
Chapter 7
Designing for Security and Legal Compliance
Identity and Access Management and Related Access Control Services
The Identity and Access Management (IAM) service is designed to allow you to specify what operations specific users can perform on particular resources. This is also described as specifying “who gets to do what on which resources.” IAM is the recommended way to control access in most cases. In some limited cases, such as in a development environment, the older basic roles system may be used. More on that to follow.
The first step to understanding IAM is to understand the abstractions used. The primary elements of IAM are as follows:
- Identities and groups
- Resources
- Permissions
- Roles
- Policies
It is essential to have a solid grasp of these concepts to function as a Google Cloud architect.
Identities and Groups
Identities and groups are entities that are used to grant access permissions to users.
Identities
An identity is an entity that represents a person or other agent that performs actions on a GCP resource. Identities are sometimes called members. There are several kinds of identities:
- Google account
- Service account
- Cloud Identity domain
Google accounts are used by people and represent people who interact with GCP, such as developers and administrators. These accounts are designated by an email address that is linked to a Google account. For example, [email protected] could be an identity in GCP. The domain of the email does not have to be gmail.com; it just has to be associated with a Google account.
Service accounts are used by applications running in GCP. These are used to give applications their own set of access controls instead of relying on using a person's account for permissions. Service accounts are also designated by email addresses. You can create multiple service accounts for an application, each with its own set of access control capabilities. When you create a service account, you specify a name of the account, such as gcp-arch-exam. IAM will then create an associated email such as [email protected], where gcp-certs-1 is the project ID of the project hosting the service account. Note that not all service accounts follow this pattern. When App Engine creates a service account, it uses the appspot.gserviceaccount.com domain.
Cloud Identity is an (IDaaS) offering. Users who do not have Google accounts or G Suite accounts can use the Cloud Identity service to create an identity. It will not be linked to a Google account, but it will create an identity that can be used when assigning roles and permissions.
Cloud Identity can be configured to delegate authentication to other identity providers that use OIDC or SAML. This is convenient when the primary source of truth about an application is an enterprise identity provider.
Groups
Related to identities are Google Groups, which are sets of Google accounts and service accounts. Groups have an associated email address. Groups are useful for assigning permissions to sets of users. When a user is added to a group, that user acquires the permissions granted to the group. Similarly, when a user is removed from the group, they no longer receive permissions from the group. Google Groups do not have login credentials, and therefore they cannot be used as an identity.
G Suite domains are another way to group identities. A G Suite domain is one that is linked to a G Suite account; that is, a G Suite account consists of users of a Google service account that bundles mail, Docs, Sheets, and so on for businesses and organizations. All users in the G Suite account are members of the associated group. Like Google Groups, G Suite domains can be used for specifying sets of users, but they are not identities.
Resources
Resources are entities that exist in the Google Cloud platform and can be accessed by users. Resources is a broad category that essentially includes anything that you can create in GCP. Resources include the following:
- Projects
- Virtual machines
- App Engine applications
- Cloud Storage buckets
- Pub/Sub topics
Google has defined a set of permissions associated with each kind of resource. Permissions vary according to the functionality of the resource.
Permissions
A permission is a grant to perform some action on a resource. Permissions vary by the type of resource with which they are associated. Storage resources will have permissions related to creating, listing, and deleting data. For example, a user with the bigquery.tables.create permission can create tables in BigQuery. Cloud Pub/Sub has a permission called pubsub.subscriptions.consume, which allows users to read from the Cloud Pub/Sub topic it is associated with.
Here are some examples of other permissions used by Compute Engine:
compute.instances.getcompute.networks.usecompute.securityPolicies.list
Here are some permissions used with Cloud Storage:
resourcemanager.projects.getresourcemanager.projects.liststorage.objects.create
For the purpose of the exam, it is not necessary to know specific permissions. However, it is important to know that the permissions in IAM are fine-grained; that is, they grant permissions to do limited operations. Usually, for each Google Cloud API endpoint, there is a permission associated with it. There are API endpoints for almost every kind of action that you can take in GCP so that there is basically a one-to-one relationship between the things that you can do and the permissions to do them.
One of the reasons why it is not required to know specific permissions in detail is that GCP administrators do not have to work with them very often. Instead, they work with roles, which are collections of permissions.
Roles
Roles are sets of permissions. One of the most important things to remember about IAM is that administrators grant roles, not permissions, to identities. You cannot grant a permission directly to a user—you must grant it by assigning a role to an identity.
Roles can be granted to identities. An identity can have multiple roles. Roles are granted for projects, folders, or organizations, and they apply to all resources under those. In other words, resources in those projects, folders, or organizations assume those roles when the role applies to the type of resource. For example, roles granted to a project that grants permissions to Compute Engine instances are applied to VM instances in that project.
There are three types of roles.
- Predefined
- Basic
- Custom
Predefined Roles
Predefined roles are created and managed by GCP. The roles are organized around groups of tasks commonly performed when working with IT systems, such as administering a server, querying a database, or saving a file to a storage system. Roles have names such as the following:
roles/bigquery.adminroles/bigquery.dataEditorroles/cloudfunction.developerroles/cloudsql.viewer
The naming convention is to use the prefix roles/ followed by the name of the service and a name associated with a person's organizational responsibilities.
For the purpose of the exam, it is important to understand how predefined roles are structured and named. There may be questions about what role is needed to perform a task, but you will likely be able to choose the correct answer based on the service name and the function performed. Some function names are used repeatedly in predefined roles, such as viewer, admin, and editor.
Basic Roles
GCP did not always have the IAM service. Before IAM was released, permissions were grouped into a set of three roles that are now called basic roles, and previously these were known as primitive roles.
- Viewer
- Editor
- Owner
The Viewer role grants a user read-only permission to a resource. A user with a Viewer role can see but not change the state of a resource.
The Editor role has all the capabilities of the Viewer role and can also modify the state of the resource. For example, users with the Editor role on a storage system can write data to that system.
The Owner role includes the capabilities of the Editor role and can also manage roles and permissions for the resource to which it is assigned. For example, if the owner role is granted on a project to a user, then that user can manage roles and permissions for all resources in the project. The Owner role can also be assigned to specific resources, such as a Compute Engine instance or a Cloud Pub/Sub topic. In those cases, the permissions apply only to that specific resource.
Users with the Owner role can also set up billing if the resources are being billed to the billing account associated with the resources' parent organization. It is possible, however, to have resources that are billed to a different account. This happens when a large enterprise has multiple GCP organizations but wants all resources to be billed to a single billing account. In these cases, it is necessary to have explicit permissions associated with the billing account to do anything with it.
As a general rule, you should favor the use of predefined roles over basic roles except in cases where resources are used by a small, trusted group of individuals. A DevOps team working in a development environment is an example of a use case for using basic roles. Using basic roles can reduce the administrative overhead of managing access controls.
Custom Roles
When the predefined roles do not fit a particular set of needs, users of GCP can set up their own roles. These are known as custom roles. With custom roles, administrators can specify a particular set of permissions. This is useful when you want to ensure that a user has the fewest permissions possible and is still able to perform tasks associated with their role. This is an example of following the principle of least privilege. It is considered a security best practice.
In highly secure production environments, developers may be able to view code (Get) in production but not change it (Set). If developers are deploying code that makes use of Cloud Functions, they could be granted the role roles/cloudfunctions.developer. This role includes several permissions, including cloudfunctions.functions.sourceCodeGet and cloudfunctions.functions.sourceCodeSet. The cloudfunctions.functions.sourceCodeGet permission is not a problem, but the developer should not have the cloudfunctions.functions.sourceCodeSet permission. In a case like this, you should create a custom role that has all of the permissions of roles/cloudfunctions.developer except cloudfunctions.functions.sourceCodeSet.
Policies
In addition to granting roles to identities, you can associate a set of roles and permissions with resources by using policies. A policy is a set of statements that define a combination of users and the roles. This combination of users (or members as they are sometimes called) and a role is called a binding. Policies are specified using JSON.
In the following example from Google's IAM documentation, the role roles/storage_objectAdmin is assigned to four identities, and the roles/storage_objectViewer is assigned to one identity—a user with the email [email protected]:
{"bindings": [{"role": "roles/storage.objectAdmin","members": ["user:[email protected]","serviceAccount:[email protected]","group:[email protected]","domain:google.com" ]},{"role": "roles/storage.objectViewer","members": ["user:[email protected]"]}]}Source: cloud.google.com/iam/docs/overview
Policies can be managed using the Cloud IAM API, which provides three functions.
setIamPolicyfor setting policies on resourcesgetIamPolicyfor reading policies on resourcestestIamPermissionsfor testing whether an identity has a permission on a resource
Policies can be set anywhere in the resource hierarchy, such as at the organization, folder, or project level (see Figure 7.1). They can also be set on individual resources. Policies set at the project level are inherited by all resources in the project including projects under it in the hierarchy, while policies set at the organization level are inherited by all resources in all folders and projects in the organization. If the resource hierarchy is changed, permissions granted by policies change accordingly.
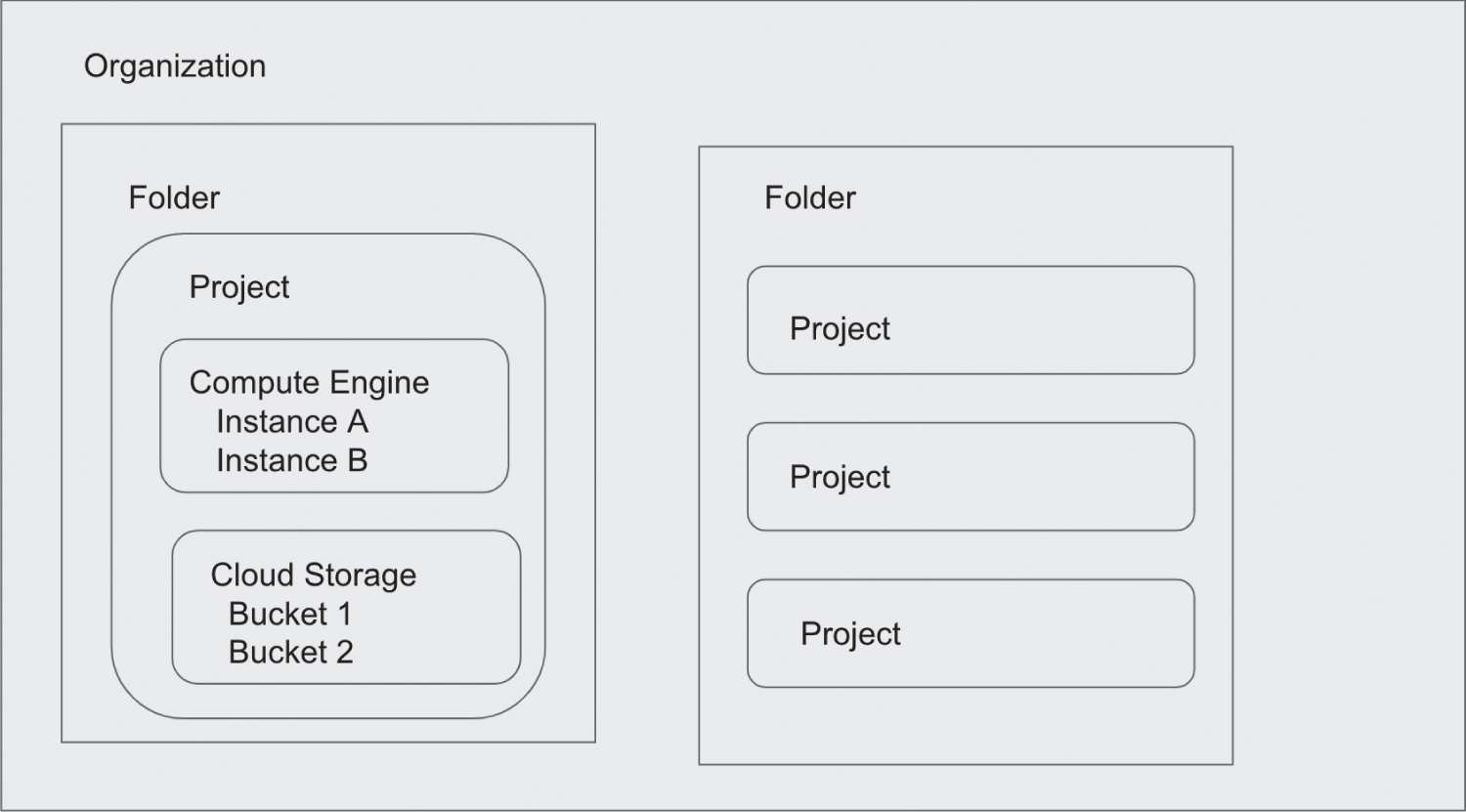
FIGURE 7.1 Google Cloud Platform resource hierarchy
Cloud IAM Conditions
Cloud IAM Conditions is a feature of IAM that allows you to specify and enforce conditional access controls based on the attributes of a resource. This allows you to grant access to an identity when specified conditions are met. Conditions are defined in resources role bindings.
Conditions are expressed using the Common Expression Language (CEL), which is designed for specifying attribute-based logic expressions. CEL includes variables, operators, and functions and can reference resource attributes as well as attributes of the requestor. Resource attributes include the type of a resource, the resource's name, and tags attached to the resource. Request attributes include the access level, the date and time, and the destination IP address and port.
The GCP services that have resource types that support conditional role bindings are Bigtable, Cloud KMS, Cloud SQL, Cloud Storage, Compute Engine, Identity-Aware Proxy, Resource Manager, and Secret Manager. IAM Conditions are available only for Cloud Storage buckets that use uniform bucket-level access.
IAM Best Practices
Google recommends several best practices for using IAM securely. For more details, see cloud.google.com/iam/docs/using-iam-securely.
Favor predefined roles over basic roles. Predefined roles are designed to provide all of the permissions needed for a user or service account to carry out a particular set of tasks. Use basic roles only for small teams that do not need granular permissions or in development and test environments where having broad groups of permissions can facilitate the use of the environment without introducing too much risk. When using predefined roles, assign the most restricted set of roles needed to do a job. For example, if a user only needs to list Cloud Pub/Sub topics, then grant pubsub.topics.list only.
Think in terms of trust boundaries, which set the scope of where roles and permissions should apply. For example, if you have three services in an application, consider having three trust boundaries—one for each service. You could use a different service account for each service and assign it just the roles it needs. For example, if only one of the services writes to Cloud Storage, then only that service should have permissions to write to Cloud Storage. If either of the other services is compromised, it will not have permission to write to Cloud Storage and thus limit the amount of damage that can be done.
Review where policies are set in the resource hierarchy. Folders inherit from the organization, and projects inherit from the organization and their containing folders. Policies assigned to a child entity cannot affect its parent entity.
Restrict access to roles that allow a user to administer IAM roles and policies. The Project IAM Admin and Folder IAM Admin roles allow a user to modify policies but do not grant the permissions needed to read, write, or otherwise administer resources. The effective policy for a resource is the union of the policy set at that resource and the policy inherited from its parent.
When you have to assign multiple roles to enable users to perform a task, grant those roles to a group and then add users to the group. This way, if you need to modify the set of roles needed to perform the task, you will only have to change the group and not each individual user.
Review the Cloud Audit Logs messages for changes to IAM policies. Also, limit access to audit logs using logging roles, such as roles/logging.viewer and roles/logging.privateLogViewer. Restrict access to roles/logging.admin, which gives all permissions related to logging.
IAM gives cloud administrators tools to craft sets of permissions granted to users and service accounts precisely. Another way of ensuring the confidentiality, integrity, and availability of cloud applications is with sound data security practices.
Identity-Aware Proxy
Identity-Aware Proxy (IAP) is an application layer (layer 7)–based access control for applications accessed using HTTPS. IAP allows you to define access control policies for applications and resources.
Applications that use IAP provide access to users who have proper IAM roles. When IAP is enabled, an IAP authentication server receives information about the protected resource, the request URL, and any IAP credentials in the request. IAP checks browser credentials, and if they do not exist, the user is redirected to sign in using OAuth 2.0 Google Account authentication. The IAP server verifies the user is authorized to access the resource.
It is important to note that when using IAP, you will need to implement network controls to prevent traffic that does not come from the IAP serving infrastructure.
IAP for On-Premises Apps allows you to use IAP to protect applications that run outside of GCP.
Workload Identity Federation
Workload Identity Federation allows you to use IAM to grant external identities IAM roles. Workload identities are organized into workload identity pools. Google recommends creating separate workload pools for each external environment that needs access to your GCP resources.
Workload Identity Federation depends on workload identity providers that manage the external identities. A range of identity providers are supported, including AWS, Azure Active Directory, on-premises Active Directory, Okta, and Kubernetes clusters.
Identity federation is implemented using SAML or OAuth 2.0 token exchange. The credentials associated with an identity include attributes that are mapped to equivalent attributes in a Google Cloud token. Attribute conditions defined using CEL are supported as well.
Workload Identity Federation allows for service account impersonation. To allow for this, you would grant roles/iam.workloadIdentityUser on the service account with the roles needed to execute the target workload.
Organization Constraints
In addition to IAM access controls, we can limit what GCP users and service accounts can do by using organization policy constraints. A constraint is a rule that is applied to prevent some action or configuration choice from being made. This is useful when you want to implement policies across an organization. For example, if you want to prevent serial port access to a VM in Compute Engine, you can specify the constraints/compute.disableSerialPortAccess constraint.
Some constraints apply to multiple Google Cloud services, and some apply to specific services. The multiservice constraints include Resource Location Restriction, which defines a set of locations where location-based resources can be created, and Restrict Allowed Google Cloud APIs and services, which limit the set of APIs that can be enabled.
There is a range of service-specific constraints. The full list is available at cloud.google.com/resource-manager/docs/organization-policy/org-policy-constraints. Here are some examples:
- App Engine Disable Source Code Download, to prevent download of code previously uploaded to App Engine
- Cloud Run Allowed Binary Authorization Policies, which defines the set of Binary Authorization policy names that are allowed to be specified on a Cloud Run resource
- Cloud SQL Restrict Public IP Access on Cloud SQL Instances, to restrict the use of IP addresses on Cloud SQL instances
- Cloud Storage Enforce Public Access Prevention, to prevent public exposure of data by not allowing public access to Cloud Storage data
- Compute Engine Shielded VMS, which requires all new Compute Engine VMs to use Shielded disk images
- IAM Disable Cross-Project Service Account Usage, to prevent service accounts from being used in projects other than the one they were created in
Organization constraints provide a convenient way to implement policies across organization resources.
Data Security
GCP provides multiple mechanisms for securing data in addition to IAM policies, which control access to data. Two essential services are encryption and key management. Also, there are a number of ways to protect access to data in Cloud Storage, which are outlined here.
Encryption
Encryption is the process of encoding data in a way that yields a coded version of data that cannot be practically converted back to the original form without additional information such as a key. We typically distinguish between encryption at rest and encryption in transit.
Encryption at Rest
Google encrypts data at rest by default. You do not have to configure any policy to enable this feature. This applies to all Google data storage services, such as Cloud Storage, Cloud SQL, and Cloud Bigtable. Encryption at rest actually occurs at multiple levels.
- At the platform level, database and file data is protected using AES256 and AES128 encryption.
- At the infrastructure level, data is grouped into data chunks in the storage system, and each chunk is encrypted using AES256 encryption.
- At the hardware level, storage devices apply AES256 in almost all cases, but as of July 2020, a small number of older persistent disks use AES128 encryption.
At the platform level, distributed filesystems and databases encrypt data. The granularity of encryption can vary across services. For example, Cloud SQL encrypts all data in a database instance with the same key, while Cloud Spanner, Bigtable, and Cloud Firestore encrypt data using the infrastructure encryption mechanism.
When Google Cloud stores data in the storage system, it stores it in subfile chunks that can be up to several gigabytes in size. Each chunk is encrypted with its own key, known as a data encryption key (DEK). If a chunk is updated, a new key is used. Keys are not used for more than one chunk. Also, each chunk has a unique identifier that is referenced by access control lists (ACLs) to limit access to the chunks, which are stored in different locations to make it even more difficult for a malicious actor to piece them together.
In addition to encrypting data that is in chunks, Google also encrypts the data encryption keys using a second key. This is known as envelope encryption. The key used to encrypt a DEK is known as a key encryption key (KEK).
In addition to the chunk-level encryption that occurs at the infrastructure level, when blocks of data are written to persistent storage, the storage device encrypts those blocks using either AES128 or AES256. Older devices use AES128, but new storage devices use AES256.
To summarize encryption at rest:
- Data at rest is encrypted by default in Google Cloud Platform.
- Data is encrypted at multiple levels, including the application, infrastructure, and device levels.
- Data is encrypted in chunks. Each chunk has its own encryption key, which is called a data encryption key.
- Data encryption keys are themselves encrypted using a key encryption key.
Google Cloud manages much of the encryption process, including managing keys. This is helpful for users who want Google Cloud to manage all aspects of encryption. In cases where organizations need to manage their own keys, they will have to use one of two key management methods, described in the “Key Management” section.
Before delving into key management, let's look at encryption in transit.
Encryption in Transit
Encryption in transit, also called encryption in motion, is used to protect the confidentiality and integrity of data in the event that the data is intercepted in transit. GCP uses a combination of authenticating sources and encryption to protect data in transit.
Google distinguishes data in transit on the Google network and data in transit on the public internet. Data within the boundaries of the Google network is authenticated but may not be encrypted. Data outside the physical boundaries of the Google network is encrypted.
Users of applications running in Google Cloud communicate with the application over the internet. Traffic incoming from users to the Google Cloud is routed to the Google Front End, a globally distributed proxy service. The Google Front End terminates HTTP and HTTPS traffic and routes it over the Google network to servers running the application. The Google Front End provides other security services, such as protecting against distributed denial-of-service (DDoS) attacks. Google Front End also implements global load balancers.
All traffic to Google Cloud services is encrypted by default. Google Cloud and the client negotiate how to encrypt data using either Transport Layer Security (TLS) or the Google-developed protocol QUIC (in the past, this term stood for Quick UDP Internet Connections, but now the name of the protocol is simply QUIC).
Within the Google Cloud infrastructure, Google uses Application Layer Transport Security (ALTS) for authentication and encryption. This is done at layer 7 of the OSI network model.
GCP offers encryption at rest and encryption in transit by default. Cloud users do not have to do anything to ensure that encryption is applied to their data. Users of GCP services can, however, determine how encryption keys are managed.
Key Management
There are many data encryption and key encryption keys in use at any time in the Google Cloud.
Default Encryption
Google manages these keys by default for users. When using default encryption, customers have no access to keys or control over how keys are rotated. DEKs are stored near the data chunks that they encrypt. There is a separate DEK for each data chunk, but one KEK can be used to encrypt multiple DEKs. The KEKs are stored in a centralized key management service.
The DEKs are generated by the storage service that is storing the data chunk using a common cryptographic library. The DEKs are then sent to the centralized key management service, where they are themselves encrypted using the storage system's KEK. When the storage system needs to retrieve data, it sends the DEK to the key management service, where the calling service is authenticated, and the DEK is decrypted and sent back to the storage system.
Cloud KMS Key Management
Cloud KMS is a hosted key management service in Google Cloud. It enables customers to generate and store keys in GCP. It is used when customers want control over key management but do not need keys to reside on their own key management infrastructure.
Cloud KMS supports a variety of cryptographic keys, including AES256, RSA 2048, RSA 3072, RSA 4096, EC P256, and EC P384. It also provides functionality for automatically rotating keys and encrypting DEKs with KEKs. Cloud KMS keys can be destroyed, but there is a 24-hour delay before the key is destroyed in case someone accidentally deletes a key or in the event of a malicious act.
Cloud KMS keys can be used for application-level encryption in GCP services, including Compute Engine, BigQuery, Cloud Storage, and Cloud Dataproc.
Cloud KMS allows users to import keys that are managed outside of Google.
Cloud HSM
Cloud HSM provides support for using keys only on FIPS 140-2 level 3 hardware security modules (HSMs). FIPS 140-2 is a U.S. government security standard for cryptographic modules. Level 3 requires tamper-evident physical security as well as protections to respond to attempts to tamper.
Customer-Supplied Keys
Another alternative for key management is customer-supplied keys. Customer-supplied keys are used when an organization needs complete control over key management, including storage.
In this model, keys are generated and kept on-premises and used by GCP services to encrypt the customer's data. These keys are passed with other arguments to API function calls. When the keys are sent to GCP, they are stored in memory while being used. Customer-supplied keys are not written to persistent storage.
Encryption and key management are essential components of a comprehensive security regime. Data at rest and in transit are encrypted by default. Keys are managed by default by GCP but can be managed by cloud users. Cloud KMS is a hosted managed key service that generates and stores keys in the cloud on behalf of a user. Customer-supplied keys are managed on-premises and sent to Google as part of API calls. Customer-supplied keys allow customers the greatest amount of control but also require infrastructure and management procedures that are not needed when using default encryption.
Customer-Managed Encryption Keys
Customer-managed encryption keys (CMEKs) are keys that are managed by customers of Google Cloud using Cloud KMS. When using CMEKs, customers have more control over the key lifecycle. Customers using CMEKs can limit Google Cloud's ability to decrypt data by disabling keys. In addition, customers can automatically or manually rotate keys when using CMEKs.
Cloud External Key Manager
Cloud External Key Manager (Cloud EKM) allows customers to manage keys outside of Google Cloud and set up Cloud KMS to use those externally managed keys.
Cloud Storage Data Access
When you create a bucket in Cloud Storage, you can choose to use uniform or fine-grained access. With uniform bucket-level access you use only IAM to manage permissions while fine-grained access enables the use of ACLs along with IAM. Google recommends using uniform access. With uniform access, you can grant permissions at the bucket or project level. Fine-grained access controls were designed to support interoperability with AWS S3 buckets, but it is considered a legacy access control method.
In addition to uniform and fine-grained access, you can use signed URLs to provide access to objects for a short period of time. Signed URLs are useful when you want to grant access to a small number of objects in a bucket that has otherwise limited access.
Cloud Storage buckets can also be made publicly accessible; however, cloud administrators can prevent public access by enabling the public access prevention resource constraint.
With regard to uploading data into Cloud Storage, you can create signed policy documents to restrict what can be uploaded. With policy documents you can limit uploads based on object size, content type, and other characteristics.
It is a good practice to validate uploads and downloads to Cloud Storage using either CRC32C or MD5 checksums. This can help protect the integrity of data by detecting differences in source and transferred data due to network problems, memory errors, bugs, or malicious tampering. CRC32C is the Google-recommended way to validate data because it supports composite objects, such as those created when you upload an object as multiple components loaded in parallel.
Security Evaluation
Cloud users can expend significant time and resources configuring and managing identity management services, access controls, and encryption key management. Without a formal evaluation process, however, they are in the dark about how well these measures protect their systems. Two ways to evaluate the extent of the protection provided by the combination of security measures in place are penetration testing and auditing.
Penetration Testing
Penetration testing is the process of simulating an attack on an information system to gain insights into potential vulnerabilities. Penetration tests are authorized by system owners.
In some cases, penetration testers know something about the structure of the network, servers, and applications being tested. In other cases, testers start without detailed knowledge of the system that they are probing.
Penetration testing occurs in these five phases.
- Reconnaissance is the phase at which penetration testers gather information about the target system and the people who operate it or have access to it. This could include phishing attacks that lure a user into disclosing their login credentials or details of software running on their network equipment and servers.
- Scanning is the automated process of probing ports and checking for known and unpatched vulnerabilities.
- Gaining access is the phase at which the attackers exploit the information gathered in the first two phases to access the target system.
- In the maintaining access phase, attackers will do things to hide their presence, such as manipulating logs or preventing attacking processes from appearing in a list of processes running on a server.
- Removing footprints, the final phase, involves eliminating indications that the attackers have been in the system. This can entail manipulating audit logs and deleting data and code used in the attack.
During a penetration test, testers will document how they gathered and exploited information, what if any vulnerabilities they exploited, and how they removed indications that they were in the system.
You do not have to notify Google when conducting a penetration test, but you must still comply with the terms of service for GCP.
You can find details on how to perform penetration testing at the Highly Adaptive Cybersecurity Services site at www.gsa.gov/technology/technology-products-services/it-security/highly-adaptive-cybersecurity-services-hacs, at the Penetration Testing Execution Standard organization at www.pentest-standard.org/index.php/Main_Page, and at the Open Web Application Security Project at owasp.org/www-project-penetration-testing-kit.
Auditing
Auditing is basically reviewing what has happened on your system. In the case of Google Cloud, there are a number of sources of logging information that can provide background details on what events occurred on your system and who executed those actions.
Your applications should generate logs that identify significant events, especially security-related events. For example, if a new user is granted administrator rights to an application, that should be logged.
The Cloud Logging agent will collect logs for widely used services, including syslog, Jenkins, Memcached, MySQL, PostgreSQL, Redis, and ZooKeeper. For a full list of logs collected, see cloud.google.com/logging/docs/agent/default-logs.
Managed services, like Compute Engine, Cloud SQL, and App Engine, log information to Cloud Logging logs.
Cloud Audit Logs is a GCP service that records administrative actions and data operations. Administrative actions that modify configurations or metadata of resources are always logged by Cloud Audit Logs. Data access logs record information when data is created, modified, or read. Data access logs can generate large volumes of data so that it can be configured to collect information for select GCP services. System Event audit logs are generated by Google Cloud systems and record details of actions that modify resource configurations. Policy Denied audit logs record information related to when Google Cloud denies access to a user or service account because of a security policy.
The logs are saved for a limited period of time. Often, regulations require that audit logs be retained for longer periods of time. Plan to export audit logs from Cloud Audit Logs and save them to Cloud Storage or BigQuery. They can also be written to Cloud Pub/Sub.
Logs are exported from Cloud Logging, which supports the following three export methods:
- JSON files to Cloud Storage
- Logging tables to BigQuery datasets
- JSON messages to Cloud Pub/Sub
You can use lifecycle management policies in Cloud Storage to move logs to different storage tiers, such as Nearline and Coldline storage, or delete them when they reach a specified age.
Penetration testing and logging are two recommended practices for keeping your systems secure.
Security Design Principles
As a cloud architect, you will be expected to know security design principles such as separation of duties, least privileges, and defense in depth.
Separation of Duties
Separation of duties (SoD) is the practice of limiting the responsibilities of a single individual in order to prevent the person from successfully acting alone in a way detrimental to the organization. A simple example comes from finance.
In a finance department that practices separation of duties, a single person cannot both create a bill to be paid and pay the bill. If they could, that person could create a false bill in the finance system and then approve its payment. We have similar situations in information technology.
If there is concern that developers should not have the ability to deploy application code to production without first having it reviewed, then the deployment process could be configured to require that another developer review the code before releasing it. In this case, the developer who wrote the code cannot be the one to review it.
This kind of practice is used in DevOps organizations that prioritize agility and rapid release of new features. In an organization where security is a higher priority, then developers may not be allowed to deploy code to production at all. Instead, that responsibility is given to a different role.
Sometimes duties extend outside of development or system administration. For example, an organization may require a senior manager to approve giving a root privilege to an account on systems that store sensitive and confidential information. Another person, such as a system administrator, would then actually create the account. In this case, approval and execution are separated.
There are limits to separation of duties. In small organizations, there may not be enough staff to separate duties as much as one would like. For example, if only one person knows how to administer operating systems, then that person would likely have complete access to any part of the system. In such a case, the system administrator could make a malicious change to the operating system and then modify logs to hide those actions. In these cases, other practices, such as third-party audits, can be used to mitigate the risk of malicious activity.
Least Privilege
Least privilege is the practice of granting only the minimal set of permissions needed to perform a duty. IAM roles and permissions are fine-grained and enable the practice of least privilege. Consider, for example, roles associated with App Engine.
roles/appengine.appAdmincan read, write, and modify access to all application configuration and settings.roles/appengine.appViewerhas read-only access to all application configuration and settings.roles/appengine.codeViewerhas read-only access to all application configuration, settings, and deployed source code.roles/appengine.deployerhas read-only access to all application configuration and settings and has write access to create a new version but cannot modify existing versions other than deleting versions that are not receiving traffic.roles/appengine.serviceAdminhas read-only access to all application configuration and settings and has write access to module-level and version-level settings but cannot deploy a new version.
Someone who is responsible for auditing App Engine code in production only needs to view code and does not need to change it. They can have only roles/appengine.codeViewer and still be able to perform their duties. In an organization where developers release code into production but then an application administrator takes over responsibility, developers can be granted roles/appengine.deployer, and the application administrator can have roles/appengine.serviceAdmin.
The predefined roles in IAM are designed to fit the needs of common roles found in information technology. There is likely to be a predefined IAM role for most organizational roles. If not, you can create a custom role and assign that role the specific privileges required.
The basic roles—roles/viewer, roles/editor, and roles/owner—are not suitable for implementing the principle of least privilege. These roles grant broad permissions, such as the ability to view all existing resources and data in a project. These may be suitable for some situations, such as a small team development environment, but they should not be used when blanket access to resources is not acceptable.
Defense in Depth
Defense in depth is the practice of using more than one security control to protect resources and data. For example, to prevent unauthorized access to a database, a user attempting to read the data may need to authenticate to the database and must be executing the request from an IP address that is allowed by firewall rules.
Defense in depth prevents an attacker from gaining access to a resource by exploiting a single vulnerability. If an attacker used a phishing scheme to coax a user's login credentials, they could then log in and bypass the protection of the authentication system. With a firewall rule in place to allow traffic only from trusted IP addresses, the attacker could not reach the resource from other IP addresses. The attacker would have to try to spoof an IP address or gain physical access to a location with devices assigned a trusted IP address.
Defense in depth assumes that any security control can be compromised. One might be tempted to think a widely used open source application that has source code available to anyone would have been reviewed so much that any vulnerabilities have been found and corrected. That is not the case.
For example, in 2014, the Heartbleed vulnerability was found in OpenSSL, a widely used open source cryptographic software library. The vulnerability allowed attackers to read memory of servers or clients running the compromised version. For more information on Heartbleed, see heartbleed.com. In 2021, a vulnerability in Log4j was discovered that allowed an unauthenticated remote actor to execute arbitrary code loaded from an LDAP server. For more on the impact of this vulnerability, see security.googleblog.com/2021/12/understanding-impact-of-apache-log4j.html.
These security design principles are often used to secure systems, especially when those systems are subject to regulations.
Major Regulations
Governments and industry organizations have developed rules and regulations to protect the privacy of individuals, ensure the integrity of business information, and ensure that a baseline level of security is practiced by organizations using information technology. As a cloud architect, you should understand widely applicable regulations, such as HIPAA/HITECH, which applies to individuals living in the United States, and GDPR, which applies to individuals living in the European Union.
Although HIPAA/HITECH and GDPR are different regulations, they have overlapping goals. It is not surprising that similar security controls and practices are often used to comply with both. Two other regulations with which you should be familiar for the Professional Cloud Architect exam are SOX and the Children's Online Privacy Protection Act.
HIPAA/HITECH
HIPAA is a federal law in the United States that protects individuals' healthcare information. It was enacted in 1996 and updated in 2003 and 2005. HIPAA is a broad piece of legislation, but from a security perspective, the most important parts are the HIPAA Privacy Rule and the HIPAA Security Rule.
The HIPAA Privacy Rule is a set of rules established to protect a patient's healthcare information. It sets limits on data that can be shared by healthcare providers, insurers, and others with access to protected information. This rule also grants patients the right to review information in their records and request information. For further details on this rule, see the following:
www.hhs.gov/hipaa/for-professionals/privacy/index.html
The HIPAA Security Rule defines standards for protecting electronic records containing personal healthcare information. The rule requires organizations that hold electronic healthcare data to ensure the confidentiality, integrity, and availability of healthcare information, protect against expected threats, and prevent unauthorized disclosures. In practice, this requires security management practices, access control practices, incident response procedures, contingency planning, and evaluation of security measures. For more information on the HIPAA Security Rule, see the following:
www.hhs.gov/hipaa/for-professionals/security/index.html
The Health Information Technology for Economic and Clinical Health (HITECH) Act was enacted in 2009, and it includes rules governing the transmission of health information. HITECH extended the application of HIPAA to business associates of healthcare providers and insurers. Business associates that provide services to healthcare and insurance providers must follow HIPAA regulations as well.
When using Google Cloud for data and processes covered by HIPAA, you should know that all of Google Cloud infrastructure is covered under Google's Business Associate Agreement (BAA), and many GCP services are as well, including Compute Engine, App Engine, Kubernetes Engine, BigQuery, Cloud SQL, and many other products. For a complete list, see the following:
cloud.google.com/security/compliance/hipaa
For more on HITECH, see the following:
General Data Protection Regulation
The EU's GDPR was passed in 2016 and began enforcement in 2018. The purpose of this regulation is to standardize privacy protections across the European Union, grant controls to individuals over their private information, and specify security practices required for organizations holding the private information of EU citizens.
GDPR distinguishes controllers and processors. A controller is a person or organization that determines the purpose and means of processing personal data. A processor is a person or organization that processes data on behalf of a controller.
Controllers are responsible for gaining and managing consent of individuals whose data is collected. Controllers direct processors on implementing the wishes of individuals who request access or changes to data. Processors are responsible for securing data and conducting audits to ensure that security practices are functioning as expected.
In the event of a data breach, data processors must notify the controller. Controllers in turn must notify the supervising authority, which varies by country, and individuals whose data was compromised.
For more information on GDPR, see the following:
Sarbanes-Oxley Act
SOX is a U.S. federal law passed in 2002 to protect the public from fraudulent accounting practices in publicly traded companies. The legislation includes rules governing financial reporting and information technology controls. SOX has three rules covering destruction and falsification of records, the retention period of records, and the types of records that must be kept.
Under SOX, public companies are required to implement controls to prevent tampering with financial data. Annual audits are required as well. This typically means that companies will need to implement encryption and key management to protect the confidentiality of data and access controls to protect the integrity of data.
For more information on Sarbanes-Oxley, see www.soxlaw.com.
Children's Online Privacy Protection Act
COPPA is a U.S. federal law passed in 1998 that requires the U.S. Federal Trade Commission to define and enforce regulations regarding children's online privacy. This legislation is primarily focused on children under the age of 13, and it applies to websites and online services that collect information about children.
The rules require online service operators to do the following:
- Post clear and comprehensive privacy policies.
- Provide direct notice to parents before collecting a child's personal information.
- Give parents a choice about how a child's data is used.
- Give parents access to data collected about a child.
- Give parents the opportunity to block collection of a child's data.
- Keep a child's data only so long as needed to fulfill the purpose for which it was created.
- In general, maintain the confidentiality, integrity, and availability of collected data.
Personal information covered by this rule includes name, address, online contact information, telephone number, geolocation data, and photographs.
For more information on COPPA, see the following:
www.ftc.gov/tips-advice/business-center/guidance/complying-coppa-frequently-asked-questions
ITIL Framework
ITIL, which was formerly known as the Information Technology Infrastructure Library, is a set of IT service management practices for coordinating IT activities with business goals and strategies. ITIL specifies 34 practices grouped into three broad areas.
- General management practices, which include strategy, architecture, risk management, security management, and project management
- Service management practices, which include business analysis, service design, capacity and performance management, incident management, and IT asset management
- Technical management practices, which include deployment management, infrastructure management, and software development management
One reason an organization may adopt ITIL is to establish repeatable good practices that span business and technical domains within an organization.
For more on information ITIL, see the following:
www.tsoshop.co.uk/product/9789401804394/Business-and-Management/ITIL-4-pocket-guide
Summary
Designing for security and compliance is multifaceted. IAM is used for managing identities, groups, roles, permissions, and related functionality. Predefined roles are preferred over basic roles in most situations. Policies are used to associate a set of roles and permissions with a resource.
Encryption is used to protect data in transit and at rest. Google Cloud encrypts data at rest by default. Google Cloud can manage keys, or customers can manage their own keys. It is strongly suggested that you use security best practices, including separation of duties and defense in depth.
Exam Essentials
- Know the key components of the Identity and Access Management service. The key components of the IAM service include identities and groups, resources, permissions, roles, and policies. Identities can be a Google account, a service account, or a Cloud Identity account. Identities can be collected into Google Groups or G Suite groups.
- Understand roles are sets of permissions. Remember that IAM permissions are granted to roles and roles are granted to identities. You cannot grant a permission directly to an identity. Google has created predefined roles that map to common organizational roles, such as administrators, viewers, and deployers. Predefined roles have all of the permissions someone in that organizational role typically needs to perform their duties. Custom roles can also be created if the predefined roles do not fit your needs.
- Basic roles should be used in limited situations. Basic roles are the owner, editor, and viewer. These roles existed prior to IAM and grant coarse-grained permissions to identities. Basic roles should be used only in cases where users need broad access, such as developers in a development environment. In general, you should favor predefined roles over basic roles or custom roles.
- Resources are entities in GCP that can be accessed by a user. Access is controlled by IAM. Resources is a broad category that essentially includes anything that you can create in GCP including projects, virtual machines, storage buckets, and Cloud Pub/Sub topics. Permissions vary by type of resource. Cloud Pub/Sub, for example, has permissions related to writing messages to topics and creating subscriptions. Those permissions would not make sense for other types of resources. Some role patterns are used across entity types, such as admin and viewer.
- Policies are used to associate a set of roles and permissions with resources. A policy is a set of statements that define a combination of users and roles. This combination of users and a role is called a binding. Policies are specified using JSON. Policies are used in addition to IAM identity-based access controls to limit access to resources.
- Understand the resource hierarchy. Organizations are at the top of the hierarchy. Organizations contain folders and projects. Folders can contain other folders as well as projects. Access controls assigned to entities in the hierarchy are inherited by entities lower in the hierarchy. Access controls assigned to an entity do not affect entities higher in the hierarchy.
- Know that Google encrypts data at rest by default. Data is encrypted at multiple levels. At the platform level, database and file data is protected using AES256 and AES128 encryption. At the infrastructure level, data is grouped into data chunks in the storage system, and each chunk is encrypted using AES256 encryption. At the hardware level, storage devices apply AES256 or AES128 encryption.
- Data at rest is encrypted with a data encryption key (DEK). The DEK is encrypted with a KEK. Data is encrypted in chunks, and the DEK is kept near the data that it encrypts. The service writing the data has a KEK, which is used to encrypt the DEK. Google manages rotating KEKs.
- Understand how Google encrypts data in transit. Google distinguishes data in transit on the Google network and data in transit on or over the public internet. Data within the boundaries of the Google network is authenticated but may not be encrypted. Data outside the physical boundaries of the Google network is encrypted.
- Know the three types of key management. Google provides default key management in which Google generates, stores, and manages keys. With the Cloud KMS Key Management service, customers manage the generation, rotation, and destruction of keys, but the KMS service stores the keys in the cloud. Customer-supplied keys are fully managed and stored on-premises by customers.
- Understand the role of penetration testing and auditing. Both are forms of security evaluation. The goal of penetration testing is to find vulnerabilities in services by simulating an attack by malicious actors. You do not have to notify Google when you perform penetration testing. The purpose of auditing is to ensure that security controls are in place and functioning as expected.
- Know security best practices, including separation of duties, least privilege, and defense in depth. Separation of duties is the practice of limiting the responsibilities of a single individual in order to prevent the person from successfully acting alone in a way detrimental to the organization. Least privilege is the practice of granting only the minimal set of permissions needed to perform a duty. Defense in depth is the practice of using more than one security control to protect resources and data.
- Understand how to use security controls to comply with regulations. Governments and industry organizations have developed rules and regulations to protect the privacy of individuals, ensure the integrity of business information, and make sure that a baseline level of security is practiced by organizations using information technology. Architects should understand the broad requirements of these regulations. Regulations often have common requirements around confidentiality, integrity, and availability.
Review Questions
- A company is migrating an enterprise application to Google Cloud. When running on-premises, application administrators created user accounts that were used to run background jobs. There was no actual user associated with the account, but the administrators needed an identity with which to associate permissions. What kind of identity would you recommend using when running that application in GCP?
- Google-associated account
- Cloud Identity account
- Service account
- Batch account
- You are tasked with managing the roles and privileges granted to groups of developers, quality assurance testers, and site reliability engineers. Individuals frequently move between groups. Each group requires a different set of permissions. What is the best way to grant access to resources that each group needs?
- Create a group in Google Groups for each of the three groups: developers, quality assurance testers, and site reliability engineers. Add the identities of each user to their respective group. Assign predefined roles to each group.
- Create a group in Google Groups for each of the three groups: developers, quality assurance testers, and site reliability engineers. Assign permissions to each user and then add the identities to their respective group.
- Assign each user a Cloud Identity, and grant permissions directly to those identities.
- Create a G Suite group for each of the three groups: developers, quality assurance testers, and site reliability engineers. Assign permissions to each user and then add the identities to their respective group.
- You are making a presentation on Google Cloud security to a team of managers in your company. Someone mentions that to comply with regulations, the organization will have to follow several security best practices, including least privilege. They would like to know how GCP supports using least privilege. What would you say?
- GCP provides a set of three broad roles: owner, editor, and viewer. Most users will be assigned viewer unless they need to change configurations, in which case they will receive the editor role, or if they need to perform administrative functions, in which case they will be assigned owner.
- GCP provides a set of fine-grained permissions and predefined roles that are assigned those permissions. The roles are based on commonly grouped responsibilities. Users will be assigned only the predefined roles needed for them to perform their duties.
- GCP provides several types of identities. Users will be assigned a type of identity most suitable for their role in the organization.
- GCP provides a set of fine-grained permissions and custom roles that are created and managed by cloud users. Users will be assigned a custom role designed specifically for that user's responsibilities.
- An online application consists of a front-end service, a back-end business logic service, and a relational database. The front-end service is stateless and runs in an instance group that scales between two and five servers. The back-end business logic runs in a Kubernetes Engine cluster. The database is implemented using Cloud SQL PostgreSQL. How many trust domains should be used for this application?
- 1.
- 2.
- 3.
- None. These services do not need trust domains.
- In the interest of separating duties, one member of your team will have permission to perform all actions on logs. You will also rotate the duty every 90 days. How would you grant the necessary permissions?
- Create a Google Group, assign
roles/logging.adminto the group, add the identity of the person who is administering the logs at the start of the 90-day period, and remove the identity of the person who administered logs during the previous 90 days. - Assign
roles/logging.adminto the identity of the person who is administering the logs at the start of the 90-day period, and revoke the role from the identity of the person who administered logs during the previous 90 days. - Create a Google Group, assign
roles/logging.privateLogViewerto the group, add the identity of the person who is administering the logs at the start of the 90-day period, and remove the identity of the person who administered logs during the previous 90 days. - Assign
roles/logging.privateLogViewerto the identity of the person who is administering the logs at the start of the 90-day period, and revoke the role from the identity of the person who administered logs during the previous 90 days.
- Create a Google Group, assign
- Your company is subject to several government and industry regulations that require all personal healthcare data to be encrypted when persistently stored. What must you do to ensure that applications processing protected data encrypt it when it is stored on disk or SSD?
- Configure a database to use database encryption.
- Configure persistent disks to use disk encryption.
- Configure the application to use application encryption.
- Nothing. Data is encrypted at rest by default.
- Data can be encrypted at multiple levels, such as at the platform, infrastructure, and device levels. Data may be encrypted multiple times before it is written to persistent storage. At the device level, how is data encrypted in GCP?
- AES256 or AES128 encryption
- Elliptic curve cryptography
- Data Encryption Standard (DES)
- Blowfish
- In GCP, each data chunk written to a storage system is encrypted with a data encryption key. The key is kept close to the data that it encrypts to ensure low latency when retrieving the key. How does GCP protect the data encryption key so that an attacker who gained access to the storage system storing the key could not use it to decrypt the data chunk?
- Writes the data encryption key to a hidden location on disk
- Encrypts the data encryption key with a key encryption key
- Stores the data encryption key in a secure Cloud SQL database
- Applies an elliptic curve encryption algorithm for each data encryption key
- Data can be encrypted at different layers of the OSI network stack. Google Cloud may encrypt network data at multiple levels. What protocol is used at layer 7?
- IPSec
- TLS
- ALTS
- ARP
- After reviewing security requirements with compliance specialists at your company, you determine that your company will need to manage its own encryption keys. Keys may be stored in the cloud. What GCP service would you recommend for storing keys?
- Cloud Datastore
- Cloud Firestore
- Cloud KMS
- Bigtable
- The finance department of your company has notified you that logs generated by any finance application will need to be stored for five years. It is not likely to be accessed, but it has to be available if needed. If it were needed, you would have up to three days to retrieve the data. How would you recommend storing that data?
- Keep it in Cloud Logging.
- Export it to Cloud Storage and store it in Archive class storage.
- Export it to BigQuery and partition it by year.
- Export it to Cloud Pub/Sub using a different topic for each year.
- The legal department in your company notified software development teams that if a developer can deploy to production, then that developer cannot be allowed to perform the final code review before deploying to production. This is an example of which security best practice?
- Defense in depth
- Separation of duties
- Least privilege
- Encryption at rest
- A startup has hired you to advise on security and compliance related to their new online game for children ages 10 to 14. Players will register to play the game, which includes collecting the name, age, and address of the player. Initially, the company will target customers in the United States. With which regulation would you advise them to comply?
- HIPAA/HITECH
- SOX
- COPPA
- GDPR
- The company for which you work is expanding from North America to set up operations in Europe, starting with Germany and the Netherlands. The company offers online services that collect data on users. With what regulation must your company comply?
- HIPAA/HITECH
- SOX
- COPPA
- GDPR
- Enterprise Self-Storage Systems is a company that recently acquired a startup software company that provides applications for small and midsize self-storage companies. The company is concerned that the business strategy of the acquiring company is not aligned with the software development practices of the software development teams of the acquired company. What IT framework would you recommend the company follow to better align business strategy with software development?
- ITIL
- TOGAF
- Porters Five Forces Model
- Ansoff Matrix