
Chapter 3. Ingredients of Data Governance: People and Processes
Overview
As mentioned in previous chapters, companies want to be able to derive more insights from their data. They want to make “data driven decisions”. Gone are the days of business decisions being made exclusively based on intuition or observation. Big data and big data analytics now allow for decisions to be made based on collecting data, and extracting patterns and facts from that data.
We have spent much time explaining how this movement to using big data has brought with it a host of considerations around the governance of that data and have outlined tools that aid in this process. Tools, however, are not the only factor to evaluate when designing a data governance strategy - the people involved and the process by which data governance is implemented is key to a successful implementation of a data governance strategy.
The people and process are aspects of a data governance strategy that often get overlooked or oversimplified. There is an exceedingly heavier reliance on governance tools which, while tools are getting better and more robust, they are not enough by themselves; how the tools are implemented - an understanding of the people using them as well as the process set up for their proper use is critical to governance success.
The People: Roles, Responsibilities and “Hats”
Many data governance frameworks revolve around a complex interplay of many roles and their responsibilities. These frameworks rely heavily on each role doing its “part” in order for the well-oiled data governance machine to run smoothly.
The problem with this is that most companies rarely are able to exactly or even semi-fully match these frameworks due to lack of employee skill set or, more commonly, simply lack of headcount. For this reason employees working in the information and data space of their company often wear different user “hats”. We use the term “hat” to delineate the difference between an actual role/job title and tasks that are done - the same person can perform tasks that align with many different roles, or wear many different “hats” as part of their day to day job.
User “Hats” Defined
In chapter one we outlined three broad categories of Governors, Approvers, and Users. Here we will go in depth into the different “hats” (vs roles) within each category (and expand on an additional category of Ancillary “hats”), the tasks associated with each, and finally, the implications and considerations when looking at these “hats” from a task oriented perspective vs. a role based approach.

Figure 3-1. Chart showing categories of Governors, Approvers, Users, and Ancillary with the respective hats listed below and tasks associated with each
Legal (Ancillary)
Contrary to the title of “legal”, this hat may or may not be an actual attorney. The tasks of this hat are to be up to date on what legal requirements a company must comply with in terms of their data handling and communicate this internally. Depending on the company this may actually be an attorney (this is especially true for highly regulated companies - which will be covered in depth below) who needs to have a deep knowledge of the type of data collected and how it’s treated to ensure that the company is in compliance in the event of an external audit. Other companies, especially those dealing with sensitive but not highly regulated data, are more likely to simply have someone whose task is to be up to date and have a deep understanding of regulations that do or do not apply to the data the company collects.
Privacy Tsar (Governor)
We chose to title this hat “Privacy Tsar” as this is a term we use internally but this hat has also been called in other literature, “Governance Manager”, “Director of Privacy”, and “Director of Data Governance”. The key tasks of this hat are to ensure that the regulations Legal has deemed appropriate are followed. Additionally, the Privacy Tsar also generally oversees the entire governance process at the company which includes to define how and which governance process should be followed - more on different process approaches to come. It’s important to note that the Privacy Tsar may or may not have an extremely technical background. On the surface it would seem that this hat may come from a technical background but depending on the company and the resources they may (or may not) have dedicated to their data governance efforts, these tasks are often performed by people who sit more on the business side of the company rather than the technical side.
Data Owner (Approver/Governor)
In order for the Privacy Tsar’s governance strategy/process to be realized, the Data Owner (sometimes called Data Custodian) is needed. The tasks of the Data Owner are to physically implement the process and/or strategy laid out by the Privacy Tsar. This most often includes the ideation and creation of the data architecture of the company along with choosing and implementing tooling and data pipeline and storage creation, monitoring, and maintenance - in other words, “owning the data”. From the task descriptions it’s clear that these must be performed by one with quite a bit of technical background and expertise, hence the person(s) who wear the Data Owner hat are largely engineers or folks with an engineering background.
Data Steward (Governor)
When researching data governance there is likely much weight given to the “Data Steward” and that’s with good reason - the tasks of a Data Steward include categorization and classification of data. In order for any sort of governance to be implemented, data must be defined and labeled such that it’s known what the data itself is; sensitive, restricted, health related, etc. The interesting aspect of the Data Steward and the large reason we advocate the usage of the term “hats” vs “roles” is that it’s very rare to find a singular person doing this “role” in the wild. The act of data “stewardship” is highly, highly manual and extremely time consuming. In fact, one company we spoke to said that for a short while they actually had a “full time” Data Steward who quit after several months citing the job as being “completely soul sucking”. The manual, time consuming nature coupled with the fact that in most cases there is no dedicated person to perform stewardship duties - these duties often fall across many different people or to someone who has another role/other duties they perform as well. As such, full data categorization/classification is often not done well, not done fully, or in the worst cases just not done at all. This is an important item to note, because without stewardship, governance is incomplete at best. We will cover this in more depth later, but here is where we begin to see a recurring theme when looking at the people and the process. Much of the governance process most companies employ right now are in an effort to get around the fact that stewardship falls short. As we outlined in chapter 1, the quick growth and expansion of data collected by companies has resulted in an overwhelm of data and companies simply don’t have the time or headcount to dedicate to being able to categorize, classify, and label ALL of their data so they create and utilize other methods and strategies to “do their best given the limitations”.
Data Analyst/Data Scientist (User)
While Data Analysts and Data Scientists are not directly involved in data governance duties, they are the users of data within a company and largely who data governance efforts are for. Companies struggle with governance and security of their data vs the democratization of their data. In order to be data driven, companies must collect and analyze large amounts of data. The more data that can be made available to analysts, the better - unless of course that data is sensitive and should have limited access. Therefore, the better the governance execution, the better (and more safely) analysts are able to do their job and provide valuable business insights.
Business Analyst (User)
Data Analysts and Data Scientists are the main “users” or consumers of data but there are a few periphery people within a company who also use and view data. In moving to being more data driven, companies have folks who sit on the “business” side of things who are very interested in the data analyses produced by analysts and scientists. In some companies, even, Data Engineers aid in the creation and maintenance of much simpler analytics platforms to aid in “self-service” for business users. More and more business people in companies have questions they hope crunching some data will help them to answer. Analysts/scientists thus end up fielding many, many inquiries, some of which they simply don’t have time to answer. By enabling business users to directly answer some of their own questions, analysts/scientists are able to free up their time to answer more complex analysis questions.
Customer Support Specialists (User/Ancillary)
While technically only a “viewer” of data, it’s worth noting that there are folks who will need access to some sensitive data even though they don’t have any tasks around manipulating that data. In terms of hats customer support specialists do tend to have this as their sole role and are not also doing other things, however, they are a consumer of data and their needs and how to grant them appropriate access must be considered and managed by the other hats executing a company’s governance strategy.
C-Suite (Ancillary)
In many companies the C-Suite has limited tasks in relation to the actual execution of a data governance strategy. They are nonetheless a critical hat in the grand scheme of governance as they “hold the purse strings”. As we mentioned earlier, tools, as well as headcount are critical factors when considering a successful data governance strategy. It then makes sense that the person who actually funds that strategy must understand it and be on board with the funding that makes it a reality.
External Auditor (Ancillary)
We have included the hat of External Auditor in this section despite the fact that they are not within a particular company. Many of the companies we’ve spoken to have mentioned the importance of the External Auditor in their governance strategy. No longer is it good enough to simply be “compliant” with regulations - companies now often need to prove their compliance which has direct implications to the way a governance strategy and process is employed. Oftentimes companies need to prove who has access to what data as well as all the different locations and permutations of that data (its lineage). While internal tool reporting can generally help with providing proof of compliance, the way that a governance strategy is set up and tended to can help, or hinder the production of this documentation.
An Important Consideration: Data Enrichment and its Importance
As we mentioned at the beginning of this section, one person may wear many “hats”, i.e. perform many of the tasks involved in carrying out a data governance strategy at a company. As can be seen in the list of hats and (fairly long) list of tasks within each hat shown in Figure 3-1, it’s easy to see how many of these tasks may not get completed or completed well.
While there are many tasks that are important to a successful implementation of a data governance strategy it could be argued that the most critical is that of data categorization, classification, and labeling. As we pointed out, this task is manual and highly time consuming which means that it rarely gets executed fully. There is a saying, “in order to govern data you must first know what it is”. Without proper data enrichment (process of attaching metadata to data) - the center task of the Data Steward hat - proper data governance falls short. It’s true that there are some tools that strive to help with this process but the majority of them are “metadata management” tools which simply help to manage metadata, not create it. This central task of the Data Steward is so key, however what we commonly see is the person who wears the Data Steward hat also often wears the Privacy Tsar hat, and the Data Owner hat, and/or may even wear a hat in a completely different part of the company (a common one we see is Business Analyst). Wearing many hats results in a limited amount of tasks that can be done (one person can only do so much!) and most often the majority of the time consuming task of data enrichment falls off the list.
In the next section we will cover some common governance processes we’ve observed over the years. One thing to keep in mind while reading through the processes is to think about how the “hats” play a role in the execution of these processes; we will discuss their interplay later in this chapter.
The Process: Diverse Companies, Diverse Needs and Approaches to Data Governance
It’s important to note that in the discussion of the people and process around data governance there is no “one size fits all” approach. As mentioned, in this section we will begin to examine some broad company categories, outline their specific concerns, needs, and considerations, and finally explore how those interplay with their approach to data governance.
Legacy
Legacy companies are defined as companies that have been around for quite some time and most certainly have, or have had legacy on premise (on-prem) systems, most often many different systems which bring with them a host of issues. The time and level of effort of this work often leads to it not being done fully or simply not done at all. Further, for consistency (and arguably the most effective use of data and data analytics) there should be a central data dictionary within a company defining all data names, classes, and categories that is standardized and used throughout the company. Many legacy companies lack this central data dictionary as their data is spread out through these various on prem systems and more often than not these on prem systems and the data within them is associated with a particular branch or line of business that in and of itself is agnostic of the data that resides in the other lines of business’ system. As such there ends up being a “dictionary” for each system and line of business that may not align to any other line of business or system which makes cross-system governance and analytics near impossible.
A prime example of this would be a large retailer that has a system that houses their online sales and another that handles their brick and mortar sales. In one system the income the company receives from a sale is called “revenue” while in the other system it’s called simply “sales”. One can see where this becomes problematic if executives are trying to figure out what the total income for the company is - analytics are near impossible to run when the same data does not have the same metadata vernacular attached - the same enterprise dictionary is not used. This becomes an even larger issue when considering sensitive data and it’s treatment. If there is no agreed upon company wide “terminology” (as outlined in the enterprise dictionary) and if that terminology is not implemented for all sources of data, governance is rendered incomplete and ineffective.
The power of the cloud and big data analytics drives many companies to want to migrate their data, or a portion of their data to the cloud, but the past pain of inconsistent enterprise dictionaries and haphazard governance gives them pause - they don’t want to “repeat their past mistakes”; they don’t simply want to replicate all of the current issues they have. While tools can help to right past wrongs, they simply aren’t enough. Companies need (and desire) a framework for how to move their data and have it properly governed from the beginning with the right people working the right process.
Cloud Native/Digital Only
Cloud native companies (sometimes referred to as “digital only”) are defined as companies who have, and have always had, all of their data stored in the cloud. Not always, but in general these tend to be much younger companies who have never had on premise systems and thus have never had to “migrate” their data to a cloud environment. Just on that alone it’s easy to see where cloud native companies don’t face the same issues legacy companies do.
Despite the fact that cloud native companies do not have to deal with on prem systems and often the “siloing” of data that comes along with that, they still may deal with different clouds as well as different storage solutions within and between those clouds which have their own flavor of “siloing”. For one, a centralized data dictionary, as we’ve explored, is already a challenge, and having one that spans multiple clouds is even more daunting. Even if a centralized data dictionary is established, the process and tools (as some clouds require that only certain tools be used) by which data is enriched and governed in each cloud likely will be slightly different which hinders consistency (in both process and personnel) and thus effectiveness. Further, even within a cloud, there can be different storage solutions which also may carry with them different structures of data (ex: files vs. tables vs. jpgs) which can be difficult to attach metadata to rendering governance additionally difficult.
In terms of cloud and data governance within clouds, specifically, however, cloud native companies tend to have better governance and data management processes set up from the beginning as their relatively younger “age” in dealing with data often results in less data overall and familiarity of some common data handling best practices. Additionally, cloud native companies, by definition, have all of their data in the cloud, including their most sensitive data which means that they’ve likely been dealing with the need of governance since the beginning and likely have some processes in place for perhaps not governing all of their data but at least their most sensitive.
Retail
Retail companies are an interesting category as they often not only ingest quite a bit of data from their own stores (or online stores) but they also tend to ingest and utilize quite a bit of third party data. This presents yet another instance where data governance is only as good as the process set up for it and the people who are there to execute it. The oft mentioned importance of creating and implementing a data dictionary apply as well as a process around how this third party data is ingested, where it lands, and how governance can be applied.
One twist that we have not discussed but that very much applies in the case of retail is that of governance beyond simple classification of data. Let’s look at an example: so far we have discussed the importance of classifying data (especially sensitive data) so that it can be known and thus governed appropriately with that governance most often relating to the treatment and/or access of said data. But access and treatment of data are not the only aspects to consider in some instances; the use case for that data is also of importance. In the case of retail, there may be a certain class of data, email for example, that was collected for the purpose of sending a customer their receipt from an in-store purchase. In the context (use case) of accessing this data for the purposes of sending a customer a receipt, this is completely acceptable. If, however, one wanted to access this same data for the purpose of sending a customer some marketing material around the item they just purchased, this use case would not be acceptable unless the customer has given explicit consent for their email to be used for marketing. Now, depending on the employee structure at a company, the above problem may not be able to be solved with simple role-based access controls (fulfillment gets access, marketing does not) if the same employee may cover many different roles. This warrants the need for a more complex process that includes establishing use cases for data classes.
Highly Regulated
Highly regulated companies represent the sector of companies that deal with extremely sensitive data; data that often carries additional compliance requirements beyond the usual handling of sensitive information. Some examples of highly regulated companies would be that of financial, pharmaceutical, and healthcare.
Highly regulated companies deal with a lot and multiple kinds of sensitive data. They have to juggle not only basic data governance best practices, but also the additional regulations related to the data they collect and deal in, and face regular audits to make sure that they are above board and compliant. Due to this, many highly regulated companies are more sophisticated in their data governance process. As they’ve had to deal with compliance related to their data from the get-go they often have better systems in place to identify and classify their sensitive data and treat it appropriately.
Also, for many of these kinds of companies, their business is solely based around sensitive data so not only do they tend to have better processes in place from the beginning, those processes most often include a more well funded and sophisticated people organization that handles sensitive data. These companies tend to actually have physical people dedicated to each of the hats discussed earlier, which as we pointed out, additional headcount can help be the deciding factor in a successful vs unsuccessful data governance strategy.
One final note about highly regulated companies is that due to the legal requirements they face on the handling of certain data, they can function similar to Legacy companies in that they have difficulty moving off-prem and/or trying out new tools. Any tool that will touch any sensitive data under a regulation must meet the standards (fully) of said regulation. As an example, a tool or product in beta may only be used by a healthcare company if it is HIPAA compliant. Many product betas, as they’re used for early access and as a way to work out bugs, are not designed to meet the most stringent compliance standards. While the final product may be, the beta generally is not meaning that highly regulated companies often don’t get to experiment with these new tools/products and thus have trouble migrating to new, potentially better tools than the ones they’re currently using.
Small Companies
For our purposes we define a small company as one that has less than 1,000 employees. One of the benefits of small companies is their smaller employee footprint.
Smaller companies often have small data analytics teams which means that there are fewer people who actually need to touch data. This means that there is less risk overall. One of the primary reasons to govern data is to make sure that sensitive data does not fall into the wrong hands. Fewer employees also makes for a much less arduous and complicated process of setting up and maintaining access controls. As we discussed earlier, access controls and policy management can get increasingly complicated especially when factors such as use case for data come into play.
Another benefit of a small amount of people touching data is that there is often less proliferation of datasets. Data analysts and scientists as part of their jobs create many different views of datasets and joins (combining tables together from different dataset sources). This proliferation of data makes it hard to track; to know where the data came from and to where it’s going (not to mention who had and now has access). Fewer analysts/scientists mean fewer datasets/tables/joins resulting in data that’s much easier to track and thus easier to govern.
Large Companies
While there are many more company types, we will end our exploration of broad categories with that of large companies, defined as companies with more than 1,000 employees.
If small companies have the governance benefit of dealing with less data, conversely large companies deal with the reverse in that they often deal with A LOT of data. Large companies not only generate a great deal of data themselves, but they also often deal with a lot of third party data. All this data results in immense difficulty in wrapping their arms around it all; they are overwhelmed by the myriad of data they have and often struggle to govern even a portion of it.
As such only some data gets enriched and curated which means that only some of their data is able to be used to drive insights.
Large companies often put in place processes to limit this overwhelm by only choosing select data to enrich, curate, and thus govern. A common strategy to limit the data that a Data Steward must enrich is to select a number of categories and only govern data that fall within those categories. Another is to govern only known pipelines of data (these are the pipelines consisting of the primary data a company deals with such as daily sales numbers from a retail store) and to handle “ad-hoc” pipeline data (engineers at times are asked to create new pipelines to address one time or infrequent data analysis use cases) only as time allows or if absolutely necessary.
It’s easy to see that these strategies (which we will discuss more in depth later) result in a sort of iceberg of data where enriched (“known”), curated data sits at the top and there is a mound of data below, the majority of which is un-enriched and thus “unknown”. Companies don’t know what this data is which means they can’t govern it and ungoverned data is quite scary. It could be sensitive, it could be non-compliant, and there could be dire consequences if it happens to get leaked. This causes much fear and forces companies with this problem to use strategies to help mitigate their risk.
Not only do large companies deal with copious amounts of data, they also tend to have a much larger workforce of data analysts, data scientists, and data engineers (Data Owners) - all of which need access to data to do their jobs. More data plus more people who need access to data results in much more complicated (and often poorly managed) processes around access control. Access control is generally based on user role which should determine which data (and only that data) that they need access to. This strategy may seem simple but is a difficult process to implement for two main reasons. The first being that in order to know what data is critical to a particular users’ role, data must be known. And we know from previous discussion in this book that the majority of data a company has is unknown. This results in not only the inability to govern (it’s impossible to govern what you don’t know you have) but also the inability to know what data is appropriate for who. Data specialists still need to do their job, however, so [too much] access is often granted at the expense of risk. Companies try to offset this risk with creating a “culture of security” which puts the onus on the employee to “do the right thing” and not expose or misuse potentially sensitive information. Another issue with role-based access is that roles and their ensuing uses for data are, at times, not black and white; the use case for data must also be considered. Depending upon the company, a user in the same role may be able to use data for some use cases and not for others (an example being the use case we outlined in the Retail section). As touched on in the previous chapter and will be covered in depth later, the addition of use case as a parameter during policy creation helps to mitigate this issue.
Like legacy companies, large companies often also deal with the issue of many different storage systems, the majority of which are legacy. Large companies tend to be built up over time and with time comes more data and more storage systems. We’ve already discussed how the siloed nature of different storage systems makes governance difficult. Different storage systems naturally create data silos, but large companies have another factor that results in even more complex “silos” - acquisitions.
Large companies are sometimes built completely from within but others become large (and even larger) due to acquisitions. When companies acquire other, smaller companies, they also acquire all their data (and its underlying storage) which brings along a whole host of potential problems. The primary being how the acquired company handled their data; their overall governance process and approach. This includes how they managed their data: their method for data classification, their enterprise dictionary (or lack thereof), their process and methods around access control, and overall culture of privacy and security. For these reasons many large companies find that it can be near impossible to marry their central governance process with that of their acquisitions which often results in acquired data sitting in storage and not used for analytics.
People + Process Together: Considerations, Issues, and Some Successful Strategies
We have now outlined the different people involved as well as some specific processes and approaches utilized by varying kinds of company.
There is, obviously, a synergy between people and process of which there are some considerations and issues. We will review several of the issues we’ve observed along with outlining a few strategies that we have seen where the right people and process together have resulted in moving towards a successfully implemented data governance strategy.
Considerations and Issues
This certainly is not an exhaustive list of all the potential issues with implementing a successful data governance strategy; we are simply highlighting some of the top issues we’ve observed. We’ve noted, briefly, the mitigation efforts to combat these issues but note that the latter half of this text will go into these in much more detail.
“Hats” vs “Roles” and Company Structure
We previously discussed our intentional use of the term user “hats” vs “user roles” and the impact that wearing many hats has on the data governance process. To expand on that idea further an additional issue that arises with hats vs roles is that responsibility and accountability become unclear. When looking at the different kinds of approaches different companies take to achieve governance and underlying need is for actual people to take responsibility for the parts of that process. This is easy when it is clearly someone’s job to conduct a piece of the process but when the lines of what is and is not within a person’s purview, these fuzzy lines often result in inadequate work, miscommunication, and overall mismanagement. It’s clear that a successful governance strategy will not simply rely on “roles” but on tasks and who is responsible or accountable to these tasks. It’s easy to point the finger or miss that a task was completed or done properly when the owner of a task is ambiguous or simply missing entirely.
Tribal Knowledge and Subject Matter Experts (SMEs)
When talking with customers about their pain points with data governance one of the things they request over and over again are tools that help their analysts find which datasets are “good”; meaning when an analyst is searching for data they know that this dataset is of the best quality and most useful for their use case. They state that this would help their analysts save time searching for the “right/best” dataset as well as would assist them in producing better analytics. Currently, for most companies, the way analysts know which datasets they should work with is by word of mouth or “tribal knowledge”. This is an obvious problem for companies as roles change and/or people move on, etc. Companies request “crowdsourcing” functionality such as allowing analysts to comment on or rank datasets to help give them a “usefulness” score for others to see when searching. This suggestion is not without merit but uncovers the larger problem of findability and quality. Companies are relying on people to know the usefulness of a dataset and to transfer that knowledge on, yet this is a strategy that is fallible and difficult, if not impossible to scale. This is where tools that lessen (or negate) the effort placed on a particular user or users aids in the process. A tool that can detect most used datasets and surface these first in a search, for example, can help minimize the reliance on tribal knowledge and SMEs.
Unknown Data
Regardless of the type of company, ALL companies want to be able to collect data that can be used to drive informed business decisions. They are certain that more data and the analytics that could be run on that data could result in key insights; insights that have the potential to skyrocket the success of their business. The problem, however, is that in order for data to be used, it must be known. It must be known what the letters or numbers or characters in a column of a table mean. And now, it must also be known if those numbers, letters, or characters represent information that is sensitive in nature and needs to be treated in a specific way. Data enrichment is key to “knowing” data, yet it is largely a manual process. It generally requires actual people to look at every piece of data to determine what it is. As we discussed this process is cumbersome on its own but becomes almost impossible when the extra complexity of disparate data storage systems and different data definitions and catalogs are considered. The “impossible” nature of this work, in general, means that it just never gets done and leaves companies scrambling to implement half strategies, a few tools, and a hope that by educating people on how data should be treated and handled will make up for it.
Old Access Methods
Gone are the days of simple access controls; i.e. these users/roles get access and these users/roles do not. Historically there were not many users or roles who even had the need to view or interact with data which meant that only a small portion of employees in a company needed to be granted access in the first place. In today’s data driven businesses there is the potential for many, many users who may need to touch data in a variety of ways as seen in the beginning of this chapter. Each of these hats have different types of tasks that they may need to do in relation to data which requires varying levels of access and security privilege.
We already discussed the problematic nature of unknown data - another layer of that is the implementation of access controls. There is a synergy between knowing what data even needs access restrictions (remember: data must be known in order for it to be governed) and what those restrictions should be for what users. As discussed in Chapter 2, there are varying levels of access control all the way from access to plain text to hashed or aggregated data.
A further complication to access is that of the intent of the user accessing data. There may be use cases for which access can and should be granted and other use cases for which access should strictly be denied. A prime example (and one we’ve heard from more than one company) is a customer’s shipping address. Imagine the customer just bought a new couch and their address was recorded in order to fulfill shipment of that couch. A user working to fulfil shipment orders should undoubtedly get access to this information. Now let’s say that the slipcovers for the couch this customer just bought go on sale and the company would like to send a marketing flyer to the customer to let them know about this sale. It may be the case that the user in the company who handles shipping data also happens to handle marketing data (remember “hats”?). If the customer has opted OUT of promotional mail the user in this example would not be able to send the marketing material even though they have access to that data. This means that access controls and policies need to be sensitive enough to not only account for black and white “gets access/doesn’t get access” for a particular user - they also need to account for what purpose the user is using the data.
Regulation Compliance
Another struggle companies have is around compliance with regulations. Some regulations such as those in financial and healthcare industries have been around for quite awhile and as we pointed out before, companies who deal with these kinds of data tend to have better governance strategies for two main reasons: one, they’ve been dealing with these regulations for some time and have built processes in to address them, and two, these regulations are fairly established and don’t change much.
The advent of a proliferation of data collection has brought about new regulations such as GDPR (General Data Protection Regulation) and CCPA (California Consumers Protection Act) which aim to protect ALL of a person’s data - not just their most sensitive (i.e. health or financial data). Companies in all types of industries - not just highly regulated - now must comply with these new regulations or face deep financial consequences. This is a difficult endeavor for companies that previously did not have regulations to comply with and thus perhaps did not set up their data infrastructure to address. As an example, one of the main components of GDPR is the “right to be forgotten”, or the ability for a person to request that all their data collected by a company be deleted. If the company does not have their data set up to find all the permutations of a person’s individual data they struggle to be compliant. Thus it can be seen how findability is important not only from the perspective of finding the right data to analyze but also for finding the right data to delete.
Processes and Strategies with Varying Success
While the issues with people and process are many, we have observed some strategies that have been implemented with varying degrees of success. While we will outline and go into some detail about these strategies below, the latter half of this text will go into further depth along with our recommendations on how these strategies can be implemented to achieve greater data governance success.
Data Segregation within Storage Systems
We reviewed some of the issues that arise with having multiple data storage systems, however some companies use multiple storage systems and even different storage “areas” within the same storage system in an advantageous and systematic way. Their process is to separate curated/known data from uncurated/unknown data. They may do this in a variety of ways but we have heard two common, prevailing strategies.
The first is to keep all uncurated data in an on prem storage system and push to the cloud curated data that can be used for analytics. The benefit companies see in this strategy is that the “blast radius” or the potential for data to be leaked either by mistake or by a bad actor is greatly diminished if only known, clean, and curated data is moved into a public cloud. To be clear, companies often cite that it is often not their total distrust in cloud security (although that can play a role as well), it is in their concern that their own employees may unwittingly leak data if its in a public cloud vs in an on prem environment.

Figure 3-2. Chart showing on prem vs cloud storage and what the data looks like in each (uncurated vs curated) with special reference to how the curation in each affects what could be leaked
The second strategy is similar to the first in that there is a separation between curated and uncurated data but this is done within the same cloud environment. Companies will create different tiers or layers within their cloud environment and base access on these; the bottom, uncurated tier may be accessed by only a few users while the uppermost, curated and cleaned (of sensitive data) tier may be accessed by any user.

Figure 3-3. Map showing a “data lake” within cloud storage with multiple tiers with visual to show what kind of data resides in each tier and who has access at each tier level
Data Segregation and Ownership by Line of Business
As we’ve mentioned more than a few times, data enrichment is a key challenge in successful data governance for many reasons, the primary of those being level of effort and lack of accountability/ownership.
One way we’ve observed companies handle this issue is by segregating their data by line of business. In this strategy each line of business has dedicated people to do the work of governance on just that data. While it’s often not actually delineated by role, each line of business has people to do the tasks of: handling ingress and egress of data (pipelines), deep knowledge of the kind of data they have, enrichment of data, enforcement/management of access controls and governance policies, and data analysis. Depending on the company size and/or complexities of data within each line of business these tasks are sometimes handled by just one person, a handful of people, or a large team.
There are several reasons this process tends to be quite successful. The first is that the amount of data any given “team” must wrap their arms around is smaller. Instead of having to look at and manage a company’s entire data story, they only need to understand and work on a portion of it. Not only does this result in less work but it also allows for deeper knowledge of that data. Deeper knowledge of data has a multitude of advantages, a few being quicker data enrichment and ability to run quicker, more robust analytics.
The second reason this process is successful is that there is clear, identifiable ownership and accountability for data. There is a person (or persons) to go to, specifically, when something goes wrong, or when something needs to change (such as the addition of a new data source or the implementation of a new compliance policy). When there is no clear accountability and responsibility for data it’s easy for that data to be lost, forgotten, or worse, mismanaged.
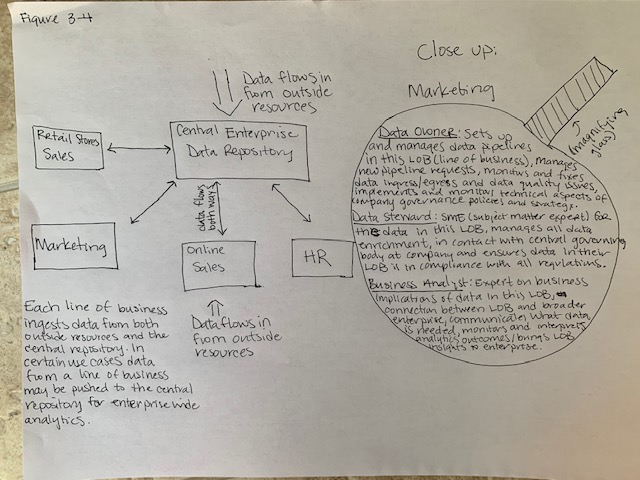
Figure 3-4. Flowchart of an enterprise with 4 lines of business and their data ingress/egress as well as a closeup of one line of business, its key hats and their tasks
This process, while successful, does come with some pitfalls, however. The primary one is that segregating data by line of business encourages the siloing of data and can, depending on how it’s set up, inhibit cross-company analytics.
We recently worked with a large retail company who were dealing with this exact issue.
This large US retailer (over 350,000 employees), in an effort to better deal with the tremendous amount of data they collect divided up their data by several lines of business - to name a few: air shipping, ground shipping, retail store sales, and marketing. Having the data separated in this way greatly enabled them to devote specific data analytics teams to each line of business whereby they could more quickly enrich their data allowing them to apply governance policies to aid with CCPA compliance. This strategy, however, created issues when they began to want to run analytics across their different lines of business. In order to separate their data they created infrastructure and storage solutions with data pipelines that feed directly (and only) into that line of business. We won’t go into too much depth on data pipelines here but in short it is a common practice to have data “land” in only one storage solution as duplicating data and transferring it to additional storage areas is costly and difficult to maintain. Because specific data only resides in one storage area/silo, they could not run analytics across these to see what patterns might emerge between, for example, air shipping and retail store sales.

Figure 3-5. Figure of above two data silos for example company: Air Shipping and Ground Shipping. Each silo has its own data pipeline and stores this data within its own bucket meaning analytics can only be run within silos unless data from that pipeline is duplicated and piped into another silo.
This process of segregation by line of business to aid with accountability and responsibility is not a bad strategy and while it’s obvious there are pitfalls there are also ways to make it more successful which we will cover in the second half of this text.
Creation of “Views” of Datasets
A classic strategy employed by many companies is to create different “views” of datasets.
As seen in Figure 3-6 these “views” are really just different versions of the same dataset and/or table that have sensitive information sanitized or removed.

Figure 3-6. Three different types of “views” - one plain text, one with sensitive data hashed, and another with sensitive data redacted
This strategy is classic (and works) because it allows for analytics to easily be run, worry free, by virtually anyone on the “clean” view (the one with sensitive data either hashed or removed). It takes the risk of access to and usage of sensitive data away.
While this strategy works it is problematic in the long run for several reasons. The first is that it takes quite a bit of effort and manpower to create these views. The “clean” view has to be manually created by someone who does have access to all of the data. They must go in, identify any and all columns, rows, or cells that contain sensitive data and decide how they should be treated: hashed, aggregated, completely removed, etc. They then must create an entirely new dataset/table with these treatments in place and make it available to be used for analytics.
The second issue is that new views are constantly needing to be created as fresher data comes in. This results in not only constant time and effort being put into creating “fresh” views, but also a proliferation of datasets/tables that are difficult to manage. Once all these views are created (and re-created), it’s hard to know which is the most fresh and should be used. Past datasets/tables often can’t be immediately deprecated as there may be a need down the line for that specific data.
While views have some success and merit in aiding in access controls we will propose and discuss some strategies that we have seen that not only are easier to manage but scale better as a company collects more and more data.
A Culture of Privacy and Security
The final process we’d like to discuss is that of creating a culture of privacy and security. While certainly every company and employee should respect data privacy and security, this is a strategy companies implement more often as a response to inadequacies in other areas as opposed to a genuine sentiment to have employees adopt personal responsibility around protecting their data.
In our observations, companies create and implement a complex framework around a culture of privacy and security for four reasons:
-
Their governance/data management tools are not working sufficiently
-
People are accessing data they should not be and/or using data in ways that are not appropriate (whether intentional or not)
-
People are not following processes and procedures put into place (again, intentional or not)
-
They know that governance standards/data compliance are not being met and they don’t know what else to do but hope that educating people on the “right thing” will help
To be sure, throughout this text already we have covered in great detail governance tools, the people involved, and the processes that are/can be followed. This is where it can be seen the importance of putting all the pieces together: tools, people, and process. One, or even two pieces are insufficient in a successful governance strategy.
A company must have set processes in place that are executed by people who have clear ownership, responsibility, and accountability to those processes, as well as the proper tools being used in the right way. All of these parts rely on and feed into each other.
This is not to say that a culture of privacy and security is not needed or not important - it is. Regardless of tools, people, or process, it’s important for employees to understand how data should be managed and treated so that they are good stewards of proper data handling and usage. What a culture of privacy and security should NOT be is a means to solve shortcomings in other areas of a governance strategy
Conclusion
In this chapter we have reviewed multiple unique considerations in regards to the people and process of data governance for different kinds of companies. We also covered some common issues companies we’ve observed face as well as some strategies we’ve seen implemented with varying success.
From our discussion it’s clear that data governance is not simply an implementation of tools but that the overall process and consideration of the people involved, while it may vary slightly from company to company or industry to industry, is important and necessary for a successful data governance program.
The process for how to think about data, how it should be handled and classified from the beginning, how it needs to be classified and categorized ongoing, and who will do this work and be responsible for it, coupled with the tools that enable these to be done efficiently and effectively, are key, if not mandatory for successful data governance.