
![]()
Redo and Undo
This chapter introduces you two of the most important pieces of data in an Oracle database: redo and undo. Redo is the information Oracle records in online (and archived) redo log files in order to “replay” your transaction in the event of a failure. Undo is the information Oracle records in the undo segments in order to reverse, or roll back, your transaction.
In this chapter, we will discuss topics such as how redo and undo (rollback) are generated, and how they fit into transactions. We’ll also discuss the performance implications of COMMIT and ROLLBACK statements. I will present the pseudo-code for these mechanisms in Oracle and a conceptual explanation of what actually takes place. I will not cover every internal detail of what files get updated with what bytes of data. What actually takes place is a little more involved, but having a good understanding of the flow of how it works is valuable and will help you to understand the ramifications of your actions.
![]() Note Time and time again, I get questions regarding the exact bits and bytes of redo and undo. People seem to want to have a very detailed specification of exactly, precisely, what is in there. I never answer those questions. Instead, I focus on the intent of redo and undo, the concepts behind redo and undo. I focus on the use of redo and undo—not on the bits and bytes. I myself do not “dump” redo log files or undo segments. I do use the supplied tools, such as LogMiner to read redo and flashback transaction history to read undo, but that presents the information to me in a human-readable format. So, we won’t be doing internals in this chapter but rather building a strong foundation.
Note Time and time again, I get questions regarding the exact bits and bytes of redo and undo. People seem to want to have a very detailed specification of exactly, precisely, what is in there. I never answer those questions. Instead, I focus on the intent of redo and undo, the concepts behind redo and undo. I focus on the use of redo and undo—not on the bits and bytes. I myself do not “dump” redo log files or undo segments. I do use the supplied tools, such as LogMiner to read redo and flashback transaction history to read undo, but that presents the information to me in a human-readable format. So, we won’t be doing internals in this chapter but rather building a strong foundation.
What Is Redo?
Redo log files are crucial to the Oracle database. These are the transaction logs for the database. Oracle maintains two types of redo log files: online and archived. They are used for recovery purposes; their main purpose in life is to be used in the event of an instance or media failure.
If the power goes off on your database machine, causing an instance failure, Oracle will use the online redo logs to restore the system to exactly the committed point it was at immediately prior to the power outage. If your disk drive fails (a media failure), Oracle will use both archived redo logs and online redo logs to recover a backup of the data that was on that drive to the correct point in time. Moreover, if you “accidentally” truncate a table or remove some critical information and commit the operation, you can restore a backup of the affected data and recover it to the point in time immediately prior to the “accident” using online and archived redo log files.
Archived redo log files are simply copies of old, full online redo log files. As the system fills up log files, the ARCn process makes a copy of the online redo log file in another location, and optionally puts several other copies into local and remote locations as well. These archived redo log files are used to perform media recovery when a failure is caused by a disk drive going bad or some other physical fault. Oracle can take these archived redo log files and apply them to backups of the data files to catch them up to the rest of the database. They are the transaction history of the database.
![]() Note With the advent of Oracle 10g, we now have flashback technology. This allows us to perform flashback queries (query the data as of some point in time in the past), un-drop a database table, put a table back the way it was some time ago, and so on. As a result, the number of occasions in which we need to perform a conventional recovery using backups and archived redo logs has decreased. However, the ability to perform a recovery is the DBA’s most important job. Database recovery is the one thing a DBA is not allowed to get wrong.
Note With the advent of Oracle 10g, we now have flashback technology. This allows us to perform flashback queries (query the data as of some point in time in the past), un-drop a database table, put a table back the way it was some time ago, and so on. As a result, the number of occasions in which we need to perform a conventional recovery using backups and archived redo logs has decreased. However, the ability to perform a recovery is the DBA’s most important job. Database recovery is the one thing a DBA is not allowed to get wrong.
Every Oracle database has at least two online redo log groups with at least a single member (redo log file) in each group. These online redo log groups are written to in a circular fashion. Oracle will write to the log files in group 1, and when it gets to the end of the files in group 1, it will switch to log file group 2 and begin writing to that one. When it has filled log file group 2, it will switch back to log file group 1 (assuming you have only two redo log file groups; if you have three, Oracle would, of course, proceed to the third group).
Redo logs, or transaction logs, are one of the major features that make a database a database. They are perhaps its most important recovery structure, although without the other pieces such as undo segments, distributed transaction recovery, and so on, nothing works. They are a major component of what sets a database apart from a conventional file system. The online redo logs allow us to effectively recover from a power outage—one that might happen while Oracle is in the middle of a write. The archived redo logs let us recover from media failures when, for instance, the hard disk goes bad or human error causes data loss. Without redo logs, the database would not offer any more protection than a file system.
What Is Undo?
Undo is conceptually the opposite of redo. Undo information is generated by the database as you make modifications to data so that the data can be put back the way it was before the modifications took place. This might be done in support of multiversioning, or in the event the transaction or statement you are executing fails for any reason, or if we request it with a ROLLBACK statement. Whereas redo is used to replay a transaction in the event of failure—to recover the transaction—undo is used to reverse the effects of a statement or set of statements. Undo, unlike redo, is stored internally in the database in a special set of segments known as undo segments.
![]() Note “Rollback segment” and “undo segment” are considered synonymous terms. Using manual undo management, the DBA will create “rollback segments.” Using automatic undo management, the system will automatically create and destroy “undo segments” as necessary. These terms should be considered the same for all intents and purposes in this discussion.
Note “Rollback segment” and “undo segment” are considered synonymous terms. Using manual undo management, the DBA will create “rollback segments.” Using automatic undo management, the system will automatically create and destroy “undo segments” as necessary. These terms should be considered the same for all intents and purposes in this discussion.
It is a common misconception that undo is used to restore the database physically to the way it was before the statement or transaction executed, but this is not so. The database is logically restored to the way it was—any changes are logically undone—but the data structures, the database blocks themselves, may well be different after a rollback. The reason for this lies in the fact that, in any multiuser system, there will be tens or hundreds or thousands of concurrent transactions. One of the primary functions of a database is to mediate concurrent access to its data. The blocks that our transaction modifies are, in general, being modified by many other transactions as well. Therefore, we can’t just put a block back exactly the way it was at the start of our transaction—that could undo someone else’s work!
For example, suppose our transaction executed an INSERT statement that caused the allocation of a new extent (i.e., it caused the table to grow). Our INSERT would cause us to get a new block, format it for use, and put some data into it. At that point, some other transaction might come along and insert data into this block. If we roll back our transaction, obviously we can’t unformat and unallocate this block. Therefore, when Oracle rolls back, it is really doing the logical equivalent of the opposite of what we did in the first place. For every INSERT, Oracle will do a DELETE. For every DELETE, Oracle will do an INSERT. For every UPDATE, Oracle will do an “anti-UPDATE,” or an UPDATE that puts the row back the way it was prior to our modification.
![]() Note This undo generation is not true for direct-path operations, which have the ability to bypass undo generation on the table. We’ll discuss these operations in more detail shortly.
Note This undo generation is not true for direct-path operations, which have the ability to bypass undo generation on the table. We’ll discuss these operations in more detail shortly.
How can we see this in action? Perhaps the easiest way is to follow these steps:
- Create an empty table.
- Full-scan the table and observe the amount of I/O performed to read it.
- Fill the table with many rows (no commit).
- Roll back that work and undo it.
- Full-scan the table a second time and observe the amount of I/O performed.
So, let’s create an empty table:
EODA@ORA12CR1> create table t
2 as
3 select *
4 from all_objects
5 where 1=0;
Table created.
And now we’ll query it, with AUTOTRACE enabled in SQL*Plus to measure the I/O.
![]() Note In this example, we will full-scan the table twice each time. The goal is to only measure the I/O performed the second time in each case. This avoids counting additional I/Os performed by the optimizer during any parsing and optimization that may occur.
Note In this example, we will full-scan the table twice each time. The goal is to only measure the I/O performed the second time in each case. This avoids counting additional I/Os performed by the optimizer during any parsing and optimization that may occur.
The query initially takes no I/Os to full-scan the table:
EODA@ORA12CR1> select * from t;
no rows selected
EODA@ORA12CR1> set autotrace traceonly statistics
EODA@ORA12CR1> select * from t;
no rows selected
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
0 consistent gets
0 physical reads
EODA@ORA12CR1> set autotrace off
Now, that might surprise you at first—especially if you are an Oracle user dating back to versions before Oracle 11g Release 2—that there are zero I/Os against the table. This is due to a new Oracle 11g Release 2 feature—deferred segment creation.
![]() Note The deferred segment creation feature is available only with the Enterprise Edition of Oracle. This feature is enabled by default in Oracle 11g Release 2 and higher. You can override this default behavior when creating the table.
Note The deferred segment creation feature is available only with the Enterprise Edition of Oracle. This feature is enabled by default in Oracle 11g Release 2 and higher. You can override this default behavior when creating the table.
If you run this example in older releases, you’ll likely see three or so I/O’s performed. We’ll discuss that in a moment, but for now let’s continue this example. Next, we’ll add lots of data to the table. We’ll make it “grow,” then roll it all back:
EODA@ORA12CR1> insert into t select * from all_objects;
18371 rows created.
EODA@ORA12CR1> rollback;
Rollback complete.
Now, if we query the table again, we’ll discover that it takes considerably more I/Os to read the table this time:
EODA@ORA12CR1> select * from t;
no rows selected
EODA@ORA12CR1> set autotrace traceonly statistics
EODA@ORA12CR1> select * from t;
no rows selected
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
317 consistent gets
0 physical reads
EODA@ORA12CR1> set autotrace off
The blocks that our INSERT caused to be added under the table’s high-water mark (HWM) are still there—formatted, but empty. Our full scan had to read them to see if they contained any rows. Moreover, the first time we ran the query, we observed zero I/Os. That was due to the default mode of table creation in Oracle 11g Release 2—using deferred segment creation. When we issued that CREATE TABLE, no storage, not a single extent, was allocated. The segment creation was deferred until the INSERT took place, and when we rolled back, the segment persisted. You can see this easily with a smaller example, I’ll explicitly request deferred segment creation this time although it is enabled by default in 11g Release 2 and higher:
EODA@ORA12CR1> drop table t purge;
Table dropped.
EODA@ORA12CR1> create table t (x int )
2 segment creation deferred;
Table created.
EODA@ORA12CR1> select extent_id, bytes, blocks
2 from user_extents
3 where segment_name = 'T'
4 order by extent_id;
no rows selected
EODA@ORA12CR1> insert into t(x) values (1);
1 row created.
EODA@ORA12CR1> rollback;
Rollback complete.
EODA@ORA12CR1> select extent_id, bytes, blocks
2 from user_extents
3 where segment_name = 'T'
4 order by extent_id;
EXTENT_ID BYTES BLOCKS
---------- ---------- ----------
0 65536 8
As you can see, after the table was initially created there was no allocated storage—no extents were used by this table. Upon performing an INSERT, followed immediately by ROLLBACK, we can see the INSERT allocated storage—but the ROLLBACK does not “release” it.
Those two things together—that the segment was actually created by the INSERT but not “uncreated” by the ROLLBACK, and that the new formatted blocks created by the INSERT were scanned the second time around—show that a rollback is a logical “put the database back the way it was” operation. The database will not be exactly the way it was, just logically the same.
How Redo and Undo Work Together
Now let’s take a look at how redo and undo work together in various scenarios. We will discuss, for example, what happens during the processing of an INSERT with regard to redo and undo generation, and how Oracle uses this information in the event of failures at various points in time.
An interesting point to note is that undo information, stored in undo tablespaces or undo segments, is protected by redo as well. In other words, undo data is treated just like table data or index data—changes to undo generates some redo, which is logged (to the log buffer and then the redo log file). Why this is so will become clear in a moment when we discuss what happens when a system crashes. Undo data is added to the undo segment and is cached in the buffer cache, just like any other piece of data would be.
Example INSERT-UPDATE-DELETE-COMMIT Scenario
For this example, assume we’ve created a table with an index as follows:
create table t(x int, y int);
create index ti on t(x);
And then we will investigate what might happen with a set of statements like this:
insert into t (x,y) values (1,1);
update t set x = x+1 where x = 1;
delete from t where x = 2;
We will follow this transaction down different paths and discover the answers to the following questions:
- What happens if the system fails at various points in the processing of these statements?
- What happens if the buffer cache fills up?
- What happens if we ROLLBACK at any point?
- What happens if we succeed and COMMIT?
The initial INSERT INTO T statement will generate both redo and undo. The undo generated will be enough information to make the INSERT “go away.” The redo generated by the INSERT INTO T will be enough information to make the INSERT “happen again.”
After the INSERT has occurred, we have the scenario illustrated in Figure 6-1.

Figure 6-1. State of the system after an INSERT
There are some cached, modified undo blocks, index blocks, and table data blocks. Each of these blocks is protected by entries in the redo log buffer.
Hypothetical Scenario: The System Crashes Right Now
In this scenario, the system crashes before a COMMIT is issued or before the redo entries are written to disk. Everything is OK. The SGA is wiped out, but we don’t need anything that was in the SGA. It will be as if this transaction never happened when we restart. None of the blocks with changes got flushed to disk, and none of the redo got flushed to disk. We have no need of any of this undo or redo to recover from an instance failure.
Hypothetical Scenario: The Buffer Cache Fills Up Right Now
The situation is such that DBWn must make room and our modified blocks are to be flushed from the cache. In this case, DBWn will start by asking LGWR to flush the redo entries that protect these database blocks. Before DBWn can write any of the blocks that are changed to disk, LGWR must flush (to disk) the redo information related to these blocks. This makes sense: if we were to flush the modified blocks for table T (but not the undo blocks associated with the modifications) without flushing the redo entries associated with the undo blocks, and the system failed, we would have a modified table T block with no undo information associated with it. We need to flush the redo log buffers before writing these blocks out so that we can redo all of the changes necessary to get the SGA back into the state it is in right now, so that a rollback can take place.
This second scenario shows some of the foresight that has gone into all of this. The set of conditions described by “If we flushed table T blocks and did not flush the redo for the undo blocks and the system failed” is starting to get complex. It only gets more complex as we add users, and more objects, and concurrent processing, and so on.
At this point, we have the situation depicted in Figure 6-1. We have generated some modified table and index blocks. These have associated undo segment blocks, and all three types of blocks have generated redo to protect them. The redo log buffer is flushed at least every three seconds, when it is one-third full or contains 1MB of buffered data, or whenever a COMMIT or ROLLBACK takes place. It is very possible that at some point during our processing, the redo log buffer will be flushed. In that case, the picture will look like Figure 6-2.
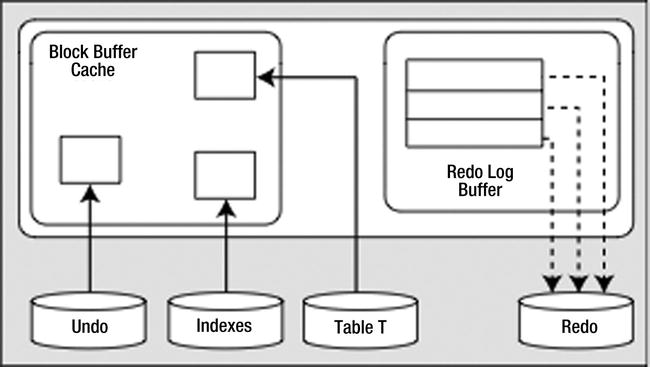
Figure 6-2. State of the system after a redo log buffer flush
That is, we’ll have modified blocks representing uncommitted changes in the buffer cache and redo for those uncommitted changes on disk. This is a very normal scenario that happens frequently.
The UPDATE will cause much of the same work as the INSERT to take place. This time, the amount of undo will be larger; we have some “before” images to save as a result of the UPDATE. Now we have the picture shown in Figure 6-3 (the dark rectangle in the redo log file represents the redo generated by the INSERT, the redo for the UPDATE is still in the SGA and has not yet been written to disk).
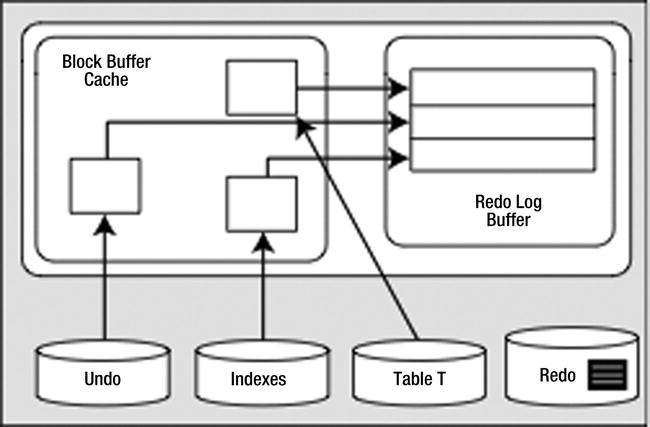
Figure 6-3. State of the system after the UPDATE
We have more new undo segment blocks in the block buffer cache. To undo the UPDATE, if necessary, we have modified database table and index blocks in the cache. We have also generated more redo log buffer entries. Let’s assume that our redo generated from the INSERT statement (discussed in the prior section) is on disk (in the redo log file) and redo generated from the UPDATE is in cache.
Hypothetical Scenario: The System Crashes Right Now
Upon startup, Oracle would read the redo log files and find some redo log entries for our transaction. Given the state in which we left the system, we have the redo entries generated by the INSERT in the redo log files (which includes redo for undo segments associated with the INSERT). However, the redo for the UPDATE was only in the log buffer and never made it to disk (and was wiped out when the system crashed). That’s okay, the transaction was never committed and the data files on disk reflect the state of the system before the UPDATE took place.
However, the redo for the INSERT was written to the redo log file. Therefore Oracle would “roll forward” the INSERT. We would end up with a picture much like Figure 6-1, with modified undo blocks (information on how to undo the INSERT), modified table blocks (right after the INSERT), and modified index blocks (right after the INSERT). Oracle will discover that our transaction never committed and will roll it back since the system is doing crash recovery and, of course, our session is no longer connected.
To roll back the uncommitted INSERT, Oracle will use the undo it just rolled forward (from the redo and now in the buffer cache) and apply it to the data and index blocks, making them look as they did before the INSERT took place. Now everything is back the way it was. The blocks that are on disk may or may not reflect the INSERT (it depends on whether or not our blocks got flushed before the crash). If the blocks on disk do reflect the INSERT, then the INSERT will be undone when the blocks are flushed from the buffer cache. If they do not reflect the undone INSERT, so be it—they will be overwritten later anyway.
This scenario covers the rudimentary details of a crash recovery. The system performs this as a two-step process. First it rolls forward, bringing the system right to the point of failure, and then it proceeds to roll back everything that had not yet committed. This action will resynchronize the data files. It replays the work that was in progress and undoes anything that has not yet completed.
Hypothetical Scenario: The Application Rolls Back the Transaction
At this point, Oracle will find the undo information for this transaction either in the cached undo segment blocks (most likely) or on disk if they have been flushed (more likely for very large transactions). It will apply the undo information to the data and index blocks in the buffer cache, or if they are no longer in the cache request, they are read from disk into the cache to have the undo applied to them. These blocks will later be flushed to the data files with their original row values restored.
This scenario is much more common than the system crash. It is useful to note that during the rollback process, the redo logs are never involved. The only time redo logs are read for recovery purposes is during recovery and archival. This is a key tuning concept: redo logs are written to. Oracle does not read them during normal processing. As long as you have sufficient devices so that when ARCn is reading a file, LGWR is writing to a different device, there is no contention for redo logs. Many other databases treat the log files as “transaction logs.” They do not have this separation of redo and undo. For those systems, the act of rolling back can be disastrous—the rollback process must read the logs their log writer is trying to write to. They introduce contention into the part of the system that can least stand it. Oracle’s goal is to make it so that redo logs are written sequentially, and no one ever reads them while they are being written.
Again, undo is generated as a result of the DELETE, blocks are modified, and redo is sent over to the redo log buffer. This is not very different from before. In fact, it is so similar to the UPDATE that we are going to move right on to the COMMIT.
We’ve looked at various failure scenarios and different paths, and now we’ve finally made it to the COMMIT. Here, Oracle will flush the redo log buffer to disk, and the picture will look like Figure 6-4.
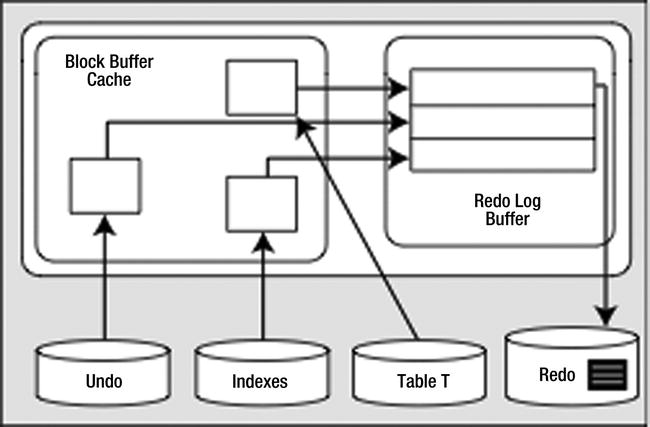
Figure 6-4. State of the system after a COMMIT
The modified blocks are in the buffer cache; maybe some of them have been flushed to disk. All of the redo necessary to replay this transaction is safely on disk and the changes are now permanent. If we were to read the data directly from the data files, we probably would see the blocks as they existed before the transaction took place, as DBWn most likely has not yet written them. That’s OK—the redo log files can be used to bring those blocks up to date in the event of a failure. The undo information will hang around until the undo segment wraps around and reuses those blocks. Oracle will use that undo to provide for consistent reads of the affected objects for any session that needs them.
Commit and Rollback Processing
It is important to understand how redo log files might impact us as developers. We will look at how the different ways we can write our code affect redo log utilization. We’ve already seen the mechanics of redo earlier in the chapter, and now we’ll look at some specific issues. You might detect many of these scenarios, but they would be fixed by the DBA as they affect the database instance as a whole. We’ll start with what happens during a COMMIT, and then get into commonly asked questions and issues surrounding the online redo logs.
What Does a COMMIT Do?
As a developer, you should have a good understanding of exactly what goes on during a COMMIT. In this section, we’ll investigate what happens during the processing of the COMMIT statement in Oracle. A COMMIT is generally a very fast operation, regardless of the transaction size. You might think that the bigger a transaction (in other words, the more data it affects), the longer a COMMIT would take. This is not true. The response time of a COMMIT is generally “flat,” regardless of the transaction size. This is because a COMMIT does not really have too much work to do, but what it does do is vital.
One of the reasons this is an important fact to understand and embrace is that it will lead to letting your transactions be as big as they should be. As we discussed in the previous chapter, many developers artificially constrain the size of their transactions, committing every so many rows, instead of committing when a logical unit of work has been performed. They do this in the mistaken belief that they are preserving scarce system resources, when in fact they are increasing them. If a COMMIT of one row takes X units of time, and the COMMIT of 1,000 rows takes the same X units of time, then performing work in a manner that does 1,000 one-row COMMITs will take an additional 1,000*X units of time to perform. By committing only when you have to (when the logical unit of work is complete), you will not only increase performance, you’ll also reduce contention for shared resources (log files, various internal latches, and the like). A simple example demonstrates that it necessarily takes longer. We’ll use a Java application, although you can expect similar results from most any client—except, in this case, PL/SQL (we’ll discuss why that is after the example). To start, here is the sample table we’ll be inserting into:
SCOTT@ORA12CR1> create table test
2 (id number,
3 code varchar2(20),
4 descr varchar2(20),
5 insert_user varchar2(30),
6 insert_date date
7 )
8 /
Table created.
Our Java program (stored in a file named perftest.java) will accept two inputs: the number of rows to INSERT (iters) and how many rows between commits (commitCnt). It starts by connecting to the database, setting autocommit off (which should be done in all Java code), and then calling a doInserts() method a total of two times:
- Once just to warm up the routine (make sure all of the classes are loaded)
- A second time, with SQL Tracing on, specifying the number of rows to INSERT along with how many rows to commit at a time (i.e., commit every N rows)
It then closes the connection and exits. The main method is as follows :
import java.sql.*;
public class perftest
{
public static void main (String arr[]) throws Exception
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection con = DriverManager.getConnection
("jdbc:oracle:thin:@csxdev:1521:ORA12CR1", "scott", "tiger");
Integer iters = new Integer(arr[0]);
Integer commitCnt = new Integer(arr[1]);
con.setAutoCommit(false);
doInserts(con, 1, 1 );
Statement stmt = con.createStatement ();
stmt.execute("begin dbms_monitor.session_trace_enable(waits=>true); end;" );
doInserts(con, iters.intValue(), commitCnt.intValue() );
con.close();
}
![]() Note The SCOTT account or whatever account you use to test this with will need to have the EXECUTE privilege granted on the DBMS_MONITOR package.
Note The SCOTT account or whatever account you use to test this with will need to have the EXECUTE privilege granted on the DBMS_MONITOR package.
Now, the method doInserts() is fairly straightforward. It starts by preparing (parsing) an INSERT statement so we can repeatedly bind/execute it over and over:
static void doInserts(Connection con, int count, int commitCount )
throws Exception
{
PreparedStatement ps =
con.prepareStatement
("insert into test " +
"(id, code, descr, insert_user, insert_date)"
+ " values (?,?,?, user, sysdate)");
It then loops over the number of rows to insert, binding and executing the INSERT over and over. Additionally, it checks a row counter to see if it needs to COMMIT or not inside the loop :
int rowcnt = 0;
int committed = 0;
for (int i = 0; i < count; i++ )
{
ps.setInt(1,i);
ps.setString(2,"PS - code" + i);
ps.setString(3,"PS - desc" + i);
ps.executeUpdate();
rowcnt++;
if ( rowcnt == commitCount )
{
con.commit();
rowcnt = 0;
committed++;
}
}
con.commit();
System.out.println
("pstatement rows/commitcnt = " + count + " / " + committed );
}
}
Now we’ll run this code repeatedly with different inputs and review the resulting TKPROF file. We’ll run with 100,000 row inserts—committing 1 row at a time, then 10, and so on. The resulting TKPROF files produced the results in Table 6-1.
Table 6-1. Results from Inserting 100,000 Rows
![]()
As you can see, the more often you commit, the longer you wait (your mileage will vary on this). And the amount of time you wait is more or less directly proportional to the number of times you commit. Remember, this is just a single-user scenario; with multiple users doing the same work, all committing too frequently, the numbers will go up rapidly.
We’ve heard the same story, time and time again, with similar situations. For example, we’ve seen how not using bind variables and performing hard parses often severely reduces concurrency due to library cache contention and excessive CPU utilization. Even when we switch to using bind variables, soft parsing too frequently—caused by closing cursors even though we are going to reuse them shortly— incurs massive overhead. We must perform operations only when we need to—a COMMIT is just another such operation. It is best to size our transactions based on business need, not based on misguided attempts to lessen resource usage on the database.
There are two factors contributing to the expense of the COMMIT in this example:
- We’ve obviously increased the round-trips to and from the database. If we commit every record, we are generating that much more traffic back and forth. I didn’t even measure that, which would add to the overall runtime.
- Every time we commit, we must wait for our redo to be written to disk. This will result in a “wait.” In this case, the wait is named “log file sync.”
So, we committed after every INSERT, we waited every time for a short period of time—and if you wait a little bit of time but you wait often, it all adds up. Fully thirty seconds of our runtime was spent waiting for a COMMIT to complete when we committed 100,000 times—in other words, waiting for LGWR to write the redo to disk. In stark contrast, when we committed once, we didn’t wait very long (not a measurable amount of time actually). This proves that a COMMIT is a fast operation; we expect the response time to be more or less flat, not a function of the amount of work we’ve done.
So, why is a COMMIT’s response time fairly flat, regardless of the transaction size? It is because before we even go to COMMIT in the database, we’ve already done the really hard work. We’ve already modified the data in the database, so we’ve already done 99.9 percent of the work. For example, operations such as the following have already taken place:
- Undo blocks have been generated in the SGA.
- Modified data blocks have been generated in the SGA.
- Buffered redo for the preceding two items has been generated in the SGA.
- Depending on the size of the preceding three items and the amount of time spent, some combination of the previous data may be flushed onto disk already.
- All locks have been acquired.
When we COMMIT, all that is left to happen is the following:
- A System Change Number (SCN) is generated for our transaction. In case you are not familiar with it, the SCN is a simple timing mechanism Oracle uses to guarantee the ordering of transactions and to enable recovery from failure. It is also used to guarantee read-consistency and checkpointing in the database. Think of the SCN as a ticker; every time someone COMMITs, the SCN is incremented by one.
- LGWR writes all of our remaining buffered redo log entries to disk and records the SCN in the online redo log files as well. This step is actually the COMMIT. If this step occurs, we have committed. Our transaction entry is “removed” from V$TRANSACTION—this shows that we have committed.
- All locks recorded in V$LOCK held by our session are released, and everyone who was enqueued waiting on locks we held will be woken up and allowed to proceed with their work.
- Some of the blocks our transaction modified will be visited and “cleaned out” in a fast mode if they are still in the buffer cache. Block cleanout refers to the lock-related information we store in the database block header. Basically, we are cleaning out our transaction information on the block, so the next person who visits the block won’t have to. We are doing this in a way that need not generate redo log information, saving considerable work later (this is discussed fully in the next chapter).
As you can see, there is very little to do to process a COMMIT. The lengthiest operation is, and always will be, the activity performed by LGWR, as this is physical disk I/O. The amount of time spent by LGWR here will be greatly reduced by the fact that it has already been flushing the contents of the redo log buffer on a recurring basis. LGWR will not buffer all of the work you do for as long as you do it. Rather, it will incrementally flush the contents of the redo log buffer in the background as you are going along. This is to avoid having a COMMIT wait for a very long time in order to flush all of your redo at once.
So, even if we have a long-running transaction, much of the buffered redo log it generates would have been flushed to disk, prior to committing. On the flip side is the fact that when we COMMIT, we must typically wait until all buffered redo that has not been written yet is safely on disk. That is, our call to LGWR is by default a synchronous one. While LGWR may use asynchronous I/O to write in parallel to our log files, our transaction will normally wait for LGWR to complete all writes and receive confirmation that the data exists on disk before returning.
![]() Note Oracle 11g Release 1 and above have an asynchronous wait. However, that style of commit has limited general-purpose use. Commits in any end-user-facing application should be synchronous.
Note Oracle 11g Release 1 and above have an asynchronous wait. However, that style of commit has limited general-purpose use. Commits in any end-user-facing application should be synchronous.
Now, earlier I mentioned that we were using a Java program and not PL/SQL for a reason—and that reason is a PL/SQL commit-time optimization. I said that our call to LGWR is by default a synchronous one and that we wait for it to complete its write. That is true in Oracle 12c Release 1 and before for every programmatic language except PL/SQL. The PL/SQL engine, realizing that the client does not know whether or not a COMMIT has happened in the PL/SQL routine until the PL/SQL routine is completed, does an asynchronous commit. It does not wait for LGWR to complete; rather, it returns from the COMMIT call immediately. However, when the PL/SQL routine is completed, when we return from the database to the client, the PL/SQL routine will wait for LGWR to complete any of the outstanding COMMITs. So, if you commit 100 times in PL/SQL and then return to the client, you will likely find you waited for LGWR once—not 100 times—due to this optimization. Does this imply that committing frequently in PL/SQL is a good or OK idea? No, not at all—just that it is not as bad an idea as it is in other languages. The guiding rule is to commit when your logical unit of work is complete—not before.
![]() Note This commit-time optimization in PL/SQL may be suspended when you are performing distributed transactions or Data Guard in maximum availability mode. Since there are two participants, PL/SQL must wait for the commit to actually be complete before continuing. Also, it can be suspended by directly invoking COMMIT WORK WRITE WAIT in PL/SQL with database version Oracle 11g Release 1 and above.
Note This commit-time optimization in PL/SQL may be suspended when you are performing distributed transactions or Data Guard in maximum availability mode. Since there are two participants, PL/SQL must wait for the commit to actually be complete before continuing. Also, it can be suspended by directly invoking COMMIT WORK WRITE WAIT in PL/SQL with database version Oracle 11g Release 1 and above.
To demonstrate that a COMMIT is a “flat response time” operation, we’ll generate varying amounts of redo and time the INSERTs and COMMITs. As we do these INSERTs and COMMITs, we’ll measure the amount of redo our session generates using this small utility function:
EODA@ORA12CR1> create or replace function get_stat_val(p_name in varchar2 ) return number
2 as
3 l_val number;
4 begin
5 select b.value
6 into l_val
7 from v$statname a, v$mystat b
8 where a.statistic# = b.statistic#
9 and a.name = p_name;
10
11 return l_val;
12 end;
13 /
Function created.
![]() Note The owner of the previous function will need to have been directly granted the SELECT privilege on the V$ views V_$STATNAME and V_$MYSTAT.
Note The owner of the previous function will need to have been directly granted the SELECT privilege on the V$ views V_$STATNAME and V_$MYSTAT.
Drop the table T (if it exists) and create an empty table T of the same structure as BIG_TABLE:
EODA@ORA12CR1> drop table t purge;
EODA@ORA12CR1> create table t
2 as
3 select *
4 from big_table
5 where 1=0;
Table created.
![]() Note Directions on how to create and populate the BIG_TABLE table used in many examples is in the “Setting Up Your Environment” section at the very front of this book.
Note Directions on how to create and populate the BIG_TABLE table used in many examples is in the “Setting Up Your Environment” section at the very front of this book.
And we’ll measure the CPU and Elapsed time used to commit our transaction using the DBMS_UTILITY package routines GET_CPU_TIME and GET_TIME. The actual PL/SQL block used to generate the workload and report on it is:
EODA@ORA12CR1> declare
2 l_redo number;
3 l_cpu number;
4 l_ela number;
5 begin
6 dbms_output.put_line
7 ('-' || ' Rows' || ' Redo' ||
8 ' CPU' || ' Elapsed' );
9 for i in 1 .. 6
10 loop
11 l_redo := get_stat_val('redo size' );
12 insert into t select * from big_table where rownum <= power(10,i);
13 l_cpu := dbms_utility.get_cpu_time;
14 l_ela := dbms_utility.get_time;
15 commit work write wait;
16 dbms_output.put_line
17 ('-' ||
18 to_char(power(10, i ), '9,999,999') ||
19 to_char((get_stat_val('redo size')-l_redo), '999,999,999' ) ||
20 to_char((dbms_utility.get_cpu_time-l_cpu), '999,999' ) ||
21 to_char((dbms_utility.get_time-l_ela), '999,999' ) );
22 end loop;
23 end;
24 /
- Rows Redo CPU Elapsed
- 10 7,072 0 1
- 100 10,248 0 0
- 1,000 114,080 0 0
- 10,000 1,146,484 0 2
- 100,000 11,368,512 0 2
- 1,000,000 113,800,488 1 2
PL/SQL procedure successfully completed.
* This test was performed on a single-user machine with a 1.7 MB log buffer and three 500MB online redo log files. Times are in hundredths of seconds.
As you can see, as we generate varying amount of redo from 7,072 bytes to 113MB, the difference in time to COMMIT is not measurable using a timer with a one hundredth of a second resolution. As we were processing and generating the redo log, LGWR was constantly flushing our buffered redo information to disk in the background. So, when we generated 113MB of redo log information, LGWR was busy flushing every 1MB, or so. When it came to the COMMIT, there wasn’t much left to do—not much more than when we created ten rows of data. You should expect to see similar (but not exactly the same) results, regardless of the amount of redo generated.
What Does a ROLLBACK Do?
By changing the COMMIT to ROLLBACK, we can expect a totally different result. The time to roll back is definitely a function of the amount of data modified. I changed the script developed in the previous section to perform a ROLLBACK instead (simply change the COMMIT to ROLLBACK) and the timings are very different. Look at the results now:
EODA@ORA12CR1> declare
2 l_redo number;
3 l_cpu number;
4 l_ela number;
5 begin
6 dbms_output.put_line
7 ('-' || ' Rows' || ' Redo' ||
8 ' CPU' || ' Elapsed' );
9 for i in 1 .. 6
10 loop
11 l_redo := get_stat_val('redo size' );
12 insert into t select * from big_table where rownum <= power(10,i);
13 l_cpu := dbms_utility.get_cpu_time;
14 l_ela := dbms_utility.get_time;
15 --commit work write wait;
16 rollback;
17 dbms_output.put_line
18 ('-' ||
19 to_char(power(10, i ), '9,999,999') ||
20 to_char((get_stat_val('redo size')-l_redo), '999,999,999' ) ||
21 to_char((dbms_utility.get_cpu_time-l_cpu), '999,999' ) ||
22 to_char((dbms_utility.get_time-l_ela), '999,999' ) );
23 end loop;
24 end;
25 /
- Rows Redo CPU Elapsed
- 10 7,180 0 0
- 100 10,872 0 0
- 1,000 121,880 0 0
- 10,000 1,224,864 0 0
- 100,000 12,148,416 2 4
- 1,000,000 121,733,580 25 36
PL/SQL procedure successfully completed.
This difference in CPU and Elapsed timings is to be expected, as a ROLLBACK has to undo the work we’ve done. Similar to a COMMIT, a series of operations must be performed. Before we even get to the ROLLBACK, the database has already done a lot of work. To recap, the following would have happened:
- Undo segment records have been generated in the SGA.
- Modified data blocks have been generated in the SGA.
- A buffered redo log for the preceding two items has been generated in the SGA.
- Depending on the size of the preceding three items and the amount of time spent, some combination of the previous data may be flushed onto disk already.
- All locks have been acquired.
When we ROLLBACK,
- We undo all of the changes made. This is accomplished by reading the data back from the undo segment and, in effect, reversing our operation and then marking the undo entry as applied. If we inserted a row, a ROLLBACK will delete it. If we updated a row, a rollback will reverse the update. If we deleted a row, a rollback will reinsert it again.
- All locks held by our session are released, and everyone who was enqueued waiting on locks we held will be released.
A COMMIT, on the other hand, just flushes any remaining data in the redo log buffers. It does very little work compared to a ROLLBACK. The point here is that you don’t want to roll back unless you have to. It is expensive since you spend a lot of time doing the work, and you’ll also spend a lot of time undoing the work. Don’t do work unless you’re sure you are going to want to COMMIT it. This sounds like common sense—of course I wouldn’t do all of the work unless I wanted to COMMIT it. However, I’ve often seen a developer use a “real” table as a temporary table, fill it up with data, report on it, and then roll back to get rid of the temporary data. Later we’ll talk about true temporary tables and how to avoid this issue.
Summary
In this chapter, we explored redo and undo and took a look at what they mean to the developer. The key point to take away from this chapter is the importance of redo and undo, and the fact that they are not overhead—they are integral components of the database and are necessary and mandatory. Once you have a good understanding of how they work and what they do, you’ll be able to make better use of them. Understanding that you are not “saving” anything by committing more frequently than you should (you are actually wasting resources, as it takes more CPU, more disk, and more programming) is probably the most important point of all. Be aware of what the database needs to do, and then let the database do it.