
Chapter 4
Designing Compute Systems
Google Cloud Platform offers several kinds of compute resources that provide varying levels of controls, features, and management support. In this chapter, we will discuss the foundations of designing compute systems. This begins with understanding several compute services:
- Compute Engine
- App Engine
- Cloud Functions
- Cloud Run
- Kubernetes Engine
- Anthos
Each of these six services serves different use cases, although there are use cases that would benefit from using two or more of these services. Knowing how to choose among these is an important skill for architects to develop.
Compute resources require varying levels of provisioning, depending on the compute service. We will discuss using standard, sole-tenant, preemptible, shielded, and confidential virtual machines as well as bare-metal machines in Compute Engine, understanding the difference between App Engine Standard and App Engine Flexible, designing Kubernetes clusters, deploying Anthos for application management, and using Cloud Functions. Network configuration and infrastructure provisioning using an infrastructure-as-code (IaC) approach is also described.
This chapter also describes data pipeline and workflow orchestration services including Cloud Dataflow, Cloud Dataproc, Cloud Workflows, Cloud Data Fusion, and Cloud Composer.
We will also discuss several common design issues, including managing state in distributed systems, designing data flows and pipelines, data integrity, and monitoring and logging.
Compute Services and Use Cases
One of the primary drivers for using public clouds such as the Google Cloud Platform is the ability to access compute resources. Consider these use cases:
- Early public clouds provided access to basic virtual machines, but cloud providers have expanded the type of compute services offered. Google Cloud Platform offers platform-as-a-service (PaaS) with App Engine.
- The ability to run small functions in response to events without setting up and managing servers for those functions is especially useful in distributed cloud applications. This capability is available with Cloud Functions.
- Containers are an efficient way to deploy distributed systems based on microservices, but managing a large number of containers quickly becomes a challenge. Google created its own container orchestration system and then released it into open source as Kubernetes. Google Cloud Platform now offers a fully managed Kubernetes service called Kubernetes Engine (known as GKE).
- Cloud users are increasingly adopting multicloud strategies. Google Cloud has introduced Anthos as an application management-level service for managing policies and workloads across multiple Kubernetes clusters running in GCP, on premises, and in other public clouds.
- AI and machine learning enable new kinds of services but require significant amounts of data to be stored, preprocessed, and used with machine learning algorithms. Several Google Cloud services are available to build scalable, performant data pipelines.
For the Google Cloud Professional Architect exam, it is important to know the features and use cases for each of these compute services. Expect to see questions that ask you to choose the correct compute option for particular scenarios.
Compute Engine
Compute Engine is Google's infrastructure-as-a-service (IaaS) offering. It is also the building block for other services that run on top of this compute resource. The core functionality provided by Compute Engine is virtual machines. Running virtual machines (VMs) in Google Cloud Platform is also known as an instance.
Specifying a Virtual Machine
When creating a VM, you will need to specify several types of information such as machine type, availability status, and enhanced security controls.
Machine Types and Service Accounts
Instances are provisioned by specifying machine types, which are differentiated by the number of CPUs and the amount of memory allocated to the instance. Machines are grouped into machine families, including general-purpose, compute-optimized, memory-optimized, and GPU. Within the general-purpose family, you may choose among several machine types: shared-core, standard, high memory, and high CPU. Currently, compute-optimized machine type supports a standard machine type. Memory-optimized instances have mega memory and ultra-memory machine types. The GPU family is characterized primarily by the type and number of GPUs. Users can also specify customized machine types by specifying vCPUs, memory, CPU platform, number of GPUs, and GPU platform. The options available for machine types may vary depending on the region the virtual machine is deployed to.
When creating an instance, you also specify a boot image. You can choose from a set of predefined boot images, or you can create your own based on one of the predefined boot images. When specifying a boot image, you can also specify standard persistent disk, balanced persistent disk, SSD persistent disk, or extreme persistent disk as well as the size of the disk. The type of disk should be decided based on the workload you will be running on the VM.
- Standard persistent disks are efficient and reliable block storage used for large data processing workloads that use sequential I/Os.
- Balanced disks are cost-effective and reliable block storage. SSD persistent disks are fast and reliable and balance cost and performance. These devices have the same maximum IOPS as SSD persistent disks but lower IOPS per GB. These are often used with general-purpose applications loads.
- SSD persistent disks provide low latency and high IOPS typically used in applications that require single-digit millisecond latencies, such as databases.
- Extreme persistent disks provide high performance for workloads that have both sequential and random access patterns. IOPS are user configurable. These devices are used for high-performance applications such as SAP HANA.
In addition to specifying a boot image, you also have the option of deploying a container. When deploying a container, you can specify a restart policy (Always, Never, On Failure) and if the container should run as privileged. Containers are not allowed to access system devices, such as disks or network interfaces. When a container is run as privileged, the container has equivalent permissions to running as root on the host.
Data is encrypted automatically. You can choose to use Google managed keys, or you can manage keys yourself and store them in the cloud by using the Google Cloud Key Management Service. If you prefer to manage and store keys outside of GCP, you can use customer-supplied keys.
A VM also has a service account associated with it. A service account is a type of identity. Service accounts have permissions bound to them. The service account enables VMs to perform actions that would otherwise require a user to execute a task. For example, if a service account has permission to write to a Cloud Storage bucket, a process on the VM can write to that bucket using the service account.
Sole-Tenant VMs
If you need to ensure that your VMs run only on physical servers with other VMs from the same project, you can select sole tenancy when provisioning instances. When specifying a sole-tenant VM, you will specify node affinity labels. Node affinity labels are used to group nodes and schedule VMs on specific nodes.
By using sole-tenant nodes you can deploy multiple VMs on a machine while ensuring that only VMs from the same project are provisioned on that physical machine. Sole-tenant nodes are especially useful when using bring your own license (BYOL) that are based on per-core or per-processor licenses pricing.
You may also enable CPU overcommit on sole-tenant nodes. This allows you to share spare CPU cycles across instances and is especially useful when a workload typically under-utilizes CPU and can tolerate some performance fluctuations. When you overcommit CPU resources, you specify the minimum number of CPUs that are allocated to a VM. The overcommit value represents the minimum number of CPU threads guaranteed to be available for a VM.
Preemptible Virtual Machines and Spot VMs
VMs can be standard or preemptible. Standard VMs continue to run until you shut them down or there is a failure in the VM. If a standard VM fails, it will be migrated to another physical server by default. Preemptible virtual machines are available at 60 percent to 91 percent discounts off the cost of standard VMs; preemptible VMs may not always be available depending on the demand for compute resources. A preemptible VM will run up to 24 hours before it is shut down by GCP. It can be shut down at any time before then as well. When a preemptible VM is shut down, processes on the instance will have 30 seconds to shut down gracefully. Preemptible VMs cannot live migrate to a standard VM or automatically restart in the case of a maintenance event. Preemptible VMs are not covered by the Compute Engine SLA.
Spot VMs are a newer version of preemptible VMs. Both have a similar pricing model, but Spot VMs are not automatically shut down after 24 hours. At the time of writing, Spot VMs are in Pre-GA and may have limited support and are not covered by the Compute Engine SLA.
Shielded VMs
Shielded VMs are instances with enhanced security controls, including the following:
- Secure boot
- vTPM
- Integrity monitoring
Secure boot runs only software that is verified by digital signatures of all boot components using UEFI firmware features. If some software cannot be authenticated, the boot process fails. Software is authenticated by verifying the digital signature of boot components are in a secure store of approved keys.
Virtual Trusted Platform Module (vTPM) is a virtual module for storing keys and other secrets. vTPM enables Measured Boot, which takes measurements to create a known good boot baseline, which is known as the integrity policy baseline. That baseline is used for comparisons with subsequent boots to detect any differences.
Integrity monitoring compares the boot measurements with a trusted baseline and returns true if the results match and false otherwise. Logs are created for several types of events, including clearing the secrets store, early boot sequence integrity checks, late boot sequence integrity checks, updates to the baseline policy, and enabling/disabling Shielded VM options.
Confidential VMs
Confidential VMs encrypt data in use. This complements encryption of data in transit and at rest. Confidential VMs run on hosts that are based on AMD EPYC™ processors, which provide Secure Encrypted Virtualization that encrypts all memory. All Confidential VMs have their own encryption key. You can create a Confidential VM by enabling the feature when creating a VM.
Recommender
Google provides a recommender service to help optimize the use of cloud resources. Compute Engine is one of the GCP products with recommenders, which are machine learning models that provide insights into how you can save on your cloud expenses, improve security, or otherwise optimize your cloud resources. Recommenders use data about your provisioned infrastructure to generate recommendations.
Recommenders include a committed use discount recommender, idle custom image recommender, idle IP address recommender, idle persistent disk recommender, and idle VM recommender.
Instance Groups
Instance groups are clusters of VMs that are managed as a single unit. GCP supports two kinds of instance groups: managed and unmanaged. Managed instance groups (MIGs) contain identically configured instances. The configuration is specified in an instance template. Unmanaged instance groups are groups of VMs that may not be identical. They are not provisioned using an instance template. They are used only to support preexisting cluster configurations for load balancing tasks. Unmanaged instance groups are not recommended for new configurations.
An instance template defines a machine type, disk image or container image, network settings, and other properties of a VM. The instance template can be used to create a single instance or a managed group of instances. Instance templates are global resources, so they can be used in any region. If you specify zonal resources in a template, however, they will have to be changed before using the template in another zone.
MIGs provide several advantages, including the following:
- Maintaining a minimal number of instances in the MIG. If an instance fails, it is automatically replaced.
- Autohealing using application health checks. If the application is not responding as expected, the instance is restarted.
- Distribution of instances across a zone. This provides resiliency in case of zonal failures.
- Load balancing across instances in the group.
- Autoscaling to add or remove instances based on workload.
- Auto-updates, including rolling updates and canary updates.
- Rolling updates will update a minimal number of instances at a time until all instances are updated.
- Canary updates allow you to run two versions of instance templates to test the newer version before deploying it across the group.
MIGs should be used when availability and scalability are required for VMs. This is usually the case in production systems. MIGs may be deployed as zonal MIGs, which have instances in a single zone, or as regional MIGs, which have instances in multiple zones within a single region.
Managed instance groups may be used for stateless or stateful workloads. Stateless workloads do not maintain state which is the case for website front ends and many bulk file processing applications, such as processing uploaded files from a queue. Stateful applications maintain state information.
Examples include databases and long-running batch computations. Stateful MIGs preserve each instance's state, including instance name, persistent disks, and metadata when the instance is restarted, re-created, autohealed, or otherwise updated.
Compute Engine Use Cases
Compute Engine provides flexible and customizable compute resources. Compute Engine is a good choice for a compute service when you need control over all aspects of a VM, including specifying the operating system, selecting enhanced security controls, and configuring attached storage.
Compute Engine instances can also be created using a container as a base image. In this case, Compute Engine will use a container-optimized operating system. Kubernetes Engine uses Compute Engine instance groups to implement Kubernetes clusters. If you prefer to take advantage of advanced container-orchestration features, you should use Kubernetes Engine. Cloud Run is a managed service for running stateless containerized applications. App Engine Flexible supports running custom containers in a platform-as-a-service. Kubernetes Engine, Cloud Run, and App Engine are described in detail later in this chapter.
You can manage all aspects of a VM when deploying Compute Engine instances by logging into instances as root or administrator. From there, you can install additional software, change access controls, and set up users and groups, among other things. In general, it is a good practice to use scripts or automation to improve reproducibility and reduce the chance of errors when manually making changes.
Compute Engine is also a good option when running stateful applications, like databases. You can configure persistent storage tailored to your needs. If you need to support high IOPS, then you can configure instances with SSD persistent disks or extreme persistent disks. If you are deploying a cluster to run batch jobs that are not time sensitive, you could save on costs by using balanced persistent disks.
If you need a highly secured environment, then Shielded VMs and sole tenancy can be enabled in Compute Engine instances. Sole tenancy is used when you want to run only VMs from the same project on a server and is useful when using BYOL licensing that is based on a per-core or per-processor pricing model.
App Engine
App Engine is a serverless PaaS compute offering. With App Engine, users do not have to configure servers since it is a fully managed service. They provide application code that is run in the App Engine environment. There are two forms of App Engine: App Engine Standard and App Engine Flexible.
App Engine Standard
App Engine Standard is a PaaS product that allows developers to run their applications in a serverless environment. There are restrictions, however, on the languages that can be used to develop those applications. Currently, App Engine Standard provides the following language-specific runtime environments:
- Go
- Java
- PHP
- Node.js
- Python
- Ruby
Each instance of an application running in App Engine Standard has an instance class that is determined by the CPU speed and the amount of memory. The memory in an instance varies by runtime generation, known as first-generation and second-generation.
Second-generation runtimes are used with Python 3, Java 11, Node.js, PHP 7, Ruby, and Go 1.12+. The default instance class for second-generation runtimes is the F1 with 256 MB memory limit and 600 MHz CPU limit. You can change the instance:class setting in app.yaml to use a different instance class. The largest second-generation instance class provides 2048 MB of memory and 4.8GHz CPU.
First-generation App Engine Standard supports Python 2.7, Java 8, and PHP 5.5. These language versions are no longer supported by open source communities, but Google Cloud continues to support them as legacy runtimes because some App Engine customers require them.
App Engine Flexible
App Engine Flexible allows developers to customize their runtime environments by using Dockerfiles. By default, the App Engine Flexible environment supports the following:
- Go
- Java 8
- .NET
- Node.js
- PHP 5/7
- Python 2.7 and Python 3.6
- Ruby
Custom Runtimes
App Engine Flexible instances are based on Compute Engine VMs so you can use SSH for debugging and deploy custom Docker containers. With App Engine Flexible you can specify CPU and memory configurations. These instances provide additional features to what is provided by Compute Engine, including the following:
- Health checks and autohealing
- Automatic updates to the operating system
- Automatically colocate a project's VM instances for performance
- Weekly maintenance operations including restarts and updates
- Ability to use root access
App Engine Use Cases
App Engine Standard is a good option when you have an application that is written in one of the supported languages and needs to scale rapidly up or down, depending on traffic. Instance startup time is on the order of seconds. On the other hand, App Engine Flexible is a good choice when applications are run within a Docker container. App Engine Flexible scales, but startup time of instances is on the order of minutes, not seconds. It is also a good choice when your application uses microservices, when it depends on custom code, or when libraries are not available in App Engine Standard.
The following are the key differences between running containers in App Engine Flexible and running them in Compute Engine:
- App Engine Flexible containers are restarted once per week.
- By default, SSH access is disabled in an App Engine Flexible container, but you can enable it. SSH access is enabled by default in Compute Engine.
- Images in App Engine Flexible are built using the Cloud Build service. Images run in Compute Engine may use the Cloud Build service, but it is not necessary.
- The geographic location of App Engine Flexible instances is determined by project settings, and all App Engine Flexible instances are colocated for performance.
App Engine resources are regional, and GCP deploys resources redundantly across all zones in a region.
App Engine includes the App Engine Cron Service, which allows developers to schedule tasks to run at regular times or intervals.
In general, applications running in App Engine should be stateless. If state does need to be maintained, store it outside instances in a cache or database.
App Engine provides Task Queues to support operations that need to run asynchronously or in the background. Task Queues can use either a push or pull model. Task Queues are well suited for distributing tasks. If you need a publish/subscribe-type messaging service, then Cloud Pub/Sub is a good option.
App Engine Flexible provides some support for deploying applications with containers, but for full container orchestration services, consider using Kubernetes Engine.
Cloud Functions
Cloud Functions is a serverless compute service well suited for event processing. The service is designed to respond to and execute code in response to events within the Google Cloud Platform. For example, if an image file is uploaded to Cloud Storage, a Cloud Function can execute a piece of code to transform the image or record metadata in a database. Similarly, if a message is written to a Cloud Pub/Sub topic, a Cloud Function may be used to operate on the message or invoke an additional process.
Cloud Functions supports several runtimes, including Node.js, Python 3, Go, Java 11, .NET Core, Ruby, and PHP.
Incoming requests to a cloud function are assigned to an instance of a Cloud Function. An existing instance may be used if available or a new instance may be created. Each instance operates on one request at a time. You can, however, specify a maximum limit on the number of instances that exist at one time.
Events, Triggers, and Functions
Cloud Functions uses three components: events, triggers, and functions. An event is an action that occurs in the GCP. Cloud Functions does not work with all possible events in the cloud platform; instead, it is designed to respond to several kinds of events:
- Cloud Storage
- Cloud Pub/Sub
- HTTP
- Cloud Firestore
- Firebase
- Cloud Logging
For each kind of event, there are different actions to which a Cloud Function can respond.
- Cloud Storage has upload, delete, and archive events.
- Cloud Pub/Sub recognizes message publishing events.
- HTTP events have five actions:
GET,POST,PUT,DELETE, andOPTIONS. - Cloud Firestore supports events on document create, update, delete, and write operations.
- Firebase is a mobile application development platform that supports database triggers, remote configuration triggers, and authentication triggers.
- When a message is written to Cloud Logging, you can have it forwarded to Cloud Pub/Sub, and from there you can trigger a call to a cloud function.
A trigger in Cloud Functions is a specification of how to respond to an event. Triggers have associated functions.
HTTP functions are guaranteed to execute at most once while other event types are guaranteed to execute at least once. A Cloud Function should be idempotent; that is, it should return the same result given the same set of input parameters no matter how many times it is executed.
Cloud Functions Use Cases
A Cloud Function is used for event-driven processing. The code is run in response to a triggering event, like a file being updated in Cloud Storage or a message written to a Cloud Pub/Sub topic. Here are some specific use cases that demonstrate the range of uses for Cloud Functions:
- When an image is uploaded to a particular Cloud Storage bucket, a function verifies the image file type and converts to the preferred file type if needed.
- When a new version of code is uploaded to a code repository, trigger on a webhook and execute a function that sends a message to other developers who are watching changes to the code.
- When a user of a mobile app initiates a long-running operation, write a message to a Cloud Pub/Sub queue and trigger a function to send a message to the user informing them that the operation will take several minutes.
- When a background process completes, write a message to a Cloud Pub/Sub queue and trigger the execution of a function that sends a message to the initiator of the process notifying them that the operation finished.
- When a database administrator authenticates to a Firebase database, trigger the execution of a function that writes a message to an audit log and sends a message to all other administrators informing them someone has logged in as an administrator.
Notice that each example begins with the word When. This is because a Cloud Function is executed in response to things that happen somewhere in GCP. Cloud Functions complement the App Engine Cron Service, which is provided to execute code at regular intervals or at specific times. With these two services, developers can create code that executes as needed without human intervention. Both services also relieve developers of writing a service that would run continually and check if an event occurred and, if it did, then execute some action.
Cloud Run
Cloud Run is a Google Cloud service for running stateless containers. Cloud Run is available as a managed service or within Anthos. When using the managed service, you pay per use and can have up to 1,000 container instances by default. You can allow unauthorized access to services running in Cloud Run, or you can use an Identity-Aware Proxy (IAP) to limit access to authorized clients.
Unlike App Engine Standard, Cloud Run does not restrict you to using a fixed set of programming languages. Cloud Run services have regional availability. Cloud Run is easily integrated with Cloud Code for version control and Cloud Build for continuous deployments.
A service is the main abstraction of computing in Cloud Run. A service is located in a region and replicated across multiple zones. A service may have multiple revisions. A revision is a deployment of a service and consists of a specific container image and a configuration. Cloud Run will autoscale the number of instances based on load.
Each container instance can process up to 80 concurrent requests by default, but this can be increased up to 1,000. This is different from Cloud Functions, which serves only one request at a time.
If you deploy an image that is not designed to handle multiple requests or a single request can consume most CPU and memory, then you can reduce the concurrency to 1. Also, if you want to avoid cold starts, you can configure a minimum number of instances of 1 to ensure your service is always available to receive a request without waiting to start up an instance.
To improve the security of services, use Google managed base images that are regularly updated. Also enable the Container Registry image vulnerability scanner to perform security scans on your images in Container Registry.
Kubernetes Engine
Google Kubernetes Engine (GKE) is a managed service providing Kubernetes cluster management and Kubernetes container orchestration. Kubernetes Engine allocates cluster resources, determines where to run containers, performs health checks, and manages VM lifecycles using Compute Engine instance groups. Note, Kubernetes is often abbreviated K8s.
Kubernetes and Kubernetes Engine are increasingly important for architects to understand. Kubernetes provides highly scalable and reliable execution of containers, which are often more efficient to run than virtual machines. Kubernetes has a growing ecosystem of related services and tools such as Helm, for managing Kubernetes applications, and Flux, for supporting continuous deployment and delivery using source version control, commonly called GitOps. Also, it is common to use Istio to secure individual clusters or enable services in multiple clusters to securely work with each other.
Kubernetes uses declarative configuration to define the desired state of a cluster, service, or other entity. Kubernetes uses automation to monitor the state of entities and return them to the desired state when they drift from that desired state. Key services provided by Kubernetes include the following:
- Service discovery
- Load balancing
- Storage allocation
- Automated rollouts and rollbacks
- Placement of containers to optimize use of resources
- Automated detection and correction with self-healing
- Configuration management
- Secrets management
Kubernetes is open source so it can be run in Google Cloud, on-premises, and in other clouds. This has created the need for services to support the deployment of multiple Kubernetes clusters over multiple cloud or on-premises infrastructures. Anthos is another Google Cloud service designed for orchestrating applications and workload across multiple clusters. Anthos is described in more detail in the following sections.
Kubernetes Cluster Architecture
You can think of Kubernetes from an infrastructure perspective, that is, in terms of the VMs in the cluster, or from a workload and Kubernetes abstraction perspective, such as in terms of how applications function within the cluster.
Kubernetes Clusters from an Infrastructure Perspective
A Kubernetes cluster has two types of instances: cluster masters and nodes. (See Figure 4.1.)
- The cluster master runs four core services that are part of the control plane: controller manager, API server, scheduler, and etcd. The controller manager runs services that manage Kubernetes abstract components, such as deployments and replica sets. Applications interacting with the Kubernetes cluster make calls to the master using the API server. The API server also handles intercluster interactions. The scheduler is responsible for determining where to run pods, which are low-level compute abstractions that support containers. etcd is a distributed key-value store used to store state information across a cluster.
- Nodes are instances that execute workloads. They communicate with the cluster master through an agent called kubelet. Kube-proxy is a network proxy that runs on each node and is responsible for maintaining and implementing rules for network communication with network sessions inside and outside the cluster.
The container runtime is the software that enables containers to run. Supported container runtimes include Docker, containerd, CRI-O, and any other container runtime that implements the Kubernetes Container Runtime Interface (CRI). Note, Docker has been deprecated as a supported container runtime by Kubernetes in favor of container runtimes that implement the CRI.
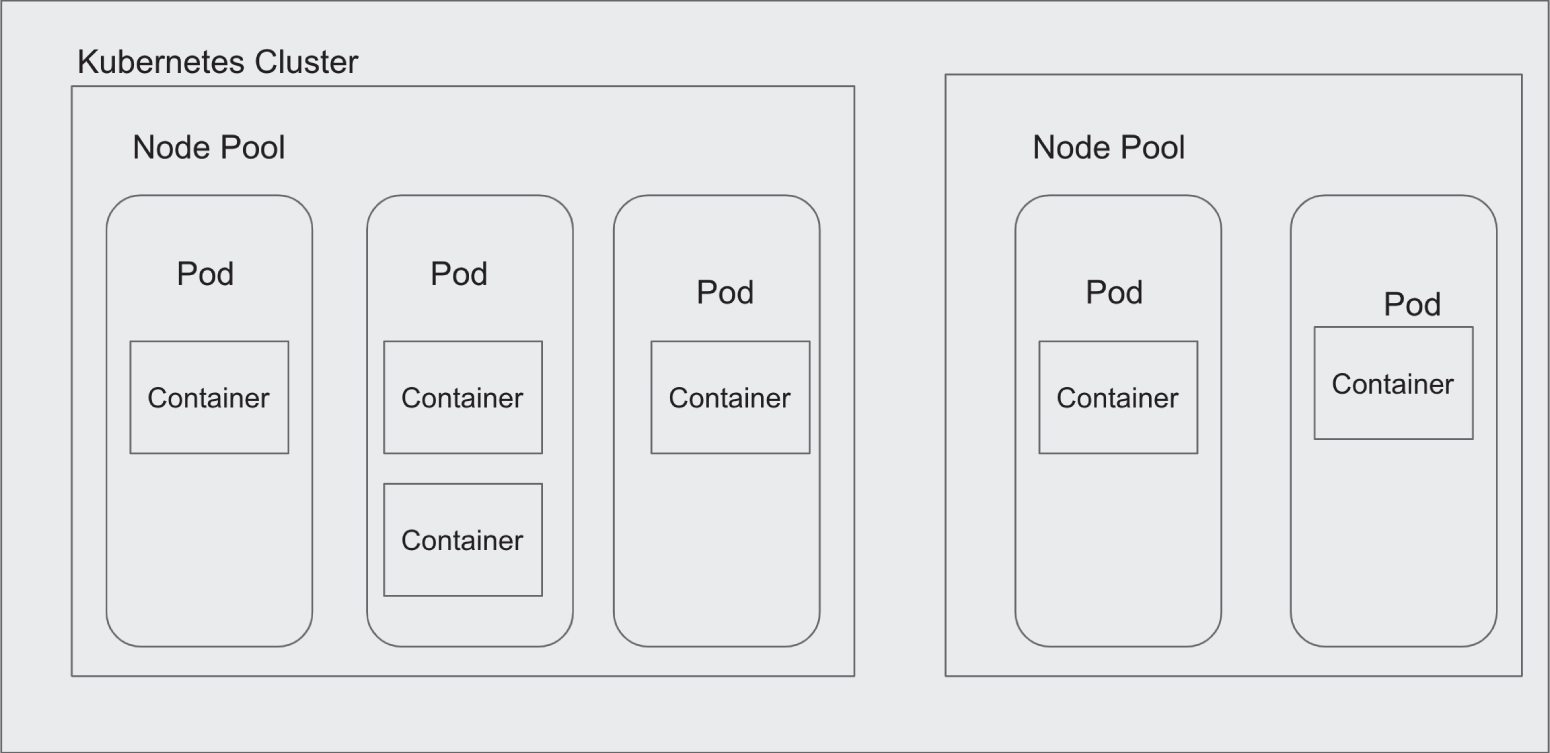
FIGURE 4.1 Kubernetes clusters have a set of worker nodes that are managed by a control plane.
Kubernetes Clusters from a Workload and Kubernetes Abstraction Perspective
Kubernetes introduces abstractions that facilitate the management of containers, applications, and storage services. Some of the most important are the following:
- Pods
- Services
- ReplicaSets
- Deployments
- PersistentVolumes
- StatefulSets
- Ingress
- Node pools
Pods are the smallest computation unit managed by Kubernetes. Pods contain one or more containers. Often pods have just one container, but if the functionality provided by two containers is tightly coupled, then they may be deployed in the same container. A common example is the use of proxies, such as an Envoy proxy, which can provide support services such as authentication, monitoring, and logging. Multiple containers should be in the same pod only if they are functionally related and have similar scaling and lifecycle characteristics.
Pods are deployed to nodes by the scheduler. They are usually deployed in groups or replicas. This provides for high availability, which is especially needed with pods. Pods are ephemeral and may be terminated if they are not functioning properly.
One of the advantages of Kubernetes is that it monitors the health of pods and replaces them if they are not functioning properly. Since multiple replicas of pods are run, pods can be destroyed without completely disrupting a service. Pods also support scalability. As load increases or decreases, the number of pods deployed for an application can increase or decrease.
Since pods are ephemeral, other services that depend on them need a way to discover them when needed. Kubernetes uses the service abstraction for this. A service is an abstraction with a stable API endpoint and stable IP address that is used to expose an application running on a set of pods. A service keeps track of its associated pods so that it can always route calls to a functioning pod.
A ReplicaSet is a controller that manages the number of pods running for a deployment. Deployments are a type of controller consisting of pods running the same version of an application. Each pod in a deployment is created using the same template, which defines how to run a pod. The definition is called a pod specification.
Kubernetes deployments are configured with a desired number of pods. If the actual number of pods varies from the desired state, for example, if a pod is terminated for being unhealthy, then the ReplicaSet will add or remove pods until the desired state is reached.
Pods may need access to persistent storage, but since pods are ephemeral, it is a good idea to decouple pods that are responsible for computation from persistent storage, which should continue to exist even after a pod terminates. PersistentVolumes is Kubernetes' way of representing storage allocated or provisioned for use by a pod. Pods acquire access to persistent volumes by creating a PersistentVolumeClaim, which is a logical way to link a pod to persistent storage.
Pods as described so far work well for stateless applications, but when state is managed in an application, pods are not functionally interchangeable. Kubernetes uses the StatefulSet abstraction, which is like a deployment. StatefulSets are used to designate pods as stateful and assign a unique identifier to them. Kubernetes uses these to track which clients are using which pods and to keep them paired.
An Ingress is an object that controls external access to services running in a Kubernetes cluster. An Ingress Controller must be running in a cluster for an Ingress to function.
Node pools are sets of nodes in a cluster with the same configuration and a common node label. (See Figure 4.2.) Kubernetes creates a default node pool when a cluster is created, and you can create additional custom node pools. Node pools can be created with nodes configured for particular workloads. The configuration of a pod determines which node pool it runs in. Pod configuration can contain a nodeSelector that specifies a node label. A node with the same node label specified in a pod configuration will be selected to run that pod. When node labels are used, pods will only be run on nodes with a matching node label. Kubernetes also supports the concept of node affinity, which tries to schedule a pod on a node that meets the specified constraints but will run it on another node if needed.
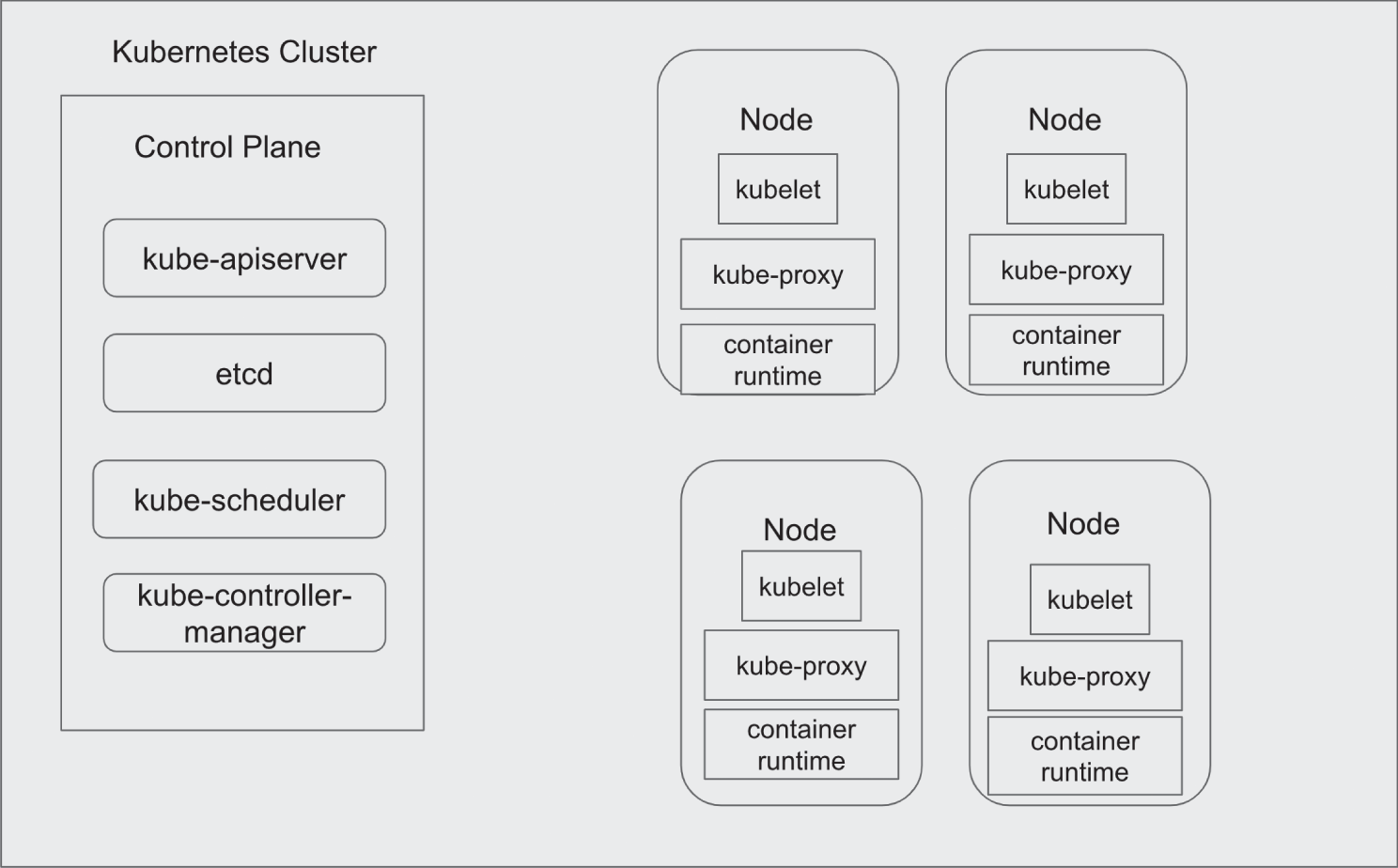
FIGURE 4.2 Pods are deployed on nodes, which may be grouped into multiple node pools within a cluster.
Kubernetes Engine Types of Clusters
Kubernetes Engine clusters can be configured to varying levels of management and availability depending on needs.
There are two modes of operation in Kubernetes Engine: standard and autopilot. In standard mode you have the most flexibility and control over the configuration of the cluster, including the infrastructure. This is a good option when you would like control over whether you use zonal or regional clusters, use routes-based networking, and select the version of Kubernetes you run. When running in standard mode, you pay per node provisioned.
In standard mode, you can choose between zonal and regional clusters. Zonal clusters have a single control plane in a single zone. A single-zone cluster has nodes running in the same zone as the control plane. A multizonal cluster has a single control plane running a zone but has nodes running in multiple zones. This has the advantage that workloads can run in a zone if there is an outage in the other zones. A regional cluster has multiple replicas of the control plane running in multiple zones of a single region. Node pools are replicated across three zones in regional clusters by default, but you can change that configuration during cluster setup.
In autopilot mode, GKE provides a preconfigured provisioned and managed cluster. Autopilot mode clusters are always regional and use VPC-native network routing. With autopilot mode you will not have to manage compute capacity or manage the health of pods. Nodes and node pools are managed by GKE. When using autopilot, you pay only for CPU, memory, and storage that pods use while running.
GKE also provides the option of creating private clusters, in which nodes have only internal IP addresses. This isolates nodes in the cluster from the internet by default.
Kubernetes Networking
Kubernetes uses a declarative model to specify network rules in Kubernetes. Networking in Kubernetes is associated with pods, services, and external clients as well as with nodes. Three kinds of IP addresses are supported in Kubernetes.
- ClusterIP, which is an IP address assigned and fixed to a service
- Pod IP, which is an ephemeral IP address assigned to a pod
- Node IP, which is an IP address assigned to a node in a cluster
Node IPs are assigned from the cluster's virtual private cloud (VPC) network and provide connectivity to kubelet and kube-proxy. Pod IP addresses are assigned from a pool of addresses shared across the cluster. ClusterIP addresses are assigned by the VPC.
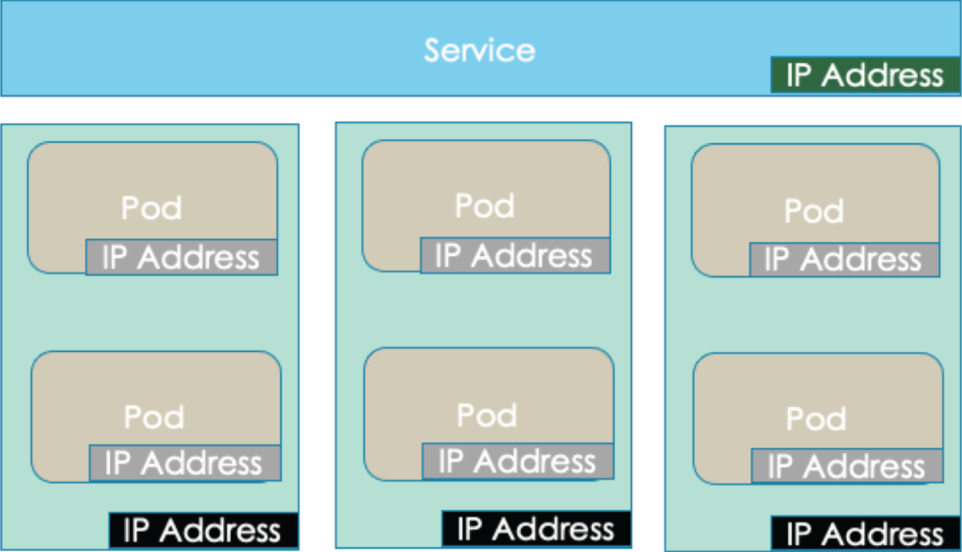
FIGURE 4.3 Kubernetes uses multiple types of IP addresses for different purposes.
Service Networking
By default, pods do not expose external IP addresses and instead rely on kube-proxy to manage traffic on the node. Pods and containers within a cluster can communicate using IP addresses and with services using ClusterIP addresses.
Network access to a service depends on how the service is defined. When creating a service, we can specify a ServiceType. The default ServiceType is ClusterIP, which exposes a service on the internal IP network and makes the service reachable only from within the cluster.
A NodePort ServiceType exposes the service on a node's IP address at a static port specified as NodePort in the configuration. External clients can reach the service by specifying the node IP address and the NodePort.
A LoadBalancer service exposes a service outside the cluster using a cloud provider load balancer. When a LoadBalancer service type is used, a NodePort and ClusterIP service are created automatically, and the load balancer routes traffic to them.
You can also create a service with an ExternalName ServiceType, which uses DNS names to make a service reachable.
Load Balancing in Kubernetes Engine
Load balancers distribute traffic and control access to a cluster. Services in Kubernetes Engine can use external load balancers, internal load balancers, and HTTP(S) load balancers.
External load balancers are used when a service needs to be reachable from outside the cluster and outside the VPC. GKE will provision a network load balancer for the service and configure firewall rules to allow connections to the service from outside the cluster.
Internal load balancers are used when a service needs to be reachable from within the cluster. In this case an internal TCP/UDP load balancer is used. The load balancer uses an IP address from the VPC subnet instead of an external IP address.
Container native load balancing makes use of network endpoint groups (NEGs). The endpoints consist of an IP address and a port that specify a pod and a container port.
To allow HTTP(S) traffic from outside the VPC, we use a Kubernetes Ingress resource. The Ingress maps URLs and hostnames to services in the cluster. Services are configured to use both ClusterIP and NodePort service types.
If further constraints on network are needed, you can specify network policies to limit access to pods based on labels, IP address ranges, and port numbers. These policies create pod-level firewall rules. You can restrict External Load Balancers by specifying loadBalancerSourceRanges in a service configuration. To limit access to HTTP(S) load balancers, use Cloud Armor security policies and Identity-Aware Proxy service.
Kubernetes Engine Use Cases
Kubernetes Engine is a managed service that relieves users of managing their own Kubernetes cluster. Kubernetes is used to allocate compute resources efficiently to a pool of containers running applications. It is essential that applications and services be containerized before they can run in Kubernetes.
Kubernetes is a good platform for deploying microservices. If you prefer to minimize system administration overhead, you could deploy containers using App Engine Flexible. Cloud Run is an option if you are running stateless containers and do not require Kubernetes features, such as node pools. If you prefer to have more maximum control over the configuration of the platform running your containers, then Kubernetes Engine in standard mode is the best option. If you want the features of Kubernetes while minimizing cluster and infrastructure management, then Kubernetes Engine in autopilot mode is a good option.
Anthos
Anthos is an application management platform that builds on Kubernetes' hybrid and multicloud implementations. Anthos is designed to address many of the challenges of managing applications and services across infrastructure on-premises and in multiple clouds. With Anthos, we extend the declarative model found in Kubernetes to allow us to specify the desired state of a fleet of clusters. Anthos observes state of clusters, decides on changes needed to bring the system into the desired state, and then executes those changes. This management model includes policy enforcement, service management, cluster management, and infrastructure management.
Overview of Anthos
Anthos Clusters extend GKE for hybrid and multicloud environments by providing services to create, scale, and upgrade conformant Kubernetes clusters along with a common orchestration layer. Multiple clusters can be managed as a group known as a fleet. Anthos Clusters can be connected using standard networking options including VPNs, Dedicated Interconnects, and Partner Interconnects.
The configuration of Anthos Clusters uses a declarative model for computing, networking, and other services. Configurations, which are stored in Git repositories, build on Kubernetes abstractions such as namespaces, labels, and annotations.
There are several key benefits to using Anthos to manage multiple Kubernetes clusters, including the following:
- Centralized management of configuration as code
- Ability to roll back deployments with Git
- A single view of cluster infrastructure and applications
- Centralized and auditable workflows
- Instrumentation of code using Anthos Service Mesh
- Anthos Service Mesh authorization and routing
In addition, Anthos includes Migrate for Anthos for GKE, which is a service that allows you to orchestrate migrations using Kubernetes and Anthos.
The term Anthos Clusters refers to GKE Clusters that have been extended to function on-premises or in multicloud environments.
Anthos Service Mesh
A service mesh is an architecture pattern that provides a common framework for services to communicate. We use service meshes to perform common operations, such as monitoring, networking, and authentication on behalf of services so individual services do not have to implement those operations. In addition to alleviating work on service developers, with a service mesh we can have consistent ways of handling support operations like monitoring and networking.
Anthos Service Mesh is a managed service based on Istio, which is a widely used open source service mesh. A service mesh has one, or possibly more than one, control plane and a data plane. A control plane is a set of services that configure and manage communications between services. The control plane provides configuration information to sidecar proxies for each service. A sidecar is an auxiliary service that supports a main service. In the case of Kubernetes, a sidecar is a utility service that runs with a workload container in a pod. A data plane is a part of a service mesh that manages communications between workload services.
Some of the functionality provided by Anthos Service Mesh includes the following:
- Controlling the flow of traffic between services, including at the application layer (layer 7) when using Istio-compatible custom resources
- Collecting service metrics and logs for ingestion by Cloud Operations
- Preconfigured service dashboards
- Authenticating services with mutual TLS (mTLS) certificates
- Encrypting control plane communications
Anthos Service Mesh can be deployed in three ways: in-cluster control plane, managed Anthos Service Mesh, or including Compute Engine VMs in the service mesh. With the in-cluster control plane the Istiod service is run in the control plane to manage security, traffic, configuration, and service discovery. With managed Anthos Service Mesh, Google manages the control plane, including upgrades. Google Cloud also manages scaling as needed and security. When using Anthos Service Mesh for Compute Engine VMs, you can also manage and secure managed instance groups and Google Kubernetes Engine Clusters in the same mesh.
Anthos Multi Cluster Ingress
The Anthos Multi Cluster Ingress is a controller that is hosted on Google Cloud and enables load balancing of resources across clusters, including multiregional clusters. In this setup, you can have a single consistent virtual IP address for applications regardless of where they are deployed. By supporting multiple regions and multiple clusters, the Multi Cluster Ingress brings additional support for high availability. It also enables the cluster migration during upgrades and so reduces downtime.
The Multi Cluster Ingress is a globally distributed control plane that runs outside of your clusters. Within the Multi Cluster Ingress, the Config Cluster is the GKE Cluster running in GCP that is configured with the Multi Cluster Ingress resource. This ingress resource runs only on the Google Cloud Deployment.
Anthos Deployment Options
Anthos is available in several deployment options. The features available vary by deployment, but Anthos Service Mesh and Anthos Config Management are included in all deployments. Anthos Service Mesh provides the following:
- Traffic control with rules for HTTP(S), gRPC, and TCP traffic
- Metrics, logs, and traces for all HTTP(S) traffic in a cluster, including ingress and egress traffic
- Service-level security with authentication and authorization
- Support for A/B testing and canary rollouts
The Anthos Config Management service controls cluster configuration by applying to configuration specifications to select components of a cluster based on such as namespaces, labels, and annotations. Anthos Config Management includes the Policy Controller, which is designed to enforce business logic rules on API requests to Kubernetes. This is particularly useful for defining and enforcing security and audit rules consistently across a fleet.
The Google Cloud Deployment is the most comprehensive deployment option and includes core GKE components, including the following:
- Node auto provisioning
- Vertical pod autoscaling
- Shielded GKE Nodes
- Workload Identity Federation
- GKE Sandbox
The Google Cloud Deployment also includes Anthos Config Management, Anthos Cloud Run, Multi Cluster Ingress, and binary authorization.
The On-Premises Deployment is designed to run Anthos in on-premises infrastructure. In addition to Anthos Config Management and the Anthos UI & Dashboard, this deployment includes services needed for an on-premises implementation including the following:
- Network plugin
- Container Storage Interface (CSI) and hybrid storage
- Authentication Plugin for Anthos
- Prometheus and Grafana (on VMware)
- Bundled layer 4 load balancers (on VMware)
Anthos can be run on AWS using the AWS Deployment which includes the following:
- Anthos Config Management
- Anthos UI & Dashboard
- Network Plugin
- Container Storage Interface (CSI) and hybrid storage
- Authentication Plugin for Anthos
- AWS load balancers
The minimal deployment option known as Attached Clusters Deployment includes Anthos Config Management, Anthos UI & Dashboard, and Anthos Service Mesh.
AI and Machine Learning Services
Google Cloud delivers an array of AI and machine learning services. Vertex AI is a unified machine learning platform for developing, deploying, and scaling machine learning models. Cloud TPUs are accelerators for training large deep learning networks. In addition, Google also offers specialized services such as Speech-to-Text, Text-to-Speech, Virtual Agents, Dialogflow CX, Translation, Vision OCR, and the Document AI Platform. In this section, we will review Vertex AI and Cloud TPUs, two broadly useful services that architects should be familiar with.
Vertex AI
Vertex AI is the combination of two prior Google Cloud services, AutoML and AI Platform. Vertex AI provides a single API and user interface. Vertex AI supports both customer training of machine learning models and automated training of models using AutoML. Vertex AI includes several components, such as the following:
- Training using both AutoML automated training and AI custom training
- Support for ML model deployment
- Data labeling, which allows you to request human assistance in labeling training examples for supervised learning tasks
- Feature store, which is a repository for managing and sharing ML features
- Workbench, which is a Jupyter notebook-based development environment
Vertex AI also includes specially configured deep learning VM images and containers.
Cloud TPU
Cloud TPU is a Google Cloud service that provides access to Tensor Processing Units (TPUs), which are custom-designed, application-specific integrated circuits (ASICs) designed by Google. TPUs can be more efficient at training deep learning models than GPUs or CPUs. A single Cloud TPU v2 can provide 180 teraflops, while a v3 can provide 420 teraflops. You can also use clusters of TPUs known as pods. A v2 pod provides 11.5 petaflops, and a v3 pod provides more than 100 petaflops.
Cloud TPUs are a distinct service that is integrated and available from other GCP services. For example, you can connect to a TPU or pod from a Compute Engine VM running a deep learning image or Google Kubernetes Engine.
In addition to the standard priced TPUs, Preemptible TPUs are available at 70 percent off standard pricing.
Data Flows and Pipelines
Applications are typically composed of multiple modules or services. Monolithic applications do exist, but they are typically legacy systems. Even when monolithic applications are used, there are some business operations that require multiple steps of processing using multiple applications.
Consider, for example, a health insurance claim, made on behalf of a patient by a healthcare provider. The workflow to process this claim might include the following:
- Verifying the patient and provider data in an eligibility application
- Analyzing the medical procedures performed and assigning a value in a benefits assignment application
- Reviewing the claim and proposed benefit for potential fraud in a compliance review system
- Sending the data to a data warehouse for use by business analysts
- Issuing payment to the provider by a payment processing system
- Sending an explanation of benefits letter to the patient by a patient services application
This insurance claim scenario is an example of how monolithic systems may be used together to implement a workflow to implement a fairly complicated business process. Other workflows are implemented using microservices. For example, when you make a purchase online, the retailer's application may use several microservices, such as the following:
- Checking inventory to verify that the product is available to ship
- Authorizing payment through a third-party payment processor
- Issuing a fulfillment order that is sent to a warehouse where the item will be packaged and shipped
- Sending details of the transaction to a data warehouse for analysis
- Sending a confirmation message to the customer with delivery information
In both the health insurance claim and the online purchase example, multiple applications and services are used to implement a business workflow. When choosing cloud compute resources and designing workflows to meet business requirements, consider how data will flow from one service to the next.
Cloud Pub/Sub Pipelines
Cloud Pub/Sub is a good option for buffering data between services. It supports both push and pull subscriptions.
With a push subscription, message data is sent by HTTP POST request to a push endpoint URL. The push model is useful when a single endpoint processes messages from multiple topics. It's also a good option when the data will be processed by an App Engine Standard application or a Cloud Function. Both of those services bill only when in use, and pushing a message avoids the need to check the queue continually for messages to pull.
With a pull subscription, a service reads messages from the topic. This is a good approach when processing large volumes of data and efficiency is a top concern.
Cloud Pub/Sub pipelines work well when data just needs to be transmitted from one service to another or buffered to control the load on downstream services. If you need to process the data, for example, applying transformations to a stream of Internet of Things (IoT) data, then Cloud Dataflow is good option.
Cloud Dataflow Pipelines
Cloud Dataflow is an implementation of the Apache Beam stream processing framework. Cloud Dataflow is fully managed, so you do not have provision and manage instances to process data in streams. The service also operates in batch mode without changes to processing code. Developers can write stream and batch processing code using Java, Python, and SQL.
Cloud Dataflow can be used in conjunction with Cloud Pub/Sub, with Cloud Dataflow being responsible for processing data and Cloud Pub/Sub being responsible for sending messages and buffering data. Cloud Dataflow pipelines often fit into an application's architecture between data ingestion services, like Cloud Pub/Sub and Cloud IoT Core, and storage and analysis services, such as Cloud Bigtable, BigQuery, or Cloud Machine Learning.
Cloud Dataproc
Cloud Dataproc is a managed Spark and Hadoop service that is widely used for large-scale batch processing and machine learning. Spark also supports stream processing. Cloud Dataproc creates clusters quickly so they are often used ephemerally. Cloud Dataproc clusters use Compute Engine virtual machines and can use preemptible instances as worker nodes. It also supports Workflows Templates, which implements workflows as directed acyclic graphs.
Cloud Dataproc has built-in integration with BigQuery, Bigtable, Cloud Storage, Cloud Logging, and Cloud Monitoring.
Cloud Dataproc is recommended when migrating an on-premises Spark and Hadoop cluster and you want to minimize management overhead.
Cloud Workflows
Cloud Workflows is a service for orchestrating HTTP-based API services and serverless workflows. It can be used with Cloud Functions, Cloud Run, and other Google Cloud APIs to string together a set of processing steps.
Workflows are defined as a series of steps specified in YAML or JSON formats. An authenticated call is required to execute a workflow.
Cloud Workflows is used to coordinate a series of API calls. When you need to process a large volume of data or coordinate a complex sequence of jobs, one of the other Google Cloud managed services for workloads, such as Cloud Dataflow, Cloud Dataproc, Cloud Fusion, or Cloud Composer, will be a better option.
Cloud Data Fusion
Cloud Data Fusion is a managed service based on the CDAP data analytics platform that allows for development of extraction, transformation, and load (ETL) and extraction, load, and transform (ELT) pipelines without coding. CDAP provides a code-free, drag-and-drop development tool that includes more than 160 prebuilt connectors and transformations.
Cloud Data Fusion is deployed as an instance and comes in three versions. The Developer version is the lowest cost and most limited in terms of features. The Basic Edition includes a visual design, transformations, and an SDK. The Enterprise edition includes those features plus streaming pipelines, integration with a metadata repository, high availability, as well as support for triggers and scheduling.
Cloud Composer
Cloud Composer is a managed service for Apache Airflow, a workflow orchestration system that executes workflows represented as directed acyclic graphs (DAGs). Within Apache Airflow, a workflow is a collection of tasks with dependencies. DAGs are defined in Python scripts and stored in Cloud Storage.
The building blocks of Apache Airflow include tasks, operators, hooks, and plugins. Tasks are a unit of work represented by a node in a graph. Operators define how tasks will be run and include action operators, transfer operators, and sensor operators. Hooks are interfaces to third-party services. When a hook is combined with an operator, it is referred to as a plugin.
When an Apache Airflow DAG is executed, logs are generated. Workflow logs are associated with a single DAG task. You can view the logs in the Airflow web interface or by viewing the logs folder in the associated Cloud Storage bucket. Streaming logs are available in Logs Viewer for the scheduler, web server, and workers.
Compute System Provisioning
GCP provides an interactive console as well as a command-line utility for creating and managing compute, storage, and network resources. It also provides the Deployment Manager service that allows you to specify infrastructure as code. It is a good practice to define infrastructure as code, since it allows teams to reproduce environments rapidly. It also lends itself to code reviews, version control, and other software engineering practices.
Deployment Manager uses declarative templates that describe what should be deployed.
Sets of resource templates can be grouped together into deployments. When a deployment is run or executed, all of the specified resources are created.
Alternatively, you may also use Terraform, an open source infrastructure and code system. Terraform uses HashiCorp Configuration Language (HCL) to describe resources and then generates execution plans to implement changes to bring an infrastructure into the desired state described by the HCL specification. Terraform is cloud agnostic.
Additional Design Issues
In addition to considering how you will configure and deploy compute resources, you will need to understand how compute resources interact, how data flows, and how to monitor infrastructure and applications.
Managing State in Distributed Systems
Managing state information is commonplace when designing distributed systems. Stateful systems present a few different kinds of challenges, which you should keep in mind when designing cloud application architectures.
Persistent Assignment of Clients to Instances
Stateful systems keep data about client processes and connections. For example, consider IoT sensors on industrial machines.
Every minute a sensor sends metrics on temperature, vibrations, and throughput of the device. The data is stored in a buffer for 10 minutes where it is evaluated for anomalies. The 10 minutes' worth of data that is maintained is state information. For this model to work, a sensor needs to send its data continually to the same server each time data is generated.
One design decision is how to assign sensors to servers. Often, the best solution is to assign a sensor to an instance randomly. This will distribute the workload evenly across a cluster. In practice, it is common to use modulo division on a numeric identifier, like a sensor ID. The divisor is the number of instances. Assuming that you have a cluster with eight instances, one set of assignments for sensors with IDs 80, 83, 89, and 93 is as follows:
- 80 mod 8 = 0
- 83 mod 8 = 3
- 89 mod 8 = 1
- 93 mod 8 = 5
A variation on this pattern is to use some form of aggregate-level identifier, such as an account number or group number instead of individual sensor identifiers. For example, assume that in our IoT example each machine has between 10 and 200 sensors. If we assigned sensors to instances based on machine ID, it is possible that some servers would have more load than others. If 300 machines with 200 sensors were assigned to one machine, while 300 machines with 10 sensors were assigned to another, the workload would be skewed to the former.
Horizontally scalable systems function well in GCP. Compute Engine instance groups and Kubernetes Engine clusters can readily add and remove compute resources as needed. When each instance has to store state information, you will need to find a way to distribute work at the application level so that clients can be assigned to a single server. Another option, however, is to move state information off the instances to some common data store.
Persistent State and Volatile Instances
Assigning a client to a server solves the problem of having state information available to the application instance that needs it. Since clients always send data to the same instance, state information is maintained on that instance. No other instance needs to be queried to collect a client's state data in this scenario.
It does not solve the problem of instance volatility, however. What happens when an instance or container becomes unhealthy and shuts down? We could treat this as a high availability problem and use redundant instances. This may be a viable option when there are a small number of instances, but it can quickly become wasteful as the number of instances grows.
A better solution in many cases is to separate the storage of state data from volatile instances. Both in-memory cache and databases are viable options.
In-Memory Cache
In-memory cache, such as Cloud Memorystore, which is a managed Redis and memcached service, works well when an application needs low-latency access to data. The data in the cache can be persisted using snapshots. If the cache fails, the contents of memory can be re-created using the latest snapshot. Of course, any data changed between the time of the last snapshot and the cache failure is not restored using the snapshot. Additional measures are required. For example, if the data is ingested from a queue, the data could be kept in the queue until it is saved in a snapshot. If snapshots are made once per minute, the time to live (TTL) on messages in the queue could be set to two minutes.
Cloud Pub/Sub uses a publish-subscribe model. Once a message is delivered and the delivery is acknowledged, the message is removed from the message queue. If a message is not acknowledged within a configured amount of time, it is redelivered.
Databases
Another option for moving state data off of volatile instances is to use a database. This has the advantage of persisting data to durable storage. When using a database, the application only needs to define how to read and write data to the database; no additional steps are needed to snapshot caches or manage message queues. A potential disadvantage is that database latency may be higher than cache latency. If latency is a concern, you can use a cache to store database query results so data that is repeatedly queried can be read from the lower-latency cache instead of the higher-latency database.
Another disadvantage is that databases are complicated applications and can be difficult to maintain and tune. GCP offers several databases as managed services, including Cloud SQL and Cloud Datastore, which reduce the operational burden on developers and operators.
Synchronous and Asynchronous Operations
In some cases, the workflow is simple enough that a synchronous call to another service is sufficient. Synchronous calls are calls to another service or function that wait for the operation to complete before returning; asynchronous calls do not wait for an operation to complete before returning. Authorizing a credit card for a purchase is often a synchronous operation. The process is usually completed in seconds, and there are business reasons not to proceed with other steps in the workflow until payment is authorized.
In other situations, synchronous calls to services could hold up processing and introduce lag into the system. Consider the online purchase example. Once payment is authorized, the fulfillment order should be created. The system that receives fulfillment orders may experience high load or might have several servers unavailable during update operations. If a synchronous call is made to the fulfillment system, then a disruption in the normal operation of the fulfillment system could cause delays in finishing the purchase transaction with the customer. From a business requirement perspective, there is no need to complete the fulfillment order processing before completing the sales transaction with the customer. This would be a good candidate for an asynchronous operation.
One way to implement asynchronous processing is to buffer data between applications in a message queue. One application writes data to the message queue, and the other application reads it. Writing and reading from message queues are fast operations, so synchronous read and write operations on queues are not likely to introduce delays in processing. If the application that reads from the queue cannot keep up with the rate at which messages are being written, the messages will remain in the queue until the reading application can get to them.
This kind of buffering is especially helpful when the services have different scaling requirements. A spike in traffic on the front end of a web application can be addressed by adding instances. This is especially straightforward when the front-end application is stateless. If the backend depends on a database, then scaling is more difficult. Instead of trying to scale the backend, it's better to allow work to accumulate in a queue and process that work using the resources in place. This will require more time to complete the work, but it decouples the work that must be done immediately, which is responding to the user, from work that can be done later, such as backend processing.
You have multiple options when implementing workflows and pipelines. You could implement your own messaging system and run it on one of the GCP compute services. You could also deploy a messaging service, such as RabbitMQ, or a streaming log, such as Apache Kafka. If you would like to use a GCP managed service, consider Cloud Pub/Sub and Cloud Dataflow.
Summary
GCP offers a number of compute services including Compute Engine, App Engine, Cloud Run, Kubernetes Engine, Anthos, and Cloud Functions. Compute Engine is Google's infrastructure-as-a-service (IaaS) offering. The core functionality provided by Compute Engine is virtual machines (VMs). App Engine is a platform-as-a-service (PaaS) compute offering. With App Engine, users do not have to configure servers. They provide application code that is run in the App Engine environment. There are two forms of App Engine: App Engine Standard and App Engine Flexible. Cloud Run is a managed service for deploying stateless containers. Kubernetes Engine is a managed service providing Kubernetes cluster management and Kubernetes container orchestration. Kubernetes Engine allocates cluster resources, determines where to run containers, performs health checks, and manages VM lifecycles using Compute Engine instance groups. Anthos is an application orchestration platform that allows for centralized management of a fleet of Anthos-compliant Kubernetes clusters. Cloud Functions is a serverless compute service well suited for event processing. The service is designed to execute code in response to events within the Google Cloud Platform. Google Cloud provides several services to support data pipelines and machine learning including: Cloud Pub/Sub, Cloud Dataflow, Cloud Dataproc, Cloud Fusion, Cloud Composer, and Cloud Workflows. Other issues to consider when designing infrastructure are managing state in distributed systems, data flows, and monitoring and alerting.
Exam Essentials
- Understand when to use different compute services. GCP compute services include Compute Engine, App Engine, Cloud Run, Kubernetes Engine, Anthos, and Cloud Functions. Compute Engine is an IaaS offering. You have the greatest control over instances, but you also have the most management responsibility.
App Engine is a PaaS that comes in two forms. App Engine Standard uses language-specific sandboxes to execute your applications. App Engine Flexible lets you deploy containers, which you can create using Docker.
Cloud Run is another alternative for deploying stateless containers using a managed service.
Kubernetes Engine is a managed Kubernetes service. It is well suited for applications built on microservices, but it also runs other containerized applications. Anthos is used to manage Kubernetes clusters deployed across multiple clouds and on-premises.
Cloud Functions is a service that allows you to execute code in response to an event on GCP, such as a file being uploaded to Cloud Storage or a message being written to a Cloud Pub/Sub topic.
- Understand Compute Engine instances' optional features. These include the variety of machine types, preemptibility, and Shielded VMs. Also understand how service accounts are used. Understand managed instance groups and their features, such as autoscaling and health checks.
- Know the difference between App Engine Standard and App Engine Flexible. App Engine Standard employs language-specific runtimes, while App Engine Flexible uses containers that can be used to customize the runtime environment. Be familiar with additional services, such as the App Engine Cron Service and Task Queues.
- Know the Kubernetes and Anthos architectures. Understand the differences between master cluster instances and node instances in Kubernetes. Understand the organizing abstractions, including pods, services, ReplicaSets, deployments, PersistentVolumes, and StatefulSets. Know that an Ingress is an object that controls external access to services running in a Kubernetes cluster.
- Know when to use specialized data pipeline and machine learning services. Understand the use cases for Cloud Pub/Sub, Cloud Dataflow, Cloud Dataproc, Cloud Workflows, and Cloud Data Fusion. Know that Vertex AI provides support for both automated and custom machine learning model training.
Review Questions
- You are consulting for a client that is considering moving some on-premises workloads to the Google Cloud Platform. The workloads are currently running on VMs that use a specially hardened operating system. Application administrators will need root access to the operating system as well. The client wants to minimize changes to the existing configuration. Which GCP compute service would you recommend?
- Compute Engine
- Kubernetes Engine
- App Engine Standard
- App Engine Flexible
- You have just joined a startup company that analyzes healthcare data and makes recommendations to healthcare providers to improve the quality of care while controlling costs. The company must comply with privacy regulations. A compliance consultant recommends that your company control its encryption keys used to encrypt data stored on cloud servers. You agree with the consultant but also want to minimize the overhead of key management. What GCP service should the company use?
- Use default encryption enabled on Compute Engine instances.
- Use Google Cloud Key Management Service to store keys that you create and use them to encrypt storage used with Compute Engine instances.
- Implement a trusted key store on premises, create the keys yourself, and use them to encrypt storage used with Compute Engine instances.
- Use an encryption algorithm that does not use keys.
- A colleague complains that the availability and reliability of GCP VMs is poor because their instances keep shutting down without them issuing shutdown commands. No instance has run for more than 24 hours without shutting down for some reason. What would you suggest your colleague check to understand why the instances may be shutting down?
- Make sure that the Cloud Operations agent is installed and collecting metrics.
- Verify that sufficient persistent storage is attached to the instance.
- Make sure that the instance availability is not set to preemptible.
- Ensure that an external IP address has been assigned to the instance.
- Your company is working on a government contract that requires all instances of VMs to have a virtual Trusted Platform Module. What Compute Engine configuration option would you enable or disable on your instance?
- Trusted Module Setting
- Shielded VMs
- Preemptible VMs
- Disable live migration
- You are leading a lift-and-shift migration to the cloud. Your company has several load-balanced clusters that use VMs that are not identically configured. You want to make as few changes as possible when moving workloads to the cloud. What feature of GCP would you use to implement those clusters in the cloud?
- Managed instance groups
- Unmanaged instance groups
- Flexible instance groups
- Kubernetes clusters
- Your startup has a stateless web application written in Python 3.7. You are not sure what kind of load to expect on the application. You do not want to manage servers or containers if you can avoid it. What GCP service would you use?
- Compute Engine
- App Engine
- Kubernetes Engine in Standard Mode
- Cloud Dataproc
- Your department provides audio transcription services for other departments in your company. Users upload audio files to a Cloud Storage bucket. Your application transcribes the audio and writes the transcript file back to the same bucket. Your process runs every day at midnight and transcribes all files in the bucket. Users are complaining that they are not notified if there is a problem with the audio file format until the next day. Your application has a program that can verify the quality of an audio file in less than two seconds. What changes would you make to the workflow to improve user satisfaction?
- Include more documentation about what is required to transcribe an audio file successfully.
- Use Cloud Functions to run the program to verify the quality of the audio file when the file is uploaded. If there is a problem, notify the user immediately.
- Create a Compute Engine instance and set up a cron job that runs every hour to check the quality of files that have been uploaded into the bucket in the last hour. Send notices to all users who have uploaded files that do not pass the quality control check.
- Use the App Engine Cron Service to set up a cron job that runs every hour to check the quality of files that have been uploaded into the bucket in the last hour. Send notices to all users who have uploaded files that do not pass the quality control check.
- You have inherited a monolithic C++ application that you need to keep running. There will be minimal changes, if any, to the code. The previous developer who worked with this application created a Dockerfile and image container with the application and needed libraries. You'd like to deploy this in a way that minimizes your effort to maintain it. How would you deploy this application?
- Create an instance in Compute Engine, install Docker, install the Cloud Monitoring agent, and then run the Docker image.
- Create an instance in Compute Engine, but do not use the Docker image. Install the application, Ruby, and needed libraries. Install the Cloud Monitoring agent. Run the application directly in the VM, not a container.
- Use App Engine Flexible to run the container image. App Engine will monitor as needed.
- Use App Engine Standard to run the container image. App Engine will monitor as needed.
- You have been asked to give a presentation on Kubernetes. How would you explain the difference between the cluster master and nodes?
- Cluster masters manage the cluster and run core services such as the controller manager, API server, scheduler, and etcd. Nodes run workload jobs.
- The cluster manager is an endpoint for API calls. All services needed to maintain a cluster are run on nodes.
- The cluster manager is an endpoint for API calls. All services needed to maintain a cluster are run on nodes, and workloads are run on a third kind of server, a runner.
- Cluster masters manage the cluster and run core services such as the controller manager, API server, scheduler, and etcd. Nodes monitor the cluster master and restart it if it fails.
- External services are not able to access services running in a Kubernetes cluster. You suspect a controller may be down. Which type of controller would you check?
- Pod
- Deployment
- Ingress Controller
- Service Controller
- You are planning to run stateful applications in Kubernetes Engine. What should you use to support stateful applications?
- Pods
- StatefulPods
- StatefulSets
- PersistentStorageSet
- Every time a database administrator logs into a Firebase database, you would like a message sent to your mobile device. Which compute service could you use that would minimize your work in deploying and running the code that sends the message?
- Compute Engine
- Kubernetes Engine
- Cloud Functions
- Cloud Dataflow
- Your team has been tasked with deploying infrastructure for development, test, staging, and production environments in region us-west1. You will likely need to deploy the same set of environments in two additional regions. What service would allow you to use an infrastructure-as-code (IaC) approach?
- Cloud Dataflow
- Deployment Manager
- Identity and Access Manager
- App Engine Flexible
- An IoT startup collects streaming data from industrial sensors and evaluates the data for anomalies using a machine learning model. The model scales horizontally. The data collected is buffered in a server for 10 minutes. Which of the following is a true statement about the system?
- It is stateful.
- It is stateless.
- It may be stateful or stateless; there is not enough information to determine.
- It is neither stateful nor stateless.
- Your team is designing a stream processing application that collects temperature and pressure measurements from industrial sensors. Someone on the team suggests using a Cloud Memorystore cache. What could that cache be used for?
- A SQL database
- As a memory cache to store state data outside of instances
- An extraction, transformation, and load service
- A persistent object storage system
- A distributed application is not performing as well as expected during peak load periods. The application uses three microservices. The first of the microservices has the ability to send more data to the second service than the second service can process and keep up with. This causes the first microservice to wait while the second service processes data. What can be done to decouple the first service from the second service?
- Run the microservices on separate instances.
- Run the microservices in a Kubernetes cluster.
- Write data from the first service to a Cloud Pub/Sub topic and have the second service read the data from the topic.
- Scale both services together using MIGs.
- A colleague has suggested that you use the Apache Beam framework for implementing a highly scalable workflow. Which Google Cloud service would you use?
- Cloud Dataproc
- Cloud Dataflow
- Cloud Dataprep
- Cloud Memorystore
- Your manager wants more data on the performance of applications running in Compute Engine, specifically, data on CPU and memory utilization. What Google Cloud service would you use to collect that data?
- Cloud Dataprep
- Cloud Monitoring
- Cloud Dataproc
- Cloud Memorystore
- You are receiving alerts that CPU utilization is high on several Compute Engine instances. The instances are all running a custom C++ application. When you receive these alerts, you deploy an additional instance running the application. A load balancer automatically distributes the workload across all of the instances. What is the best option to avoid having to add servers manually when CPU utilization is high?
- Always run more servers than needed to avoid high CPU utilization.
- Deploy the instances in a MIG, and use autoscaling to add and remove instances as needed.
- Run the application in App Engine Standard.
- Whenever you receive an alert, add two instances instead of one.
- A retailer has sales data streaming into a Cloud Pub/Sub topic from stores across the country. Each time a sale is made, data is sent from the point of sale to Google Cloud. The data needs to be transformed and aggregated before it is written to BigQuery. Which of the following services would you use to perform that processing and write data to BigQuery?
- Firebase
- Cloud Dataflow
- Cloud Memorystore
- Cloud Datastore
- Auditors have determined that several of the microservices deployed on Kubernetes clusters in your GCP and on-premises clusters do not perform authentication in ways that comply with security requirements. You want developers to be able to deploy microservices without having to spend a lot of time developing and testing authentication mechanisms. What managed service in GCP would you use to reduce the need for developers to implement authentication mechanisms with each new service?
- Kubernetes Services
- Anthos Service Mesh
- Kubernetes Ingress
- Anthos Config Management