
Chapter 3 – How Aster Processes Data
“Fall seven times, stand up eight.”
- Japanese Proverb
When a Table is Created, a Table Header is Created
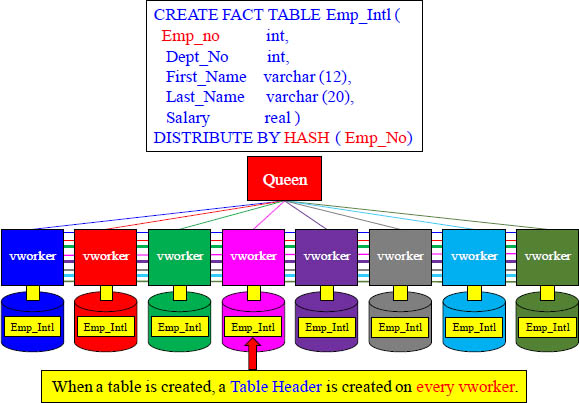
All vworkers have the exact same tables because when a table is created, a table header is immediately created on every vworker.
Every vworker has the Exact Same Tables
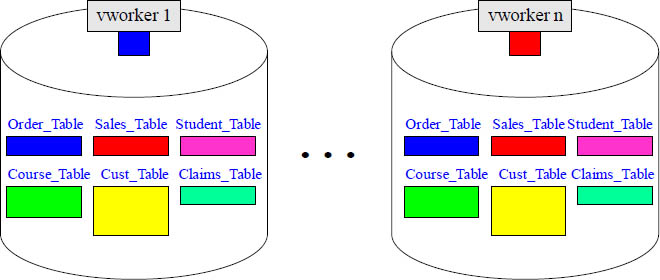
The first thing that happens when a table is created is that a Table Header is created on every vworker. Each vworker now has the table, and they know the table’s columns and distribution key. So, each vworker has the exact same tables and the exact same number of tables. It is just like looking into a mirror. Each vworker holds a portion of the rows of every table that is hashed, and every vworker holds the exact same rows for tables that are replicated. In this parallel processing system, every vworker does an equal amount of the work.
All Aster Tables are spread across All vworkers
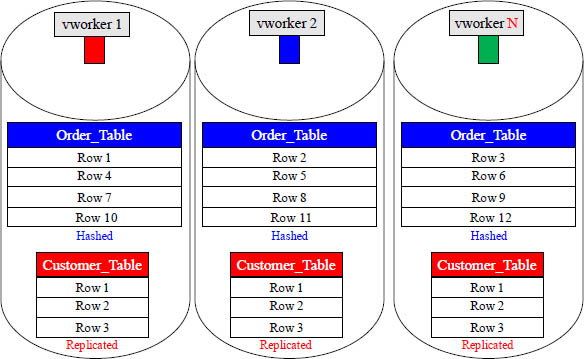
When data is loaded, each vworker holds a portion of the rows of every table that is hashed, and every vworker holds the exact same rows for tables that are replicated.
The Table Header and the Data Rows are Stored Separately
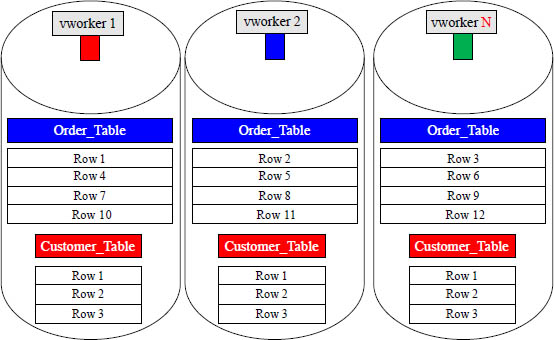
The Table Header is created on each vworker when the table is created. The rows are stored in data blocks when the data is loaded. Both are stored separately on each vworker.
A vworker Stores the Rows of a Table inside a Data Block

Each vworker stores the rows they own inside a data block. Above, you can see that this vworker is responsible for four rows, and those four rows are held in a single data block.
To Read Rows, a vworker Moves the Data Block into Memory
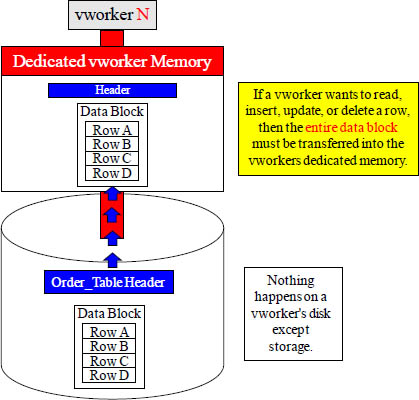
To read data, a vworker must transfer the table header and the data block from inside its disk to its dedicated memory. Nothing happens on the disk except storage.
A Full Table Scan Means All vworkers must Read All Rows
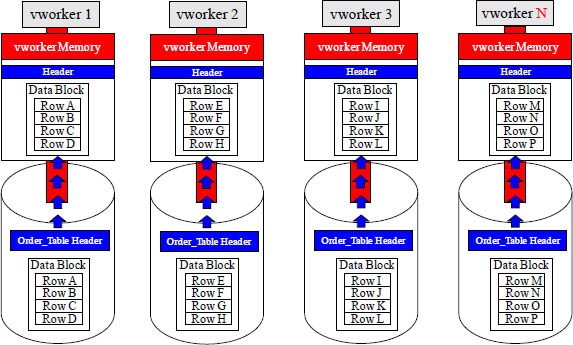
A Full Table Scan means that all vworkers must transfer their data block from their disk into their dedicated memory, and then each vworker must read each row from the table starting from the first row they own to the last row.
The “Achilles Heel”, or Slowest Process, is Block Transfer

To read or write data, a vworker must move the data block from disk into its Memory. This is the Achilles heel of the system, and it is painfully slow!
Each Table has a Distribution Key

Each table chooses a column to be the Distribution Key. When users query a table and use the Distribution Key column in their SQL, only a “Single vworker” is used.
A Query Using the Distribution Key uses a Single vworker.
Choosing a good Distribution Key results in one vworker being used in the query.
As Rows are Added, a Data Block will Eventually Split
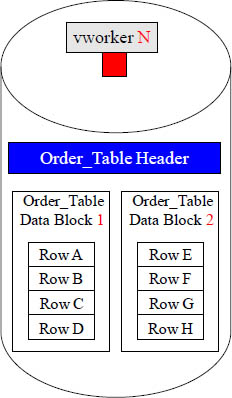
An Aster table can have trillions of rows, so an individual vworker might have millions, or even billions, of rows for a single table. As rows of a table are inserted inside a block, the block grows. Once a block reaches a maximum size, it splits into two smaller blocks.
A Full Table Scan Means All vworkers Read All Blocks
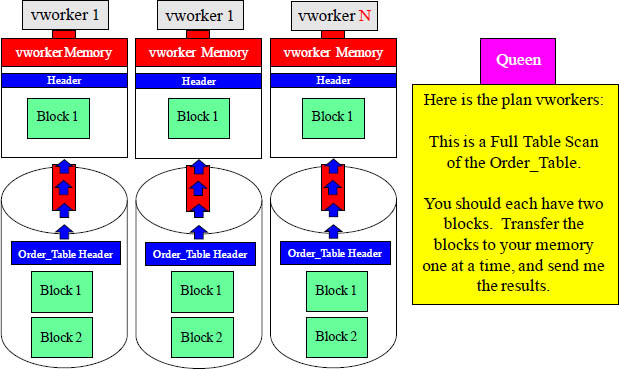
A Full Table Scan means that all vworkers must transfer their data blocks from their disk into their memory, and then read each block to evaluate the first row they own to the last row. Each vworker above process two blocks, so there is twice the transfer.
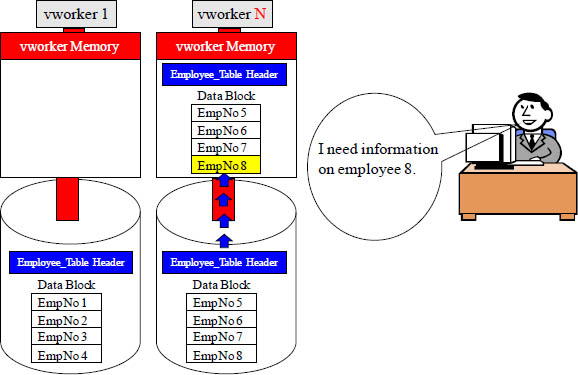
Distribution Key Query uses One vworker
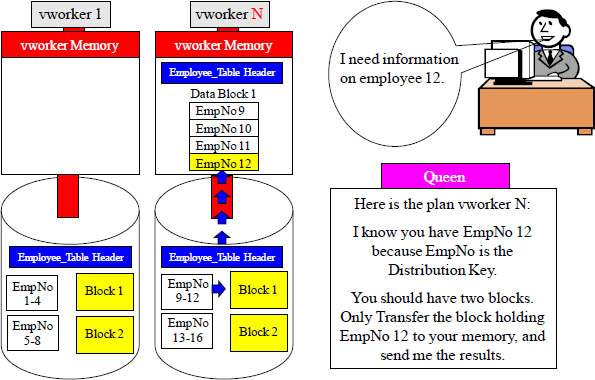
Vworker 2 was contacted and told to transfer it’s Employee_Table blocks into memory. Now, you see the importance of utilizing only a single vworker in tactical queries.
Each vworker Can Have Many Blocks for a Single Table

Each vworker has the same table header but contains different data rows for each table. Some tables are huge like the Order_Table. As more and more data was loaded, it performed many block splits. The Customer_Table is smaller and replicated.
A Full Table Scan Means All vworkers Read All Blocks

A Full Table Scan means that all vworkers must transfer their data blocks from their disk into their memory, and then read each block to evaluate the first row they own to the last row. Each vworker above process all blocks one at a time.
Quiz – How Many Blocks Move into vworker Memory?
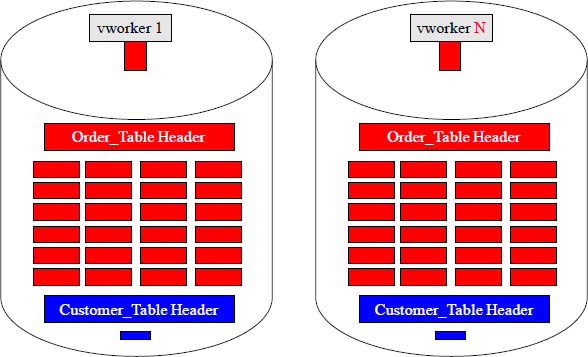
If a Full Table Scan was needed to satisfy a query using the Order_Table, how many data blocks would need to be transferred from disk to memory per vworker? ________
Answer – How Many Blocks Move into vworker Memory?

If a Full Table Scan was needed to satisfy a query using the Order_Table, how many data blocks would need to be transferred from disk to memory per vworker? 24
Quiz – How Many Blocks Move Using the Distribution Key?

If the Distribution Key for the Order_Table was Order_Number, and a user queried asking for information about Order_Number 100, how many blocks would need to be transferred into vworker memory in the entire system? __________
Answer-How Many Blocks Move Using the Distribution Key?
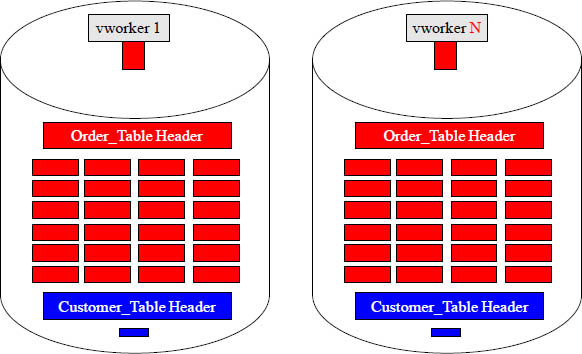
If the Distribution Key for the Order_Table was Order_Number, and a user queried asking for information about Order_Number 100, how many blocks would need to be transferred into vworker memory in the entire system? 1