
Chapter 24: Working with Multi-File Programs
To solve large problems, we often need large programs. All the programs we have developed so far have been small – under 1,000 lines of code. This is a reasonable size for a medium-sized program to, say, create a simple game, perform a basic but robust utility, or keep notes that may consist of anywhere between 10,000 to 100,000 lines of code. A large program would manage a company's inventory, track sales orders and bills of materials, provide word processing or spreadsheet capabilities, or manage the resources of the computer itself – an operating system. Such programs would consist of anywhere from 100,000 lines of code to a million or more lines of code. Such programs would have teams of programmers and require hundreds of man-years of effort to create and maintain.
As you gain experience in programming, you may find that the kinds of problems you work to solve become larger. Along with that, you will find that the size of the programs that solve those problems will commensurately become larger. These large programs are not one single large file. Rather, they are a collection of many files, compiled into a single program.
So far, we've used functions to organize operations. In this chapter, we will extend this idea to group functions into one or more program source code files. A program can then be made up of many source code files, with each file having a logical grouping of functions. Then, we can build programs with those multiple files.
There are many benefits to splitting large programs into multiple files. Specific areas/files can be developed by different programmers or programmer teams. Maintaining individual files is easier because they have a logical connection within a file. But the biggest benefit of using multiple files is reusability: the ability to use one or more source files in many programs. In this chapter, we will learn how to take a single file with many data structures and functions and logically break it into multiple source files and header files.
In this chapter, we will cover the following topics:
- Understanding how to group related functions into separate program files
- Understanding how to use header files versus source files
- Understanding that the preprocessor is powerful enough that we can easily hurt ourselves and others with it
- Building our multi-file program on the command line – making changes, rinse, and repeat
Technical requirements
As specified in the Technical requirements section of Chapter 1, Running Hello, World!, continue to use the tools you have chosen.
The source code for this chapter can be found at https://github.com/PacktPublishing/Learn-C-Programming-Second-Edition/tree/main/Chapter24.
Understanding multi-file programs
Before we get into the nitty-gritty of the differences between source files and header files, we need to understand why we need to have multiple source files at all.
In Chapter 23, Using File Input and File Output, we saw how some of the functions in the program we looked at pertained only to opening and closing files, and some of the functions pertained only to manipulating a linked list. We used the sortNames.c file to define the usage(), getName(), putName(), trimStr(), and, of course, main() functions. Each of these functions deals with some detail of input and output. Although you could argue that trimStr() belongs more logically in a string-handling source code file, we used it here to clean up the string from getName(), so here it stays. To sort the names, we used the functions that were declared in nameList.h and defined in nameList.c. These functions only dealt with the linked list structure. Since these functions were called from the main() functions, we needed their prototypes in that file; therefore, we put the structure and function declarations in a header file and included that header in both source code files.
Imagine that we have several programs that use a linked list to sort strings. If we ensure all the structures and functions are general enough for nameList, then we can reuse these functions without needing to rewrite them. In each program that needs to sort a linked list, we would only need to include the header file, nameList.h, and be certain that the source code file, nameList.c, is compiled into the final program. This serves three purposes, as follows:
- Functions that perform similar functions are kept together in one file. This logical grouping helps provide order when there are hundreds, or even thousands, of functions. Related functions will be found close together, making a large, complex program more easily understood. We saw something like this when we included multiple header files. For instance, all input/output (I/O) function prototypes can be seen in stdio.h, and nearly all string-handling functions can be found in string.h.
- Any changes that are made to those functions or structures in one file are limited primarily to just that file, not every program that uses those functions.
- By grouping related functions together, we can create subsystems of functions and use them to build up more complex programs with one or more subsystems.
After we explore some of the details of source files versus header files and the preprocessor, we will revisit the carddeck.c program – that is, the final version of the program from Chapter 16, Creating and Using More Complex Structures. That program is a single source file, so we will break it up. By the time we do that, you should clearly understand why breaking it up is appropriate.
Using header files for declarations and source files for definitions
The two types of files we will use to group functions are header files and source code files – or, more simply, just source files. Nearly all of the programs we have created thus far have been single-file source files that have included struct and enum definitions, typedef keywords, function prototypes, and functions. This is not typical in C programming; we have only been doing this to keep our programs more condensed. It is far more typical for C programs to consist of the main source file – where the main() function is defined – and one or more header files and auxiliary source files. The sortNames().c, nameList.h, and nameList.c programs are typical examples of common C programs.
Whenever the preprocessor sees the #include directive, which must be followed by a filename, it opens that file and reads it into the input stream for compilation at that location, just as if we had typed in the contents of the file ourselves. The filename must be surrounded by either < and > or " and ". Each of these has a special meaning to the preprocessor. The angle brackets tell the preprocessor to look in predefined locations that are relative to the compiler for the given filename, while the quotation marks tell the preprocessor to look in the current directory for the filename.
Creating source files
As we have already seen in our single-file programs, we can put pretty much anything and everything in a source file. We use source files primarily to define functions and we put all the rest, or almost all of the rest, in a header file to be included in the source file.
A source file can be laid out in any number of ways. We can define all the functions before they are called and have the main() function at the very end, or we can use function prototypes at the top of the program and place our function definitions in any order, with the main() function typically appearing immediately after the function prototypes. However, there are perfectly good reasons to keep some things in the source file only; we will explore these reasons fully in Chapter 25, Understanding Scope.
Since we know what a source file with everything in it looks like, let's focus on which things go into a header file and which things do not.
Thinking about multiple source files
When we have a complex program that employs a variety of data structures and functions to perform I/O get user interaction, manipulate our data structures, and so on, we would like it to consist of multiple source files and their corresponding header files. But how should we think about organizing such a complex program into smaller source files and corresponding header files?
The simplest and most effective guideline is to organize each source file around an individual data structure. The header file defines the structure and function prototypes that manipulate that data structure. The source file contains the definitions of the functions that manipulate that data structure. Those functions are specific to that data structure. We will do this when we divide our carddeck.c program into multiple header and source files.
Be aware, however, that not every function and not every data structure may deserve a source/header file. There will always be exceptions to this simple guideline.
For instance, we could have a simple main() source file with an accompanying file handling the source file, and a command-line option for handling the source file when both of these groups of operations are complex or involve a lot of code. On the other hand, if these operations are rather simple, then it may make more sense to keep them all in the main() source file.
Let's consider header file contents a bit more closely.
Creating header files
Header files are used for the following reasons:
- Header files remove the clutter of function prototypes and the declaration of custom types from the source file. They are moved to a header file to be included in the source file.
- For functions that are called from a different source file, including the header file with those function prototypes provides access to those functions. Simply including the header file makes them available within that program.
- For custom data types that are used in other source files, including the header file with those custom data type declarations makes those custom types known within the other source files.
- Header files help you organize all of the C Standard Library header files, as well as our header files, into a single header file. An example of this would be a source file that includes, say, the stdio.h, stdlib.h, and string.h header files, while another source file includes, say, the stdio.h, math.h, and unistd.h header files. Note that stdio.h is needed in both source files but the other standard headers are only needed in one source file. We could create a single header file – say, commonheaders.h – that includes all of those headers and itself, which is then included in each of the source files.
- This is not always done in a program; however, when there are many source files and a wide variety of standard library headers spread all over the source files, it is a good way to centralize header file inclusion and avoid accidentally omitting a necessary header.
There are some very simple rules to follow for the contents of header files. These are driven by the fact that a given header file may be used in more than one file. Many programmers create header files for their source files without really thinking about why. A simple guideline on when to create a header file at all is as follows:
Only create a header file when it will be used in two or more files.
Another way to put this is like so:
Everything in a .h file should be used in at least two.c files.
Recall that in the sortNames program, the nameList.h header file was included in both sortNames.c and nameList.c. Often, the habit of creating a header file for each source file is so commonplace that it is done without much thought. Creating such header files is similar to using { and } for the if()… else… statement blocks, even when they aren't needed; it does little harm and helps organize your source files. I find that whenever I create the .c file, I automatically create the .h file for it as well.
So, what goes in a header file? Here are some examples:
- Function prototypes; in other words, anything that declares a function but does not define it.
- Custom type definitions (enums and structs).
- Preprocessor directives such as #define and #include.
- Anything that defines a type but does not allocate memory, such as typedef declarations and struct types defined by the typedef and enum types.
extern declarations are references to variables that are defined (allocated) in source files. The variables are not allocated in the header file but the extern declaration makes them visible in the same way that function prototypes make functions visible. We will explore this further in the next chapter, Chapter 25, Understanding Scope.
Conversely, what does not go into a header file? There are two main categories, as follows:
- Anything that allocates memory, such as variable declarations and constant declarations
- Function definitions
When a constant or variable is declared, memory is allocated. This occurs regardless of whether the variable is an intrinsic type or a custom type. If a variable is declared in a header file and that header file is included multiple times, the compiler will try to allocate memory each time using the same name. This results in the compiler being unable to determine which memory is being referenced by the variable identifier. This is called a name clash. The compiler will generate at least one error when it encounters multiple defined variables of the same identifier.
When a function is defined, the compiler remembers the address of that function, among other things. When the function is called, it jumps to that address to execute the function. If a function is defined in a header file and that header file is included multiple times, the function will have multiple addresses for the same function and the compiler will be unable to determine which function should be used. This is also called a name clash. The compiler will generate at least one error when it encounters a function that's been defined more than once.
As we break carddeck.c into several header and source files, we will introduce a way to use the preprocessor to avoid these name collisions. However, the idea of keeping variable declarations and function definitions out of header files is such a long-standing practice that to alter it is a very bad programming practice. Other programmers expect header files not to have memory allocation or function definitions. Once a header file exists, it is assumed that it can be included as many times as needed. There is no good reason to alter this deeply ingrained practice.
To be clear, as we have seen, anything that could go into a header file doesn't have to; it can occur in the source file where it is used. Why we would put something in a header file or not is a topic for Chapter 25, Understanding Scope. For now, we will use a single header file for each C source file as a means to declutter the source file.
Revisiting the preprocessor
The preprocessor is a very powerful utility; therefore, it must be used with great care. We can't eliminate it since it is an essential part of developing multi-file programs. In this section, we will explore how to use the preprocessor. Our goal is to find, just as Goldilocks did, the just-right amount of preprocessing to employ – not too much and not too little.
Introducing preprocessor directives
The preprocessor is a simple macro processor that processes the source text of a C program before the program is read by the compiler. It is controlled via single-line preprocessor directives and transforms the source text by interpreting macros embedded in the source text to substitute, add, or remove text based on the given directives. The resulting preprocessed source text must be a valid C program.
The following table provides an overview of the basic preprocessor directives:
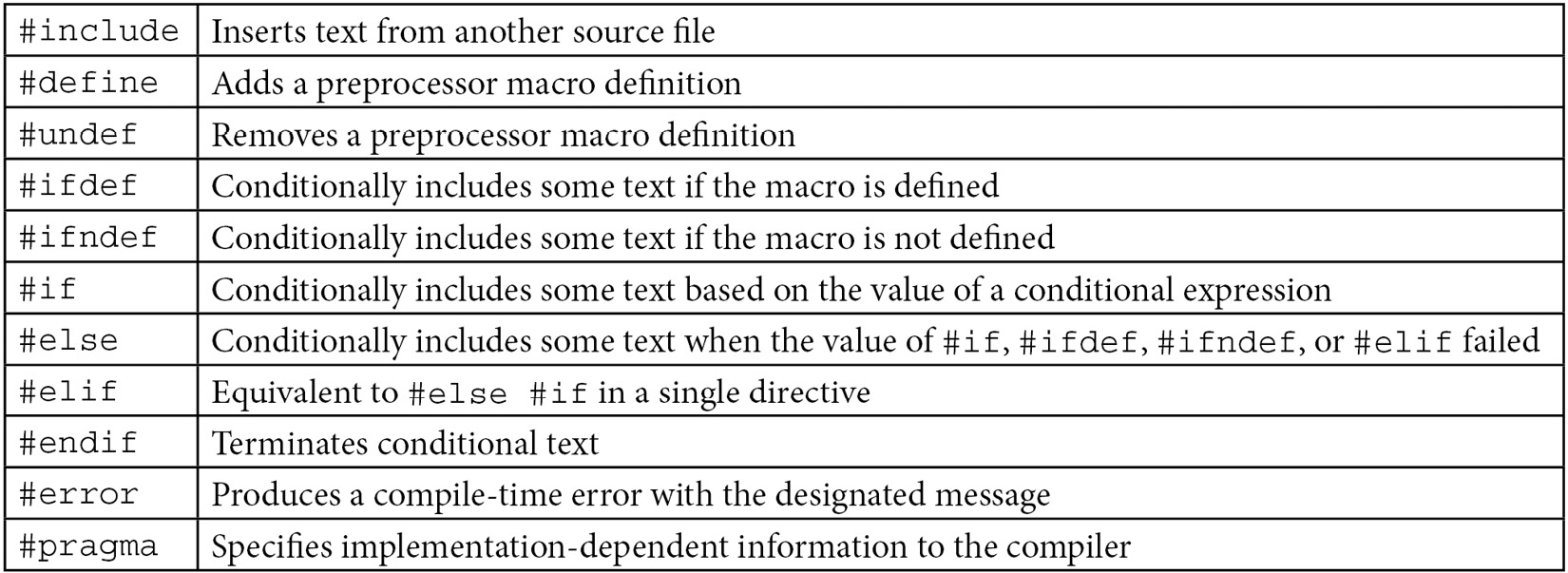
There are a small number of other directives that have specialized use, but they haven't been covered here.
The main feature of the preprocessor is that it largely performs textual substitution. Herein lies both its power and its danger. It does textual substitution, but it doesn't understand C syntax or any syntax at all.
Historical Note
In the early versions of C, the preprocessor was used to fill in the gaps for features that were needed but were not part of the language specification. As time went on, C added features that have diminished the need for using the preprocessor but have not eliminated that need yet.
Understanding the limits and dangers of the preprocessor
Because the preprocessor provides simple programming-like commands, it becomes very tempting to use it as a programming language. However, because it is merely a simple macro processor that does not understand syntax, the results of its output can be very misleading, resulting in code that compiles but behaves unpredictably.
There are circumstances where using the preprocessor in complicated ways is warranted. Those are, however, circumstances that require advanced programming techniques and rigorous verification methods that are outside the scope of this book. It is for this reason that I recommend keeping our use of the preprocessor both as simple and as useful as possible.
Using the preprocessor effectively
The following are some guidelines for using and not using the preprocessor effectively:
- If you can write a function in C, do that instead of using a preprocessor macro.
- You may also want to consider using the inline C declaration. inline provides a suggestion to the compiler to place the body of the function wherever it is called as if a textual substitution were done. This has the advantage of preserving all type checking, as well as eliminating the overhead of a function call. inline becomes useful in very high-performance programming situations.
- Use the preprocessor as a last resort for performance. Eliminating statements or function calls as a means of improving performance is known as central processing unit (CPU) cycle trimming and is highly subject to even minor variations in system configurations. Therefore, strive to pick the best, most efficient algorithm before resorting to cycle trimming.
Don't ever assume performance will be improved by any technique or trick; actual performance must be measured before and after to determine any effects on performance. Entire volumes have been written about how to both measure and improve performance.
- Prefer const <type> <variable> = <value>; over #define <name> <literal>. In the former case, type information is preserved, whereas in the latter case, there is no type information, so we can never be certain if the macro will be used properly.
- Prefer enum { <constantValue> = <value>, ... } over #define <name> <literal>. You may want to declare an array size, say, in a structure, but the compiler won't allow you to use a const int value. Many consider C's array definition a deficiency of the language, so many programmers use #define largely for this reason. Rather than drag the preprocessor into it, you can declare an identifier in an enum block and give it a constant value. We will see how this works in the program at the end of this chapter.
- It is tempting to write macro symbols that appear as functions with parameters. Because you don't know how the macro will be used, unexpected and unpredictable behavior may occur.
- Control the use of included headers with simple preprocessor directives.
The last two items deserve further exploration.
Extreme care must be taken when you're crafting function-like macro symbols.
In Chapter 5, Exploring Operators and Expressions, the following two macros were briefly mentioned:
#define celsiusToFahrenheit(x) (((x)*9.0/5.0)+32)
#define fahrenheitToCelsius(x) (((x)-32)*5.0/9.0)
Notice the rather peculiar and unintuitive extra set of ( ) around x. Why may this be needed? In most cases, this macro might be used with a single value or a variable. What happens when the macro is called with an expression, such as temp1 + 5 or temp2 - temp1? Without the extra parenthesis, arithmetic precedence rules would apply and give an entirely unpredictable result.
This is but one example of how crafting function-like macro definitions can be dangerous.
The preprocessor is essential to controlling the use of header files. When a header file is included in a source file, its content is copied into the source file at compile time. If the header file is also included in another header file, as often happens, it will be included in the source file. This will cause name clashes. The way to prevent this is to use three preprocessor directives in the header file, as follows:
#ifndef _SOME_HEADER_FILE_H_
#define _SOME_HEADER_FILE_H_
// contents of header file
...
...
...
#endif
The first directive tests whether the _SOME_HEADER_FILE_H_ macro has already been defined. If so, this means that this particular header file would have already been processed at least once, and all of the text of the file is ignored until the last directive, #endif, which should be the last line of the header file.
The first directive tests whether the _SOME_HEADER_FILE_H_ macro has not already been defined. If it has not, the next directive defines it, and the rest of the header file text is inserted into the source file. The next time this file is encountered by the preprocessor, the macro will have been defined and this test will fail, excluding all the text until the #endif directive.
This method ensures that a header file will always only be included once. To use this method effectively, the macro symbol for the header file should be unique. Typically, using the filename with all caps and underscores in the manner shown is effective and guarantees uniqueness.
Debugging with the preprocessor
So, we have seen two instances of using the preprocessor effectively: for #include files and limiting redundant processing of #include files. The last simple and effective use for the preprocessor is as a tool for debugging large and/or complex programs of multiple files.
Using conditional directives, we can easily control what source code is inserted into the source file or excluded from the source file. Consider the following directives:
...
#if TEST_CODE
// code to be inserted and executed in final program
fprintf( stderr, "This is a test. We got here. " );
#endif
...
If the TEST_CODE macro is defined and has a nonzero value, the statements within the #if and #endif directives will be included in the source file. For this code to be included, we can define the macro in a couple of ways. First, it can be defined in the main source file with the following code:
#define TEST_CODE 1
This statement defines that the TEST_CODE macro must have a value of 1 (nonzero, which implies TRUE). If we wanted to turn off the test code but keep the macros in place, we would change the line in the preceding code snippet to the following:
#define TEST_CODE 0
This defines TEST_CODE and gives it a value of 0 (zero, which implies FALSE), which will prevent the test statements from being inserted into the source code.
An alternative way is to define the macro on the command line for compilation, as follows:
cc myProgram.c -o myProgram -Wall -Werror -std=c11 -D TEST_CODE=1
The -D option defines the TEST_CODE macro and gives it a value of 1. Note that command-line macros are processed before directives in any file.
When I have to test a wide variety of features in a very complex program, I use a set of macros, such as the following:
#if defined DEBUG
#define DEBUG_LOG 1
#define DEBUG_LOG_ALIGN 0
#define DEBUG_LOG_SHADOW 0
#define DEBUG_LOG_WINDOW 0
#define DEBUG_LOG_KEEPONTOP 1
#define DEBUG_LOG_TIME 1
#else
#define DEBUG_LOG 0
#define DEBUG_LOG_ALIGN 0
#define DEBUG_LOG_SHADOW 0
#define DEBUG_LOG_WINDOW 0
#define DEBUG_LOG_KEEPONTOP 1
#define DEBUG_LOG_TIME 0
#endif
This set of macro definitions existed alone in a header file. Then, I could turn a whole set of debugging macro symbols on or off via the command line by simply adding -D DEBUG to the command-line options. Sprinkled throughout this program, which consisted of over 10,000 lines of code in approximately 230 files, were #if defined DEBUG_LOG_xxx ... #endif directives with a few lines of code to provide logging as the program was executing. I've found this rudimentary method, sometimes called caveman debugging, to be effective.
A similar mechanism can be used to insert one set of statements or another set of statements into the source file. Consider the following directives:
...
#if defined TEST_PROGRAM
// code used to test parts of program
...
#else
// code used for the final version of the program (non-testing)
..
#endif
When the TEST_PROGRAM macro is defined, the statements up to #else are inserted into the source file. When TEST_PROGRAM is not defined, the statements in the #else branch are inserted into the source file.
This method is handy when you need to use a set of source files for testing and need the main() function for testing but don't need it when the source is part of another set of source files. On the other hand, care must be exercised to prevent test code behavior from varying too widely from the final code. Therefore, this method is not applicable in all cases.
Any further discussion of debugging is beyond the scope of this book.
Sometimes, you may find that you want to explore several ways to do the same thing in C. However, after your exploration, you have two or more methods but you only need one. Rather than comment out the statements you don't want, you can put them all in the #if 0 ... #endif block. The 0 value will always be false and the statements between #if and #endif will be excluded at compile time from the source code file. Some of the programs in the source code repository for this book will use this method to exclude an alternate method, to perform a series of steps.
We now have four effective yet simple uses for the preprocessor, as follows:
- To include header files
- To limit redundant processing of header files
- For caveman debugging
- To exclude a set of statements with #if 0 ... #endif when we are experimenting with our program
Now, we are ready to create a multi-file program from a single-file program.
Creating a multi-file program
We will take the final version of the carddeck.c single-file program from Chapter 16, Creating and Using More Complex Structures, and reorganize it into multiple header files and source files. You may want to review the contents and organization of that file now before we begin.
We are going to create four .c files, each with .h files; we will create eight files in total. These files will be named as follows:
- card.c and card.h to manipulate the Card structure.
- hand.c and hand.h to manipulate the Hand structure.
- deck.c and deck.h to manipulate the Deck structure.
- dealer.c and dealer.h to be the main program file; dealer.h will be included in each of the source files when possible.
First, create a separate folder where these eight new files will exist. You may copy carddeck.c to this folder or you may choose to leave it in its original location. We want to copy and paste pieces of the source file into each of our eight new files. If possible, with your editor, open carddeck.c in a separate window. It is from this window that you will be copying sections of carddeck.c and pasting them into new files. This is the approach we will be taking. An alternative approach, which we are not going to describe here, would be to copy carddeck.c eight times to each of those files and then pare down each of them to their new purposes.
In the end, this collection of programs will run as it did previously and produce the same output it did previously. This will be proof of our successful transformation.
Extracting card structures and functions
As we extract this file, we will be going through carddeck.c to find the relevant bits. Follow these steps:
- Create and open the card.h header file and place the following new lines:
#ifndef _CARD_H_
#define _CARD_H_
#endif
This is our starting point for this header file. We use the macro directives, as we explained earlier, to ensure that anything in this file is only preprocessed once. The _CARD_H_ macro is used nowhere else in the program except in this single header file. Everything else that we put in this file will be after #define _CARD_H_ and before #endif.
Next, we would normally add the necessary header files. We will save this for later when we finish creating the dealer.c and dealer.h files.
- In carddeck.c, you should see several const int definitions. The only ones of these that pertain to the Card structure are kCardsInSuit, kWildCard, and kNotWildCard. Rather than keep them as this type, we will use the following enum declaration to define them:
enum {
kCardsInSuit = 13
}
extern const bool bWildCard;
extern const bool bNotWildCard;
We've done this to give these identifiers actual constant values. We will need this when we declare a hand or deck structure and need to specify the array size with a constant value.
Note that the extern keyword is used to indicate that the constant variable is declared (allocated) elsewhere.
- Next, copy the typedef enum { … } Suit; declaration, the typedef enum {… } Face; declaration, the typedef struct { … } Card; declaration, and the three Card functions, InitializeCard(), PrintCard(), and CardToString(), from carddeck.c to card.h. The header should now look as follows:
#ifndef _CARD_H_
#define _CARD_H_
enum {
kCardsInSuit = 13
};
extern const bool bWildCard;
extern const bool bNotWildCard;
typedef enum {
eClub = 1, eDiamond, eHeart, eSpade
} Suit;
typedef enum {
eOne = 1, eTwo , eThree , eFour , eFive , eSix , eSeven ,
eEight , eNine , eTen , eJack , eQueen , eKing , eAce
} Face;
typedef struct {
Suit suit;
int suitValue;
Face face;
int faceValue;
bool isWild;
} Card;
void InitializeCard( Card* pCard , Suit s , Face f , bool w );
void PrintCard( Card* pCard );
void CardToString( Card* pCard , char pCardStr[20] );
int GetCardFaceValue( Card* pCard );
int GetCardSuitValue( Card* pCard );
#endif
We have grouped all of the constant values (via enum), the Card structure definition, and the functions that operate on a Card in a single file. Save this file.
Typically, in card.c, you would include card.h and any other standard library headers. But in this program, we are going to have a single header file that is included in all the source files. We will get to that when we finish creating dealer.h. The first line in card.h should be #include "dealer.h".
- Next, open card.c and add the following definitions:
- const bool bWildCard = true;
- const bool bNotWildCard = false;
- Remember that they were declared as extern in the header file. We have defined them here. Note that any variable or constant that's declared as extern must be defined somewhere exactly once.
- To finish this extraction, find the InitalizeCard(), PrintCard(), and CardToString() functions in carddeck.c and copy them into card.c. Your card.c source file should look as follows:
#include "dealer.h"
const bool bWildCard = true;
const bool bNotwildCard = false;
void InitializeCard( Card* pCard, Suit s , Face f , bool w ) {
// function body here
...
}
void PrintCard( Card* pCard ) {
// function body here
...
}
void CardToString( Card* pCard , char pCardStr[20] ) {
// function body here
...
}
The card.c source file has a single #include file, definitions for bWildCard and bNotWildCard, and three function definitions that manipulate a card. We have omitted the statements in the function bodies of these functions for brevity. Save this file. Now, we are ready to move on to the Hand files.
Extracting hand structures and functions
Just as we extracted the typedef, enum, and struct instances, along with the functions for the Card structure, we will do the same for Hand structures. Follow these steps:
- Create and open the hand.h header file and place the following new lines:
#ifndef _HAND_H_
#define _HAND_H_
#endif
This is our starting point for this header file. Looking through carddeck.c once more; there are a couple of const int types related to Hand that we need to add as enum instances, as follows:
enum {
kCardsInHand = 5,
kNumHands = 4
};
- Next, let's add the typedef struct { … } Hand; declaration and the four function definitions related to the Hand structure – InitializeHand(), AddCardToHand(), PrintHand(), and PrintAllHands(). However, notice that the parameter of one of these functions is a Card* parameter, so the compiler will need to know about the Card structure when it encounters this prototype. This means we will need to include the card.h header file. After making these additions, hand.h should look as follows:
#ifndef _HAND_H_
#define _HAND_H_
#include "card.h"
enum {
kCardsInHand = 5,
kNumHands = 4
};
typedef struct {
int cardsDealt;
Card* hand[ kCardsInHand ];
} Hand;
void InitializeHand( Hand* pHand );
void AddCardToHand( Hand* pHand , Card* pCard );
void PrintHand( Hand* pHand , char* pLeadStr );
void PrintAllHands( Hand* hands[ kNumHands ] );
#endif
hand.h now has the constant values it needs, the structure definition for Hand, and the function prototypes to manipulate the Hand structure. Save hand.h.
- Create and open hand.c. As with card.c, find the four function definitions in carddeck.c and copy them into hand.c. Add the #include "dealer.h" directive to hand.c. It should now appear as follows:
#include "dealer.h"
void InitializeHand( Hand* pHand ) {
// function body here
...
}
void AddCardToHand( Hand* pHand , Card* pCard ) {
// function body here
...
}
void PrintHand( Hand* pHand , char* pLeadStr ) {
// function body here
...
}
void PrintAllHands( Hand* hands[ kNumHands ] ) {
// function body here
...
}
The hand.c source file contains a single #include directive and four function definitions that manipulate a card. We have omitted the statements in the function bodies of these functions for brevity. Save this file. Now, we are ready to move on to the Deck files.
Extracting deck structures and functions
Just as we extracted the typedef, enum, and struct instances, along with the functions for the Card and Hand structures, we will do the same for Deck structures. Follow these steps:
- Create and open the deck.h header file and place the following new lines:
#ifndef _DECK_H_
#define _DECK_H_
#endif
This is our starting point for this header file. Looking through carddeck.c again; there is one const int related to Hand that we need to add as an enum, as follows:
enum {
kCardsInDeck = 52
};
- Next, let's add typedef struct { … } Deck; and the four function definitions related to the Deck structure – InitializeDeck(), ShuffleDeck(), DealCardFromDeck(), and PrintDeck(). However, notice that the Deck structure contains two Card arrays and one function returns a Card*, which is a pointer to the Card structure, so the compiler will need to know about the Card structure when it encounters this structure and the function prototype. We will need to include the card.h header file. After making these additions, deck.h should look as follows:
#ifndef _DECK_H_
#define _DECK_H_
#include "card.h"
enum {
kCardsInDeck = 52
};
typedef struct {
Card ordered[ kCardsInDeck ];
Card* shuffled[ kCardsInDeck ];
int numDealt;
bool bIsShuffled;
} Deck;
void InitializeDeck( Deck* pDeck );
void ShuffleDeck( Deck* pDeck );
Card* DealCardFromDeck( Deck* pDeck );
void PrintDeck( Deck* pDeck );
#endif
- deck.h now has the constant value it needs, the structure definition for Deck, and the function prototypes to manipulate the Deck structure. Save deck.h.
- Create and open deck.c. As with card.c, find the four function definitions in carddeck.c and copy them into deck.c. Add the #include "dealer.h" directive to deck.c. It should now appear as follows:
#include "dealer.h"
bool bRandomize = true; // default if not set elsewhere
void InitializeDeck( Deck* pDeck ) {
// function body here
...
}
void ShuffleDeck( Deck* pDeck ) {
// function body here
...
}
Card* DealCardFromDeck( Deck* pDeck ) {
// function body here
...
}
void PrintDeck( Deck* pDeck ) {
// function body here
...
}
The deck.c source file has a single #include directive and four function definitions that manipulate a deck. It also contains the definition for bRandomize. Note that this is not in the header file. This variable is only ever used inside this source file, so it does not need to be visible to other source files. However, the fact that this definition is buried inside this source file is not an ideal situation. To remedy this, we will declare this extern variable in dealer.c and set it there at the beginning of main(). We have omitted the statements in the function bodies of these functions for brevity. Save this file. Now, we are ready to finish creating the dealer files.
Finishing the dealer.c program
Having extracted the Card, Hand, and Deck declarations and functions, we can finish the program. Follow these steps:
- Create and open the dealer.h header file and add the following new lines:
#include <stdbool.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <time.h>
#include "card.h"
#include "hand.h"
#include "deck.h"
Looking through carddeck.c, all we need to do is transfer the standard library header files to dealer.h. We also created three header files for each of the three .c source files; we will add them to this header file. Recall that we also included this header file in each of the three source files. Also, remember that we added the #ifndef … #endif exclusion directives around each of those header files so that they will only be preprocessed once. This header file contains all of the standard library headers that any of the source files could need and contains the header files for each of the three source files. Save this file.
- Create and open dealer.c. The only thing left to transfer to dealer.c is the main() function. The dealer.c file should appear as follows:
#include "dealer.h"
extern bool bRandomize; // defined in deck.c
int main( void ) {
Deck deck;
Deck* pDeck = &deck;
bRandomize = false;
InitializeDeck( pDeck );
PrintDeck( pDeck );
ShuffleDeck( pDeck );
PrintDeck( pDeck );
Hand h1 , h2 , h3 , h4;
Hand* hands[] = { &h1 , &h2 , &h3 , &h4 };
for( int i = 0 ; i < kNumHands ; i++ ) {
InitializeHand( hands[i] );
}
for( int i = 0 ; i < kCardsInHand ; i++ ) {
for( int j = 0 ; j < kNumHands ; j++ ) {
AddCardToHand( hands[j] , DealCardFromDeck( pDeck ) );
}
}
PrintAllHands( hands );
PrintDeck( pDeck );
return 0;
}
The main() function controls all the work of this program. It declares a Deck structure and calls the Deck functions to manipulate that deck. The #include file that provides the declarations for this in deck.h is included here within dealer.h. Next, four Hand structures are declared, and a Hand function is called to initialize the hands. The #include file that provides the declarations for this in hand.h is included here within dealer.h. Then, cards are dealt from the deck and placed into the hands. Within main(), there is no direct reference to a Card. Therefore, card.h is not directly needed for dealer.c. However, the structures and functions of Card are needed by both Hand and Deck. The source files for Hand and Deck need to know about the Card structures and functions. These kinds of header file interdependencies are the primary reason they are all put into a single header that is included in each source file.
An alternative approach would have been to include only the header files that are needed to compile that source file in each file. In this approach, dealer.c would only need to include deck.h and hand.h. In deck.c, the included files would be deck.h, card.h, stdio.h, stdlib.h, and time.h. In hand.c, the included files would be hand.h, card.h, and stdio.h. Finally, in card.c, the included files would be card.h, string.h, and stdio.h. This approach was not taken because using a single header file is both more reliable and more flexible if/when these source files are used in a larger program.
With that, we have eight files that make up our program. Let's build it.
Building a multi-file program
In all of our single-file programs, we used the following command line to build them:
cc <sourcefile>.c -o <sourcefile> -Wall -Werror -std=c17
In the two-file program from Chapter 23, Using File Input and File Output, we used the following command line to build it:
cc <sourcefile_1>.c <sourcefile_2>.c -o <programname> <additional options>
The compiler command line can take multiple source files and compile them into a single executable. In this program, we have four source files, so to compile this program, we need to put each source file on the command line, as follows:
cc card.c hand.c deck.c dealer.c -o dealer <additional options>
The order of the list of source files does not matter. The compiler will use the results of the compilation of each file and build them into a single executable named dealer.
Compile the program with the preceding command. The program should compile without errors. Run the program. You should see the following output:

Figure 24.1 – Screenshot of the output of dealer.c
Note that this output is the same as what was shown in Chapter 16, Creating and Using More Complex Structures.
Once you get this program working, spend some time commenting out one or more header files and recompiling to see what kind of errors you get. For instance, what happens when you comment out #include deck.h? What happens when you comment out #include hand.h? What happens when you comment out #include card.h? After each experiment, make sure you undo your experiment and verify that you can compile the program. Once you have explored those experiments, you may also want to try the alternative approach to including headers that was mentioned at the end of the preceding Finishing the dealer.c program section.
Whichever method of including header files you choose, ensure you get the program to work as expected. We will use these eight files to build two card games, Black Jack and One-Handed Solitaire, in the remaining chapters of this book.
Finally, be aware that you will develop the ability to naturally create separate source files and header files as you develop your programs. As you think about the parts of the program you are working on, you will see the logical grouping of data structures and the functions that manipulate them. By doing so, you can focus on a single grouping rather than try to simultaneously think about the whole program.
Summary
In this chapter, we took a single source file made up of many structures and functions that operate on them and grouped them into four source code files and four header files. We saw how we could – and should – group structures and functions that operate on them into a source file and a corresponding header file. All of the functions were related, in that they operated on the structures declared in that file's header file. These many source files were then compiled into a single program. After that, we built programs with those multiple files. We also explored simple yet efficient ways to use the preprocessor without overusing it. Lastly, we learned how to build a multi-file program by specifying each .c file on the compiler's command line.
This chapter was just an introduction to multi-file programs. In the next chapter, Chapter 25, Understanding Scope, we will expand our knowledge of multi-file programs so that we can both limit which variables and functions can be called from within a single file, as well as expand the visibility of variables and functions.
Questions
Answer the following questions to test your knowledge of this chapter:
- Can you declare structures in a header file?
- Can you allocate an array in a header file?
- Can you define functions in a header file?
- How many times can you define a function?
- How do you prevent name clashes when using header files?
- Can you tell that I think getting tricksy with the preprocessor is a really bad idea?