
![]()
Iterators
Iterators provide element-by-element access to a sequence of things. The things can be numbers, characters, or objects of almost any type. The standard containers, such as vector, provide iterator access to the container contents, and other standard iterators let you access input streams and output streams, for example. The standard algorithms require iterators for operating on sequences of things.
Until now, your view and use of iterators has been somewhat limited. Sure, you’ve used them, but do you really understand them? This Exploration helps you understand what’s really going on with iterators.
Kinds of Iterators
So far, you have seen that iterators come in multiple varieties, in particular, read and write. The copy function, for example, takes two read iterators to specify an input range and one write iterator to specify the start of an output range. As always, specify the input range as a pair of read iterators: one that refers to the first element of the range and one that refers to the one-past-the-end element of the input range. The copy function returns a write iterator: the value of the result iterator after the copy is complete.
WriteIterator copy(ReadIterator start, ReadIterator end, WriteIterator result);
All this time, however, I’ve oversimplified the situation by referring to “read” and “write” iterators. In fact, C++ has five different categories of iterators: input, output, forward, bidirectional, and random access. Input and output iterators have the least functionality, and random access has the most. You can substitute an iterator with more functionality anywhere that calls for an iterator with less. Figure 44-1 illustrates the substitutability of iterators. Don’t be misled by the figure, however. It does not show class inheritance. What makes an object an iterator is its behavior. If it fulfills all the requirements of an input iterator, for example, it is an input iterator, regardless of its type.
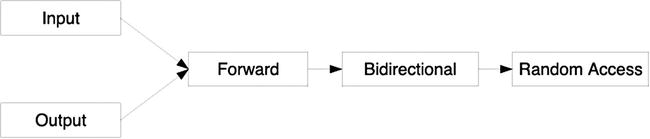
Figure 44-1. Substitution tree for iterators
All iterators can be copied and assigned freely. The result of a copy or an assignment is a new iterator that refers to the same item as the original iterator. The other characteristics depend on the iterator category, as described in the following sections.
An input iterator, unsurprisingly, supports only input. You can read from the iterator (using the unary * operator) only once per iteration. You cannot modify the item that the iterator refers to. The ++ operator advances to the next input item. You can compare iterators for equality and inequality, but the only meaningful comparison is to compare an iterator with an end iterator. You cannot, in general, compare two input iterators to see if they refer to the same item.
That’s about it. Input iterators are quite limited, but they are also extremely useful. Almost every standard algorithm expresses an input range in terms of two input iterators: the start of the input range and one past the end of the input range.
The istream_iterator type is an example of an input iterator. You can also treat any container’s iterator as an input iterator; e.g., the iterator that a vector’s begin() member function returns.
An output iterator supports only output. You can assign to an iterator item (by applying the * operator to the iterator on the left-hand side of an assignment), but you cannot read from the iterator. You can modify the iterator value only once per iteration. The ++ operator advances to the next output item.
You cannot compare output iterators for equality or inequality.
In spite of the limitations on output iterators, they, too, are widely used by the standard algorithms. Every algorithm that copies data to an output range takes an output iterator to specify the start of the range.
One caution when dealing with output iterators is that you must ensure that wherever the iterator is actually writing has enough room to store the entire output. Any mistakes result in undefined behavior. Some implementations offer debugging iterators that can check for this kind of mistake, and you should certainly take advantage of such tools when they are available. Don’t rely solely on debugging libraries, however. Careful code design, careful code implementation, and careful code review are absolutely necessary to ensure safety when using output (and other) iterators.
The ostream_iterator type is an example of an output iterator. You can also treat many container’s iterators as output iterators; e.g., the iterator that a vector’s begin() member function returns.
A forward iterator has all the functionality of an input iterator and an output iterator, and a little bit more. You can freely read from, and write to, an iterator item (still using the unary * operator), and you can do so as often as you wish. The ++ operator advances to the next item, and the == and != operators can compare iterators to see if they refer to the same item or to the end position.
Some algorithms require forward iterators instead of input iterators. I glossed over that detail in the previous Explorations, because it rarely affects you. For example, the binary search algorithms require forward iterators to specify the input range, because they might have to refer to a particular item more than once. That means you cannot directly use an istream_iterator as an argument to, say, lower_bound, but then you aren’t likely to try that in a real program. All the containers’ iterators meet the requirements of forward iterators, so in practical terms, this restriction has little impact.
A bidirectional iterator has all the functionality of a forward iterator, but it also supports the -- operator, which moves the iterator backward one position to the previous item. As with any iterator, you are responsible for ensuring that you never advance the iterator past the end of the range or before the beginning.
The reverse and reverse_copy algorithms (and a few others) require bidirectional iterators. Most of the containers’ iterators meet at least the requirements of bidirectional iterators, so you rarely have to worry about this restriction.
A random access iterator is the most powerful iterator. It has all the functionality of all other iterators, plus you can move the iterator an arbitrary amount by adding or subtracting an integer.
You can subtract two iterators (provided they refer to the same sequence of objects) to obtain the distance between them. Recall from Exploration 43 that the distance function returns the distance between two iterators. If you pass forward or bidirectional iterators to the function, it advances the starting iterator one step at a time, until it reaches the end iterator. Only then will it know the distance. If you pass random access iterators, it merely subtracts the two iterators and immediately returns the distance between them.
You can compare random access iterators for equality or inequality. If the two iterators refer to the same sequence of objects, you can also use any of the relational operators. For random access iterators, a < b means a refers to an item earlier in the sequence than b.
Algorithms such as sort require random access iterators. The vector type provides random access iterators, but not all containers do. The list container, for example, implements a doubly linked list. It has only bidirectional iterators. Because you can’t use the sort algorithm, the list container has its own sort member function. Learn more about list in Exploration 53.
Now that you know that vectors supply random access iterators, and you can compare random access iterators using relational operators, revisit Listing 10-4. Can you think of an easier way to write that program? (Hint: Consider a loop condition of start < end.) See my rewrite in Listing 44-1.
Listing 44-1. Comparing Iterators by Using the < Operator
#include <algorithm>
#include <iostream>
#include <iterator>
#include <vector>
int main()
{
std::vector<int> data{};
int x{};
while (std::cin >> x)
data.push_back(x);
for (auto start(data.begin()), end(data.end()); start < end; ++start)
{
--end; // now end points to a real position, possibly start
std::iter_swap(start, end); // swap contents of two iterators
}
std::copy(data.begin(), data.end(), std::ostream_iterator<int>(std::cout, " "));
}
So input, forward, bidirectional, and random access iterators all qualify as “read” iterators, and output, forward, bidirectional, and random access iterators all qualify as “write” iterators. An algorithm, such as copy, might require only input and output iterators. That is, the input range requires two input iterators. You can use any iterator that meets the requirements of an input iterator: input, forward, bidirectional, or random access. For the start of the output range, use any iterator that meets the requirements of an output iterator: output, forward, bidirectional, or random access.
The most common sources for iterators are the begin() and end() member functions that all containers (such as map and vector) provide. The begin() member function returns an iterator that refers to the first element of the container, and end() returns an iterator that refers to the position of the one-past-the-end element of the container.
What does begin() return for an empty container?
_____________________________________________________________
If the container is empty, begin() returns the same value as end(), that is, a special value that represents “past the end” and cannot be dereferenced. One way to test whether a container is empty is to test whether begin() == end(). (Even better, especially when you are writing a real program and not trying to illustrate the nature of iterators, is to call the empty() member function, which every container provides.)
The type of a container’s iterator is always named iterator. The name is a nested member, so you refer to the iterator name by prefixing it with the container type.
std::map<std::string, int>::iterator map_iter;
std::vector<int>::iterator vector_iter;
Each container implements its iterator differently. All that matters to you is that the iterator fulfills the requirements of one of the standard categories.
The exact category of iterator depends on the container. A vector returns random access iterators. A map returns bidirectional iterators. Any library reference will tell you exactly what category of iterator each container supports.
A number of algorithms and container member functions also return iterators. For example, almost every function that performs a search returns an iterator that refers to the desired item. If the function cannot find the item, it returns the end iterator. The type of the return value is usually the same as the type of the iterators in the input range. Algorithms that copy elements to an output range return the result iterator.
Once you have an iterator, you can dereference it with * to obtain the value that it refers to (except for an output iterator, which you dereference only to assign a new value, and the end iterators, which you can never dereference). If the iterator refers to an object, and you want to access a member of the object, you can use the shorthand -> notation.
std::vector<std::string> lines(2, "hello");
std::string first{*lines.begin()}; // dereference the first item
std::size_t size{lines.begin()->size()}; // dereference and call a member function
You can advance an iterator to a new position by calling the next or advance function (declared in <iterator>). The advance function modifies the iterator that you pass as the first argument. The next function takes the iterator by value and returns a new iterator value. The second argument is the integer distance to advance the iterator. The second argument is optional for next; default is one. If the iterator is random access, the function adds the distance to the iterator. Any other kind of iterator must apply its increment (++) operator multiple times to advance the desired distance. For example:
std::vector<int> data{ 1, 2, 3, 4, 5 };
std::vector<int>::iterator iter{ data.begin() };
assert(4 == *std::next(iter, 3));
For a vector, std::next() is just like addition, but for other containers, such as std::map, it applies the increment operator multiple times to reach the desired destination. If you have a reverse iterator, you can pass a negative distance or call std::prev(). If the iterator is bidirectional, the second argument can be negative to go backward. You can advance an input iterator but not an output iterator. Reusing the sequence functor from Exploration 42, read the program in Listing 44-2.
Listing 44-2. Advancing an Iterator
#include <algorithm>
#include <iostream>
#include <iterator>
#include <vector>
#include "data.hpp" // see Listing 43-2.
#include "sequence.hpp" // see Listing 42-6.
int main()
{
intvector data(10);
std::generate(data.begin(), data.end(), sequence{0, 2}); // fill with even numbers
intvec_iterator iter{data.begin()};
std::advance(iter, 4);
std::cout << *iter << ", ";
iter = std::prev(iter, 2);
std::cout << *iter << ' ';
}
What does the program print?_____________________________________________
The data vector is filled with even numbers, starting at 0. The iterator, iter, initially refers to the first element of the vector, namely, 0. The iterator advances four positions, to value 8, and then back two positions, to 4. So the output is
8, 4
Declaring variables to store iterators is clumsy. The type names are long and cumbersome. Therefore, I often use auto to define a variable. If I really need to name a type, say, because I have to write a function that takes an iterator parameter, I use typedef declarations to create shorter aliases for the long, clumsy type names, as follows:
typedef std::vector<std::string>::iterator strvec_iterator;
std::vector<std::string> lines(2, "hello");
strvec_iterator iter{lines.begin()};
std::string first{*iter}; // dereference the first item
std::size_t size{iter->size()}; // dereference and call a member function
const_iterator vs. const iterator
A minor source of confusion is the difference between a const_iterator and const iterator. An output iterator (and any iterator that also meets the requirements of an output iterator, namely, forward, bidirectional, and random access) lets you modify the item it references. For some forward iterators (and bidirectional and random access), you want to treat the data in the range as read-only. Even though the iterator itself meets the requirements of a forward iterator, your immediate need might be only for an input iterator.
You might think that declaring the iterator const would help. After all, that’s how you ask the compiler to help you, by preventing accidental modification of a variable: declare the variable with the const specifier. What do you think? Will it work? ________________
If you aren’t sure, try a test. Read Listing 44-3 and predict its output.
Listing 44-3. Printing the Middle Item of a Series of Integers
#include <iostream>
#include "data.hpp"
int main()
{
intvector data{};
read_data(data);
const intvec_iterator iter{data.begin()};
std::advance(iter, data.size() / 2); // move to middle of vector
if (not data.empty())
std::cout << "middle item = " << *iter << ' ';
}
Can you see why the compiler refuses to compile the program? Maybe you can’t see the precise reason, buried in the compiler’s error output. (The next section will discuss this problem at greater length.) The error is that the variable iter is const. You cannot modify the iterator, so you cannot advance it to the middle of the vector.
Instead of declaring the iterator itself as const, you have to tell the compiler that you want the iterator to refer to const data. If the vector itself were const, the begin() function would return exactly such an iterator. You could freely modify the iterator’s position, but you could not modify the value that the iterator references. The name of the iterator that this function returns is const_iterator (with underscore).
In other words, every container actually has two different begin() functions. One is a const member function and returns const_iterator. The other is not a const member function; it returns a plain iterator. As with any const or non-const member function, the compiler chooses one or the other, depending on whether the container itself is const. If the container is not const, you get the non-const version of begin(), which returns a plain iterator, and you can modify the container contents through the iterator. If the container is const, you get the const version of begin(), which returns a const_iterator, which prevents you from modifying the container’s contents. You can also force the issue by calling cbegin(), which always returns const_iterator, even for a non-const object.
Rewrite Listing 44-3 to use a const_iterator. Your program should look something like Listing 44-4.
Listing 44-4. Really Printing the Middle Item of a Series of Integers
#include <iostream>
#include "data.hpp"
int main()
{
intvector data{};
read_data(data);
intvector::const_iterator iter{data.begin()};
std::advance(iter, data.size() / 2); // move to middle of vector
if (not data.empty())
std::cout << "middle item = " << *iter << ' ';
}
Prove to yourself that you cannot modify the data when you have a const_iterator. Make a further modification to your program to negate the middle value. Now your program should look like Listing 44-5.
Listing 44-5. Negating the Middle Value in a Series of Integers
#include <iostream>
#include "data.hpp"
int main()
{
intvector data{};
read_data(data);
intvector::const_iterator iter{data.begin()};
std::advance(iter, data.size() / 2); // move to middle of vector
if (not data.empty())
*iter = -*iter;
write_data(data);
}
If you change const_iterator to iterator, the program works. Do it.
When you compiled Listing 44-3, the compiler issued an error message, or diagnostic, as the C++ standard writers call it. For example, the compiler that I use every day, g++, prints the following:
In file included from /usr/include/c++/4.8/bits/stl_algobase.h:66:0,
from /usr/include/c++/4.8/bits/char_traits.h:39,
from /usr/include/c++/4.8/ios:40,
from /usr/include/c++/4.8/ostream:38,
from /usr/include/c++/4.8/iostream:39,
from list4403.cpp:1:
/usr/include/c++/4.8/bits/stl_iterator_base_funcs.h: In instantiation of 'void
std::__advance(_RandomAccessIterator&, _Distance, std::random_access_iterator_tag) [with
_RandomAccessIterator = const __gnu_cxx::__normal_iterator<int*, std::vector<int> >; _Distance = long int]':
/usr/include/c++/4.8/bits/stl_iterator_base_funcs.h:177:61: required from 'void
std::advance(_InputIterator&, _Distance) [with _InputIterator = const __gnu_cxx::__normal_iterator<int*,
std::vector<int> >; _Distance = long unsigned int]'
list4403.cpp:9:37: required from here
/usr/include/c++/4.8/bits/stl_iterator_base_funcs.h:156:11: error: no match for 'operator+=' (operand
types are 'const __gnu_cxx::__normal_iterator<int*, std::vector<int> >' and 'long int')
__i += __n;
^
/usr/include/c++/4.8/bits/stl_iterator_base_funcs.h:156:11: note: candidate is:
In file included from /usr/include/c++/4.8/bits/stl_algobase.h:67:0,
from /usr/include/c++/4.8/bits/char_traits.h:39,
from /usr/include/c++/4.8/ios:40,
from /usr/include/c++/4.8/ostream:38,
from /usr/include/c++/4.8/iostream:39,
from list4403.cpp:2:
/usr/include/c++/4.8/bits/stl_iterator.h:774:7: note: __gnu_cxx::__normal_iterator<_Iterator, _Container>&
__gnu_cxx::__normal_iterator<_Iterator, _Container>::operator+=(const difference_type&) [with _Iterator
= int*; _Container = std::vector<int>; __gnu_cxx::__normal_iterator<_Iterator,
_Container>::difference_type = long int] <near match>
operator+=(const difference_type& __n)
^
/usr/include/c++/4.8/bits/stl_iterator.h:774:7: note: no known conversion for implicit 'this' parameter from
'const __gnu_cxx::__normal_iterator<int*, std::vector<int> >*' to '__gnu_cxx::__normal_iterator<int*,
std::vector<int> >*'
So what does all that gobbledygook mean? Although a C++ expert can figure it out, it may not be much help to you. Buried in the middle is the line number and source file that identify the source of the error. That’s where you have to start looking. The compiler didn’t detect the error until it started working through various #include files. These file names depend on the implementation of the standard library, so you can’t always tell from those file names what is the actual error.
In this case, the error arises from within the std::advance function. That’s when the compiler detects that it has a const iterator, but it does not have any functions that work with a const iterator. Instead of complaining about the const-ness, however, all it manages to do is to complain that it lacks a “match” for the function it seeks. That means it is looking for argument types that match the parameter types, to resolve an overloaded operator. Because a const argument cannot match a non-const parameter, the compiler failed to find an overload that matches the arguments.
Don’t give up hope for ever understanding C++ compiler error messages. By the end of the book, you will have gained quite a bit more knowledge that will help you understand how the compiler and library really work, and that understanding will help you make sense of these error messages. If you can, compile your code with clang++, which does a good job of issuing helpful messages. Even if your production code must be compiled with a different compiler, you can use clang++ to help diagnose problems.
My advice for dealing with the deluge of confusing error messages is to start by finding the first mention of your source file. That should tell you the line number that gives rise to the problem. Check the source file. You might see an obvious mistake. If not, check the error message text. Ignore the “instantiated from here” and similar messages. Try to find the real error message, which often starts with error: instead of warning: or note:.
The <iterator> header defines a number of useful, specialized iterators, such as back_inserter, which you’ve seen several times already. Strictly speaking, back_inserter is a function that returns an iterator, but you rarely have to know the exact iterator type.
In addition to back_inserter, you can also use front_inserter, which also takes a container as an argument and returns an output iterator. Every time you assign a value to the dereferenced iterator, it calls the container’s push_front member function to insert the value at the start of the container.
The inserter function takes a container and an iterator as arguments. It returns an output iterator that calls the container’s insert function. The insert member function requires an iterator argument, specifying the position at which to insert the value. The inserter iterator initially passes its second argument as the insertion position. After each insertion, it updates its internal iterator, so subsequent insertions go into subsequent positions. In other words, inserter just does the right thing.
Other specialized iterators include istream_iterator and ostream_iterator, which you’ve also seen. An istream_iteratoris an input iterator that extracts values from a stream when you dereference the iterator. With no arguments, the istream_iterator constructor creates an end-of-stream iterator. An iterator is equal to the end-of-stream iterator when an input operation fails.
An ostream_iteratoris an output iterator. The constructor takes an output stream and an optional string as arguments. Assigning to the dereferenced iterator writes a value to the output stream, optionally followed by the string (from the constructor).
Another specialized iterator is thereverse_iterator class. It adapts an existing iterator (called the base iterator), which must be bidirectional (or random access). When the reverse iterator goes forward (++), the base iterator goes backward (--). Containers that support bidirectional iterators have rbegin() and rend() member functions, which return reverse iterators. The rbegin() function returns a reverse iterator that points to the last element of the container, and rend() returns a special reverse iterator value that represents one position before the beginning of the container. Thus, you treat the range [rbegin(), rend()] as a normal iterator range, expressing the values of the container in reverse order.
C++ doesn’t permit an iterator to point to one position before the beginning, so reverse iterators have a somewhat funky implementation. Ordinarily, implementation details don’t matter, but reverse_iterator exposes this particular detail in its base() member function, which returns the base iterator.
I could tell you what the base iterator actually is, but that would deprive you of the fun. Write a program to reveal the nature of the reverse_iterator’s base iterator. (Hint: Fill a vector with a sequence of integers. Use a reverse iterator to get to the middle value. Compare with the value of the iterator’s base() iterator.)
If a reverse_iterator points to position x of a container, what does its base() iterator point to?
_____________________________________________________________
If you did not answer x + 1, try running the program in Listing 44-6.
Listing 44-6. Revealing the Implementation of reverse_iterator
#include <algorithm>
#include <cassert>
#include <iostream>
#include "data.hpp"
#include "sequence.hpp"
int main()
{
intvector data(10);
std::generate(data.begin(), data.end(), sequence(1));
write_data(data); // prints { 1 2 3 4 5 6 7 8 9 10 }
intvector::iterator iter{data.begin()};
iter = iter + 5; // iter is random access
std::cout << *iter << ' '; // prints 5
intvector::reverse_iterator rev{data.rbegin()};
std::cout << *rev << ' '; // prints 10
rev = rev + 4; // rev is also random access
std::cout << *rev << ' '; // prints 6
std::cout << *rev.base() << ' '; // prints 7
std::cout << *data.rend().base() << ' '; // prints 0
assert(data.rbegin().base() == data.end());
assert(data.rend().base() == data.begin());
}
Now do you see? The base iterator always points to one position after the reverse iterator’s position. That’s the trick that allows rend() to point to a position “before the beginning,” even though that’s not allowed. Under the hood, the rend() iterator actually has a base iterator that points at the first item in the container, and the reverse_iterator’s implementation of the * operator performs the magic of taking the base iterator, retreating one position, and then dereferencing the base iterator.
As you can see, iterators are a little more complicated than they initially seem to be. Once you understand how they work, however, you will see that they are actually quite simple, powerful, and easy-to-use. But first, it’s time to pick up a few more important C++ programming techniques. The next Exploration introduces exceptions and exception-handling, necessary topics for properly handling programmer and user errors.