
Chapter 2: Understanding Program Structure
A C program, as in most programming languages, consists of a sequence of small, individual pieces of computational work called statements, which can form larger building blocks called functions, which are then compiled into a single program.
In the previous chapter, we learned about the basic development process. While understanding the process is fundamental, programming is principally about solving problems. This chapter will introduce one of the most important aspects of solving problems in any programming language: the ability to break a problem into smaller parts and then focus on solving each smaller problem. You can then use those parts as necessary to combine them into a complete program/solution. This is done by creating and using functions. As we examine these programming elements throughout this chapter, we will expand on the main() function, which we encountered in the previous chapter.
The following topics will be covered in this chapter:
- Introducing statements and blocks
- Introducing functions
- Understanding function definitions
- Order of execution
- Understanding function declarations
By the end of this chapter, you will have a solid foundation to create and use function statements.
NOTE:
When you type in the program and get compilation errors (likely due to inappropriate line wrapping in the text), refer to the source code in the repository for proper use of line breaks.
Technical requirements
Throughout the rest of this book, unless otherwise mentioned, you will continue to use your computer with the following:
- A plaintext editor of your choice
- A console, terminal, or command-line window (depending on your OS)
- A compiler – either the GNU Compiler Collection (GCC) or Clang (clang) for your particular OS
For consistency, it is best if you use the same computer and programming tools for all of the exercises. By doing so, you can focus more closely on the details of C.
The source code for this chapter can be found at https://github.com/PacktPublishing/Learn-C-Programming-Second-Edition/tree/main/Chapter02. Continue to type in the source code yourself and get your versions of the programs to run correctly.
Introducing statements and blocks
Before we begin to explore the details of statements, let's return to the various uses of punctuation that we encountered in our Hello, world! program. Here is the program for reference; comments have been removed so that we can concentrate on the details of the code:
#include<stdio.h>
int main() {printf( "Hello, world! " );
return 0;
}
First, I'd like to draw your attention to the paired punctuation – the punctuation that occurs with a beginning mark and an ending mark. Going through it line by line, we can see the following pairs – < and >, ( and ) (which occur on two lines), { and }, and " and ". We can also see some other punctuation that may or not be familiar to you. These are #, ., ;, , <space>, and <newline>. These punctuation marks are significant in the C language.
When we look closely at our "Hello, world! " greeting, we can see the beginning " character and the ending " character. Everything between them is part of what will be printed on the console. Therefore, there are two punctuation marks that we can ignore – , and !. We can ignore the comma and the exclamation mark contained between " and " because, as we have already seen, these are printed to the screen as part of our greeting. The characters between " and " represent a sequence of characters, or a string, to be displayed on the console. However, is a punctuation mark that has special significance when it's part of a string.
Note that, on your keyboard, the location of two different punctuation marks – /, or the forward slash, and , or the backward slash (also known as backslash). As you read from left to right, the forward slash falls forward while the backslash falls backward; hence their names. They have different uses in C. As we have seen with C++-style comments, two // characters constitute the beginning of a comment, terminated by the <newline> character. We'll come back to <newline> in a moment. However, if any other character occurs between //, then we do not have a C++-style comment; we have something else. A digraph in C is a two-character sequence, which means something more than either of the characters alone. Care must be exercised to ensure the digraph of two / characters is preserved; otherwise, the compiler will interpret this as something other than a C++-style comment.
In our greeting string, we can see the digraph, which represents the <newline> character to be output to the console. We must distinguish the <newline> character, , from the <carriage return> character, . We'll learn about many more of these digraphs when we explore output formatting in Chapter 19, Exploring Formatted Output, and input formatting in Chapter 21, Exploring Formatted Input. On some computer systems, to get a new line – that is, to advance one line down and return to the beginning of the line – is used (on Linux, Unix, and macOS). On others, is used (on some versions of Unix and other OSes). Yet, on others, both and are used together (on Windows).
These digraphs reflect the operation of antiquated manual typewriters. Manual typewriters have a carriage with a rotating platter and a return lever. Paper is fed into and wrapped around the platter. As characters are struck, the platter moves, positioning the paper for the next character. When the paper moves to its left most position (the end of the line), the page must be repositioned, or returned, to the beginning of the next line. This is done by manipulating the return lever. When the return lever is manipulated, it rotates the platter, giving a line feed or a new line to the next line. Then, the lever is forcibly pushed to the right and the carriage is returned to its beginning position – hence, a carriage return. Often, these two actions are combined into one swift and firm movement – new line and carriage return. The physical action of the manual typewriter is mirrored by the and diagraphs, as well as others.
Experimenting with statements and blocks
What happens to your system when you replace with ? The most likely result is that it will appear as if no greeting was printed at all. If that is the case, what happened is that the text's printing focus went back to the beginning of the line, but the line was not advanced; the console prompt wrote over it, wiping out our greeting. If you want to advance to the next line without returning to the beginning of the line, try the <linefeed> character, or v. This is the equivalent of rotating the platter without returning it to its beginning position.
Digraphs that appear in strings are also called escape sequences because they escape from the normal meaning of every single character. They all begin with the backslash () character. The following table shows the legal C digraphs:

Even though escape sequences appear in our program as two characters, they are single, non-visible characters. We will explore these in much greater detail in Chapter 15, Working with Strings. Here are some examples:
"Hello, world without a new line"
"Hello, world with a new line "
"A string with "quoted text" inside of it"
"Tabbed Column Headings"
"A line of text that spans three lines and completes the line "
To see how this works, create a file called printingExcapeSequences.c and edit/type the following program:
#include <stdio.h>
int main( void ) {printf( "Hello, world without a new line" );
printf( "Hello, world with a new line " );
printf( "A string with "quoted text" inside of it " );
printf( "Tabbed Column Headings " );
printf( "The quick brown " );
printf( "fox jumps over " );
printf( "the lazy dog. " );
printf( "A line of text that spans three lines and completes the
line " );
return 0;
}
This program is a series of printf() statements that each writes a string to the console. Note the use of the <newline> character, , which typically appears at the end of a string but can appear anywhere in it or not at all. In the third string, an escape sequence, ", is used to print the " character in the output string. Notice how tabs, , can be embedded into any string.
Once you have typed in this program, save it. Compile and run it in a console window using the following commands:
cc printingEscapeSequences.c <return>
./a.out<return>
You should see the following output:

Figure 2.1 – Screenshot of the compilation and execution of printingEscapeSequences.c
As you examine the output, see whether you can correlate the printf() strings to what you can see in the console. Notice what happens when there is no character in an output string, the quotation marks within an output string, and what looks like. Finally, notice how can be used to align columns of text.
We use the printf() function extensively to output strings to the console. In Chapter 20, Getting Input from the Command Line, we will use a variant of printf() to output strings to a file for permanent storage.
Understanding delimiters
Delimiters are characters that are used to separate smaller parts of the program from one another. These smaller parts are called tokens. A token is the smallest complete C language element. A token is either a single character or a sequence of characters predefined by the C language, such as int or return, or a sequence of characters/words defined by us, which we will learn about later. When a token is predefined by C, it cannot be used except in a prescribed way. These tokens are called keywords. Three keywords we have already encountered are include, int, and return. We will encounter many others throughout this chapter.
What about main()? Is it a keyword? No, it is not. Every C program must have a single function named main(), which is the starting point for the execution of the program. This is sometimes called the program's entry point; the main() function is called by the system when we run the program from the command line. We will learn more about function names later in the Exploring function identifiers section.
Again, here is the Hello, world! program for reference:
#include<stdio.h>
int main() {printf( "Hello, world! " );
return 0;
}
There are three types of delimiters that we will explore here:
- Single delimiters: ; and <space>
- Paired, symmetric delimiters: <>, (), {}, and ""
- Asymmetric delimiters that begin with one character and end with another: # and <newline> and // and <newline>
Each of these delimiters has a specific use. Most of them have unique and unambiguous uses. That is, when you see them, they can mean one thing and only one thing. Others have slightly different meanings when they appear in different contexts.
In our Hello, world! program, there are only two required <space> characters that are delimiters. We can see a delimiting space here, between int and main():
int main()
We can also see a delimiting space here, between return and the value being returned – in this case, 0:
return 0;
In these cases, the <space> character is used to separate one keyword or token from another. A keyword is a predefined word that has a special meaning. It is reserved because it cannot be used elsewhere for some other meaning or purpose. int and return are keywords and tokens. main() is a function identifier and a token. 0 and ; are tokens; one is a literal value, while the other is a delimiter. The compiler identifies and translates tokens into machine language as appropriate. Delimiters, including <space>, facilitate interpreting text in the program compilation stream into tokens. Otherwise, when spaces are not needed to separate tokens, they are optional and are considered whitespace.
You can see the paired symmetric delimiters from the list of types of delimiters. One always begins a particular sequence, while the other always ends it. <> is used for a specific type of filename, which tells the compiler how to search for the given file. () indicates that the token is associated with a function name; we'll explore this more soon. {} indicates a block that groups one or more statements into a single unit; we will explore statements later. Finally, "" indicates the beginning and end of a sequence of characters, also referred to as a string.
Lastly, we'll consider the first line, which begins with # and ends with <newline>. This is an asymmetric delimiter pair. This particular line is a preprocessor directive. The preprocessor is the very first part of the compiler phase where directives are interpreted. In this case, the file named stdio.h is searched for and inserted into the program compilation stream, or included, just as if the file had been typed into our program. To direct the compiler to insert it, we only need to specify its filename; the compiler has a predefined set of locations to look for it. The compiler finds it and opens and reads it into the stream. If it cannot find it, an error is reported.
This #include mechanism allows a single file to be used instead of manually copying the contents of this file into every source file that needs it. If the stdio.h file changes, all the programs that use it can simply be recompiled to pick up the new changes. Otherwise, any changes to any version of the copied text of stdio.h would have to also be made in every file that also copied its contents directly. We will encounter many of these files – those that are part of the Standard Library and those we create – as we begin to make our programs more complex and useful.
Now that we understand delimiters, we can remove all the extraneous spaces, tabs, and newlines. We can pair it down to just keywords, tokens, and delimiters. Our program, hello_nowhitespace.c, would look like this:
#include<stdio.h>
int main(){printf("Hello, world!
");return 0;}Create a new file called hello_nowhitespace.c, type this in, save it, compile it, run it, and verify that its output is as it was previously. Note that we do not remove the space in our string message; that part of the program is intended for humans.
Is this good programming practice? In a word – never.
You might think that a practice like this would somehow save space on your computer's hard drive/SSD; in reality, this space-saving is insignificant, especially compared to the added human time needed to understand and modify such a program.
It is a basic fact of programming that programs are read many tens of times more often than they are created or modified. In reality, every line of code is read at least 20 times over its lifetime. You may find that you re-read your programs several times before you consider changing them or reusing them. Others will read your programs with or without your knowledge. Therefore, while we must pay attention to the rules of the compiler and strive to write complete and correct programs, we must also strive to write clear programs for other humans to understand. This not only means using comments effectively but also using whitespace effectively.
Understanding whitespace
When a <space> or <newline> character is not required to delimit a portion of C code, it is considered whitespace. Whitespace can also be <tab>, <carriage return>, or some other obscure character. However, the use of tabs in C source files is discouraged since the program listing may look different on someone else's computer or when the source code is printed, thereby diminishing clarity and obfuscating your original intent.
Because we cannot predict how tabs are configured or where tabs are used, always use spaces instead of tabs in your source code files.
We write <newline> to mean the start of a new line, which has the same effect as hitting Enter on your keyboard. Similarly, <space> is the same as hitting the spacebar at the bottom of your keyboard.
Many programmers have different opinions on how to effectively use whitespace. Some programmers feel strongly about using two spaces to indent a line, while others are vehement about using four spaces. Others don't care one way or the other. In reality, there is no one correct way to do it. As you write more of your programs and read those of others, you should pay attention to whitespace styles to try to get a sense of what is effective and what you might prefer.
Similar to whitespace, the placement of { and } to open and close a code block engenders various opinions. In one use, the opening { is placed at the end of the line of code where the block begins. Here is the Hello, world! program using this practice:
int main() {printf( "Hello, world! " );
return 0;
}
In a second use, the open { is placed on a line by itself. This tends to emphasize the beginning and end of the block. Here is the Hello, world! program using this practice:
int main()
{printf( "Hello, world! " );
return 0;
}
In both cases, the closing } is on a line alone by itself. Some even prefer to place the closing } at the end of the last line of the block.
Throughout this book, we will employ the former method primarily because it is a bit more condensed. We will also place the closing } on a line by itself since it emphasizes the closing of the block.
Also, note how the lines of code within the block are indented with two spaces.
Consistency in code formatting, including whitespace and { placement, is more important than you might think. Consistent code helps set the code reader's expectations, making the code easier to read, and hence to comprehend. Inconsistent whitespace formatting can make the code harder to read and, consequently, introduce coding errors and bugs.
Here is an example of the inconsistent and inappropriate use of whitespace. It is from our Hello, world! program but with excessive and nonsensical whitespace added:
# include <stdio.h>
int
main
(
)
{printf
(
"Hello, world! "
)
;
return
0
;
}
Note that this is still a valid C program. It will compile and run and provide the same output as before. The C compiler ignores whitespace.
Because this is an example of bad practice, you do not have to type this in yourself. In the remaining programs in this book, all the source code will be presented with both consistent whitespace usage as well as consistent commenting style. You don't have to adopt these stylistic guidelines, but you should pay attention to them and compare them to other styles. Whatever style you choose, apply it consistently in your code.
When you are paid to create or modify programs for another individual or a company, they may have a set of style guides for you to follow. Strive to follow them. More than likely, however, they will not have a set of style guides; the coding style guidelines will be embodied in their existing repository of programs. Here, again, strive to follow the coding styles in the existing code you are modifying. This consistency makes the programs easier to read and faster to comprehend for later programmers.
Some programming teams employ source code pretty-printers, where each programmer runs their source code through a special program that reads their source file, reformats it according to preset formatting rules, and writes it out in the new format; the language functionality is unchanged. In this manner, all source code looks the same, regardless of who wrote it, since the style guidelines are enforced through the program's single set of rules. Every programmer can then read the formatted source code as if anyone had written it. They can focus on the code itself and not be distracted by various coding styles.
Here is a table of the delimiters that we have already encountered in our simple program:
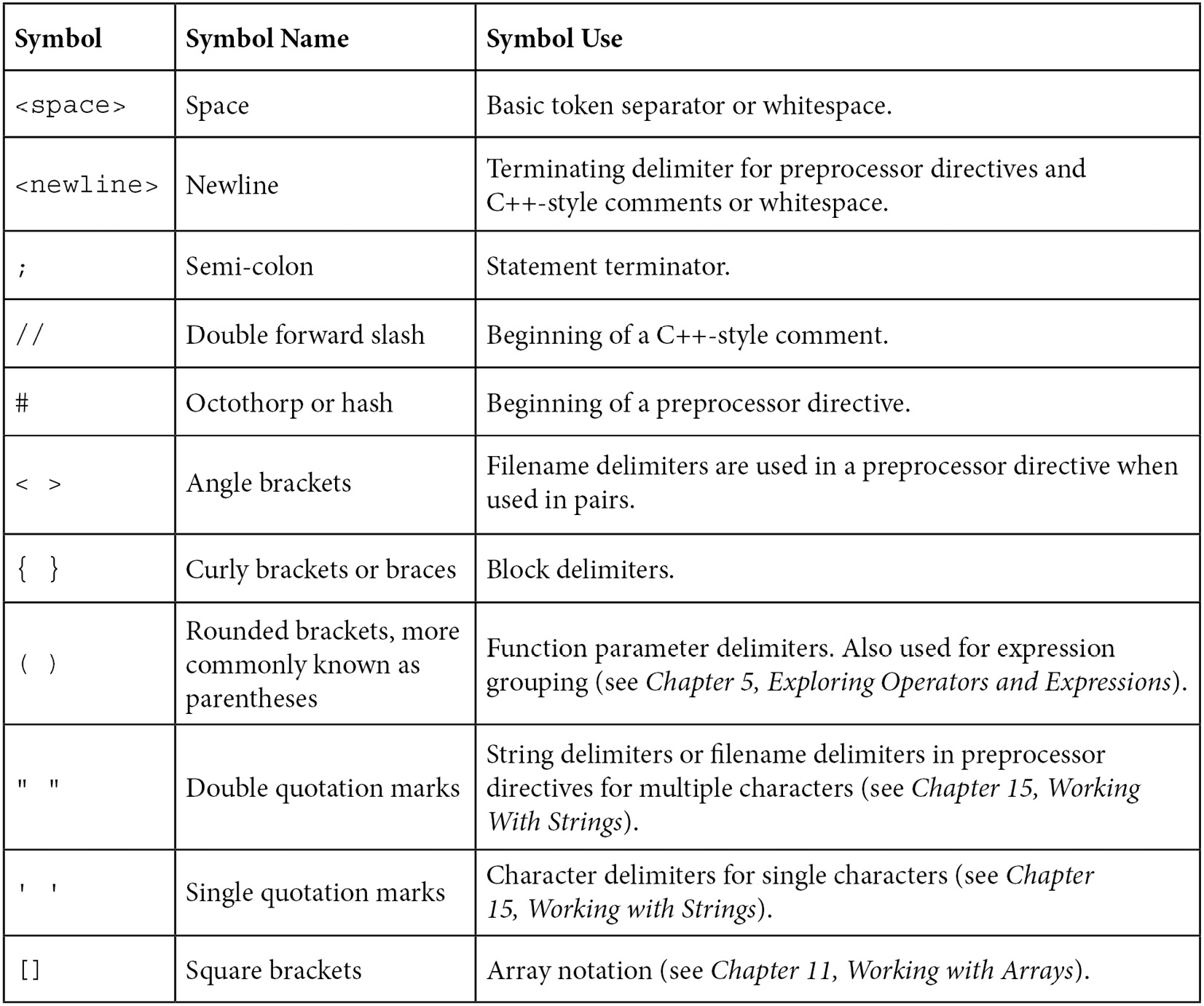
Later, we will see that some of these punctuation marks have different meanings when used in different contexts. When they're not being used as delimiters, their alternate meaning will be clear from the context. For instance, < is the less than logical operator and will occur alone when it has that meaning. For completeness, we have included the delimiters to indicate an array, which is square brackets; we will encounter them later in this book.
We are now ready to explore how these delimiters are used in various types of C statements.
Introducing statements
Statements in C are the basic building blocks of programs; each statement forms a complete unit of computational logic. There are many types of statements and they are made up of a wide variety of elements. We have already encountered several types of statements in our simple "Hello, World" program:
- Simple statements: End with ;. return 0; is a simple statement.
- Block statements: Begin with { and end with }. They contain and group other statements. Here, we represent them as { … }, where … represents one or more statements of any type of valid statement.
- Complex statements: They consist of a keyword, a parenthetical expression, and one or more block statements. main(){…} is a complex statement; it has the main function identifier and other pre-defined elements, including a block statement. Complex statements include functions (which will be covered in this chapter), control statements (covered in Chapter 6, Exploring Conditional Program Flow), and looping statements (covered in Chapter 7, Exploring Loops and Iterations).
- Compound statements: These are made up of simple statements and/or complex statements that consist of multiple statements. The body of our program is a compound block statement that consists of two statements – a call to printf(); and a return 0; statement.
In our Hello, world! program, the following are other kinds of statements we have already encountered:
- Preprocessor directive: This begins with # and ends with <newline>. It isn't a C statement that performs computation; instead, it is a command to the compiler to process our C file in a specified way. Preprocessor directives do not follow C syntax and formatting but they are included in the language; we can think of them as outside of C syntax. They direct the compiler to do extra, preparatory stuff before the compiler gets down to the actual work of compiling the program.
- Function definition statement: The main() function is a function definition. A function definition is a complex statement that consists of several parts. We will explore this in detail in the next section. Every executable C program must have one – and only one – main() function defined. The main() function is a pre-defined name for a more general function statement. By adding statements to main(), we complete the function definition. We will also define our own function definition statements – or, put simply, our own functions.
A function definition alone does nothing. To execute the function – that is, to perform the statements within a function definition – the function must be called or invoked. main() is called by the system when we run a program. We will define our own functions and then call them.
- Function call statement: This is a simple statement. Just as main() is called by the system to be executed, we can call functions that have already been defined or that we have defined in our program. In this case, we call the pre-defined printf() function to do some of the work for us. When we call a function, the execution of the current statement of the current function is suspended; here, the execution jumps into the called function and continues in that function.
- Return statement: This is a simple statement that causes execution in the current function to end; execution then returns to the caller. In the main() function, when return is encountered, our program ends, and control returns to the system.
- Block statement: A block statement is a compound statement that consists of one or more statements enclosed in { }. Block statements are required for function definition statements and control statements – we will call these named blocks – and have a well-defined structure. However, we can also group statements into unnamed blocks to organize multiple statements into related units of computation. Unnamed blocks have a simple structure and can appear anywhere that a statement can appear. We'll explore this in greater depth in Chapter 25, Understanding Scope. Until then, our use of blocks will be both simple and intuitively obvious.
For completeness, here are the other statement types we will encounter later:
- Control statements: These include if() {…} else {…}, goto, break, and continue. The return statement is also a control statement. Like a call statement function, these change the order of the execution of statements within a function. Each has a well-defined structure. We'll explore these further in Chapter 6, Exploring Conditional Program Flow.
- Looping statements: These include while(){…}, do(){…}while, and for(){…}. They are similar to control statements, but their primary purpose is to iterate; that is, to perform a statement 0 or more times. We'll explore these further in Chapter 7, Exploring Loops and Iterations.
- Expression statements: These are simple statements that evaluate expressions and return some kind of result or value. We'll examine these in Chapter 5, Exploring Operators and Expressions.
Except for control, looping, and the wide variety of simple expression statements available, we have already encountered the essential C program statements that make up the bulk of our C programs.
Now, we will explore functions, function definitions, function return values, function parameters, and function calls further.
Introducing functions
Functions are callable segments of program code that perform one or more statements of related computational work. Functions group statements into a cohesive set of instructions that perform a specific, complex task. This may comprise a single statement, only a few statements, or many statements. Functions can also call other functions. Functions made up of one or more statements, are the next, higher-up, more complex units of program composition. Statements make functions; functions make programs. main() is a function made of statements and other functions.
The process of writing programs – or rather, solving a given problem – with a computer program is primarily the task of breaking the problem down into smaller pieces – into functions – and focusing on the work to be done in each smaller piece. When we break a problem down into smaller parts, we can easily see the essence of the problem. We can focus our attention either on aspects of the larger problem or on the fine details of the subdivided problem pieces.
We may be able to reuse a single problem piece – or function – so that we don't have to copy and paste it throughout the program whenever it is needed again. Anytime a function changes, we change it in only one place. If we discover that a function does not cover all the cases we originally expected, we can either expand its functionality, add a similar function to provide a slightly different solution, or break the function down into smaller functions.
This approach is preferable to writing one large program without any functions. In many cases, writing large, monolithic programs without functions can and has been done. However, each time, a program like this would require modification; the monolithic program would have to be understood in toto, so that even a small change might require the entire program to be considered. When a problem can be expressed so that we can see its major and minor parts, as implemented with functions, it is often easier to understand it generally and look at each of its components, which makes it easier to modify.
So, a major part of solving problems in C is breaking the problem into smaller, functional parts and writing functions to resolve each of the smaller problems.
Understanding function definitions
Functions are an essential part of any C program. Each function that you will create has the following parts:
- Function identifier: This is the name of the function. The name of the function should match what it does closely.
- Function result type or return value type: Functions can return a value to the caller; the caller may ignore the result. If a return value type is specified, the function must return a value of that type to the caller.
- Function block: A block that's directly associated with the function name and parameter list where additional statements are added to perform the work of the function.
- Return statement: The primary mechanism to return a value of the specified type from the called function to its caller.
- Function parameter list: This is an optional list of values that are passed into the function, which it may use as part of its calculation.
Let's examine each of these in turn. The goal is for you to begin to recognize, understand, and create the function statement pattern for yourself. We'll use the absolute minimum C program with main() as our example function and highlight each essential part.
The function type, function identifier, and function parameter list comprise a function signature. In a C program, each function identifier must be unique. In other languages, the complete function signature is considered, but not in C. When a function is called, only its function identifier is considered.
Each part of a function is illustrated in the following diagram:

Figure 2.2 – Parts of a function definition
Once a function has been defined with a function identifier, that function identifier cannot be redefined with a different function result type or function parameter list. Each function identifier in C must be unique.
Note that function signatures are not used in C to uniquely identify a function. Therefore, two functions with the same identifier but with different parameter lists or result types will cause a compilation to fail.
Exploring function identifiers
So, main() is a function just like any other function. However, it does have some significant differences – the main function identifier is pre-defined. The signature for it is also pre-defined in two specific ways. You cannot name any other function in your main program. Your program should never call main itself; main can be called by your program code but this is an unwise practice and should be avoided.
Function identifiers should be descriptive of their purpose. You would expect the printGreeting() function to print a greeting, as its name implies. Likewise, you would expect the printWord() function to print a single word. Naming functions to match their purpose is a good programming practice. Naming functions any other way – say, Moe(), Larry(), and Curly() – gives no real indication of what they do, even if, somehow in your conception, these three functions are related; this would be considered very bad programming practice.
Function identifiers are case-sensitive. This means that main, MAIN, Main, and maiN are all different function names. It is never a good idea to write function names all in uppercase since the shape of the word is lost. All uppercase text is extremely difficult to read and should, therefore, be avoided if possible. Every identifier in C is case-sensitive. So, this guideline applies to every other C identifier, too.
An exception to using all uppercase names is for names used in preprocessor directives. Here, by convention, preprocessor directive names tend to take all uppercase letters separated by underscores. This is a historical convention. It is best to avoid all uppercase identifiers in your C code and to leave this convention to the domain of the preprocessor. Separating uppercase/preprocessor names from lowercase/program identifiers makes it clearer to the reader of the program which identifiers are handled by the preprocessor and which are actual C program identifiers.
When two functions have a similar purpose but are slightly different, do not rely on differences in the upper or lowercase of their names to differentiate them. It is far better to make them slightly different in length or use different modifiers in their name. For instance, if we had three functions to change the color of some text to three different shades of green, a poor naming choice would be makegreen(), makeGreen(), and makeGREEN() (where the capitalization here seems to imply the intensity of the color green). A better choice that explicitly conveys their purpose would be makeLightGreen(), makeGreen(), and makeDarkGreen(), respectively.
Two common methods to make function names descriptive yet easy to read are camel case and underscore-separated, also known as snake case. Camel case names have the beginning characters of words within the name capitalized. In underscore-separated names, _ is used between words:
- All uppercase: MAKELIGHTGREEN(), MAKEMEDIUMGREEN(), and MAKEDARKGREEN()
- All lowercase: makelightgreen(), makemediumgreen(), and makedarkgreen()
- Camel case: makeLightGreen(), makeMediumGreen(), and makeDarkGreen()
- Snake case (or underscore-separated): make_light_green(), make_medium_green(), and make_dark_green()
As you can see, the all-lowercase names are somewhat difficult to read. However, these are not nearly as difficult to read as all-uppercase names. The other two ways are quite a bit easier to read. Therefore, it is better to use either of the last two.
If you choose one identifier naming convention, stick to it throughout your program. Do not mix different identifier naming schemes as this makes remembering the exact name of function identifiers, as well as other identifiers, much more difficult and error-prone.
Exploring the function block
The function block is where the function does its work. The function block defines what the function does. The function block is also known as the function body.
Within the function block, there are one or more statements. In our Hello, world! main() function, there are only two statements. In the following program, main.c, there is only one – the return 0; statement:
int main() {return 0;
}
While there is no ideal size, large or small, for the number of statements in a function block, typically, functions that are no longer than either the number of lines in a terminal, 25 lines, or a printed page – say, 60 lines – are preferable to much longer functions. The Goldilocks target – given multiple options, the one Goldilocks in the fairy tale Goldilocks and the Three Bears would have chosen – in this case, would be somewhere between 25 and 50 lines. Shorter functions are often preferred over much longer ones.
In some cases, however, longer functions are warranted. Rarely, if ever, are they considered good programming practice. The objective is to break the problem into meaningful subproblems and solve each one independently of the larger problem. By keeping functions small, the subproblem can be quickly grasped and solved.
Exploring function return values
A function statement can return a value to its caller. It does so from within its function block. The caller is not required to use the returned value and can ignore it. In Hello, world!, the printf() function call returns a value but we ignore it.
When a function statement is specified with a return type, it must return a value of that type. Such a specification consists of two parts:
- The return type of the function, given before the name of the function
- The return value, which is of the same type as the return type
In main.c, int – short for integer or whole number – is the type that's specified that the main() function must return to its caller. Immediately before the closing brace, we find the return 0; statement, which returns the 0 integer value. In most OS system calls (such as Unix, Linux, macOS, and Windows), a return value of 0, by convention, typically means no error is encountered.
If the return type of a function is void instead of int or some other type, there is no return value. The return statement is optional. Consider the following two functions:
void printComma() {...
return;
}
int main() {...
return 0;
}
Note
The ellipsis, ..., indicates that one or more other statements would appear here; it is not a valid C statement or expression. It is used to draw attention to simpler, uncluttered program syntax.
We have defined the printComma() function with a void return type. A void return type, in this context, means no return value, or that nothing is to be returned. In the function body, there is an explicit return statement. However, this return statement is optional; it is implied when the closing brace of the function body is encountered and execution returns to the caller. Note that the printComma() function has a return type of void; therefore, the return; statement provides no value in it.
In the following hello2.c program, return is expressed explicitly:
#include <stdio.h>
void printComma() {printf( ", " );
return;
}
int main() {printf( "Hello" );
printComma();
printf( "world! " );
return 0;
}
In the hello2.c program, we have a function whose purpose is only to print a comma and space to the console. Type out this program. Compile, run, and verify it. Verification should be familiar to you by now since we are creating the same output. Clearly, by itself, this is not a particularly useful function.
We intend to focus on moving from a single statement in our original Hello, world! program to a program that employs several functions to do the same thing. In each case, the output will be the same. In this chapter, we will focus on the mechanism of the function, not the actual utility of the function just yet. As we expand our knowledge of C, our functions will become more useful and more relevant.
Historical Note
In C99, the return 0; statement in the main() function is optional. If there is no return or return 0; statement, then the value of 0 is assumed to be returned by main(). This, by convention, means that everything is executed normally and all is well. With this in mind, the modern, minimal main() function now becomes the following:
int main() {
}
The previous main() function becomes the following:
int main() {
printf( "Hello" );
printComma();
printf( "world! " );}
Note that this was done for C++ compatibility. This rule, however, only applies to the main() function and no other. Therefore, for consistency, we will not follow this convention in any of our programs.
For functions that do return result codes, it is good programming practice to capture them and act on them if an error does occur. We will see how to do this in Chapter 4, Using Variables and Assignments, and Chapter 6, Exploring Conditional Program Flow.
Passing in values with function parameters
A function can be given values as input to the function. It can then use them within its body. When the function is defined, the type and number of parameters that can be passed in or received by the functions are specified. When that function with parameters is called, the values of the parameters must be given. The function call parameters must match the type and number of parameters specified. In other words, the function signature must match both the caller of the function and the called function.
We have already encountered a function that takes a parameter – the printf( "Hello, world! " ); function call. Here, the single parameter is a string with a value of "Hello, world! ". It could be almost any string, so long as it is delimited by "".
Function parameters are specified in the function definition between the ( … ) delimiters. The ellipsis indicates that there can be zero or more function parameters in the parameter list, separated by commas (a C token we haven't encountered yet). When there are no parameters, the definition looks like ( void ) or, as shorthand, just (). (void) and () are equivalent empty parameter lists.
Throughout this book, we will be explicit and use ( void ) when we declare an empty parameter list. However, it is very common to see the () shorthand for an empty parameter list. However, to call a function with an empty parameter list, we should only use ().
Each parameter consists of two parts: a data type and an identifier. The data type specifies what kind of value is being used – a whole number, a decimal number, a string, and so on. The identifier is the name that's used to access the value. Multiple parameters are separated by a comma. We will explore data types fully in the next chapter. A value identifier is very similar to a function identifier; where a function name can be called from somewhere, the parameter identifier is the name by which the passed in value can be accessed within the function body. Let's look at what parameter lists look like with zero, one, and two parameters:
void printComma( void ) { ...
}
void printAGreeting( char* aGreeting ) {...
}
void printSalutation( char* aGreeting , char* who ) {...
}
Take as given, for the moment, that the C type of a string that's passed into a function is char*. This will be introduced in Chapter 3, Working With Basic Data Types. We'll explore this in much greater detail in Chapter 15, Working With Strings. In each of these function parameters, the focus is on each parameter and then on each part of each parameter.
Within the function body, the parameter value can not only be accessed but can also be manipulated. Any such manipulations on the parameter value are only valid within the function body. Once the function body ends, the parameter values are discarded.
In the following program, we can see how to use the parameter values within the function body:
#include <stdio.h>
void printComma( void ) {printf( ", " );
}
void printWord( char* word ) {printf( "%s" , word );
}
int main( void ) {printWord( "Hello" );
printComma();
printWord( "world" );
printf( "! " );
return 0;
}
In the two functions defined, because the return type is void, the return; statement is, therefore, optional and omitted. In the first function, there are no function parameters, so the parameter list is void. In the second function, the parameter identifier is word. The parameter type is char*, which we'll take to mean a string. To use word as a string in the printf() function call, we must specify a different kind of escape sequence, %s, that's specific to the printf() function, which is called a format specifier. This specifier says to take the string value given in the next function parameter – in this case, word – and print it at this location in the string. We will casually introduce format specifiers as we encounter them; they will be examined in exhaustive detail in Chapter 19, Exploring Formatted Output. Notice how the definition for printComma() uses void to indicate an empty parameter list but that the call to printComma() in the main() function does not use void.
As we did previously, type in this program, then compile, run, and verify its output. The output should be Hello, world!.
Now, with these two functions, we can use them to build a more general greeting function that takes a greeting and an addressee. We could then call this function with two values: one value for the greeting and the other for who is being greeted. To see how this works, create a new file named hello4.c and enter the following program:
#include <stdio.h>
void printComma( void ) {printf( ", " );
}
void printWord( char* word ) {printf( "%s" , word );
}
void printGreeting( char* greeting , char* addressee ) {printWord( greeting );
printComma();
printWord( addressee );
printf( "! " );
}
int main( void ) {printGreeting( "Hello" , "world" );
printGreeting( "Good day" , "Your Royal Highness" );
printGreeting( "Howdy" , "John Q. and Jane P. Doe" );
printGreeting( "Hey" , "Moe, Larry, and Curly" );
return 0;
}
Again, for now, take as given that the char* parameter type specifies that a string is being used; this will be explained later. In hello4.c, we have moved the statements from the body of main into a newly declared function, printGreeting(), which takes two parameters of a string type. Now, we have a function that can be called with different values, which we saw in the main body. printGreeting() is called four times, each time with two different string parameters. Note how each string parameter is delimited by "". Also, note how only one printf() function prints <newline>. Save this program. Compile it and run it. You should see the following output:

Figure 2.3 – Screenshot of compiling and running hello4.c
Considering our functions and how they work, we may find that we don't need printComma() and printWord(), but we still want to provide a general printGreeting() function. We will combine printComma() and printWord() into a single printf() statement with two format specifiers. To do that, copy hello4.c into a file named hello5.c. Modify hello5.c so that it looks as follows:
#include <stdio.h>
void printGreeting( char* greeting , char* who ) {printf( "%s, %s! " , greeting , who );
}
int main( void ) {printGreeting( "Hello" , "world" );
printGreeting( "Greetings" , "Your Royal Highness" );
printGreeting( "Howdy" , "John Q. and Jane R. Doe" );
printGreeting( "Hey" , "Moe, Larry, and Curly" );
return 0;
}
This program is simpler than it was previously; it only defines one function instead of three. However, it still provides a general way to print various greetings via function parameters. Save this file. Compile and run it. Your output should be identical to that of hello4.c.
On the other hand, we may find that we need to break printGreeting() into even smaller functions. So, let's do this. Copy hello5.c into a file named hello6.c and modify it so that it looks as follows:
#include <stdio.h>
void printAGreeting( char* greeting ) {printf( "%s" , greeting );
}
void printAComma( void ) {printf( ", " );
}
void printAnAddressee( char* aName ) {printf( "%s" , aName );
}
void printANewLine( void ) {printf( " " );
}
void printGreeting( char* aGreeting , char* aName ) {printAGreeting( aGreeting );
printAComma();
printAnAddressee( aName );
printANewLine();
}
int main( void ) {printGreeting( "Hi" , "Bub" );
return 0;
}
In hello6.c, there are more, smaller functions we can use to print a greeting. The advantage of doing is this is to be able to reuse our functions without having to copy one or more statements. For instance, we could expand our program to not just print a greeting but also print a variety of sentences, a question, a normal sentence, and so on. An approach such as this might be appropriate for a program that processes language and generates text. Compile hello6.c and run it. You should see the following output:
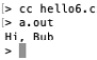
Figure 2.4 – Screenshot of compiling and running hello6.c
This might seem like a lot of functions just to print two words. However, as you can see, we can organize our program in many ways with functions. We can create fewer, possibly larger, or more general functions or decide to use more, possibly smaller, more specific functions. We can break functions into one or more other functions and call them as needed. All of these approaches will depend on the problem to be solved. So, while there are many different ways to organize a program, there is rarely a single way to do so.
You may be wondering why we define our functions with specific numbers of parameters, and yet the printf() function can take multiple parameters. This is called a variadic function. C provides a mechanism to do this. We will not explore this here; we will, however, touch on it briefly in the Appendix section with the stdarg.h header file.
In our explanations, to differentiate a function from some other program element, we will refer to a function containing name() (the parentheses after the identifier to indicate it is a function, where name is the function identifier).
As a means to express the relationship between functions clearly, consider the following:
- Functions are called and have a caller, which is the function that calls them. printComma() is called by printGreeting(). printGreeting() is the caller of printComma().
- The called function, or callee, returns to its caller. printComma() returns to printGreeting(). printGreeting() returns to main().
- A function calls another function, the callee, which is the function that is called. main() calls printGreeting(). printGreeting() calls printAddressee().
Historical Note
In K&R C (1978), function return types were assumed to be int unless otherwise specified. Also, function parameter information was specified somewhat differently. ANSI C (C90) added function prototypes, void function return types, and enhanced return types. Function definitions and prototypes have remained largely unchanged since C90. We will explore some additional enhancements when we encounter functions and arrays in Chapter 14, Understanding Arrays and Pointers.
Now that we have created a few functions – some simple, some comprised of other functions – let's take a closer look at how program execution proceeds from the caller to the callee and back to the caller. This is known as the order of execution.
Order of execution
When a program executes, it finds main() and begins executing statements in the main() function block. Whenever a function call statement is encountered, several actions occur:
- If there are function parameters, the actual values that are found in the function call statement are assigned to the function parameter names.
- Program execution jumps to that function and begins executing statements in that function block.
- Execution continues until either a return statement is encountered or the end of the block is encountered (the closing }).
- Execution jumps back, or returns, to the calling function and resumes from that point.
If, in Step 2, execution encounters another function call statement, the steps are repeated from Step 1.
The following diagram illustrates the call/return order of execution when function calls are encountered. Notice that in every case, the called function returns to the location of the callee. There is only one entry point to a function block – at its beginning – and typically only one exit point from a function block – at its end. This is generally known as structured programming. C largely enforces structured programming. In most cases, there is only one return statement in a program; C allows multiple return statements to be used within a function:
Historical Note
Before structured programming, some early programming languages permitted the use of an unrestricted goto statement, where the program flow could jump almost anywhere in the program. Extensive use of goto resulted in what was known as spaghetti code, where the flow of execution through the program was akin to following strands of spaghetti in a bowl. Such code was extremely difficult to understand and maintain.
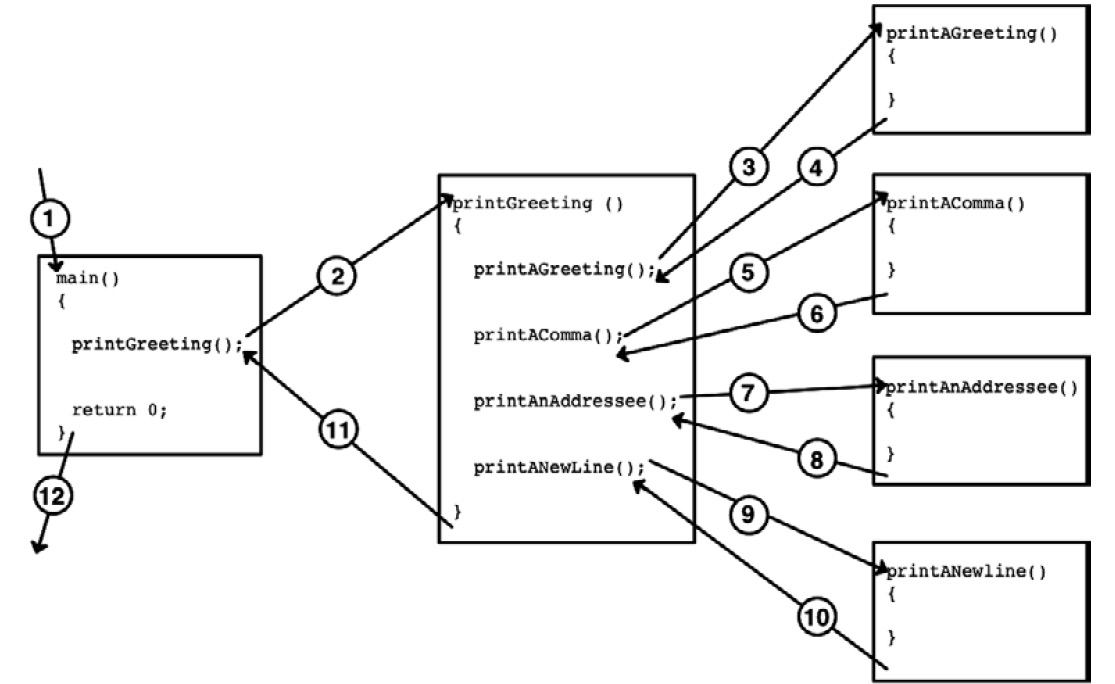
.
Figure 2.5 – Order of execution
The following steps are executed:
- The program is called by the system and begins execution at main().
- main() calls printGreeting(). Execution jumps to its function block.
- printGreeting() calls printAGreeting(). Execution jumps to its function block.
- printAGreeting() completes its function block and returns to printGreeting().
- printGreeting() then calls printAComma(). Execution jumps to its function block.
- printAComma() completes its function block and returns to printGreeting().
- printGreeting() then calls printAnAddressee(). Execution jumps to its function block.
- printAnAddressee() completes its function block and returns to printGreeting().
- printGreeting() then calls printANewline(). Execution jumps to its function block.
- printANewline() completes and returns to printGreeting().
- printGreeting() has completed its function block, so it returns to main().
- main() must return an integer, so the next statement that's processed is return 0;, which causes main() to complete its execution and return to the system.
In each case, when a function returns, it picks up immediately from where it left off in the calling function.
If there were any statements after return 0; or return;, they would never be executed.
You may have noticed that all the functions that we have used have been defined before they were called. What if we wanted to call them in any order? To do that, we need to understand function declarations.
Understanding function declarations
For the compiler to recognize a function call when it sees it, it must already know about the function. In other words, it must process the function statement's definition before it can process the call to that function. We have seen this behavior in all of our programs up to this point. In each program, we have defined the function and then, later in our program, called it.
This behavior is somewhat limiting since we may want to call a function from anywhere in our program. We don't want to get caught up in its relative position in the program and have to reshuffle the definitions of the functions just to make the compiler happy. The compiler is supposed to work for us, not the other way around.
C provides a way to declare a function so that the compiler knows just enough about the function to be able to process a call to the function before it processes the function definition. These are called function declarations. They tell the compiler the function's name, the return type, and the parameter list. They have no function body. Note that instead of the function body, they end with ;. We saw this earlier as the function signature. Elsewhere, the function definition must exist not only with the same function name, return type, and parameter list, but also to define the function block. In other words, the function signature in a function's declaration must match the function's definition, as well as the function when it is called. When function declarations differ from the function definitions, a compiler error occurs. This is a frequent cause of frustration.
Function declarations are also called function prototypes. In many ways, using the term function prototypes is less confusing than using the term function declarations; however, using either phrase is fine. We prefer to use function prototypes since that term is less similar to a function definition and so causes less confusion. In the hello7.c program, function prototypes are specified at the beginning of the program, as follows:
#include <stdio.h>
// function prototypes
void printGreeting( char* aGreeting , char* aName );
void printAGreeting( char* greeting );
void printAnAddressee( char* aName );
void printAComma( void );
void printANewLine( void );
int main( void ) {printGreeting( "Hi" , "Bub" );
return 0;
}
void printGreeting( char* aGreeting , char* aName ) {printAGreeting( aGreeting );
printAComma();
printAnAddressee( aName );
printANewLine();
}
void printAGreeting( char* greeting ) {printf( "%s" , greeting );
}
void printAnAddressee( char* aName ) {printf( "%s" , aName );
}
void printAComma( void ) {printf( ", " );
}
void printANewLine( void ) {printf( " " );
}
In hello7.c, we have rearranged the order of the function definitions. Here, functions are defined in the order that they are called. An ordering such as this is sometimes called top-down implementation since the functions that are called first also appear first in the program file. main() is called first so that the function definition is at the top. Those that are called later appear later in the file. printANewLine() is called last, so it shows up as the last function that's defined in the source file. This approach closely matches the process of starting with a whole problem and breaking it down into smaller parts. Our previous programs were ordered in a bottom-up implementation, where we start reading the code from the bottom, as it were. In those programs, main() appeared as the last function defined in the source file. It does not matter if you take a top-down or bottom-up approach.
For the compiler to be able to process functions in a top-down manner, function prototypes are required. Note that while any function prototype must appear before the function is called, the order they appear in is unimportant.
Before you add the function prototypes, you may want to copy hello6.c to hello7.c and rearrange the functions instead of typing in the program again. However, either method is fine. Try to compile the program. You may notice that you get the same kind of errors as when we removed the #include <stdio.h> line.
Note that the order of execution has not changed. Even though the order of the functions in hello7.c has changed in the source file, at execution time, each function is called in the same order as in hello6.c, and the graph of the order of execution, which was shown in the previous section, is also the same.
Once the functions are in the preceding order and main() is the first function, add the function prototypes, then compile, run, and verify that the output of hello7.c is identical to that of hello6.c.
It is good practice to put all the function prototypes together at the beginning of the file. This is not a requirement, however.
Function prototypes do not have to appear in the same order as the function definitions themselves. However, to do so, while tedious, makes it somewhat easier to find function definitions (function_C() is defined after function_B() and before function_D() and function_E(), for instance), especially when there are many function definitions. Then, we can use the order of the function prototypes as a kind of index of where to find the function definition in our source file.
You can now write programs consisting of the main() function and zero or more functions you define. The function definitions can appear in any order and can be called from anywhere within the program.
Summary
In this chapter, we began with a very simple C program and explored C statements. We expanded and changed our program through the use of functions. We saw how to define functions, call them, and declare function prototypes. Lastly, we saw how we can structure our programs using a top-down or bottom-up approach when implementing our programs.
Thinking about solving a problem in terms of breaking it down into smaller pieces, and then solving each via functions, is an essential skill to be able to solve complex problems in any programming language.
As we explore the remainder of the C syntax, we will demonstrate each feature through functions. We will explore how we can change functions to make our programs either more appropriate to our problem or to make it easier to understand how the problem is being solved.
In the next chapter, we will begin to develop an understanding of data types. Data types determine how to interpret values and what kind of manipulation can be done to those values.
Questions
Answer the following questions to test your knowledge of this chapter:
- Can you name the five types of statements we have already encountered?
- Can you name the three types of statements we have not encountered yet?
- Can you name the five parts of a function definition?
- What is another name for a function declaration?
- What is the difference between the function declaration and the function definition?
- Is a return statement always required? If not, why not?