
So far, we have successfully installed Trove, created images for the templates, and also spun up instances by using the CLI and the GUI. In this chapter, we will understand the following things about Trove:
- How the default configuration of the instance is determined
- How to make modifications to the configuration of a single or a group of instances using configuration groups in Trove
- How to resize the Trove instances
Each database engine, be it MySQL, MongoDB, Percona, and so on, has a default configuration file that the database engine looks for, when starting the service on the guest instance.
The Trove system sends this configuration file using the guest agent (we can see this if we intercept the Prepare message sent in the RabbitMQ queue as shown in the previous chapter). In this section, we will take a look at where Trove stores this information and how we could change it in order to suit our company's needs.
The default configuration that is used by all instances to start up is set in template files. trove.conf has a configuration option called template_path that is used to specify the folder where the datastore templates are being stored.
The default value of this in a package install is /etc/trove/templates. On a DevStack instance that we are running, the default value is trove/templates in the path where Trove is installed. The full path is /opt/stack/trove/trove/templates.

This contains one subfolder for each of the datastores that Trove supports. The templates for a particular datastore are found in the corresponding folder.
So, say if we want to look at the MySQL templates for the configuration, we will navigate to the mysql folder.

Now that we are in the folder, let us quickly talk about the templating mechanism that Trove follows. Trove supports templates for every type of configuration file that it has to create (it has a template for replication, both master and slave – replica_source.template and replica.template; it also has them for a single instance configuration – called config.template, and so on.)
All datastores will at least have one configuration template for the single instance/base configuration (config.template). If there are specific configurations for a specific datastore version, it is put in a separate folder inside the configuration template (take a peek inside the 5.5 folder), which is used when that specific datastore version is instantiated, otherwise the default is used.
If we take a look at the config.template file, we will notice another thing. This template file is not copied as is. The file is variable based, which is then substituted before being used by the database engine. The only variable that is used.
If you notice, the configuration values have the flavor['ram'] variable, which is substituted with the memory size in MB and then the configuration value is set.
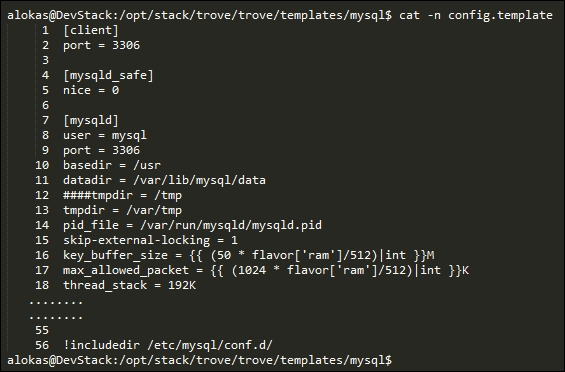
For example, key_buffer_size will be set to 200 M (50 * 2048 / 512) for an m1.small (2048 MB RAM) and 400 M for an m1.medium instance. (In order to see the RAM size for the instances, use the command trove flavor-list.)
One other thing that is found in the folder is validation-rules.json. This file, as its name suggests, performs validation on the user-defined configuration groups (which we will see in the next section of the chapter).
As Trove administrators, we can modify the validation-rules.json file, in order to add/remove configuration capability and to set the minimum and the maximum allowed values. As an example, looking at the sort_buffer_size configuration from the default validation-rules file:
{
"name": "sort_buffer_size",
"restart_required": false,
"max": 18446744073709551615,
"min": 32768,
"type": "integer"
},If our standard dictates that the minimum value for this configuration parameter should be 65536, we should be able to modify the file and load this using the command trove-manage db_load_datastore_config_parameters. The full syntax and the command in action can be seen in the later part of the chapter.
Now that we know about the template file, if we need to know the values that have been computed (based on the formulas) and passed along for a particular instance, we can see the default configuration of an instance by typing the command trove configuration-default <instance name>. In the following screenshot, we take a look at the configuration of our instance mysql_gui, which is an m1.small:
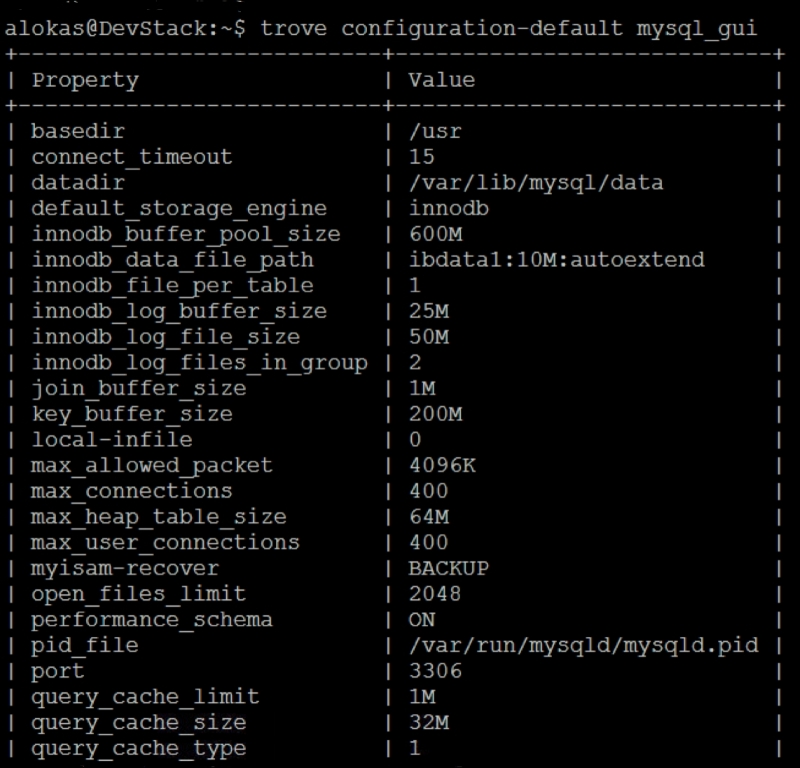
The command format might lead us to believe that these are the default values running on the instance itself. However, these are simply from the config.template file after substitution. If the template has been modified after the instance was instantiated, these values will be wrong. In a production environment, it is recommended that we design the default configuration file for a particular datastore version before the system goes live and after that all configuration modifications can be done by modifying the default configuration.
Modifying the default configuration file is as easy as editing the config.template file. For instance, if we want innodb_log_file_size to be 100 M rather than the default 50 MB, we will simply edit the config.template file in the templates directory and make the change.
Do note that this configuration doesn't get updated in the instances that have already been requested using the older configuration template. (but when you look at the trove configuration-default command output, you might be led to believe erroneously that the older systems have also been updated. Hence, it is recommended to modify the default configuration before setting the datastore in production)
In order to test this, let us request another MySQL instance called test12 using our trove create command:
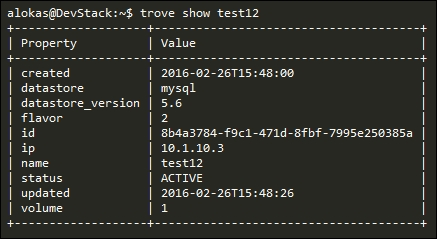
The instance is created with the same specs as that of our older mysql_gui instance that we created.
We will run remote ssh commands to verify that it is indeed the case (10.1.10.2 is the old mysql_gui instance and 10.1.10.3 is the newer test12 instance).

As we can see, the configuration of the old instance is not changed but the new instance has the new log file size.