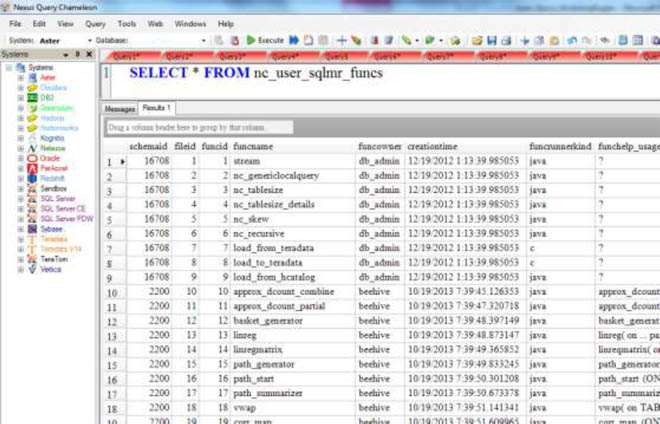
You can query the Data Dictionary residing on the Queen node to find out what SQL-MR functions you have installed. Just run the command:
SELECT * FROM nc_user_sqlmr_funcs ;
Workshop 1 – Fill in the x's
SELECT customer_id, lastpage, b_count
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'xxxx' )
SYMBOLS ( page='xxxx' as A)
RESULT ( FIRST( xxxx OF A ) AS customer_id,
last( page OF A ) AS lastpage,
COUNT( * OF A) AS b_count) ) ;
Fill in the xxxx patterns to display all customers who have gone to the page: 'FUNDS TRANSFER'. In the result I want to see:
• The first result of the customer_id
• The last page
• A Count (*)
Answer Workshop 1 - Fill in the x's
SELECT customer_id, lastpage, b_count
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id,
LAST( page OF A ) AS lastpage,
COUNT( * OF A) AS b_count) ) ;

Notice the above example and the results set. The PATTERN is set to 'A'. Then, the corresponding SYMBOLS defines 'A' as the column page='FUNDS TRANSFER'. So, the nPath function will look all rows with 'FUNDS TRANSFER' in the page column and those rows will be selected for the output. Then, the RESULT will choose the FIRST customer_id, the LAST page and a COUNT. Notice that these are the columns at the beginning of the SQL that we are selecting. All of this is only done after first PARTITIONING BY customer_id and then ORDERING by the column datestamp.
Workshop 2 – Fill in the x's
SELECT xxxx customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id)
) ;
Fill in the xxxx patterns to show all DISTINCT customer_ids who have gone to the page: 'FUNDS TRANSFER'. Give me the Distinct customer_ids.
Answer Workshop 2 – Fill in the x's
SELECT distinct customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id) )
;
Customer_id
__________
2258
7393
16094
31474
Great job! All you needed was the word DISTINCT.
Answer Workshop 2 – You Could Have Used a GROUP BY
SELECT distinct customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id) ) ;
SELECT customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id) )
GROUP BY customer_id;
Both queries above are equivalent, but Aster Data prefers the GROUP BY.
Workshop 3 – Add to the Query
SELECT DISTINCT customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id)
) ;
We just found all DISTINCT customer_ids who have gone to the page: 'FUNDS TRANSFER'. Now change the above query to:
• SORT the DISTINCT customer_ids in the result set by customer_id (in DESC Order).
Workshop 3 – Answer to Add to the Query
SELECT distinct customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id)
) ORDER BY customer_id DESC;
Customer_id
__________
32031
32030
32029
32027
Notice above that there are two ORDER BY statements. The first statement, ORDER BY datestamp, is how the data is to be sorted before nPath begins looking for 'FUNDS TRANSFER' in each row's page column. After the result set is ready to be returned, the second ORDER BY customer_id DESC is used to change the output order.
Workshop 4 – Fill in the x's
SELECT customer_id, lastpage, b_count
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'xxxx' )
SYMBOLS ( page='xxxx' as A,
page='xxxx' as B )
RESULT ( FIRST( customer_id OF ANY(xxxx) ) AS customer_id,
xxxx( page OF ANY(A,B) ) AS lastpage,
COUNT( * OF ANY(xxxx)) AS b_count) ) ;
Fill in the xxxx patterns to fulfill the following.
Show all customers who have gone to either page:
'FUNDS TRANSFER' or 'CUSTOMER SUPPORT'.
In the result, give me:
• The first result of the customer_id of both.
• The last page of both.
• A Count(*) of both.
Answer to Workshop 4 – Fill in the x's
SELECT customer_id, lastpage, b_count
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A|B' )
SYMBOLS ( page='FUNDS TRANSFER' as A,
page='CUSTOMER SUPPORT' as B )
RESULT ( FIRST( customer_id OF ANY(A,B) ) AS customer_id,
LAST( page OF ANY(A,B) ) AS lastpage,
COUNT( * OF ANY(A,B)) AS b_count) ) ;
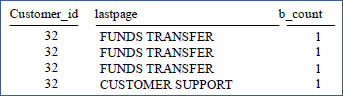
Notice the above example and the results set. The PATTERN is set to 'A|B'. The pipe symbol between A and B means A or B. It really means 'FUNDS TRANSFER' or 'CUSTOMER SUPPORT'. That is because the corresponding SYMBOLS defines 'A' as the column page='FUNDS TRANSFER' and 'B' as the column page='CUSTOMER SUPPORT'. Then, the RESULT will choose the FIRST customer_id of A or B (depending on which row was selected), the LAST page (depending on which row was selected), and a COUNT of 1 (depending on which row was selected).
Workshop 5 – Find that Customer
SELECT customer_id, session_id, first_page, last_page
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX;
Show all customers who have gone first to the 'FUNDS TRANSFER' page and then went to 'CUSTOMER SUPPORT'. In the result give me:
• The customer_id of both.
• The session_id of both.
• The First_Page of both.
• The Last_Page of both.
Answer to Workshop 5 – Find that Customer
SELECT customer_id, session_id, first_page, last_page
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A.B' )
SYMBOLS (page='ACCOUNT SUMMARY' as A,
page='FUNDS TRANSFER' as B)
RESULT ( FIRST( customer_id OF ANY(A,B) ) AS customer_id,
FIRST (page of ANY(A,B)) as first_page,
LAST(page of ANY(A,B)) as last_page,
LAST(session_id OF ANY(A,B)) as session_id) ) ;

Notice the above example and the results set. The PATTERN is set to 'A.B'. The period between A and B means A then B. It really means find a row where the page = 'FUNDS TRANSFER' and then check if the next page is 'CUSTOMER SUPPORT'. That is because the corresponding SYMBOLS defines 'A' as the column page='FUNDS TRANSFER' and 'B' as the column page='CUSTOMER SUPPORT'. You are really starting to get SQL-MR.
Workshop 6 – Change the MapReduce Function
SELECT customer_id, session_id, first_page, last_page
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A.B' )
SYMBOLS (page='ACCOUNT SUMMARY' as A,
page='FUNDS TRANSFER' as B)
RESULT ( FIRST( customer_id OF ANY(A,B) ) AS customer_id,
FIRST (page of ANY(A,B)) as first_page,
LAST(page of ANY(A,B)) as last_page,
LAST(session_id OF ANY(A,B)) as session_id) )
Order by 1,2 ;
Show all customers who have gone first to the page 'FUNDS TRANSFER' and then immediately went to 'CUSTOMER SUPPORT', but do so based on each customer in a particular session.
You have to make one minor change to the above! Good luck.
Answer to Workshop 6 – Change the MapReduce Function
SELECT customer_id, session_id, first_page, last_page
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id, session_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'B.A' )
SYMBOLS (page=CUSTOMER SUPPORT' as A,
page='FUNDS TRANSFER' as B)
RESULT ( FIRST( customer_id OF ANY(A,B) ) AS customer_id,
FIRST (page of ANY(A,B)) as first_page,
LAST(page of ANY(A,B)) as last_page,
LAST(session_id OF ANY(A,B)) as session_id) )
Order by 1,2 ;

You had to first PARTITION BY customer_id and then session_id.
Workshop 7 – Build the MapReduce Function
SELECT customer_id, session_id, first_page, last_page
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id, session_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'B.A' )
SYMBOLS (page=CUSTOMER SUPPORT' as A,
page='FUNDS TRANSFER' as B)
RESULT ( FIRST( customer_id OF ANY(A,B) ) AS customer_id,
FIRST (page of ANY(A,B)) as first_page,
LAST(page of ANY(A,B)) as last_page,
LAST(session_id OF ANY(A,B)) as session_id) )
Order by 1,2 ;
Change the above to show me all customers who went to 'ACCOUNT SUMMARY' and then went to FUNDS TRANSFER' and then went to either: 'FAQ' or 'PROFILE UPDATE'
Answer to Workshop 7 – Build the MapReduce Function
SELECT customer_id, session_id, first_page, last_page, datestamp
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A.B.C|D' )
SYMBOLS (page='ACCOUNT SUMMARY' as A,
page='FUNDS TRANSFER' as B,
page='FAQ' as C,
page='PROFILE UPDATE' as D)
RESULT ( FIRST( customer_id OF ANY(A,B,C,D) ) AS customer_id,
FIRST (page of ANY(A,B,C,D)) as first_page,
LAST(page of ANY(C,D)) as last_page,
LAST(session_id OF ANY(A,B,C,D)) as session_id,
LAST(datestamp OF ANY(A,B,C,D)) as datestamp));
This is one way you might have done it, but I have a better way.
Best Answer to Workshop 7 – Build the MapReduce Function
SELECT customer_id, session_id, first_page, last_page, datestamp
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A.B.(C|D)' )
SYMBOLS (page='ACCOUNT SUMMARY' as A,
page='FUNDS TRANSFER' as B,
page='FAQ' as C,
page='PROFILE UPDATE' as D)
RESULT ( FIRST( customer_id OF ANY(A,B,C,D) ) AS customer_id,
FIRST (page of ANY(A,B,C,D)) as first_page,
LAST(page of ANY(C,D)) as last_page,
LAST(session_id OF ANY(A,B,C,D)) as session_id,
LAST(datestamp OF ANY(A,B,C,D)) as datestamp));
This is a guaranteed winner.
Workshop 8 – Build the Accumulate in the Result
SELECT customer_id, session_id, first_page, last_page, datestamp
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A.B.C|D' )
SYMBOLS (page='ACCOUNT SUMMARY' as A,
page='FUNDS TRANSFER' as B,
page='FAQ' as C,
page='PROFILE UPDATE' as D)
RESULT ( FIRST( customer_id OF ANY(A,B,C,D) ) AS customer_id,
FIRST (page of ANY(A,B,C,D)) as first_page,
LAST(page of ANY(C,D)) as last_page,
LAST(session_id OF ANY(A,B,C,D)) as session_id,
LAST(datestamp OF ANY(A,B,C,D)) as datestamp));
Make the above better by using the accumulate capabilities in the RESULT. We still want people who first went to the ACCOUNT SUMMARY page, followed by FUNDS TRANSFERRED and then went to either FAQ or PROFILE UPDATE. The most difficult piece of this assignment is that you must also accumulate the pages of a, b, c, d. That way we can see the path! Also count those pages. Good luck!
Answer to Workshop 8 – Build the Accumulate in the Result
SELECT customer_id, pages, countany
FROM nPath
(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'a.b.(c|d)')
SYMBOLS ( page='ACCOUNT SUMMARY' as A,
page='FUNDS TRANSFER' as B,
page='FAQ' as c,
page='PROFILE UPDATE' as d )
RESULT ( FIRST( customer_id OF any(a,b,c,d)) as customer_id,
accumulate(page of any(a,b,c,d) ) AS pages,
count(* of any(a,b,c,d)) as countany)
);
This is a guaranteed winner. How about that accumulate statement. Now, you can see the entire path.
SQL-MapReduce Examples - Linear Regression (Continued)
SELECT *
FROM LINREG
(ON LINREGMATRIX
(ON (SELECT col1, col2, col3
FROM Stats_Table))
PARTITION BY 1);
The Linear Regression function uses the linear regression model to output coefficients based on an input matrix. The zeroth coefficient corresponding to the slope intercept (y=mx+b).
This is actually a nested function and calculates the input matrix based on the values returned from the LINREGMATRIX function. The LINREGMATRIX functions takes as input a table, view or sql.
Also, make sure that the last column of your input table, view or sql contains the Y component.
Finally, PARTITION BY 1 is a required clause because it tells Aster Data to submit the job to only one worker.
The above nPath function is an example that works. Let's turn the page and check out our results on Nexus.
Workshop 9 – Build the Subquery
SELECT DISTINCT customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id) )
I want to see all columns from the bank_web_clicks. You will need to run a subquery (above the SQL you see above). Can you build a subquery that accepts input from the nPath? I know you can!
This is a big step up. Now we are taking the SQL-MR statement and passing it up to a subquery. That is the true art of MapReduce and Aster Data. Make me proud!
Answer to Workshop 9 – Build the Subquery
SELECT * FROM bank_web_clicks
WHERE customer_id IN
(
SELECT DISTINCT customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id) )) ;
I want to see all columns from the bank_web_clicks. You will need to run a subquery above the SQL in front of you. Can you build a subquery that accepts input from the nPath? You just did!
Genius! You are well on your way to becoming a world-class professional in a top of the line business. Great work again! The first SELECT is asking for all data from the bank_web_clicks table but wants to be fed customer_ids. The nPath function gathers those customer_ids and passes them up.
Workshop 10 – Do Your First Join
SELECT * FROM bank_web_clicks
WHERE customer_id IN
(
SELECT DISTINCT customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id) )) ;
The example above is a subquery. Change it to a join!
I want to see all columns from the bank_web_clicks. You will need to join the bank_web_clicks table to the nPath MR-Function. Can you do it? This will be an even bigger step than the last genius move you made with the subquery. Good luck!
Answer to Workshop 10 – Do Your First Join
SELECT A.* FROM bank_web_clicks as A
INNER JOIN
(
SELECT DISTINCT customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id) )) as cust
ON (a.customer_id = cust.customer_id);
I want to see all columns from the bank_web_clicks. You will need to join the bank_web_clicks table to the nPath MR-Function.
Genius! Bravo! You are now becoming a super star. This is big time work. The key here is that you must give the nPath an alias. We called in cust. You then can join the bank_web_clicks table with cust. Nice work. Now, instead of using the INNER JOIN keyword, can you also do this using a different syntax for joining? I know you can. Make it happen.
Answer to Workshop 10 – Do the Join Using a New Syntax
SELECT A.* FROM bank_web_clicks as A
,
(
SELECT DISTINCT customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id) )) as cust
WHERE (a.customer_id = cust.customer_id);
I want to see all columns from the bank_web_clicks. You will need to join the bank_web_clicks table to the nPath MR-Function. Do it with a different syntax than the INNER JOIN.
Just replace the words INNER JOIN with a comma and then change the ON keyword below to WHERE. It is that simple.
Workshop 11 – Super Join the Tables
SELECT A.* FROM bank_web_clicks as A
INNER JOIN
(
SELECT DISTINCT customer_id
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A' )
SYMBOLS ( page='FUNDS TRANSFER' as A)
RESULT ( FIRST( customer_id OF A ) AS customer_id) )) as
cust
ON (a.customer_id = cust.customer_id);
The above is an example that joins the bank_web_clicks table on customer_id. Can you take it further? I want to see all customers who first went to the webpage 'FUNDS TRANSFER' and then went directly to 'CUSTOMER SUPPORT'. Join this table with the nPath and join the rows within the same customer session. Good luck.
Answer to Workshop 11 –Super Join the Tables
select *
from
bank_web_clicks a
INNER JOIN
(
SELECT customer_id, session_id
FROM nPath(
on bank_web_clicks
PARTITION BY customer_id, session_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN ('A.B')
SYMBOLS ( page='FUNDS TRANSFER' A
, page='CUSTOMER SUPPORT' B)
RESULT (
FIRST( customer_id OF ANY ( A,B ) ) AS customer_id
,FIRST( session_id OF ANY ( A,B ) ) AS session_id
,LAST ( page OF ANY (A,B) ) AS lastpage
, count(* OF ANY(A,B)) AS b_count)
)
) b
ON a.customer_id = b.customer_id
and a.session_id = b.session_id
Congratulations! I knew you could do it! Can you do it again with the other JOIN syntax?
Answer to Workshop 11 – Super Join the Tables
select * from bank_web_clicks a
,
(
SELECT customer_id, session_id--, lastpage, b_count
FROM nPath(
on bank_web_clicks
PARTITION BY customer_id, session_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN ('A.B')
SYMBOLS ( page='FUNDS TRANSFER' A
, page='CUSTOMER SUPPORT' B)
RESULT (
FIRST( customer_id OF ANY ( A,B ) ) AS customer_id
, FIRST( session_id OF ANY ( A,B ) ) AS session_id
, LAST ( page OF ANY (A,B) ) AS lastpage
, count(* OF ANY(A,B)) AS b_count)
)
) b
where a.customer_id = b.customer_id
and a.session_id = b.session_id
Congratulations! I knew you could do it!
Workshop 12 – Sessionize the Data
SELECT User_ID, Time_ts, Page_Clicked, Sessionid
FROM sessionize( ON clickstreams
PARTITION BY User_ID
ORDER BY Time_ts
TIMEOUT(300)
TIMECOLUMN('time_ts') ) ;
The example above sessionizes the clickstreams table, but I want you to do if from the bank_web_clicks table.
Show me all columns from the bank_web_clicks table, plus show me if the session changes. We have determined that the session changes if a lapse between pages is more than 60 seconds!
Answer to Workshop 12 – Sessionize the Data
SELECT customer_id, session_id, page, datestamp, Sessionid
FROM sessionize( ON bank_web_clicks
PARTITION BY Customer_ID, Session_id
ORDER BY datestamp
TIMEOUT(60)
TIMECOLUMN('datestamp') ) ;
Show me all columns from the bank_web_clicks table, plus show me if the session changes. We have determined that the session changes if a lapse between pages is more than 60 seconds!
Congratulations! I knew you could do it!
The above is an excellent example to keep handy.
Workshop 13 – What is this Query Doing?
SELECT click_path, count(*) as path_frequency
FROM nPath
(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( '(RELEVANT|IGNORE) *.BUY')
SYMBOLS ( page in ('ACCOUNT SUMMARY') as IGNORE,
page NOT IN ('ACCOUNT SUMMARY') as RELEVANT,
page='FUNDS TRANSFER' as BUY )
RESULT ( accumulate(page of RELEVANT ) AS click_path)
) T
GROUP BY click_path
ORDER BY count(*) desc
LIMIT 10 ;
Your mission is to run this query and give your best explanation of what is happening.
Answer to Workshop 13 – What is this Query Doing?
SELECT click_path, count(*) as path_frequency
FROM nPath
(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( '(RELEVANT|IGNORE) *.BUY')
SYMBOLS ( page in ('ACCOUNT SUMMARY') as IGNORE,
page NOT IN ('ACCOUNT SUMMARY') as RELEVANT,
page='FUNDS TRANSFER' as BUY )
RESULT ( accumulate(page of RELEVANT ) AS click_path)
) T
GROUP BY click_path
ORDER BY count(*) desc
LIMIT 10 ;
We are finding the most popular path when a user did a FUNDS TRANSFER. We did not bring back any ACCOUNT SUMMARY input.
Workshop 14 – Using ilike
SELECT customer_id, lastpage, b_count
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
PATTERN( 'A|B' )
SYMBOLS ( page='FUNDS TRANSFER' as A,
page='CUSTOMER SUPPORT' as B )
RESULT ( FIRST( customer_id OF ANY(A,B) ) AS customer_id,
LAST( page OF ANY(A,B) ) AS lastpage,
COUNT( * OF ANY(A,B)) AS b_count) ) ;
Change the query above. This time I want you to discover users who went to the ACCOUNT SUMMARY page, and then went to CUSTOMER SUPPORT page, but who might have visited other pages in between! Use the ilike command and also put the accumulate of the pages in the result. This is a great opportunity to learn something really wonderful.
Answer to Workshop 14 – Using ilike
select customer_id, session_id, path, b_count
from npath(
on bank_web_clicks
partition by customer_id, session_id
order by datestamp
mode (nonoverlapping)
pattern('A.x*.B')
symbols (page ilike '%summary%' as A,
page='CUSTOMER SUPPORT' as B, 'true' as x)
result (
first(customer_id of any(A)) as customer_id
,first(session_id of any(A)) as session_id
,accumulate(page of any(A,X,B)) as path
,count(* of any(b)) as b_count))
order by 1,2;
The above just discovered users who first went to the ACCOUNT SUMMARY page and then went to CUSTOMER SUPPORT, but who might have visited other pages in between! Wow! Check out the query in action on the next page from Nexus.
Answer to Workshop 14 – Using ilike
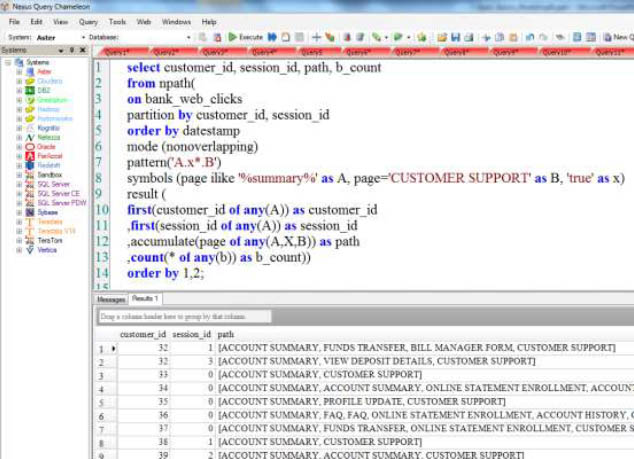
The difference between like and ilike is that ilike is NOT case sensitive.
Workshop 15 – What are the First Two Pages Visited?
SELECT customer_id, sessionid, pageid, next_pageid
FROM nPath (
ON bank_web_clicks
PARTITION BY customer_id, session_id
ORDER BY datestamp
MODE (OVERLAPPING)
PATTERN (A.B*)
SYMBOLS (XXXXXXXXXXXXX)
RESULT (FIRST(customer_id of A) as customer_id,
FIRST(session_id of A) as sessionid,
FIRST(page OF A) as pageid,
FIRST(page OF B) as next_pageid
)
) ;
Fill in the XXXXXXXXXXX pattern to find the first two pages each user visited. We have already PARTITIONED by customer_id and then session_id. Just fill in the symbols needed.
Workshop 15 – What are the First Two Pages Visited?
select *
from npath
(
on bank_web_clicks
partition by customer_id, session_id
order by datestamp
mode(nonoverlapping)
pattern('a.b*')
symbols(true as a, true as b)
result
(
first(customer_id of a) as customer_id -- customer_id
,first(session_id of a) as sessionid -- session_id
,first(page of a) as firstpagea-- the first page visited
,first(page of b) as firstpageb-- the second page (first page of b after a)
,last(page of a) as lastpagea -- a only has one page in the nonoverlapping sequence a.b*.
,last(page of b) as lastpageb -- b will be 'true' for every row, so you get the last page in the session
,count(* of a) as ranka-- always 1
,count(* of b) as rankb-- the number of pages visited in the session
,count(* of any(a,b)) as rankany-- count of a + count of b
)
);
The above just discovered the first two pages visited per customer in the same session_id. The way the pattern is done means that everything is overlapping, so you just get one row back instead of the pairwise rows when using nonoverlapping. If you used overlapping, then you would need to keep the max rank. This is an incredible learning experience. Run and study!
Workshop 16 – Advanced - First Two Pages Visited?
SELECT customer_id, sessionid, pageid, next_pageid, begdate, enddate, path
FROM nPath(
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE ( OVERLAPPING )
I started you out, but you need to make changes. Partition first by customer_id and then by session_id. Then, show me first two pages the user visited on the website. In the result, capture the customer_id, the session_id, the first page visited, the second page visited, the date and time of both the first and second page, and then accumulate the path. Good luck!
Answer to Workshop 16 Advanced - First Two Pages Visited?
SELECT customer_id, sessionid, pageid, next_pageid, begdate, enddate, path
FROM nPath (
ON bank_web_clicks
PARTITION BY customer_id, session_id
ORDER BY datestamp
MODE (OVERLAPPING)
PATTERN (A.B*)
SYMBOLS (true as A, true as B)
RESULT (FIRST(customer_id of A) as customer_id,
FIRST(session_id of A) as sessionid,
FIRST(page OF A) as pageid,
FIRST(page OF B) as next_pageid,
FIRST (datestamp OF A) as begdate,
LAST(datestamp OF B) as enddate,
ACCUMULATE(page of ANY(A,B)) as path
)
) ;
After we partitioned by customer_id and then session_id, the data was ready to be analyzed. nPath found the first two pages the user visited on the website. We captured the customer_id, the session_id, the first page visited, the second page visited, the date and time of both the first and second page and then we accumulated the path. That is pretty impressive.
Workshop 17 – Can You Clean Up the Results?
SELECT customer_id, sessionid, pageid, next_pageid, begdate, enddate, path
FROM nPath (
ON bank_web_clicks
PARTITION BY customer_id, session_id
ORDER BY datestamp
MODE (OVERLAPPING)
PATTERN (A.B*)
SYMBOLS (true as A, true as B)
RESULT (FIRST(customer_id of A) as customer_id,
FIRST(session_id of A) as sessionid,
FIRST(page OF A) as pageid,
FIRST(page OF B) as next_pageid,
FIRST (datestamp OF A) as begdate,
LAST(datestamp OF B) as enddate,
ACCUMULATE(page of ANY(A,B)) as path
)
);
Your mission is to now use the cast command. Perform the following:
1) Cast the customer_id (inside the nPath) from an integer to a decimal (8,2).
2) Trim up both the pageid and next_pageid columns
3) Cast the begdate as a date
Answer to Workshop 17 – Can You Clean Up the Results?
SELECT customer_id, sessionid, trim(pageid), next_pageid, begdate::date, enddate, path
FROM nPath (
ON bank_web_clicks
PARTITION BY customer_id, session_id
ORDER BY datestamp
MODE (OVERLAPPING)
PATTERN (A.B*)
SYMBOLS (true as A, true as B)
RESULT (FIRST(customer_id ::decimal(8,2) of A) as customer_id,
FIRST(session_id of A) as sessionid,
FIRST(TRIM(page) OF A) as pageid,
FIRST(TRIM(page) OF B) as next_pageid,
FIRST (datestamp OF A) as begdate,
LAST(datestamp OF B) as enddate,
ACCUMULATE(page of ANY(A,B)) as path
)
) ;
The mission below has been completed.
1) Cast the customer_id (inside the nPath from an integer to a decimal (8,2).
2) Trim up both the pageid and next_pageid columns
3) Cast the begdate as a date
Answer to Workshop 17 – Format the Date
SELECT cast(customer_id as decimal(8,2)), sessionid, trim(pageid), trim(next_pageid),
to_char(begdate, 'YYYY-MM-DD'), enddate, path, enddate-begdate as time1
FROM nPath ( ON bank_web_clicks
PARTITION BY customer_id, session_id
ORDER BY datestamp
MODE (OVERLAPPING)
PATTERN (A.B*)
SYMBOLS (true as A, true as B)
RESULT (FIRST(customer_id of A) as customer_id,
FIRST(session_id of A) as sessionid,
FIRST(page OF A) as pageid,
FIRST(page OF B) as next_pageid,
FIRST (datestamp OF A) as begdate,
LAST(datestamp OF B) as enddate,
ACCUMULATE(page of ANY(A,B)) as path
)
) order by customer_id, sessionid, begdate, enddate ;
The mission below has been completed.
1) Cast the customer_id (inside the nPath from an integer to a decimal (8,2).
2) Trim up both the pageid and next_pageid columns
3) Cast the begdate as a date
4) We also did a format statement of the begdate.
Workshop 18 – Build a Churn Table
How would you like to build a table from the results of the nPath function?
Your mission is to do just that. Here is the assignment.
Your nPath function will find all customers who visited the page Customer_Support. You will show their customer_id and concatenate each page visited before they reached the Customer Support page. You don't need to capture the page Customer Support in the final output. This is assumed.
Also, add a depth to your table capturing how many pages were visited by the customer before reaching the Customer Support page.
Call your new table Cust_Support_Table!
Remember: Your Cust_Support_Table will hold only two columns: customer_id concatenated with the path leading up to the Customer Support. Depth that shows how many pages were visited leading up to Customer Support.
Find all people who ended up going to the page CUSTOMER SUPPORT and the path they took to get there, but no need to put in the final CUSTOMER SUPPORT page. It is assumed.
Workshop 18 – Run the Query Before Building to Test
SELECT *
FROM nPath (
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE (NONOVERLAPPING)
PATTERN ('EVENT+.CUSTOMER_SUPPORT')
SYMBOLS(
page <> 'CUSTOMER SUPPORT' as EVENT,
page = 'CUSTOMER SUPPORT' as Customer_Support
)
RESULT (
COUNT(page of EVENT) as page_depth,
ACCUMULATE (customer_id || ' : ' || page OF EVENT) as cust_path
)
)
Find all people who ended up going to the page CUSTOMER SUPPORT and the path they took to get there, but no need to put in the final CUSTOMER SUPPORT page. It is assumed.
Workshop 18 – A Better Example
SELECT page_depth, customer_id || ' : ' || cust_path as cust_path
FROM nPath (
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE (NONOVERLAPPING)
PATTERN ('EVENT+.CUSTOMER_SUPPORT')
SYMBOLS(
page <> 'CUSTOMER SUPPORT' as EVENT,
page = 'CUSTOMER SUPPORT' as Customer_Support
)
RESULT (
COUNT(page of EVENT) as page_depth,
FIRST(customer_id of EVENT) as customer_id,
ACCUMULATE ( page OF EVENT) as cust_path
)
) ;
Find all people who ended up going to the page CUSTOMER SUPPORT and the path they took to get there, but no need to put in the final CUSTOMER SUPPORT page. It is assumed.
Answer to Workshop 18 – Build a Basic Churn Table
CREATE TABLE Cust_Support_Table
DISTRIBUTE BY HASH(cust_path)
AS
SELECT *
FROM nPath (
ON bank_web_clicks
PARTITION BY customer_id
ORDER BY datestamp
MODE (NONOVERLAPPING)
PATTERN ('EVENT+.CUSTOMER_SUPPORT')
SYMBOLS(
page <> 'CUSTOMER SUPPORT' as EVENT,
page = 'CUSTOMER SUPPORT' as Customer_Support
)
RESULT (
ACCUMULATE (customer_id || ' : ' || page OF EVENT) as cust_path,
COUNT(page of EVENT) as page_depth
)
) n ;
The mission below has been completed. You have just built a new table from the nPath called Cust_Support_Table. This will show what customers have contacted Customer_Support, and the path they on the website to get there. You can now assign someone to take action to prevent the customer from leaving.
Workshop 18 – Create the Churn Table with a Better Example

This is how you build a great Churn Table.
Multi-Case
CREATE FACT TABLE people
(userid integer,
name varchar(50),
age integer)
DISTRIBUTE BY HASH(userid);
INSERT INTO people VALUES (100, 'Harry Potter', 13);
INSERT INTO people VALUES (200, 'Hannah Montana', 16);
INSERT INTO people VALUES (300, 'Ralph Malph', 17);
INSERT INTO people VALUES (400, 'Mork from Ork', 20);
INSERT INTO people VALUES (500, 'Joey Tribbiani', 25);
INSERT INTO people VALUES (600, 'Jason Bourne', 35);
INSERT INTO people VALUES (700, 'Charles Xavier', 55);
INSERT INTO people VALUES (800, 'Yoda', 900);
INSERT INTO people VALUES (900, 'Jack Bauer', 45);
We are about to introduce the Multi-Case function. Before we demonstrate this function, above are the table and the insert statements we will use to show off this function. Turn the page to see the function perform.
The Multi-Case Function
CREATE FACT TABLE people
(userid integer, name varchar(50), age integer) DISTRIBUTE BY HASH(userid);
SELECT *
FROM multi_case ( ON (
SELECT *,
(age < 1) AS case1, (age >= 1 AND age <= 2) AS case2,
(age >= 2 AND age <=12) AS case3, (age >=13 AND age <=19) AS case4,
(age >=16 AND age <=25) AS case5, (age >=21 AND age <=40) AS case6,
(age >=35 AND age <=60) AS case7, (age >=60) AS case8
FROM people )
LABELS (
'case1 AS "infant"', 'case2 AS "toddler"', 'case3 AS "kid"', 'case4 AS "teenager"',
'case5 AS "young adult"', 'case6 AS "adult"', 'case7 AS "middle aged person"',
'case8 AS "senior citizen"' ) )
ORDER BY userid;
The Multi-Case function will allow you to build your case statements and easily return the answer set you expect.
The Multi-Case Function in Nexus
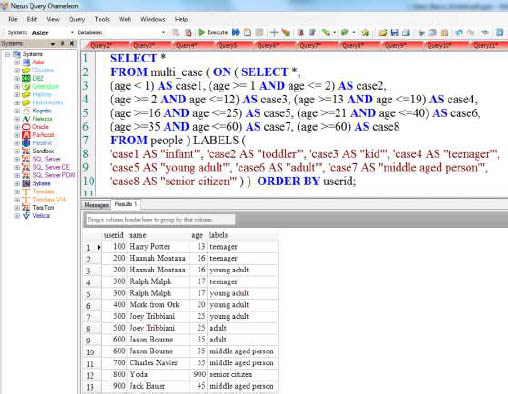
The difference between Multi-Case vs. a regular Case statement is that Multi-Case will return multiple rows and categories. Notice that Hannah Montana, Ralph Malph, Joey Tribbiani, and Jason Borne have multiple labels.
The Multi-Case Function Mixing and Matching
CREATE FACT TABLE people
(userid integer, name varchar(50), age integer) DISTRIBUTE BY HASH(userid);
SELECT *
FROM multi_case ( ON (
SELECT *,
(age < 1) AS case1, (age >= 1 AND age <= 2) AS case2,
(age >= 2 AND age <=12) AS case3, (age >=13 AND age <=19) AS case4,
(age >=16 AND age <=25) AS case5, (age >=21 AND age <=40) AS case6,
(age >=35 AND age <=60) AS case7, (age >=60) AS case8, (userid <= 400) as case9
FROM people )
LABELS (
'case1 AS "infant"', 'case2 AS "toddler"', 'case3 AS "kid"', 'case4 AS "teenager"',
'case5 AS "young adult"', 'case6 AS "adult"', 'case7 AS "middle aged person"',
'case8 AS "senior citizen"', 'case9 AS "Cartoon Characters"' ) )
ORDER BY userid;
Notice above that we have added Cartoon Characters as a case on userid. The other Multi-Case statements are on age. You can mix and match different labels on different columns in the same Multi-Case statement.
The Multi-Case Function Mixing and Matching
CREATE FACT TABLE people
(userid integer, name varchar(50), age integer) DISTRIBUTE BY HASH(userid);
SELECT *
FROM multi_case ( ON (
SELECT *,
(age < 1) AS case1, (age >= 1 AND age <= 2) AS case2,
(age >= 2 AND age <=12) AS case3, (age >=13 AND age <=19) AS case4,
(age >=16 AND age <=25) AS case5, (age >=21 AND age <=40) AS case6,
(age >=35 AND age <=60) AS case7, (age >=60) AS case8, (userid <= 400) as case9
FROM people )
LABELS (
'case1 AS "infant"', 'case2 AS "toddler"', 'case3 AS "kid"', 'case4 AS "teenager"',
'case5 AS "young adult"', 'case6 AS "adult"', 'case7 AS "middle aged person"',
'case8 AS "senior citizen"', 'case9 AS "Cartoon Characters"' ) )
ORDER BY userid;
Notice above that we have added Cartoon Characters as a case on userid. The other Multi-Case statements are on age. You can mix and match different labels on different columns in the same Multi-Case statement.
SQL-MapReduce Examples - cFilter
Collaborative Filtering is a process which is used to pair a particular event with another event based on a set of information from previous events. This is most famously seen on website after the purchase of product A. The consumer would then be notified "People who brought product A also bought product B." The hope would be that the consumer would see the value in these additional products and make addition purchases. Another example of where collaborative filtering has been used is in natural resource exploration. If oil is found there may be a possibility that natural gas is present. cFilter lets you see patterns in your data which might be difficult to extract using traditional SQL.
cFilter takes in a table as input and outputs a table. You will need to query this output table to see your results. They are not immediately displayed. The table will provide you with a comparison of two items. It will provide you with the count of item A, the count of item B and a probability score which will let you know the "chance" that item A is paired with item B. The data flow can be expressed as follows . . .

You may also see console messages if this function is run via the command line.
SQL-MapReduce Examples - cFilter (Continued)
SELECT * FROM cfilter
(ON (SELECT 1) PARTITION BY 1
DOMAIN('192.168.100.100:2406')
DATABASE('beehive')
USERID('db_superuser')
PASSWORD('db_superuser')
INPUTTABLE('transactions')
OUTPUTTABLE('transactions_results')
INPUTCOLUMNS('item')
JOINCOLUMNS('tran_id')
OTHERCOLUMNS('site_id')
DROPTABLE('false'));
Remember the cFilter function creates a table. There is really no answer set to return as it is returned in the form of a table. The syntax ON (SELECT 1) PARTITION BY 1 can be thought of as a boolean indicator. If you get an answer set back then the function was successful and you need to then query your output table.
DOMAIN is optional and tells the function the ip address of the Queen Node. The part after the colon specifies the port where the Queen Node is listening. By default this is 2406.
DATABASE is optional and is the database where your input table lives. This is also where the output table will be created.
USERID is optional and is the user id which you will use to log on to the Queen Node.
PASSWORD is required. No password. No access.
SQL-MapReduce Examples - Linear Regression (Continued)
SELECT *
FROM LINREG
(ON LINREGMATRIX
(ON (SELECT col1, col2, col3
FROM Stats_Table))
PARTITION BY 1);
The Linear Regression function uses the linear regression model to output coefficients based on an input matrix. The zeroth coefficient corresponding to the slope intercept (y=mx+b).
This is actually a nested function and calculates the input matrix based on the values returned from the LINREGMATRIX function. The LINREGMATRIX functions takes as input a table, view or sql.
Also, make sure that the last column of your input table, view or sql contains the Y component.
Finally, PARTITION BY 1 is a required clause because it tells Aster Data to submit the job to only one worker.
SQL-MapReduce Examples - cFilter (Continued)
SELECT * FROM cfilter
(ON (SELECT 1) PARTITION BY 1
DOMAIN('192.168.100.100:2406')
DATABASE('beehive')
USERID('db_superuser')
PASSWORD('db_superuser')
INPUTTABLE('transactions')
OUTPUTTABLE('transactions_results')
INPUTCOLUMNS('item')
JOINCOLUMNS('tran_id')
OTHERCOLUMNS('site_id'));
INPUTTABLE and OUTPUTTABLE are both required. The input table contains the data you want to find patterns on. The output table does not exist the first time you run cFilter. If you run cFilter a second time you need to drop your output table or you will receive an error.
INPUTCOLUMNS are required and are the list of items you wish to filter. This usually takes the form of transactional data such as web pages visited and you would filter this data in this case to answer the question, "If someone visits page A what other pages will they visit." This may help you place an ad for them on the second page that relates to the first.
JOINCOLUMNS are required used to associate data based on a transaction set or a session id. In our case, we have a transaction id and we are attempt to find patterns within those transactions.
OTHERCOLUMNS are optional and are a list of other columns which remain unchanged as they pass through the function.
SQL-MapReduce Examples - Linear Regression (Continued)
SELECT *
FROM LINREG
(ON LINREGMATRIX
(ON (SELECT col1, col2, col3
FROM Stats_Table))
PARTITION BY 1);
The Linear Regression function uses the linear regression model to output coefficients based on an input matrix. The zeroth coefficient corresponding to the slope intercept (y=mx+b).
This is actually a nested function and calculates the input matrix based on the values returned from the LINREGMATRIX function. The LINREGMATRIX functions takes as input a table, view or sql.
Also, make sure that the last column of your input table, view or sql contains the Y component.
Finally, PARTITION BY 1 is a required clause because it tells Aster Data to submit the job to only one worker.
SQL-MapReduce Examples - cFilter (Continued)
cFilter also allow you to use the following additional syntax options:
DROPTABLE is optional. Valid values are 'true' or 'false' and 'false' is the default. If your table exists you will need to use DROPTABLE('true') to drop the table. You could also consider just running a drop table statement before your cFilter function to drop your previous output table.
MAXSET is optional. The default is 100. If you have a long list of items to filter then this will tell the function to only consider the number of items set in your MAXSET clause. MAXSET(10) will only consider 10 items.
PARTITION KEY is optional. This is the key with which you want to partition the output table. By default the output table is partitioned by col1_item1 which is the first item. If you had a output table with id, item1, item2 and score the table would be partitioned by item1.
SQL-MapReduce Examples - cFilter (Continued)
Our transaction table contains four columns. The transaction id, the date the transaction took place the item which was purchase and the site id where it was purchase.
The are four main products. They are life, health, home and auto insurance. What we want to understand is if someone buys a particular type of insurance how likely are they to purchase additional insurance from one of the other categories.
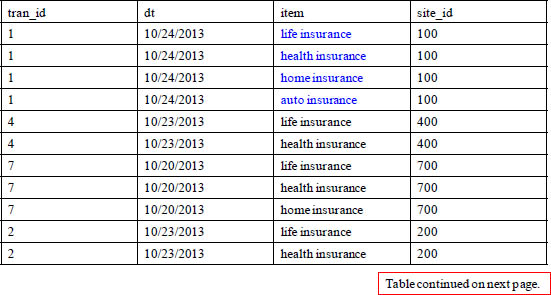
SQL-MapReduce Examples - cFilter (Continued)
This is the table which will be used as input into our function. The table's name is transactions so that will be our input table. The output table we are going to call transactions_results. Our input column for the pattern we want to discover is item. We want to know the pattern within each transaction id so we need to join on the transaction id and since we also want to see the site id as well site id is our "other" column.
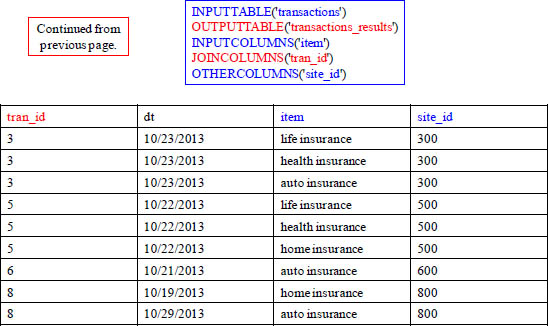
SQL-MapReduce Examples - cFilter (Continued)
Don't be confused that you don't have an answer set. The function is successful if you get anything back. In this case, we have a table named transactions_results.
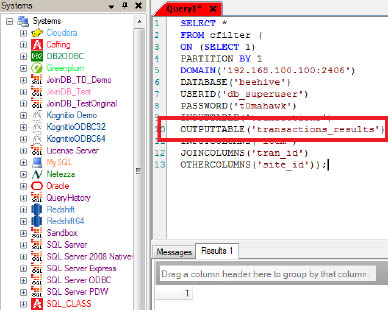
The above nPath function is an example that works. Let's turn the page and check out our results on Nexus.
SQL-MapReduce Examples - cFilter (Continued)
One final query of the transaction results table will show us the results of the cFilter function. In this case we see most stores when then sell life insurance the transaction also includes a purchase or health insurance. Store 300's rating is a lot lower and they need some work.
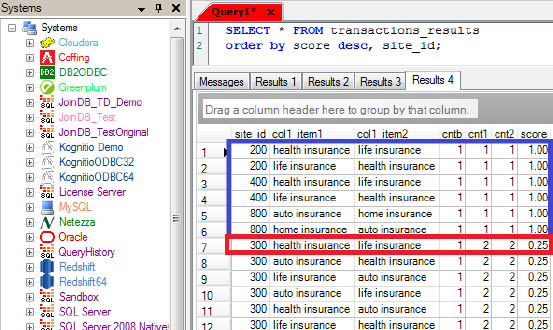
SQL-MapReduce Examples - cFilter (Continued)
Here is a list of the columns which are returned in your final results table.
col1_item1 corresponds to item one. It is also the partition key of your final table if you didn't not explicitly set one.
col1_item2 correspond to your second item.
cntB is the occurrence of both items.
cnt1 is the occurrence of item 1.
cnt2 is the occurrence of item 2.
score is the probability that item 1 will be followed by item 2.
SQL-MapReduce Examples - cFilter (Continued)
These columns may or may not be present depending on the version of the cFilter function you are using.
Support represents how often the pattern occurs.
Confidence is the percentage of occurrences of item 2 where item 1 occurs.
Lift is the ratio of observed support compared to the expected support value.
Lift > 1 is the occurrence of when item 1 or item 2 have a positive impact on the occurrence of other items.
Lift < 1 is the occurrence of when item 1 or item 2 have a negative impact on the occurrence of other items.
Lift = 1 is the occurrence of when item 1 or item 2 have an equal impact on the occurrence of other items.
Z_score is the attempt to measure how significant the pattern is. If all cntBs are the same then the Z_score is not computed.
CFILTER in Action with Bank_Web_Clicks
SELECT *
FROM cfilter (
ON (SELECT 1)
PARTITION BY 1
DOMAIN ('192.168.100.100:2406')
DATABASE ('beehive')
USERID ('db_superuser')
PASSWORD ('db_superuser')
INPUTTABLE ('bank_web_clicks')
OUTPUTTABLE ('bank_web_clicks_results')
INPUTCOLUMNS ('page')
JOINCOLUMNS ('customer_id, session_id')
);
SELECT * FROM bank_web_clicks_results;
Collaborative filtering is used to find items that are paired with other items. It is also used to find events that are paired with other events. For example, when you are on a website and see, “People who shopped for this item also shopped for . . .” uses a collaborative filtering algorithm. Another use is when you see on social media, “People who viewed this page also viewed this". Cfilter is a general-purpose tool that can provide answers in many similar-use cases. Above is an example. Now, turn the page and see this query run in Nexus. You will see a sample of the result set.
CFILTER in Action
SELECT *
FROM cfilter (
ON (SELECT 1)
PARTITION BY 1
DOMAIN ('192.168.100.100:2406')
DATABASE ('beehive')
USERID ('db_superuser')
PASSWORD ('db_superuser')
INPUTTABLE ('transactions')
OUTPUTTABLE ('transactions_results')
INPUTCOLUMNS ('item')
JOINCOLUMNS ('tran_id')
OTHERCOLUMNS ('site_id')
);
SELECT * FROM transactions_results;
Collaborative filtering is used to find items that are paired with other items. It is also used to find events that are paired with other events. For example, when you are on a website and see, “People who shopped for this item also shopped for . . .” uses a collaborative filtering algorithm. Another use is when you see on social media, “People who viewed this page also viewed this". Cfilter is a general-purpose tool that can provide answers in many similar-use cases. Above is an example. Now, turn the page and see this query run in Nexus. You will see a sample of the result set.
CFILTER using Nexus
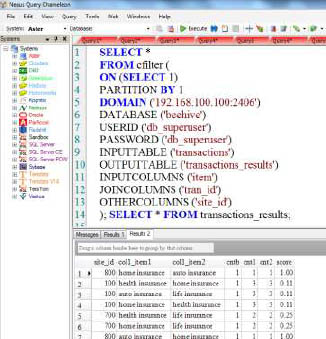
Collaborative filtering is used to find items that are paired with other items. It is also used to find events that are paired with other events. For example, when you are on a website and see, “People who shopped for this item also shopped for . . .” uses a collaborative filtering algorithm. Another use is when you see on social media, “People who viewed this page also viewed this". Cfilter is a general-purpose tool that can provide answers in many similar-use cases. Above is an example.
nPath Error
Above is an example. Why did this error? Because there is no partition statement here. How would each vworker discover the path? It would have to do it one row at a time. nPath makes you partition the data so the right data can be moved to the right vworker. This, then allows each vworker to work locally. You must partition your data in the nPath function because it works on groups (partitions), and not row by row. If it did work row by row, then one vworker would have to do all the work.