
Chapter 6. Discrete Cosine Transform
The topic of this chapter is the Discrete Cosine Transform (DCT), which is used in MP3 and related formats for compressing music; JPEG and similar formats for images; and the MPEG family of formats for video.
The DCT is similar in many ways to the Discrete Fourier Transform (DFT), which we have been using for spectral analysis. Once we learn how the DCT works, it will be easier to explain the DFT.
Here are the steps to get there:
We’ll start with the synthesis problem: given a set of frequency components and their amplitudes, how can we construct a wave?
Next we’ll rewrite the synthesis problem using NumPy arrays. This move is good for performance, and also provides insight for the next step.
We’ll look at the analysis problem: given a signal and a set of frequencies, how can we find the amplitude of each frequency component? We’ll start with a solution that is conceptually simple but slow.
Finally, we’ll use some principles from linear algebra to find a more efficient algorithm. If you already know linear algebra, that’s great, but I’ll explain what you need as we go.
The code for this chapter is in chap06.ipynb, which is in the repository for this book (see “Using the Code”). You can also view it at http://tinyurl.com/thinkdsp06.
Synthesis
Suppose I give you a list of amplitudes and a list of frequencies, and ask you to construct a signal that is the sum of these frequency components. Using objects in the thinkdsp module, there is a simple way to perform this operation, which is called synthesis:
def synthesize1(amps, fs, ts):
components = [thinkdsp.CosSignal(freq, amp)
for amp, freq in zip(amps, fs)]
signal = thinkdsp.SumSignal(*components)
ys = signal.evaluate(ts)
return ysamps is a list of amplitudes, fs is the list of frequencies, and ts is the sequence of times where the signal should be evaluated.
components is a list of CosSignal objects, one for each amplitude–frequency pair. SumSignal represents the sum of these frequency components.
Finally, evaluate computes the value of the signal at each time in ts.
We can test this function like this:
amps = np.array([0.6, 0.25, 0.1, 0.05]) fs = [100, 200, 300, 400] framerate = 11025 ts = np.linspace(0, 1, framerate) ys = synthesize1(amps, fs, ts) wave = thinkdsp.Wave(ys, framerate)
This example makes a signal that contains a fundamental frequency at 100 Hz and three harmonics (100 Hz is a sharp G2). It renders the signal for 1 second at 11,025 frames per second and puts the results into a Wave object.
Conceptually, synthesis is pretty simple. But in this form it doesn’t help much with analysis, which is the inverse problem: given the wave, how do we identify the frequency components and their amplitudes?
Synthesis with Arrays
Here’s another way to write synthesize:
def synthesize2(amps, fs, ts):
args = np.outer(ts, fs)
M = np.cos(PI2 * args)
ys = np.dot(M, amps)
return ysThis function looks very different, but it does the same thing. Let’s see how it works:
np.outercomputes the outer product oftsandfs. The result is an array with one row for each element oftsand one column for each element offs. Each element in the array is the product of a frequency and a time, .
.We multiply
argsby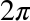 and apply
and apply cos, so each element of the result is . Since the
. Since the tsruns down the columns, each column contains a cosine signal at a particular frequency, evaluated at a sequence of times.np.dotmultiplies each row ofMbyamps, elementwise, and then adds up the products. In terms of linear algebra, we are multiplying a matrix,M, by a vector,amps. In terms of signals, we are computing the weighted sum of frequency components.
Figure 6-1 shows the structure of this computation. Each row of the matrix, M, corresponds to a time from 0.0 to 1.0 seconds; tn is the time of the nth row. Each column corresponds to a frequency from 100 to 400 Hz; fk is the frequency of the kth column.

Figure 6-1. Synthesis with arrays.
I labeled the nth row with the letters a through d; as an example, the value of a is ![]() .
.
The result of the dot product, ys, is a vector with one element for each row of M. The nth element, labeled e, is the sum of products:
And likewise with the other elements of ys. So each element of ys is the sum of four frequency components, evaluated at a point in time and multiplied by the corresponding amplitudes. And that’s exactly what we wanted.
We can use the code from the previous section to check that the two versions of synthesize produce the same results:
ys1 = synthesize1(amps, fs, ts) ys2 = synthesize2(amps, fs, ts) max(abs(ys1 - ys2))
The biggest difference between ys1 and ys2 is about 1e-13, which is what we expect due to floating-point errors.
Writing this computation in terms of linear algebra makes the code smaller and faster. Linear algebra provides concise notation for operations on matrices and vectors. For example, we could write synthesize like this:

where a is a vector of amplitudes, t is a vector of times, f is a vector of frequencies, and ⊗ is the symbol for the outer product of two vectors.
Analysis
Now we are ready to solve the analysis problem. Suppose I give you a wave and tell you that it is the sum of cosines with a given set of frequencies. How would you find the amplitude for each frequency component? In other words, given ys, ts, and fs, can you recover amps?
In terms of linear algebra, the first step is the same as for synthesis: we compute ![]() . Then we want to find a so that
. Then we want to find a so that ![]() ; in other words, we want to solve a linear system. NumPy provides
; in other words, we want to solve a linear system. NumPy provides linalg.solve, which does exactly that.
Here’s what the code looks like:
def analyze1(ys, fs, ts):
args = np.outer(ts, fs)
M = np.cos(PI2 * args)
amps = np.linalg.solve(M, ys)
return ampsThe first two lines use ts and fs to build the matrix, M. Then np.linalg.solve computes amps.
But there’s a hitch. In general we can only solve a system of linear equations if the matrix is square; that is, if the number of equations (rows) is the same as the number of unknowns (columns).
In this example, we have only 4 frequencies, but we evaluated the signal at 11,025 times. So we have many more equations than unknowns.
In general if ys contains more than 4 elements, it is unlikely that we can analyze it using only 4 frequencies.
But in this case, we know that the ys values were actually generated by adding only 4 frequency components, so we can use any 4 values from the wave array to recover amps.
For simplicity, I’ll use the first 4 samples from the signal. Using the values of ys, fs, and ts from the previous section, we can run analyze1 like this:
n = len(fs) amps2 = analyze1(ys[:n], fs, ts[:n])
And sure enough, amps2 is:
[ 0.6 0.25 0.1 0.05 ]
This algorithm works, but it is slow. Solving a linear system of equations takes time proportional to n3, where n is the number of columns in M. We can do better.
Orthogonal Matrices
One way to solve linear systems is by inverting matrices. The inverse of a square matrix M is written ![]() , and it has the property that
, and it has the property that ![]() . I is the identity matrix, which has the value 1 on all diagonal elements and 0 everywhere else.
. I is the identity matrix, which has the value 1 on all diagonal elements and 0 everywhere else.
So, to solve the equation ![]() , we can multiply both sides by
, we can multiply both sides by ![]() , which yields:
, which yields:

On the right side, we can replace ![]() with I:
with I:

If we multiply I by any vector a, the result is a, so:

This implies that if we can compute ![]() efficiently, we can find a with a simple matrix multiplication (using
efficiently, we can find a with a simple matrix multiplication (using np.dot). That takes time proportional to n2, which is better than n3.
Inverting a matrix is slow, in general, but some special cases are faster. In particular, if M is orthogonal, the inverse of M is just the transpose of M, written MT. In NumPy transposing an array is a constant-time operation. It doesn’t actually move the elements of the array; instead, it creates a “view” that changes the way the elements are accessed.
Again, a matrix is orthogonal if its transpose is also its inverse; that is, ![]() . That implies that
. That implies that ![]() , which means we can check whether a matrix is orthogonal by computing MTM.
, which means we can check whether a matrix is orthogonal by computing MTM.
So let’s see what the matrix looks like in synthesize2. In the previous example, M has 11,025 rows, so it might be a good idea to work with a smaller example:
def test1():
amps = np.array([0.6, 0.25, 0.1, 0.05])
N = 4.0
time_unit = 0.001
ts = np.arange(N) / N * time_unit
max_freq = N / time_unit / 2
fs = np.arange(N) / N * max_freq
ys = synthesize2(amps, fs, ts)amps is the same vector of amplitudes we saw before. Since we have 4 frequency components, we’ll sample the signal at 4 points in time. That way, M is square.
ts is a vector of equally spaced sample times in the range from 0 to 1 time unit. I chose the time unit to be 1 millisecond, but it is an arbitrary choice, and we will see in a minute that it drops out of the computation anyway.
Since the frame rate is N samples per time unit, the Nyquist frequency is N / time_unit / 2, which is 2000 Hz in this example. So fs is a vector of equally spaced frequencies between 0 and 2000 Hz.
With these values of ts and fs, the matrix, M, is:
[[ 1. 1. 1. 1. ] [ 1. 0.707 0. -0.707] [ 1. 0. -1. -0. ] [ 1. -0.707 -0. 0.707]]
You might recognize 0.707 as an approximation of ![]() , which is
, which is ![]() . You also might notice that this matrix is symmetric, which means that the element at
. You also might notice that this matrix is symmetric, which means that the element at ![]() always equals the element at
always equals the element at ![]() . This implies that M is its own transpose; that is,
. This implies that M is its own transpose; that is, ![]() .
.
But sadly, M is not orthogonal. If we compute MTM, we get:
[[ 4. 1. -0. 1.] [ 1. 2. 1. -0.] [-0. 1. 2. 1.] [ 1. -0. 1. 2.]]
And that’s not the identity matrix.
DCT-IV
But if we choose ts and fs carefully, we can make M orthogonal. There are several ways to do it, which is why there are several versions of the Discrete Cosine Transform (DCT).
One simple option is to shift ts and fs by a half unit. This version is called DCT-IV, where “IV” is a roman numeral indicating that this is the fourth of eight versions of the DCT.
Here’s an updated version of test1:
def test2():
amps = np.array([0.6, 0.25, 0.1, 0.05])
N = 4.0
ts = (0.5 + np.arange(N)) / N
fs = (0.5 + np.arange(N)) / 2
ys = synthesize2(amps, fs, ts)If you compare this to the previous version, you’ll notice two changes. First, I added 0.5 to ts and fs. Second, I canceled out time_units, which simplifies the expression for fs.
With these values, M is:
[[ 0.981 0.831 0.556 0.195] [ 0.831 -0.195 -0.981 -0.556] [ 0.556 -0.981 0.195 0.831] [ 0.195 -0.556 0.831 -0.981]]
And MTM is:
[[ 2. 0. 0. 0.] [ 0. 2. -0. 0.] [ 0. -0. 2. -0.] [ 0. 0. -0. 2.]]
Some of the off-diagonal elements are displayed as –0, which means that the floating-point representation is a small negative number. This matrix is very close to 2I, which means M is almost orthogonal; it’s just off by a factor of 2. And for our purposes, that’s good enough.
Because M is symmetric and (almost) orthogonal, the inverse of M is just ![]() . Now we can write a more efficient version of
. Now we can write a more efficient version of analyze:
def analyze2(ys, fs, ts):
args = np.outer(ts, fs)
M = np.cos(PI2 * args)
amps = np.dot(M, ys) / 2
return ampsInstead of using np.linalg.solve, we just multiply by ![]() .
.
Combining test2 and analyze2, we can write an implementation of DCT-IV:
def dct_iv(ys):
N = len(ys)
ts = (0.5 + np.arange(N)) / N
fs = (0.5 + np.arange(N)) / 2
args = np.outer(ts, fs)
M = np.cos(PI2 * args)
amps = np.dot(M, ys) / 2
return ampsAgain, ys is the wave array. We don’t have to pass ts and fs as parameters; dct_iv can figure them out based on N, the length of ys.
If we’ve got it right, this function should solve the analysis problem; that is, given ys it should be able to recover amps. We can test it like this:
amps = np.array([0.6, 0.25, 0.1, 0.05]) N = 4.0 ts = (0.5 + np.arange(N)) / N fs = (0.5 + np.arange(N)) / 2 ys = synthesize2(amps, fs, ts) amps2 = dct_iv(ys) max(abs(amps - amps2))
Starting with amps, we synthesize a wave array, then use dct_iv to compute amps2. The biggest difference between amps and amps2 is about 1e-16, which is what we expect due to floating-point errors.
Inverse DCT
Finally, notice that analyze2 and synthesize2 are almost identical. The only difference is that analyze2 divides the result by 2. We can use this insight to compute the inverse DCT:
def inverse_dct_iv(amps):
return dct_iv(amps) * 2inverse_dct_iv solves the synthesis problem: it takes the vector of amplitudes and returns the wave array, ys. We can test it by starting with amps, applying inverse_dct_iv and dct_iv, and testing that we get back what we started with:
amps = [0.6, 0.25, 0.1, 0.05] ys = inverse_dct_iv(amps) amps2 = dct_iv(ys) max(abs(amps - amps2))
Again, the biggest difference is about 1e-16.
The Dct Class
thinkdsp provides a Dct class that encapsulates the DCT in the same way the Spectrum class encapsulates the FFT. To make a Dct object, you can invoke make_dct on a Wave:
signal = thinkdsp.TriangleSignal(freq=400) wave = signal.make_wave(duration=1.0, framerate=10000) dct = wave.make_dct() dct.plot()
The result is the DCT of a triangle wave at 400 Hz, shown in Figure 6-2. The values of the DCT can be positive or negative; a negative value in the DCT corresponds to a negated cosine or, equivalently, to a cosine shifted by 180 degrees.

Figure 6-2. DCT of a triangle signal at 400 Hz, sampled at 10 kHz.
make_dct uses DCT-II, which is the most common type of DCT, provided by scipy.fftpack:
import scipy.fftpack
# class Wave:
def make_dct(self):
N = len(self.ys)
hs = scipy.fftpack.dct(self.ys, type=2)
fs = (0.5 + np.arange(N)) / 2
return Dct(hs, fs, self.framerate)The results from dct are stored in hs. The corresponding frequencies, computed as in “DCT-IV”, are stored in fs. And then both are used to initialize the Dct object.
Dct provides make_wave, which performs the inverse DCT. We can test it like this:
wave2 = dct.make_wave() max(abs(wave.ys-wave2.ys))
The biggest difference between ys1 and ys2 is about 1e-16, which is what we expect due to floating-point errors.
make_wave uses scipy.fftpack.idct:
# class Dct
def make_wave(self):
n = len(self.hs)
ys = scipy.fftpack.idct(self.hs, type=2) / 2 / n
return Wave(ys, framerate=self.framerate)By default, the inverse DCT doesn’t normalize the result, so we have to divide through by 2N.
Exercises
For the following exercises, I provide some starter code in chap06starter.ipynb. Solutions are in chap06soln.ipynb.
Exercise 6-1.
In this chapter I claim that analyze1 takes time proportional to n3 and analyze2 takes time proportional to n2. To see if that’s true, run them on a range of input sizes and time them. In Jupyter, you can use the “magic command” %timeit.
If you plot run time versus input size on a log-log scale, you should get a straight line with slope 3 for analyze1 and slope 2 for analyze2.
Exercise 6-2.
One of the major applications of the DCT is compression for both sound and images. In its simplest form, DCT-based compression works like this:
Break a long signal into segments.
Compute the DCT of each segment.
Identify frequency components with amplitudes so low they are inaudible, and remove them. Store only the frequencies and amplitudes that remain.
To play back the signal, load the frequencies and amplitudes for each segment and apply the inverse DCT.
Implement a version of this algorithm and apply it to a recording of music or speech. How many components can you eliminate before the difference is perceptible?
In order to make this method practical, you need some way to store a sparse array; that is, an array where most of the elements are zero. NumPy provides several implementations of sparse arrays, which you can read about at http://docs.scipy.org/doc/scipy/reference/sparse.html.
Exercise 6-3.
In the repository for this book you will find a Jupyter notebook called phase.ipynb that explores the effect of phase on sound perception. Read through this notebook and run the examples. Choose another segment of sound and run the same experiments. Can you find any general relationships between the phase structure of a sound and how we perceive it?