
As we have seen in the Mirroring queues recipe, when a mirror is configured, the messages are copied across the cluster.
However, a new node can be added to the cluster at any time and can start to host mirrored queues that already contain messages. How does the cluster behave with respect to the stored messages?
Let's suppose that we have a typical scenario with a standalone node that has some messages stored in one of its queues as follows:
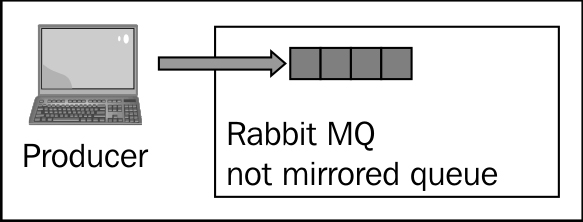
Now, if we add a node to the cluster and properly configure the ha-policies, the queue of the first node gets mirrored and subsequent messages start to get replicated on the newly added node, seen as follows:

It's very important to note that messages that are already in the master queue at the time of the addition of the second node don't get replicated by default. If the master dies at this time, these messages are lost. However, in a typical case with "live" queues, as soon as the consumer drains the single copy messages, the configuration will become fully replicated without any supplementary effort, as shown in the following screenshot:
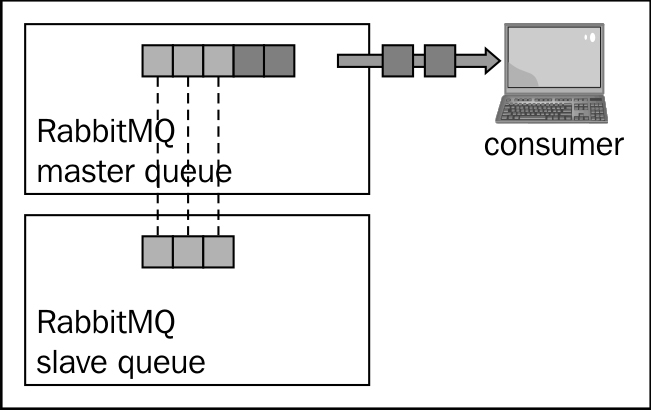
Alternatively, in the case of a queue not being drained, it's important to explicitly synchronize the queues to the mirror in order to have improved reliability. (After all, that's why we are adding a mirror.)
This is not the default behavior, because the synchronization task can have an important impact on the performance of the broker. When starting a synchronization, the queues are stuck until this process is done. In this recipe we will show you how to check the replication status and synchronize the queues.
You need a RabbitMQ cluster with mirror policies (refer to the Mirroring queues recipe).
In order to see the behavior of unsynchronized queues, we will simulate a node failure situation manually using the following steps:
- Configure the mirroring for queues prefixed by
mirr., as seen in the Mirroring queues recipe (we call therabbit@rabbitmqc1andrabbit@rabbitmqc2nodes). - Create a queue named
mirr.q_connection_1_1. - Check the queue's status from the web console; you should have the following screenshot:

- You can also check the queue using
rabbitmqctl list_queues name policy slave_pids. The result should be as follows:mirr.q_connection_1_1 ha-all all <[email protected]> [<[email protected]>] running
- Shut down the
rabbit@rabbitmqc2node usingrabbitmqctl stop_app(actually it doesn't matter which node). - Publish non-persistent messages to the queue using the
rabbit@rabbitmqc1node. - Restart the application on the
rabbit@rabbitmqc2node usingrabbitmqctl start_app. Then, check the queue as shown in the following screenshot: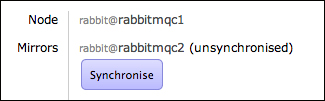
- Synchronize the queue using the Syncronise button or using
rabbitmqctl sync_queue mirr.q_connection_1_1:

After creating a stable situation by following steps 1 to 4, we simulate a node failure by stopping the rabbit@rabbitmqc2 node. So when we publish a message to the queue using the rabbit@rabbitmqc1 node, the messages aren't mirrored, because we have only one node up and running.
When the rabbit@rabbitmqc2 node gets running again (step 7), its queue is unsynchronized as we have seen in the Introduction section already.
You can synchronize the queue using the web management plugin or rabbitmqctl. In this way, your messages are replicated across the cluster.
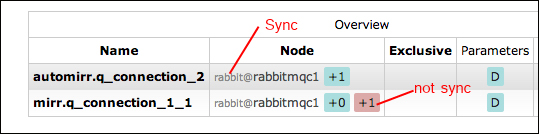
We have seen how to synchronize a queue manually, but there is also an automatic way to do this. Simply add ha-sync-mode and automatic when you configure ha-policies, as in the following screenshot:
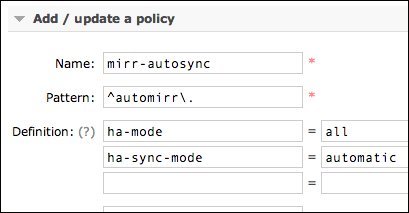
If you simulate a failure situation with the two policies, you will have the following screenshot:
You can see the Synchronising queues section at http://www.rabbitmq.com/ha.html for more details.