
Chapter 6. Automate Tests
Beware of bugs in the above code; I have only proved it correct, not tried it.
Donald Knuth
Best Practice:
-
Write automated tests for anything that is worth testing.
-
Agree on guidelines and expectations for tests and keep track of test coverage.
-
Automated tests help to find and diagnose defects early and with little effort.
The advantages of automation are easy to recognize. Automated tasks are effortless to run. The more often an automated task is executed, the more you are saving. In addition to saving time and effort for repeating the same tasks, it also removes opportunity for error. Therefore it adds reliability to your development process. This leads to less rework and thus faster development. Of course, to automate something, you need to invest in the automation itself and its maintenance (maintaining test code, script, test data, etc.). After the investment, you save time at each repeat. You should aim to automate as much as feasible in the development pipeline, as that gives developers more time to spend on other, creative tasks. You should also make it easy for yourself by using testing frameworks and tooling as much as possible.
Testing tasks are excellent candidates for automation. Table 6-1 provides a summary of the different testing types.
| Type | What it tests | Why | Who |
|---|---|---|---|
Unit test |
Behavior of one unit in isolation |
Verify that units behave as expected |
Developer (preferably of the unit) |
Integration test |
Joint behavior of multiple parts (units, classes, components) of a system at once |
Verify that parts of the system work together |
Developer |
End-to-end (or system) test |
System interaction (with a user or another system) |
Verify that system behaves as expected |
Developer/tester |
Regression test (may be unit/integration/end-to-end test) |
Previously erroneous behavior of a unit, class, or system interaction |
Ensure that bugs do not reappear |
Developer/tester |
Acceptance test (may be end-to-end test if automated) |
System interaction (with a user or another system) |
Confirm the system behaves as required |
End-user representative (never the developer) |
Note that in Table 6-1, only unit tests are white-box tests, in which the inner workings of the system are known to the tester. The other tests operate on a higher level of aggregation. Thereby they are making assumptions about the system’s internal logic (black-box tests). Different types of testing call for different specialized automation frameworks. Test frameworks should be used consistently and, therefore, the choice of test framework should be a team decision. The way in which (testing) responsibilities are divided may differ per team. For example, writing integration tests is a specialized skill that may or may not reside within the development team, but unit testing is a skill that every developer should master.
Motivation
Automated tests increase confidence in the reliability of your code. Automated tests find causes of problems early and help to reduce bugs in your code.
Automated Testing Finds Root Causes of Bugs Earlier with Little Effort
Automated tests give more certainty on the root cause of problems because they are executed consistently. Therefore, if a test executes a piece of code at two different points in time yet gives different results, you know that something has changed in the system to cause that outcome. With manual tests you do not have the same amount of certainty.
Because automated tests generally run fast and their effort for execution is negligible, they allow for early identification of problems. This early identification limits the effort it takes to fix problems: when a bug is found later in the development pipeline it will certainly require more effort to fix it. Consider that the (development) capacity to fix problems is costly and scarce when a release deadline approaches.
This is why acceptance tests should ideally be automated as much as possible. Functionality visible to users can be tested with frameworks that simulate user behavior and can “walk through” the user interface. An example is scripted user interaction through the screen, for which frameworks may provide a specific scripting language. This is especially useful for simulating browser interaction in web applications.
Automated Testing Reduces the Number of Bugs
Automated tests help your software become “more bug-free” (there is no such thing as bug-free software). Take, for example, unit tests and integration tests: they test the technical inner logic of code and the cohesion/integration of that code. Certainty about that inner working of your system avoids introduction of bugs (not all, of course). Therefore, unit tests allow for an effortless double-check of the entire codebase (isolated in units, of course), before turning to the next change.
Writing tests also has two side effects that help reduce bugs:
-
By writing tests, developers tend to write code that is more easily testable. The act of designing the tests makes developers rethink the design of the code itself: clean, simple code is testable code. If a developer finds that units are hard to test, it provides a good reason and opportunity to simplify those units. This is typically done by refactoring—for example, separating responsibilities into units, and simplifying code structure. Writing tests thus results in code that is easier to understand and maintain: you easily consider that to be higher quality code. Some development approaches advocate writing a unit test before writing the code that conforms to the test (this approach is popularized as Test-Driven Development or TDD). TDD leads to writing methods that have at least one test case and therefore TDD tends to deliver code with fewer errors.
-
Tests document the code that is tested. Test code contains assertions about the expected behavior of the system under test. This serves as documentation for the assumptions and expectations of the system: it defines what is correct and incorrect behavior.
Note
Keep in mind that tests only signal problems; they do not solve their root cause. Be aware that a team may acquire a false sense of security when all tests pass. That should not release them from critically reviewing code smells.
How to Apply the Best Practice
Based on our experience, we discuss the most important principles for achieving a great level of test automation. Come to clear agreements on tests and implement the right range of them. Make sure that those tests limit themselves to the things you want to test. Then plan and define responsibility for their maintenance:
- Agree on guidelines and expectations for tests
-
It is helpful to formalize test guidelines as part of the Definition of Done (see also Chapter 3). The principles described in this section further help you define what criteria should be adhered to for developing, configuring, and maintaining tests.
- All relevant tests are in place
-
The development team must agree on which tests need to be in place and in what order. Generally the order moves from detailed, white-box testing to high-level, black-box testing (see Table 6-1). Unit tests are most critical, as they provide certainty about the technical workings of the system on the lowest level. The behavior of code units is often the root cause of problems. You can therefore consider unit tests to be a primary safeguard against repeated defects (regression). But unit tests are no guarantee. This is because their isolated nature on the unit level does not tell you how the system performs as a whole. So higher-level tests always remain necessary.
-
Therefore, the high-level tests such as integration tests and end-to-end tests give more certainty about whether functionality is broken or incorrect. They are more sparse as they combine smaller functionalities into specific scenarios that the system likely encounters. A specific and simple form of end-to-end testing is to confirm that basic system operations are in good order. For example, testing whether the system is responsive to basic interaction or testing whether system configuration and deployment adhere to technical conventions. They are commonly referred to as smoke tests or sanity tests. Typical examples of frameworks that allow for automated (functional) testing include SOAPUI, Selenium, and FitNesse.
Note
The occurrence of bugs (or unexpected system behavior) is an opportunity to write tests. These tests will verify that the bugs do not reappear. Make sure to evaluate such situations, such that the team learns in terms of, for example, sharper specifications or requiring similar tests in the DoD.
- Good tests have sufficient coverage
-
A rule of thumb for unit test coverage is to have 80% line coverage. This refers to the percentage of lines of code in your codebase that are executed during those unit tests. In practice, this roughly translates to a 1:1 relation between the volume of production code and test code. A 100% unit test coverage is unfeasible, because some fragments of code are too trivial to write tests for. For other types of tests, the most important test scenarios must be defined.
- Good tests are isolated
-
The outcomes of a test should only reflect behavior of the subject that is tested. For example, for unit testing, this means that each test case should test only one functionality. If a test is isolated to a certain functionality, it is easier to conclude where deviations from that functionality are coming from: the cause is restricted to the functionality it is testing. This principle is rather straightforward, but also requires that the code itself has a proper isolation and separation of concerns. If in a unit test the state or behavior of another unit is needed, those should be simulated, not called directly. Otherwise, the test would not be isolated and would test more than one unit. For simulation you may need techniques like stubbing (here: a fake object) and mocking (here: a fake object simulating behavior). Both are substitutes for actual code but differ in the level of logic they contain. Typically a stub provides a standard answer while a mock tests behavior.
- Test maintenance is part of regular maintenance
-
Written tests should be as maintainable as the code that it is testing. When code is adjusted in the system, the changes should be reflected in tests, unit tests particularly. Part of regular maintenance is therefore that developers check whether code changes are reflected in modified and new test cases.
Managing Test Automation in Practice
Imagine that your team has identified a backlog for developing tests. The team is starting up, so to say. Unit test coverage is still low, there are a few integration tests, and no end-to-end tests yet. The team therefore depends largely on feedback from the acceptance tests for identification of bugs. Sometimes those bugs are identified only in production. When (regression) defects are found, they go back to development. The team wants to catch problems earlier. Let us consider the following GQM model formulated from the viewpoint of the team lead. Again, note that initial measurements can serve as a baseline for later comparison. The ideal state would be defined in the DoD and an idea of the future state should appear from a trend line. Even when the ideal level for a metric is unknown, you can tell whether you are improving. Then, changes in the trend line ask for investigation. It is now important for you to understand how you can efficiently and effectively focus efforts on writing tests:
-
Goal A: Knowing the optimal amount of automated tests (i.e., the point where writing automated tests costs more effort than the extra certainty they offer).
-
Question 1: What is the reach/coverage of our automated tests for functional and nonfunctional requirements?
-
Metric 1a: Unit test coverage. Unit test coverage is a metric that is well suited for a specific standard. The easiest way to measure this would be line coverage, with an industry standard objective of 80%. The coverage may of course be higher if developers identify a need for that. A higher coverage gives more certainty, but in practice 95% is about the maximum coverage percentage that is still meaningful. That is typically because of boilerplate code in systems that is not sensible to test, or trivial code that does not need to be tested all the way.
-
Metric 1b: Number of executed test cases grouped by test type. Expect an upward trend. Clearly this metric should move upward together with the number of tests developed. However, there may be reasons to exclude certain test cases. Exclusion needs some kind of documented justification (e.g., excluding when test cases are currently not relevant).
-
-
Question 2: How much effort are we putting into developing automated tests?
-
Metric 2a: Number of test cases developed per sprint, ordered by test type. Expect an upward trend until the team gets up to speed and gains experience with test tooling. Because different test cases/scripts are typically produced with different frameworks (e.g., performance, security, GUI tests), they have different productivity. Therefore they should be compared among their own type. After some fundamental tests are in place, expect the number of tests developed to drop over time. However, they will still be maintained. Source for this metric could be, for example, the Continuous Integration server or a manual count.
-
Metric 2b: Average development + maintenance effort for tests ordered by test type. Expect the effort for developing and maintaining tests to drop on average as the team gains experience and as some fundamental tests are in place. Maintenance effort could be a standard ratio of maintenance work or be separately administrated.
-
-
Question 3: How much benefit do automated tests offer us?
-
Metric 3a: Total development + maintenance effort for integration/regression/end-to-end tests divided by number of defects found. Initially, expect a correlation between a higher test development effort and fewer defects found. This would signify that tests become better over time in preventing defects. As the system grows naturally, more defects may occur because of more complex interactions. Therefore, the effect between test development effort and declining number of defects will weaken over time. Unit tests may be excluded as should be part of regular development and therefore you can assume that time for writing unit tests is not separately registered.
-
Metric 3b: Manual test time in acceptance environment. With an increase in test automation, expect a downward trend in manual test time. It may stabilize at some “minimum amount of manual acceptance testing.” Some development teams do achieve a full automation of acceptance testing but your organization might not have that ambition and constellation. In particular, ambitions would need to translate to costs and efforts of automating acceptance tests, and that is rather uncommon. There is an advantage of keeping part of acceptance tests manual: keeping in contact with users with the help of demos after each sprint (sprint reviews) also provides unforeseen feedback on usability, for example.
-
Metric 3c: Manual test time in acceptance divided by number of defects found in acceptance. This metric can help you to determine whether full acceptance test automation is a realistic goal. In general, the correlation is positive: the less time you spend on manual acceptance testing, the fewer defects you will find; the more time you spend, the more you will find. But with a high level of test automation, outcomes of additional manual acceptance tests should not surprise you. At some point you should find that extra effort spent in manual acceptance testing identifies no more bugs.
-
Metric 3d: Velocity/productivity in terms of story points per sprint. You can compare the velocity within a sprint with the average velocity over all development of the system. Initially you may expect an upward trend as the team gets up to speed and moves toward a stable rate of “burning” story points each sprint. We also expect productivity to gain with better tests. The velocity may be adversely affected by improperly implemented version control (because of merging difficulties after adjustments). The story point metric clearly assumes that story points are defined consistently by the team, so that a story point reflects approximately the same amount of effort over time.
-
-
Achieving the goal of optimizing the number of automated tests (Goal A) requires careful weighing. The question of whether you are doing enough testing should be answered by trading off risks and effort. With a mission-critical system the tolerance for bugs may be much lower than for an administrative system that does not cause too much trouble if it happens to be offline. A simple criterion to determine whether enough tests have been written is answering the question “does writing a further test really isolate a use case or situation that is not covered by other tests?” If the answer is “no,” your test writing efforts may be complete enough for the moment. However, tests need maintenance and fine-tuning for changing circumstances, such as adjusting the datasets for performance tests when functionality has changed. So testing, just like development, never really stops.
One way of visualizing test coverage is by using a treemap report: a chart that shows how big parts of your codebase are and how much of it is covered by tests (they could be unit tests, but also integration tests). Figure 6-1 shows a simplified visualization.
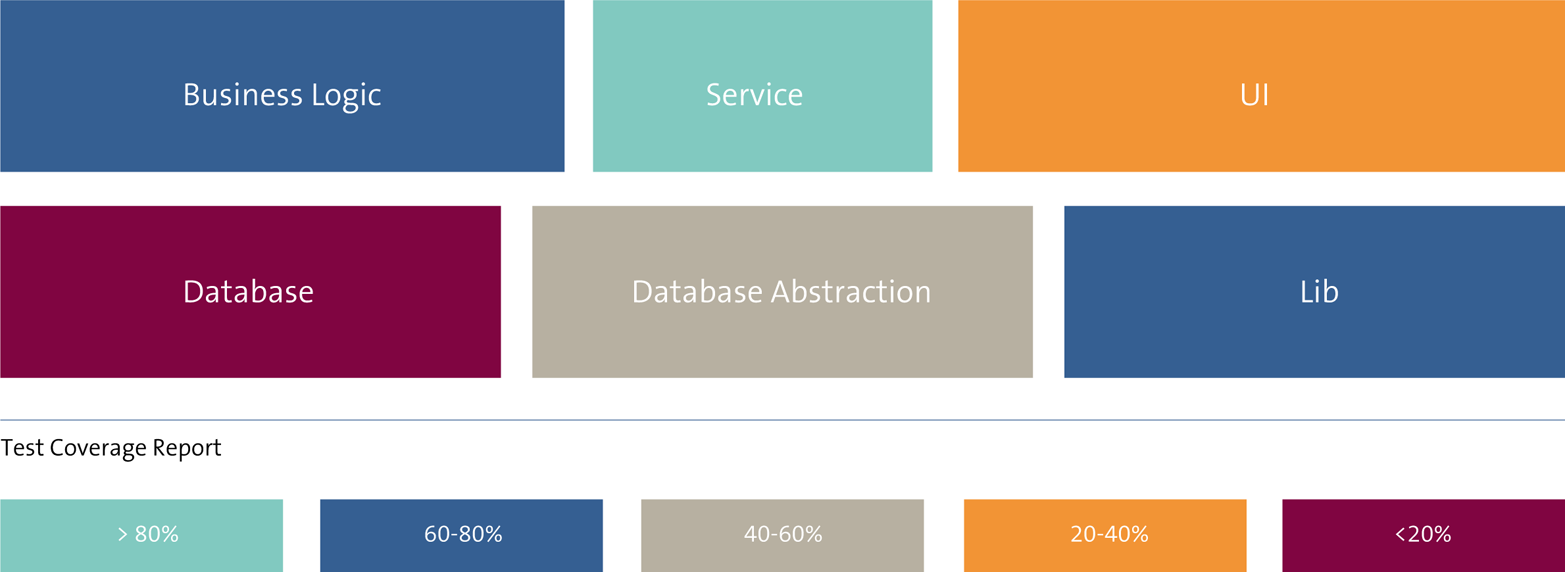
Figure 6-1. An example treemap test coverage report
Although such an image is not ideal for discovering a trend in your test coverage, it gives you insight into the overall test coverage of your system. In Figure 6-1, you can see that the database layer is hardly covered by tests, as well as the user interface part of the system. This does not need to be a problem, but asks for some analysis. Database-related code should normally not include a lot of logic and you should therefore expect tests in the database abstraction layer. Depending on your priorities, you may want to increase these test coverages or you may want to focus on getting, for example, the business logic layer fully covered.
Once you have more insight on the status of your test coverage, you can also better estimate the weak spots in your codebase:
-
Goal B: Knowing our weak spots in code that automated tests should catch.
-
Question 4: Based on test results, how well is our code guarded against known defects?
-
Metric 4a: Total of passed and failed tests ordered by test category. Expect a consistently high ratio of passed versus failed tests. Failed tests are not necessarily a problem. In fact, if tests never fail, they may not be strict enough or otherwise they may not have proper coverage of functionality. A sudden increase of failing tests definitely demands investigation. It could be that newer tests are of lesser quality, but also that test assumptions have changed that have not been taken into account yet.
-
Metric 4b: Percentage of failed tests blocking for shipment (has highest urgency). Expect a consistent low toward zero. Deviations ask for investigation.
-
Metric 4c: Percentage of failed unit tests for each build. Expect a consistent low percentage. Unit tests should fail sometimes, but they may signify that certain pieces of code are particularly complex or entangled. That may be a good starting point for refactoring efforts.
-
Metric 4d: Number of defects found in Test, Acceptance, and Production. This applies to all defects such as disappointing performance or found security vulnerabilities, but notably regression bugs can be well identified and prevented by tests. Therefore, the ideal number is zero but expect that to never happen. Do expect a downward trend and decreasing percentages between Test, Acceptance, and Production. The later the bugs are found, the more effort they require to solve. They may also signify the complexity of the bugs and give you new information about how tests can be improved.
-
-
Question 5: How well do we solve defects when they are identified?
-
Metric 5a: Average defect resolution time after identification. Consider the average resolution time for the current sprint and compare with the averages of all sprints. Expect a downward trend over time toward a stable amount of time needed to resolve defects, as tests are becoming more advanced. When comparing trends on system or sprint levels, you can tell whether in the current sprint, solving defects was easier or tougher than normal.
-
Metric 5b: Number of reoccurrences of the same or similar bug. Expect a downward slope with an ideal count of zero. Good tests particularly should avoid regression bugs from reappearing. This assumes mainly that reoccurrences are traceable. See also the following assumptions.
-
-
Assumptions Regarding These Metrics
Again we will make some assumptions about the nature of the metrics. These assumptions should allow us to keep the metrics fairly simple and help understand possible explanations of unexpected trend behavior.
For the metrics discussed here, consider the following assumptions:
-
Defects cannot be avoided completely but good tests identify failures/regression bugs quickly. This shortens the feedback loop and thus the development time needed to fix a defect.
-
On average, the odds of bugs and defects occurring within a system are roughly the same. We know this is not true in practice, because as a system grows in size and complexity, code tends to become more entangled and therefore there are more possibilities of defects occurring. However, we want to keep this assumption in mind because good tests should still ensure that these bugs are caught early.
-
We ignore weekends/holidays for the defect resolution metrics. Refer back to the discussion in “Make Assumptions about Your Metrics Explicit”.
-
Defects (in production) will be reported consistently when they occur. This assumption keeps us from concluding too quickly that a change in the number of defects is caused by a change in user behavior or defect administration.
-
Defects are registered in a way that reoccurrences refer to an earlier defect with, for example, a ticket identifier.
-
Defects are preferably registered with an estimate of resolution effort. However, it is generally beneficial to leave the defect effort estimates out of consideration, as otherwise we are essentially measuring how good the team is at effort estimation. What we really want to know is how good the team is at resolving defects. If those defects always happen to be tough ones, it is fair to investigate whether those large defects could have been avoided with code improvements and more, better tests.
-
Hours of effort are registered in a way specific enough to distinguish different types of development and test activities, for example, as development time for tests, and time for manual acceptance tests.
-
Writing unit tests is considered as an integral part of development and therefore not separately registered.
Common Objections to Test Automation Metrics
In this section, we discuss some common objections with respect to automating tests and measuring their implementation. The objections deal with the visibility of failing tests in production and the trade-off for writing unit tests.
Objection: Failing Tests Have No Noticeable Effects
“In our measurements we see that tests keep failing but they do not have noticeable effects in production.”
Situations exist where tests fail consistently while their effects are unclear. When using a metric for the number of failing tests, this seems to distort measurements. Remember that outliers in measurement always warrant an investigation into the causes. Consider two examples:
- Suddenly failing regression tests
-
Tests may fail because of changes in test data, test scripts, external systems’ behavior or data, or the test environment itself (tooling, setup), etc. Changes in any of the aforementioned may have been intentional. However, they still ask for analysis of the causes and revision of the tests.
- Consistently failing unit tests without noticeable effects
-
Failing unit tests are a showstopper for going to production! However, we know from experience that this occurs. An explanation can be that the failing unit tests concern code that does not run in production (and thus the test should be adjusted). It is more likely that effects are not noticeable because functionality is rarely used, or because the test is dependent on rare and specific system behavior. In fact, such rare and specific circumstances are typically the cases for which unit tests are insufficiently complete: tests should fail but they do not, because they have not been taken into account during development.
Thus, tests that fail but do not (immediately) have noticeable effects in production can still be highly useful tests. Remember that functionality that is rarely used in production may still be used at any moment and could even become frequently used in the future. Your automated tests should give you confidence for those situations as well.
Objection: Why Invest Effort in Writing Unit Tests for Code That Is Already Working?
“Why and to what extent should we invest in writing extra unit tests for code that already works?”
The best time to write a unit test is when the unit itself is being written, because the reasoning behind the unit is still fresh in the developer’s mind. When a very large system has little to no unit test code, it would be a significant investment to start writing unit tests from scratch. This should only be done if its effort is worth the added certainty. The effort is especially worth it for critical, central functionality and when there is reason to believe that units are behaving unpredictably.
A common variation of this objection is that there is no time to write (unit) tests because developers are pushed to deliver functionality before a deadline. This is unfortunately common but very risky. We can be curt about this: no unit tests means no quality. If all else fails, the team may choose to write higher-level tests that add confidence on the functionality such as interfaces and end-to-end tests. However, without proper unit testing you will lack confidence knowing whether or not the system arrives at the right output by accident or not.
Important
Make it a habit for all developers to review (or add) unit tests each time units are changed or added. This practice of leaving code better than you found it is known as the “Boy Scout Rule.” Consider that it is especially worth refactoring code during maintenance when unit test coverage is low because the code is hard to test.
Metrics Overview
As a recap, Table 6-2 shows an overview of the metrics discussed in this chapter, with their corresponding goals.
| Metric # in text | Metric description | Corresponding goal |
|---|---|---|
AT 1a |
Unit test coverage |
Optimal amount of testing (coverage) |
AT 1b |
Executed test cases |
Optimal amount of testing (coverage) |
AT 2a |
Developed test cases |
Optimal amount of testing (investment) |
AT 2b |
Test case development/maintenance effort |
Optimal amount of testing (investment) |
AT 3a |
Development effort versus defects |
Optimal amount of testing (effectiveness) |
AT 3b |
Manual acceptance test time |
Optimal amount of testing (effectiveness) |
AT 3c |
Manual acceptance test time versus defects |
Optimal amount of testing (effectiveness) |
AT 3d |
Velocity |
Optimal amount of testing (effectiveness) |
AT 4a |
Passed versus failed tests |
Robustness against bugs |
AT 4b |
Percentage failed blocking tests |
Robustness against bugs |
AT 4c |
Percentage failed unit tests for each build |
Robustness against bugs |
AT 4d |
Defects found in Test, Acceptance, Production |
Robustness against bugs |
AT 5a |
Average defect resolution time |
Defect resolution effectiveness |
AT 5b |
Reoccurrences of same bug |
Defect resolution effectiveness |
To fully benefit from automated tests you must integrate test runs in the development pipeline so that they are also kicked off automatically. Notably this concerns unit tests as part of the build cycle. Chapter 7 elaborates on this.