
1
Analysis of Current Practices in Reliability Prediction
Lev M. Klyatis
1.1 Overview of Current Situation in Methodological Aspects of Reliability Prediction
Because the problem of reliability prediction is so important there are many publications in the area of the methods of reliability prediction, mostly in the area of electronics. This is especially important when the reliability prediction is necessary to provide a high degree of effectiveness for the products.
Most of these traditional methods of reliability prediction utilize failure data collected from the field to estimate the parameters of the failure time distribution or degradation process. Using this data one can then estimate the reliability measures of interest, such as the expected time to failure or quantity/quality of degradation during a specified time interval and the mean time to failure (or degradation).
Reliability prediction models that utilize accelerated degradation data, rather than those models that utilize degradation data obtained under normal conditions, are often performed because the degradation process is very slow under normal field conditions and prediction modeling based on normal conditions would require excessive time.
One example of such practices is the procedure used by Bellcore for both hardware and software. O'Connor and Kleyner [1] provide a broad description of a reliability prediction method that emphasizes reliability prediction consisting of outputs from the reliability prediction procedure:
- steady‐state failure rate;
- first year multiplier;
- failure rate curve;
- software failure rate.
The output from the reliability prediction procedure is various estimates of how often failure occurs. With hardware, the estimates of interest are the steady‐state failure rate, the first year multiplier, and the failure rate curve. The steady‐state failure rate is a measure of how often units fail after they are more than 1 year old. The steady‐state failure rate is measured in FIT (failures per 109 h of operation). A failure rate of 5000 FIT means that about 4% of the units that are over a year old will fail during following one year periods. The first year multiplier is the ratio of the failure rate in the first year to that in subsequent years. Using these, one generates a failure rate curve that provides the failure rate as a function of the age (volume of work) of the equipment. For software, one needs to know how often the system fails in the field as a result of faults in the software.
The Bellcore hardware reliability prediction is primarily designed for electronic equipment. It provides predictions at the device level, the unit level, and for simple serial systems, but it is primarily aimed at units, where units are considered nonrepairable assemblies or plug‐ins. The goal is to provide the user with information on how often units will fail and will need to be replaced.
The software prediction procedure estimates software failure intensity and applies to systems and modules.
There are many uses for reliability prediction information. One such example is, it can be used as inputs to life‐cycle cost or profit studies. Life‐cycle cost studies determine the cost of a product over its entire life. Required data include how often a unit will have to be replaced. Inputs to this process include the steady‐state failure rate and the first year multiplier.
The Bellcore reliability prediction procedure consists of three methods [1]:
- Parts count. These predictions are based solely by adding together the failure rates for all the devices. This is the most commonly used method, because laboratory and field information that is needed for the other methods is usually not available.
- Incorporating laboratory information. Device or unit level predictions are obtained by combining data from a laboratory test with the data from the parts count method. This allows suppliers to use their data to produce predictions of failure rates, and it is particularly suited for new devices for which little field data are available.
- Incorporating field information. This method allows suppliers to combine field performance data with data from the parts count method to obtain reliability predictions.
Mechanical reliability prediction [2] uses various stress factors under operating conditions as a key to reliability prediction for different devices. This situation is more common in testing mechanical devices, such as bearings, compressors, pumps, and so on than with electronic hardware.
Although, the number of factors that appear to be needed in reliability testing calculations may appear excessive, tailoring methods can be used to remove factors that have little or no influence, or for which limited data are available. Generally, the problems encountered in attempting to predict the reliability of mechanical systems are the lack of:
- specific or generic failure rate data;
- information on the predominant failure modes;
- information on the factors influencing the reliability of the mechanical components.
The mechanical reliability prediction approach can be useful if there is a close connection with the source of information for calculation reliability during the desired time, whether that be warranty period, service life, or other defined period. Obtaining accurate initial information is a critical factor in prediction testing.
Unfortunately, the approaches described earlier, and other prediction methods, provide little guidance on how one can obtain accurate initial information that simulates real product reliability over time or amount of use (volume of work, or duty cycle). Without accurate simulation information, its usefulness is minimal.
Proper understanding of the role of testing and the requirement to do this testing before the production and use of a product is critical and can easily lead to poor product reliability prediction that will negatively impact financial performance.
Prediction is only useful if it reduces early product degradation and prevents premature failures of the product.
There are many recent publications addressing electronics, automotive, and other product recalls. While they usually address reliability failures in terms of safety matters that affect peoples lives by contributing to deaths or injuries, they may also consider economic impacts.
As was mentioned previously, such reliability and other problems are results, not causes. The actual causes of these recalls, and many other technical and economic problems, were a direct result of the inefficient or inadequate prediction of product reliability during the design, and prior to, the manufacturing process.
In the end, it is poorly executed prediction that negatively impacts the organizations financial performance.
Therefore, while many popular and commonly used approaches appear to be theoretically interesting, in the end they do not successfully predict reliability for the product in real‐world applications.
Consider the consequences of the recalls of Takata automobile air bag inflators [3]:
So far, about 12.5 million suspect Takata inflators have been fixed of the roughly 65 million inflators (in 42 million vehicles) that will ultimately be affected by this recall, which spans 19 automakers. Carmakers and federal officials organizing the response to this huge recall insist that the supply chain is churning out replacement parts, most of which are coming from companies other than Takata. For those who are waiting, NHTSA advises that people not disable the airbags; the exceptions are the 2001–2003 Honda and Acura models that we listed on this page on June 30, 2016—vehicles which NHTSA is telling people to drive only to a dealer to get fixed.
Meanwhile, a settlement stemming from a federal probe into criminal wrongdoing by Takata is expected early next year—perhaps as soon as January—and could approach $1 billion.
A key to preventing these situations is the use of advanced test methods and equipment; that is, accelerated reliability testing (ART) and accelerated durability testing (ADT). Implementation of these systematic procedures greatly helps in assuring successful prediction of industrial product reliability.
It is also true that advances in technology generally result in more complicated products and increased economic development costs. Such advances require even more attention to accurately predict product reliability.
When performed successfully, prediction is beneficial to all stages of the product life cycle: start‐up, production and manufacturing, warranty, and long‐term aftermarket support. It touches the lives of all concerned (designers, suppliers, manufacturers, customers), and often even uninvolved third parties who may be affected by the product's failure. It also provides the mechanism for product improvement at any time from the earliest stages of R&D throughout the entire product life cycle.
Currently there are many other publications mostly related to the theoretical aspects of reliability prediction. Many of primarily relate to failure analysis. Some popular failure analysis methods and tools include:
- Failure Reporting, Analysis, and Corrective Action System (FRACAS);
- Failure Mode, Effects and Critical Analysis (FMECA);
- Failure Mode and Effects Analysis (FMEA);
- Fault Tree Analysis (FTA).
FavoWeb is Advanced Logistic Developments' (ADL's) third‐generation, web‐based and user‐configurable FRACAS that captures information about equipment or the processes throughout its life cycle, from design, through to production, testing, and customer support.
FavoWeb has been adopted by world‐class organizations who, for the first time ever, implement a FRACAS application that seamlessly communicates with any given enterprise resource planning (ERP) system (SAP, ORACLE, MFGpro, etc.), while proving a user‐friendly and flexible, yet robust, failure management, analysis, and corrective action platform.
The FavoWeb FRACAS features include:
- full web‐base application;
- user permission mechanism—complies with International Traffic in Arms Regulations requirements;
- flexible, user configurable application;
- seamless communication with ERP/product data management/Excel/Access and other legacy systems;
- web services infrastructure;
- failure/event chaining and routing;
- compatible with PDAs;
- voice‐enabled failure reporting;
- advanced query engine for user‐defined reports.
It also allows the user to decompose the system or process into components or subprocesses. And, for each functional block, it allows the user to define name and function, and enter failure mode causes and effects manually or from libraries. The “Process & Design FMEA” module provides full graphical and textual visibility of the potential failure mode → cause → effects chain.
1.1.1 What is a Potential Failure Mode?
Potential failure mode is any manner in which a component, subsystem, or system could potentially fail to meet the design intent. The potential failure mode could also be the cause of a potential failure mode in a higher level subsystem or system, or be the effect of a potential failure.
Reliability in statistics and psychometrics is the overall consistency of a measure. A measure is said to have a high reliability if it produces similar results under consistent conditions [4]:
It is the characteristic of a set of test scores that relates to the amount of random error from the measurement process that might be embedded in the scores. Scores that are highly reliable are accurate, reproducible, and consistent from one testing occasion to another. That is, if the testing process were repeated with a group of test takers, essentially the same results would be obtained. Various kinds of reliability coefficients, with values ranging between 0.00 (much error) and 1.00 (no error), are usually used to indicate the amount of error in the scores.
For example, measurements of people's height and weight are often extremely reliable [4,5].
There are several general classes of reliability estimates:
- Inter‐rater reliability assesses the degree of agreement between two or more raters in their appraisals.
- Test–retest reliability assesses the degree to which test scores are consistent from one test administration to the next. Measurements are gathered from a single rater who uses the same methods or instruments and the same testing conditions [6]. This includes intra‐rater reliability.
- Inter‐method reliability assesses the degree to which test scores are consistent when there is a variation in the methods or instruments used. This allows inter‐rater reliability to be ruled out. When dealing with forms, it may be termed parallel‐forms reliability [6].
- Internal consistency reliability, assesses the consistency of results across items within a test [6].
A test that is not perfectly reliable cannot be perfectly valid, either as a means of measuring attributes of a person or as a means of predicting scores on a criterion. While a reliable test may provide useful valid information, a test that is not reliable cannot be valid [7].
1.1.2 General Model
Recognizing that, in practice, testing measures are never perfectly consistent, theories of statistical test reliability have been developed to estimate the effects of inconsistency on the accuracy of measurement. The starting point for almost all theories of test reliability is the concept that test scores reflect the influence of two types of factors [7]:
- Factors that contribute to consistency—stable characteristics of the individual or the attribute that one is trying to measure.
- Factors that contribute to inconsistency—features of the individual or the situation that can affect test scores but have nothing to do with the attribute being measured.
These factors include [7]:
- Temporary, but general, characteristics of the individual—health, fatigue, motivation, emotional strain;
- Temporary and specific characteristics of the individual—comprehension of the specific test task, specific tricks or techniques of dealing with the particular test materials, fluctuations of memory, attention or accuracy;
- Aspects of the testing situation—freedom from distractions, clarity of instructions, interaction of personality, sex, or race of examiner;
- Chance factors—luck in selection of answers by sheer guessing, momentary distractions.
1.1.3 Classical Test Theory
The goal of reliability theory is to estimate errors in measurement and to suggest ways of improving tests so that these errors are minimized. The central assumption of reliability theory is that measurement errors are essentially random. This does not mean that errors arise from random processes. For any individual, an error in measurement is not a completely random event. However, across a large number of individuals, the causes of measurement error are assumed to be so varied that measure errors act as random variables. If errors have the essential characteristics of random variables, then it is reasonable to assume that errors are equally likely to be positive or negative, and that they are not correlated with true scores or with errors on other tests.
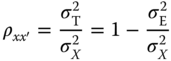
Unfortunately, there is no way to directly observe or calculate the true score, so a variety of methods are used to estimate the reliability of a test. Some examples of the methods used to estimate reliability include test–retest reliability, internal consistency reliability, and parallel‐test reliability. Each method approaches the problem of accounting for the source of error in the test somewhat differently.
1.1.4 Estimation
The goal of estimating reliability is to determine how much of the variability in test scores is due to errors in measurement and how much is due to variability in true scores. There are several strategies, including [7]:
-
Test–retest reliability method. Directly assesses the degree to which test scores are consistent from one test administration to the next. It involves:
- administering a test to a group of individuals;
- readministering the same test to the same group at some later time; and
- correlating the first set of scores with the second.
- Parallel‐forms method. The key to this method is the development of alternate test forms that are equivalent in terms of content, response processes and statistical characteristics. For example, alternate forms exist for several tests of general intelligence, and these tests are generally seen as equivalent [7].
With the parallel test model it is possible to develop two forms of a test that are equivalent, in the sense that a person's true score on form A would be identical to their true score on form B. If both forms of the test were administered to a number of people, differences between scores on form A and form B may be due to errors in measurement only [7].
This method treats the two halves of a measure as alternate forms. It provides a simple solution to the problem that the parallel‐forms method faces: the difficulty in developing alternate forms [7]. It involves:
- administering a test to a group of individuals;
- splitting the test in half;
- correlating scores on one half of the test with scores on the other half of the test.
There are many situations in which one needs to make a prediction about a product's performance before the product is in production. This means prediction is needed prior to production or warranty data being available for analysis. Many companies have product development programs that require design engineers to produce designs that will meet a certain reliability goal before the project is permitted to move on to the following phases (building prototypes, pre‐manufacturing, and full manufacturing). This is to avoid committing the business to investing significant resources to a product with unproven reliability before leaving the design stage. This is especially difficult because a new design can involve components or subsystems that have no previous testing, and have no history of being used in the field by customers. Often, they encompass totally new items and not redesigned components or subsystems of existing components which would have prior histories [7].
In other cases, companies that may not have the capabilities, resources, or time to test certain (noncrucial) components/subsystems of a system, but still need to use some estimates of the failure rate of those components to complete their system reliability analysis.
Lastly, manufacturers are often required to submit reliability predictions usually based on a specific prediction standard with their bid or proposal for a project.
As was written in Ref. [7], the following are a few advantages and disadvantages related to standards based reliability prediction.
The advantages of using standards‐based reliability prediction are:
- They can help to complete the system reliability block diagrams (RBDs) or FTAs when data for certain components/subsystems within the system are not available.
- It is sometimes accepted and/or required by government and/or industry contracts for bidding purposes.
The disadvantages of using standards‐based reliability prediction are:
- Reliance on standards that may not reflect the products actual performance.
- Although standards‐based reliability prediction addresses prediction under different usage levels and environmental conditions, these conditions may not accurately reflect the products actual application.
- Some of the standards are old and have not been updated to reflect the latest advances in technologies.
- The result from such predictions is a constant failure rate estimation that can only be used within the context of an exponential reliability model (i.e., no wearouts, no early failures). This is not necessarily accurate for all components, and certainly not for most mechanical components. In addition, certain aspects of reliability analysis, such as preventive maintenance analysis and burn‐in analysis, cannot be performed on components/subsystems that follow the exponential distribution.
So, the basic negative aspect of this approach of reliability prediction is that it is not reflective of the product's actual performance. Therefore, reliability prediction results may be very different from field results, and, as a final result, the reliability prediction will be unsuccessful.
1.1.5 Reliability Prediction for Mean Time Between Failures
Reliability prediction tools such as the ITEM ToolKit are essential when the reliability of electronic and mechanical components, systems, and projects is critical for life safety. Certain products and systems developed for commercial, military, or other applications often need absolute ensured reliability and consistent performance. However, electronics and mechanical products, systems, and components are naturally prone to eventual breakdown owing to any number of environmental variables, such as heat, stress, moisture, and moving parts. The main question is not if there will be failures, but “When?”
Reliability is a measure of the frequency of failures over time [7].
1.1.6 About Reliability Software
The reliability software modules of the ITEM ToolKit [7] provide a user‐friendly interface that allows one to construct, analyze, and display system models using the module's interactive facilities. Building hierarchies and adding new components could not be easier. ToolKit calculates the failure rates, including mean time between failures (MTBFs), associated with new components as they are added to the system, along with the overall system failure rate. Project data may be viewed via grid view and dialog view simultaneously, allowing predictions to be performed with a minimum of effort.
Each reliability prediction module is designed to analyze and calculate component, subsystem, and system failure rates in accordance with the appropriate standard. After the analysis is complete, ITEM ToolKit's integrated environment comes into its own with powerful conversion facilities to transfer data to other reliability software modules. For example, you can transfer your MIL‐217 project data to FMECA or your Bellcore project to RBD. These powerful features transfer as much of the available information as possible, saving valuable time and effort [7].
The following is an interesting statement from ReliaSoft's analysis of the current situation in reliability prediction [8]:
To obtain high product reliability, consideration of reliability issues should be integrated from the very beginning of the design phase. This leads to the concept of reliability prediction. The objective of reliability prediction is not limited to predicting whether reliability goals, such as MTBF, can be reached. It can also be used for:
- Identifying potential design weaknesses
- Evaluating the feasibility of a design
- Comparing different designs and life‐cycle costs
- Providing models statement from system reliability/availability analysis
- Aiding in business decisions such as budget allocation and scheduling
Once the product's prototype is available, lab tests can be utilized to obtain reliability predictions. Accurate prediction of the reliability of electronic products requires knowledge of the components, the design, the manufacturing process and the expected operating conditions. Several different approaches have been developed to achieve reliability prediction of electronic systems and components. Each approach has its advantages and disadvantages. Among these approaches, three main categories are often used within government and industry:
- empirical (standard bases);
- physics of failure, and;
- life testing.
The following provides an overview of all three approaches [8].
1.1.6.1 MIL‐HDBK‐217 Predictive Method
MIL‐HDBK‐217 is very well known in military and commercial industries. Version MIL‐HDBK‐217F was released in 1991 and had two revisions.
The MIL‐HDBK‐217 predictive method consists of two parts: one is known as the parts count method and the other is called the part stress method [8]. The parts count method assumes typical operating conditions of part complexity, ambient temperature, various electrical stresses, operation mode, and environment (called reference conditions). The failure rate for a part under the reference conditions is calculated as
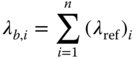
where λ ref is the failure rate under the reference conditions and i is the number of parts.
Since the parts may not operate under the reference conditions, the real operating conditions may result in failure rates different than those given by the “parts count” method. Therefore, the part stress method requires the specific part's complexity, application stresses, environmental factors, and so on. These adjustments are called Pi factors. For example, MIL‐HDBK‐217 provides many environmental conditions, expressed as π E, ranging from “ground benign” to “cannon launch.” The standard also provides multilevel quality specifications that are expressed as π Q. The failure rate for parts under specific operating conditions can be calculated as

where π S is the stress factor, π T is the temperature factor, π E is the environment factor, π Q is the quality factor, and π A is the adjustment factor.
1.1.6.2 Bellcore/Telcordia Predictive Method
Bellcore was a telecommunication research and development company that provided joint R&D and standards setting for AT&T and its co‐owners. Bellcore was not satisfied with the military handbook methods for application with their commercial products, so Bellcore designed its own reliability prediction standard for commercial telecommunication products. Later, the company was acquired by Science Applications International Corporation (SAIC) and the company's name was changed to Telcordia. Telcordia continues to revise and update the Bellcore standard. Presently, there are two updates: SR‐332 Issue 2 (September 2006) and SR‐332 Issue 3 (January 2011), both titled “Reliability prediction procedure for electronic equipment.”
The Bellcore/Telcordia standard assumes a serial model for electronic parts and it addresses failure rates at both the infant mortality stage and at the steady‐state stages utilizing Methods I, II, and III. Method I is similar to the MIL‐HDBK‐217F parts count and part stress methods, providing the generic failure rates and three part stress factors: device quality factor π Q, electrical stress factor π S, and temperature stress factor π T. Method II is based on combining Method I predictions with data from laboratory tests performed in accordance with specific SR‐332 criteria. Method III is a statistical prediction of failure rate based on field tracking data collected in accordance with specific SR‐332 criteria. In Method III, the predicted failure rate is a weighted average of the generic steady‐state failure rate and the field failure rate.
1.1.6.3 Discussion of Empirical Methods
Although empirical prediction standards have been used for many years, it is wise to use them with caution. The advantages and disadvantages of empirical methods have been discussed, and a brief summary from publications in industry, military, and academia is presented next [8].
Advantages of empirical methods:
- Easy to use, and a lot of component models exist.
- Relatively good performance as indicators of inherent reliability.
Disadvantages of empirical methods:
- Much of the data used by the traditional models is out of date.
- Failure of the components is not always due to component‐intrinsic mechanisms, but can be caused by the system design.
- The reliability prediction models are based on industry‐average values of failure rate, which are neither vendor specific nor device specific.
- It is hard to collect good‐quality field and manufacturing data, which are needed to define the adjustment factors, such as the Pi factors in MIL‐HDBK‐217.
1.1.7 Physics of Failure Methods
In contrast to empirical reliability prediction methods that are based on the statistical analysis of historical failure data, a physics of failure approach is based on the understanding of the failure mechanism and applying the physics of failure model to the data. Several popularly used models are discussed next.
1.1.7.1 Arrhenius's Law
One of the earliest acceleration models predicts how the time to failure of a system varies with temperature. This empirically based model is known as the Arrhenius equation. Generally, chemical reactions can be accelerated by increasing the system temperature. Since it is a chemical process, the aging of a capacitor (such as an electrolytic capacitor) is accelerated by increasing the operating temperature. The model takes the following form:

where L(T) is the life characteristic related to temperature, A is a scaling factor, E a is the activation energy, k is the Boltzmann constant, and T is the temperature.
1.1.7.2 Eyring and Other Models
While the Arrhenius model emphasizes the dependency of reactions on temperature, the Eyring model is commonly used for demonstrating the dependency of reactions on stress factors other than temperature, such as mechanical stress, humidity, or voltage. The standard equation for the Eyring model [8] is as follows:
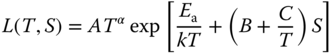
where L(T,S) is the life characteristic related to temperature and another stress, A, α, B, and C are constants, S is a stress factor other than temperature, and T is absolute temperature.
According to different physics of failure mechanisms, one more factor (i.e., stress) can be either removed or added to the standard Eyring model. Several models are similar to the standard Eyring model.
Electronic devices with aluminum or aluminum alloy with small percentages of copper and silicon metallization are subject to corrosion failures and therefore can be described with the following model [8]:

where B 0 is an arbitrary scale factor, α is equal to 0.1 to 0.15 per %RH, and f(V) is an unknown function of applied voltage, with an empirical value of 0.12–0.15.
1.1.7.3 Hot Carrier Injection Model
Hot carrier injection describes the phenomena observed in metal–oxide–semiconductor field‐effect transistors (MOSFETs) by which the carrier gains sufficient energy to be injected into the gate oxide, generate interface or bulk oxide defects, and degrade MOSFET characteristics such as threshold voltage, transconductance, and so on [8].
For n‐channel devices, the model is given by

where B is an arbitrary scale factor, I sub is the peak substrate current during stressing, N is equal to a value from 2 to 4 (typically 3), and E a is equal to −0.1 to −0.2 eV.
For p‐channel devices, the model is given by:

where B is an arbitrary scale factor, I gate is the peak gate current during stressing, M is equal to a value from 2 to 4, and E a is equal to −0.1 to −0.2 eV.
ReliaSoft's “Reliability prediction methods for electronic products” [8] states:
Since electronic products usually have a long time period of useful life (i.e., the constant line of the bathtub curve) and can often be modeled using an exponential distribution, the life characteristics in the above physics of failure models can be replaced by MTBF (i.e., the life characteristic in the exponential distribution). However, if you think your products do not exhibit a constant failure rate and therefore cannot be described by an exponential distribution, the life characteristic usually will not be the MTBF. For example, for the Weibull distribution, the life characteristic is the scale parameter eta and for the lognormal distribution, it is the log mean.
1.1.7.4 Black Model for Electromigration
Electromigration is a failure mechanism that results from the transfer of momentum from the electrons, which move in the applied electric field, to the ions, which make up the lattice of the interconnect material. The most common failure mode is “conductor open.” With the decreased structure of integrated circuits (ICs), the increased current density makes this failure mechanism very important in IC reliability.
At the end of the 1960s, J. R. Black developed an empirical model to estimate the mean time to failure (MTTF) of a wire, taking electromigration into consideration, which is now generally known as the Black model. The Black model employs external heating and increased current density and is given by

where A 0 is a constant based on the cross‐sectional area of the interconnect, J is the current density, J threshold is the threshold current density, E a is the activation energy, k is the Boltzmann constant, T is the temperature, and N is a scaling factor.
The current density J and temperature T are factors in the design process that affect electromigration. Numerous experiments with different stress conditions have been reported in the literature, where the values have been reported in the range between 2 and 3.3 for N, and 0.5 to 1.1 eV for E a. Usually, the lower the values, the more conservative the estimation.
1.1.7.5 Discussion of Physics of Failure Methods
A given electronic component will have multiple failure modes, and the component's failure rate is equal to the sum of the failure rates of all modes (i.e., humidity, voltage, temperature, thermal cycling, and so on). The authors of this method propose that the system's failure rate is equal to the sum of the failure rates of the components involved. In using the aforementioned models, the model parameters can be determined from the design specifications or operating conditions. If the parameters cannot be determined without conducting a test, the failure data obtained from the test can be used to get the model parameters. Software products such as ReliaSoft's ALTA can help analyze the failure data; for example, to analyze the Arrhenius model. For this example, the life of an electronic component is considered to be affected by temperature. The component is tested under temperatures of 406, 416, and 426 K. The usage temperature level is 400 K. The Arrhenius model and the Weibull distribution are used to analyze the failure data in ALTA.
Advantages of physics of failure methods:
- Modeling of potential failure mechanisms based on the physics of failure.
- During the design process, the variability of each design parameter can be determined.
Disadvantages of physics of failure methods:
- The testing conditions do not accurately simulate the field conditions.
- There is a need for detailed component manufacturing information, such as material, process, and design data.
- Analysis is complex and could be costly to apply.
- It is difficult (almost impossible) to assess the entire system.
Owing to these limitations, this is not generally a practical methodology.
1.1.8 Life Testing Method
As mentioned earlier, time‐to‐failure data from life testing may be incorporated into some of the empirical prediction standards (i.e., Bellcore/Telcordia Method II) and may also be necessary to estimate the parameters for some of the physics of failure models. But the term life testing method should refer specifically to a third type of approach for predicting the reliability of electronic products. With this method, a test is conducted on a sufficiently large sample of units operating under normal usage conditions. Times to failure are recorded and then analyzed with an appropriate statistical distribution in order to estimate reliability metrics such as the B10 life. This type of analysis is often referred to as life data analysis or Weibull analysis.
ReliaSoft's Weibull++ software is a tool for conducting life data analysis. As an example, suppose that an IC board is tested in the lab and the failure data are recorded. But failure data during long period of use cannot obtained, because accelerated life testing (ALT) methods are not based on accurate simulation of the field conditions.
1.1.8.1 Conclusions
In the ReliaSoft article [8], three approaches for electronic reliability prediction were discussed. The empirical (or standards based) method, which is close to the theoretical approach in practical usage, can be used in the pre‐design stage to quickly obtain a rough estimation of product reliability. The physics of failure and life testing methods can be used in both design and production stages. When using the physics of failure approach, the model parameters can be determined from design specifications or from test data. But when employing the life testing method, since the failure data, the prediction results usually are not more accurate than those from a general standard model.
For these reasons, the traditional approaches to reliability prediction are often unsuccessful when used in industrial applications.
And one more important reason is these approaches are not closely connected with the system of obtaining accurate initial information for calculating reliability prediction during any period of use.
Some of the topics covered in the ANSI/VITA 51.2 standard [9] include reliability mathematics, organization and analysis of data, reliability modeling, and system reliability evaluation techniques. Environmental factors and stresses are taken into account in computing the reliability of the components involved. The limitations of models, methods, procedures, algorithms, and programs are outlined. The treatment of maintained systems is designed to aid workers in analyzing systems with more realistic assumptions. FTA, including the most recent developments, is also extensively discussed. Examples and illustrations are included to assist the reader in solving problems in their own area of practice. These chapters provide a guided presentation of the subject matter, addressing both the difficulties expected for the beginner, while addressing the needs of the more experienced reader.
Failures have been a problem since the very first computer. Components burned out, circuits shorted or opened, solder joints failed, pins were bent, and metals reacted unfavorably when joined. These and countless other failure mechanisms have plagued the computer industry from the very first circuits to today.
As a result, computer manufacturers realize that reliability predictions are very important to the management of their product's profitability and life cycle. They employ these predictions for a variety of reasons, including those detailed in ANSI/VITA 51.2 [9]:
- Helping to assess the effect of product reliability on the maintenance activity and quantity of spare units required for acceptable field performance of any particular system. Reliability prediction can be used to establish the number of spares needed and predict the frequency of expected unit level maintenance.
- Reliability prediction reasons.
- Prediction of the reliability of electronic products requires knowledge of the components, the design, the manufacturing process, and the expected operating conditions. Once the prototype of a product is available, tests can be utilized to obtain reliability predictions. Several different approaches have been developed to predict the reliability of electronic systems and components. Among these approaches, three main categories are often used within government and industry: empirical (standards based), physics of failure, and life testing.
- Empirical prediction methods are based on models developed from statistical curve fitting of historical failure data, which may have been collected in the field, in‐house, or from manufacturers. These methods tend to present reasonable estimates of reliability for similar or slightly modified parts. Some parameters in the curve function can be modified by integrating existing engineering knowledge. The assumption is made that system or equipment failure causes are inherently linked to components whose failures are essentially independent of each other. There are many different empirical methods that have been created for specific applications.
- The physics of failure approach is based on the understanding of the failure mechanism and applying the physics of failure model to the data. Physics of failure analysis is a methodology of identifying and characterizing the physical processes and mechanisms that cause failures in electronic components. Computer models integrating deterministic formulas from physics and chemistry are the foundation of physics of failure.
While these traditional approaches provide good theoretical approaches, they are unable to reflect or account for actual reliability changes that occur during service life when usage interaction, and the effects of real‐world input, influences the product's reliability. For these reasons, it also is often not successful.
1.1.8.2 Failure of the Old Methods
Today, we find that the old methods of predicting reliability in electronics have begun to fail us. MIL‐HDBK‐217 has been the cornerstone of reliability prediction for decades. But MIL‐HDBK‐217 is rapidly becoming irrelevant and unreliable as we venture into the realm of nanometer geometry semiconductors and their failure modes. The uncertainty of the future of long established methods has many in the industry seeking alternative methods.
At the same time, on the component supplier side, semiconductor suppliers have been able to provide such substantial increases in component reliability and operational lifetimes that they are slowly beginning to drop MIL‐STD‐883B testing, and many have dropped their lines of mil‐spec parts. A major reason contributing to this is that instead of focusing on mil‐spec parts they have moved their focus to commercial‐grade parts, where the unit volumes are much higher. In recent times the purchasing power of military markets has diminished to the point where they no longer have the dominant presence and leverage. Instead, system builders took their commercial‐grade devices, sent them out to testing labs, and found that the majority of them would, in fact, operate reliably at the extended temperature ranges and environmental conditions required by the mil‐spec. In addition, field data gathered over the years has improved much of the empirical data necessary for complex algorithms for reliability prediction [10]–[14].
The European Power Supply Manufacturers Association [15] provides engineers, operations managers, and applied statisticians with both qualitative and quantitative tools for solving a variety of complex, real‐world reliability problems. There is wealth of accompanying examples and case studies [15]:
- Comprehensive coverage of assessment, prediction, and improvement at each stage of a product's life cycle.
- Clear explanations of modeling and analysis for hardware ranging from a single part to whole systems.
- Thorough coverage of test design and statistical analysis of reliability data.
- A special chapter on software reliability.
- Coverage of effective management of reliability, product support, testing, pricing, and related topics.
- Lists of sources for technical information, data, and computer programs.
- Hundreds of graphs, charts, and tables, as well as over 500 references.
- PowerPoint slides which are available from the Wiley editorial department.
Gipper [16] provides a comprehensive overview of both qualitative and quantitative aspects of reliability. Mathematical and statistical concepts related to reliability modeling and analysis are presented along with an important bibliography and a listing of resources, including journals, reliability standards, other publications, and databases. The coverage of individual topics is not always deep, but should provide a valuable reference for engineers or statistical professionals working in reliability.
There are many other publications (mostly articles and papers) that relate to the current situation in the methodological aspects of reliability prediction. In the Reliability and Maintainability Symposiums Proceedings (RAMS) alone there have been more than 100 papers published in this area. For example, RAMS 2012 published six papers. Most of them related to reliability prediction methods in software design and development.
Both physics‐based modeling and simulation and empirical reliability have been subjects of much interest in computer graphics.
The following provides the basic content of the abstracts of some of the articles in reliability prediction from the RAMS.
- Cai et al. [17] present a novel method of field reliability prediction considering environment variation and product individual dispersion. Wiener diffusion process with drift was used for degradation modeling, and a link function which presents degradation rate is introduced to model the impact of varied environments and individual dispersion. Gamma, transformed‐Gamma (T‐Gamma), and the normal distribution with different parameters are employed to model right‐skewed, left‐skewed, and symmetric stress distribution in the study case. Results show obvious differences in reliability, failure intensity, and failure rate compared with a constant stress situation and with each other. The authors indicate that properly modeled (proper distribution type and parameters) environmental stress is useful for varied environment oriented reliability prediction.
- Chigurupati et al. [18] explore the predictive abilities of a machine learning technique to improve upon the ability to predict individual component times until failure in advance of actual failure. Once failure is predicted, an impending problem can be fixed before it actually occurs. The developed algorithm was able to monitor the health of 14 hardware samples and notify us of an impending failure providing time to fix the problem before actual failure occurred.
- Wang et al. [19] deals with the concept of space radiation environment reliability for satellites and establishes a model of space radiation environment reliability prediction, which establishes the relationship among system failure rate and space radiation environment failure rate and nonspace radiation environment failure rate. It provides a method of space radiation environment reliability prediction from three aspects:
- Incorporating the space radiation environment reliability into traditional reliability prediction methods, such as FIDES and MIL‐HDBK‐217.
- Summing up the total space radiation environment reliability failure rate by summing the total hard failure rate and soft failure rate of the independent failure rates of SEE, total ionizing dose (TID), and displacement damage (DD).
- Transferring TID/DD effects into equivalent failure rate and considering single event effects by failure mechanism in the operational conditions of duty hours within calendar year. A prediction application case study has been illustrated for a small payload. The models and methods of space radiation environment reliability prediction are used with ground test data of TID and single event effects for field programmable gate arrays.
- In order to utilize the degradation data from hierarchical structure appropriately, Wang et al. first collected and classified feasible degradation data from a system and subsystems [20]. Second, they introduced the support vector machine method to model the relationship among hierarchical degradation data, and then all degradation data from subsystems are integrated and transformed to the system degradation data. Third, with this processed information, a prediction method based on Bayesian theory was proposed, and the hierarchical product's lifetime was obtained. Finally, an energy system was taken as an example to explain and verify the method in this paper; the method is also suitable for other products.
- Jakob et al. used knowledge about the occurrence of failures and knowledge of the reliability in different design stages [21]. To show the potential of this approach, the paper presents an application for an electronic braking system. In a first step, the approach presented shows investigations of the physics of failure based on the corresponding acceleration model. With knowledge of the acceleration factors, the reliability can be determined for each component of the system for each design stage. If the failure mechanisms occurring are the same for each design stage, the determined reliability of earlier design stages could be used as pre‐knowledge as well. For the calculation of the system reliability, the reliability values of all system components are brought together. In this paper, the influence of sample size, stress levels of testing, and test duration on reliability characteristics are investigated. As already noted, an electronic braking system served here as the system to be investigated. Accelerated testing was applied (i.e., testing at elevated stress levels). If pre‐knowledge is applied and the same test duration is observed, this allows for the conclusion of higher reliability levels. Alternatively, the sample size can be reduced compared with the determination of the reliability without the usage of pre‐knowledge. It is shown that the approach presented is suitable to determine the reliability of a complex system such as an electronic braking system. An important part for the determination of the acceleration factor (i.e., the ratio of the lifetime under use conditions to the lifetime under test conditions) is the knowledge of the exact field conditions. Because that is difficult in many cases, further investigations are deemed necessary.
- Today's complex designs, which have intricate interfaces and boundaries, cannot rely on the MIL‐HDBK‐217 methods to predict reliability. Kanapady and Adib [22] present a superior reliability prediction approach for design and development of projects that demand high reliability where the traditional prediction approach has failed to do the job. The reliability of a solder ball was predicted. Sensitivity analysis, which determines factors that can mitigate or eliminate the failure mode(s), was performed. Probabilistic analysis, such as the burden capability method, was employed to assess the probability of failure mode occurrences, which provides a structured approach to ranking of the failure modes, based on a combination of their probability of occurrence and severity of their effects.
- Microelectronics device reliability has been improving with every generation of technology, whereas the density of the circuits continues to double approximately every 18 months. Hava et al. [23] studied field data gathered from a large fleet of mobile communications products that were deployed over a period of 8 years in order to examine the reliability trend in the field. They extrapolated the expected failure rate for a series of microprocessors and found a significant trend whereby the circuit failure rate increases approximately half the rate of the technology, going up by approximately √2 in that same 18‐month period.
- Thaduri et al. [24] studied the introduction, functioning, and importance of a constant fraction discriminator in the nuclear field. Furthermore, the reliability and degradation mechanisms that affect the performance of the output pulse with temperature and dose rates act as input characteristics was properly explained. Accelerated testing was carried out to define the life testing of the component with respect to degradation in output transistor–transistor logic pulse amplitude. Time to failure was to be properly quantified and modeled accordingly.
- Thaduri et al. [25] also discussed several reliability prediction models for electronic components, and comparison of these methods was also illustrated. A combined methodology for comparing the cost incurred for prediction was designed and implemented with an instrumentation amplifier and a bipolar junction transistor (BJT). By using the physics of failure approach, the dominant stress parameters were selected on the basis of a research study and were subjected to both an instrumentation amplifier and a BJT. The procedure was implemented using the methodology specified in this paper and modeled the performance parameters accordingly. From the prescribed failure criteria, the MTTF was calculated for both the components. Similarly, using the 217Plus reliability prediction book, the MTTF was also calculated and compared with the prediction using physics of failure. Then, the costing implications of both the components were discussed and compared. For critical components like an instrumentation amplifier, it was concluded that though the initial cost of physics of failure prediction is too high, the total cost incurred, including the penalty costs, is lower than that of a traditional reliability prediction method. But for noncritical components like a BJT, the total cost of physics of failure approach was too high compared with a traditional approach, and hence a traditional approach was more efficient. Several other factors were also compared for both reliability prediction methods.
Much more literature on methodological approaches to reliability prediction are available.
The purpose of the MIL‐HDBK‐217F handbook [26] is to establish and maintain consistent and uniform methods for estimating the inherent reliability (i.e., the reliability of a mature design) of military electronic equipment and systems. It provides a common basis for reliability predictions during acquisition programs for military electronic systems and equipment. It also establishes a common basis for comparing and evaluating reliability predictions of related or competitive designs.
Another document worthy for discussion is the Telecordia document, Issue 4 of SR‐332 [27]. This provides all the tools needed for predicting device and unit hardware reliability, and contains important revisions to the document. The Telcordia Reliability Prediction Procedure has a long and distinguished history of use both within and outside the telecommunications industry. Issue 4 of SR‐332 provides the only hardware reliability prediction procedure developed from the input and participation of a cross‐section of major industrial companies. This lends the procedure and the predictions derived from it a high level of credibility free from the bias of any individual supplier or service provider.
Issue 4 of SR‐332 contains the following:
- Recommended methods for prediction of device and unit hardware reliability. These techniques estimate the mean failure rate in FITs for electronic equipment. This procedure also documents a recommended method for predicting serial system hardware reliability.
- Tables needed to facilitate the calculation of reliability predictions.
- Revised generic device failure rates, based mainly on new data for many components.
- An extended range of complexity for devices, and the addition of new devices.
- Revised environmental factors based on field data and experience.
- Clarification and guidance on items raised by forum participants and by frequently asked questions from users.
Lu et al. [28] describe an approach to real‐time reliability prediction, applicable to an individual product unit operating under dynamic conditions. The concept of conditional reliability estimation is extended to real‐time applications using time‐series analysis techniques to bridge the gap between physical measurement and reliability prediction. The model is based on empirical measurements is, self‐generating, and applicable to online applications. This approach has been demonstrated at the prototype level. Physical performance is measured and forecast across time to estimate reliability. Time‐series analysis is adapted to forecast performance. Exponential smoothing with a linear level and trend adaptation is applied. This procedure is computationally recursive and provides short‐term, real‐time performance forecasts that are linked directly to conditional reliability estimates. Failure clues must be present in the physical signals, and failure must be defined in terms of physical measures to accomplish this linkage. On‐line, real‐time applications of performance reliability prediction could be useful in operational control as well as predictive maintenance.
Section 8.1 in Chapter of the Engineering Statistics e‐Handbook [29] considers lifetime or repair models. As seen earlier, repairable and nonrepairable reliability population models have one or more unknown parameters. The classical statistical approach considers these parameters as fixed but unknown constants to be estimated (i.e., “guessed at”) using sample data taken randomly from the population of interest. A confidence interval for an unknown parameter is really a frequency statement about the likelihood that the numbers calculated from a sample capture the true parameter. Strictly speaking, one cannot make probability statements about the true parameter since it is fixed, not random. The Bayesian approach, on the other hand, treats these population model parameters as random, not fixed, quantities. Before looking at the current data, it uses old information, or even subjective judgments, to construct a prior distribution model for these parameters. This model expresses our starting assessment about how likely various values of the unknown parameters are. We then make use of the current data (via Bayes' formula) to revise this starting assessment, deriving what is called the posterior distribution model for the population model parameters. Parameter estimates, along with confidence intervals (known as credibility intervals), are calculated directly from the posterior distribution. Credibility intervals are legitimate probability statements about the unknown parameters, since these parameters now are considered random, not fixed.
Unfortunately, it is unlikely in most applications that data will ever exist to validate a chosen prior distribution model. But parametric Bayesian prior models are often chosen because of their flexibility and mathematical convenience. In particular, conjugate priors are a natural and popular choice of Bayesian prior distribution models.
1.1.9 Section Summary
- Section 1.1 concludes that most of the approaches considered are difficult to use successfully in practice.
- The basic cause for this is a lack of close connection to the source, which is necessary for obtaining accurate initial information that is needed for calculating changing reliability parameters during the product's life cycle.
- Three basic methods of reliability prediction were discussed:
- Empirical reliability prediction methods that are based on the statistical analysis of historical failure data models, developed from statistical curves. These methods are not considered accurate simulations of field situations and are an obstacle to obtaining accurate initial information for calculating the dynamics of changing failure (degradation) parameters during a product or technology service life.
- Physics of failure approach, which is based on the understanding of the failure mechanism and applying the physics of failure model to the data. However, one cannot obtain data for service life during the design and manufacturing stages of a new model of product/technology. Accurate initial information from the field during service life is not available during these stages of development.
- Laboratory‐based or proving ground based life testing reliability prediction, which uses ALT in the laboratory but does not accurately simulate changing parameters encountered in the field during service life of the product/technology.
- Recalls, complaints, injuries and deaths, and significant costs are direct results of these prediction failures.
- Real products rarely exhibit a constant failure rate and, therefore, cannot be accurately described by exponential, lognormal, or other theoretical distributions. Real‐life failure rates are mostly random.
- Reliability prediction is often considered as a separate issue, but, in real life, reliability prediction is an essential interacted element of a product/technology performance prediction [30].
Analysis demonstrates that the current status of product/technology methodological aspects of reliability prediction for industries such as electronic, automotive, aircraft, aerospace, off‐highway, farm machinery, and others is not very successful. The basic cause is the difficulty of obtaining accurate initial information for specific product prediction calculations during the real‐world use of the product.
Accurate prediction requires information similar to that experienced in the real world.
There are many publications on the methodological aspects of reliability prediction that commonly have similar problems; for example, see Refs [31–40].
1.2 Current Situation in Practical Reliability Prediction
There are far fewer publications that relate to the practical aspects of reliability prediction. Sometimes authors call their publications by some name indicating practical reliability prediction, but the approaches they present are not generally useful in a practical way.
The electronics community is comprised of representatives from electronics suppliers, system integrators, and the Department of Defense (DoD). The majority of the reliability work is driven by the user community that depends heavily on solid reliability data. BAE Systems, Bechtel, Boeing, General Dynamics, Harris, Lockheed Martin, Honeywell, Northrop Grumman, and Raytheon are some of the better known demand‐side contributors to the work done by the reliability community. These members have developed consensus documents to define electronics failure rate prediction methodologies and standards. Their efforts have produced a series of documents that have been ANSI and VITA ratified. In some cases, these standards provide adjustment factors to existing standards.
The reliability community addresses some of the limitations of traditional prediction practices with a series of subsidiary specifications that contain “best practices” within the industry for performing electronics failure rate predictions. The members recognize that there are many industry reliability methods, each with a custodian and a methodology of acceptable practices, to calculate electronics failure rate predictions. If additional standards are required, for use by electronics module suppliers, a new subsidiary specification will be considered by the working group.
ANSI/VITA 51.3 Qualification and Environmental Stress Screening in Support of Reliability Predictions provides information on how qualification levels and environmental stress screening may be used to influence reliability.
Although they sometimes call what are essentially empirical prediction methods “practical methods”, these approaches do not provide accurate and successful prediction during the product's service life. Let us briefly review these and some other relevant publications.
David Nicholls provides an overview in this area [41]:
- For more than 25 years, there has been a passionate dialog throughout the reliability engineering community as to the appropriate use of empirical and physics‐based reliability models and their associated benefits, limitations, and risks.
- Over its history, the Reliability Information Analysis Center has been intimately involved in this debate. It has developed models for MIL‐HDBK‐217, as well as alternative empirically based methodologies such as 217Plus. It has published books related to physics‐of‐failure modeling approaches and developed the Web‐Accessible Repository for Physics‐based Models to support the use of physics‐of‐failure approaches. In DoD‐sponsored documents it also had published ideal attributes to identify future reliability predicting methods.
- Empirical predicting methods, particularly those based on field data, provide average failure rates based on the complexities of actual environmental and operational stresses. Generally, they should be used only in the absence of actual relevant comparison data. They are frequently criticized, however, for being grossly inaccurate in prediction of actual field failure rates, and for being used and accepted primarily for verification of contractual reliability requirements.
- What should your response be (if protocol allows) if you are prohibited from using one prediction approach over another because it is claimed that, historically, those prediction methods are “inaccurate,” or they are deemed too labor intensive/cost ineffective to perform based on past experience?
- Note that the terms “predicting,” “assessment,” and “estimation” are not always distinguishable in the literature.
- A significant mistake typically made in comparing actual field reliability data with the original prediction is that the connection is lost between the root failure causes experienced in the field and the intended purpose/coverage of the reliability prediction approach. For example, MIL‐HDBK‐217 addresses only electronic and electromechanical components. Field failures whose root failure cause is traced to mechanical components, software, manufacturing deficiencies, and so on, should not be scored against a MIL‐HDBK‐217 prediction.
- Data that form the basis for either an empirical or physics‐based prediction has various factors that will influence any uncertainty in the assessments made using the data. One of the most important factors is relevancy. Relevancy is defined as the similarity between the predicted and fielded product/system architectures, complexities, technologies, and environmental/operational stresses.
- Empirical reliability prediction models based on field data inherently address all of the failure mechanisms associated with reliability in the field, either explicitly (e.g., factors based on temperature) or implicitly (generic environmental factors that “cover” all of the failure mechanisms not addressed explicitly). They do not, however, assess or consider the impact of these various mechanisms on specific failure modes, nor do they (generally) consider “end‐of‐life” issues.
- The additional insight required to ensure an objective interpretation of results for physics‐based prediction includes:
- What failure mechanisms/modes of interest are addressed by the predicting?
- What are the reliability or safety risks associated with the failure mechanisms/modes not addressed by the prediction?
- Does the prediction consider interactions between failure mechanisms (e.g., combined maximum vibration level and minimum temperature level).
As a result of the overview, Nicholls concluded:
- As the reader may have noticed, there was one question brought up in the paper that was never addressed: “How can one ensure that prediction results will not be misinterpreted or misapplied, even though all assumptions and rationale have been meticulously documented and clearly stated?”
- Unfortunately, the answer is: “You can't.” Regardless of the care taken to ensure a technically valid and supportable analysis, empirical and physics‐based predicting will always need to be justified as to why the predicted reliability does not reflect the measured reliability in the field.
From the aforementioned information we can conclude that current prediction methods in engineering are primarily related to computer science, and even there they are not entirely successful. Given this fact, how much less is known about prediction, especially accurate prediction, that relates to automotive, aerospace, aircraft, off‐highway, farm machinery, and others? We need to conclude that it is even less developed in these areas.
A fatigue life prediction method for practical engineering use was proposed by Theil [42]:
- According to this method, the influence of overload events can be taken in account.
- The validation was done using uniaxial tests carried out on metallic specimens.
It is generally accepted that during a product's service life high load cycles will occur in addition to the normally encountered operational loads. Therefore, the development of an accurate fatigue life prediction rule which takes into account overloads in the vicinity of and slightly above yield strength, with a minimal level of effort for use in practical engineering at the design stress level, would still be highly significant.
Theil's paper [42] presents a fatigue life prediction method based on an S/N curve for constant‐amplitude loading. Similarities and differences between the proposed method and the linear cumulative damage rule of Pålmgren–Miner are briefly discussed. Using the method presented, an interpretation of the Pålmgren–Miner rule from the physical point of view is given and clarified with the aid of a practical two‐block loading example problem.
Unfortunately however, statistical reliability predictions rarely correlate with field performance. The basic cause is that they are based on testing methods that incorrectly simulate the real‐world interacted conditions.
Therefore, similar to the contents of Section 1.1, current practical reliability prediction approaches cannot provide industry with with the necessary or appropriate tools to dramatically increase reliability, eliminate (or dramatically reduce) recalls, complaints, costs, and other technical and economic aspects of improved product performance.
1.3 From History of Reliability Prediction Development
The term “reliability prediction” has historically been used to denote the process of applying mathematical models and data for the purpose of estimating the field reliability of a system before empirical data are available for the system [43,44].
Jones [45] considered information on the history of reliability prediction allowing his work to be placed in context with general developments in the field. This includes the development of statistical models for lifetime prediction using early life data (i.e., prognostics), the use of nonconstant failure rates for reliability prediction, the use of neural networks for reliability prediction, the use of artificial intelligence systems to support reliability engineers' decision‐making, the use of a holistic approach to reliability, the use of complex discrete events simulation to model equipment availability, the demonstration of the weaknesses of classical reliability prediction, an understanding of the basic behavior of no fault founds, the development of a parametric drift model, the identification of the use of a reliability database to improve the reliability of systems, and an understanding of the issues that surround the use of new reliability metrics in the aerospace industry.
During World War II, electronic tubes were by far the most unreliable component used in electronic systems. This observation led to various studies and ad hoc groups whose purpose was to identify ways that electronic tube reliability, and the reliability of the systems in which they operated, could be improved. One group in the early 1950s concluded that:
- There needed to be better reliability‐data collected from the field.
- Better components needed to be developed.
- Quantitative reliability requirements needed to be established.
- Reliability needed to be verified by test before full‐scale production.
The specification requirement to have quantitative reliability requirements in turn led to the need to have a means of estimating reliability before the equipment is built and tested so that the probability of achieving its reliability goal could be estimated. This was the beginning of reliability prediction.
Then, in the 1960s, the first version of US MH‐217 was published by the US Navy. This document became the standard by which reliability predictions were performed. Other sources of failure rates prediction gradually disappeared. These early sources of failure‐rate predicting often included design guidance on the reliable application of electronic components.
In the early 1970s, the responsibility for preparing MH‐217 was transferred to the Rome Air Development Center, who published revision B in 1974. While this MH‐217 update reflected the technology at that time, there were few other efforts to change the manner in which predicting was performed. And these efforts were criticized by the user community as being too complex, too costly, and unrealistic.
While MH‐217 was updated several times, in the 1980s other agencies were developing reliability predicting models unique to their industries. For example, the SAE Reliability Standard Committee developed a set of models specific to automotive electronics. The SAE committee did this because it was their belief that there were no existing prediction methodologies that applied to the specific quality levels and environments appropriate for automotive applications.
The Bellcore reliability‐prediction standard is another example of a specific industry developing methodologies for their unique conditions and equipment. But regardless of the developed methodology, the conflict between the usability of a model and its accuracy has always been a difficult compromise.
In the 1990s, much of the literature on reliability prediction centered around whether the reliability discipline should focus on physics‐of‐failure‐based or empirically based models (such as MH‐217) for the qualification of reliability.
Another key development in reliability prediction related to the effects of acquisition reform, which overhauled the military standardization process. These reforms in turn led to a list of standardization documents that required priority action, because they were identified as barriers to commercial acquisition processes, as well as major cost drivers in defense acquisitions.
The premise of traditional methods, such as MH‐217, is that the failure rate is primarily determined by components comprising the system. The prediction methodologies that were developed toward the end of the 1990s had the following advantages:
- they used all available information to form the best estimate of field reliability;
- they were tailorable;
- they had quantifiable statistical‐confidence bounds;
- they had sensitivity to the predominant system‐reliability drivers.
During this time, some reliability professionals believed that reliability modeling should focus more on physics‐of‐failure models to replace the traditional empirical models. Physics‐of‐failure models attempt to model failure mechanisms deterministically, as opposed to the traditional approach of using models based on empirical data.
Physics‐of‐failure techniques can be effective for estimating lifetimes due to specific failure mechanisms. These techniques are useful for ensuring that there are no quantifiable failure mechanisms that will occur in a given time period. However, many of the arguments that physics‐of‐failure proponents use are based on erroneous assumptions regarding empirically based reliability prediction. The fact that a failure rate can be predicted for a given part under a specific set of conditions does not imply that a failure rate is an inherent quality of a part.
Rather, the probability of failure is a complex interaction between the defect density, defect severity, and stresses incurred in operation. Failure rates predicted using empirical models are therefore typical failure rates and represent typical defect rates, design, and use conditions.
Therefore, there is a tradeoff between the model's usability and its required level of detailed data. This highlights the fact that the purpose of a reliability prediction must be clearly understood before a methodology is chosen.
From the foregoing we can conclude that current prediction methods in engineering mostly relate to computer science, and even they are not very successful. And as relates to prediction (especially successful prediction) of automotive, aircraft, off‐highway, farm machinery, and others, we need to accept that prediction methods are even less developed.
A similar conclusion was made by Wong [46]:
Inaccurate reliability predictions could lead to disasters such as in the case of the U.S. Space Shuttle failure. The question is: ‘what is wrong with the existing reliability prediction methods?’ This paper examines the methods for predicting reliability of electronics. Based on information in the literature the measured vs predicted reliability could be as far apart as five to twenty times. Reliability calculated using the five most commonly used handbooks showed that there could be a 100 times variation. The root cause for the prediction inaccuracy is that many of the first‐order effect factors are not explicitly included in the prediction methods. These factors include thermal cycling, temperature change rate, mechanical shock, vibration, power on/off, supplier quality difference, reliability improvement with respect to calendar years, and ageing. As indicated in the data provided in this paper, any one of these factors neglected could cause a variation in the predicted reliability by several times. The reliability vs ageing‐hour curve showed that there was a 10 times change in reliability from 1000 ageing‐hours to 10,000 ageing‐hours. Therefore, in order to increase the accuracy of reliability prediction the factors must be incorporated into the prediction methods.
1.4 Why Reliability Prediction is Not Effectively Utilized in Industry
As one can see from Figure 1.1, reliability is a result of many interacting components which influence the product's performance. Therefore, one needs to understand that, if we consider reliability separately, it is different from that in the real‐life situation. Reliability prediction is only one aspect that is a result of the interacted product performance in real life (i.e., only one step of product/technology performance). Klyatis [30] gives full consideration of product performance prediction.

Figure 1.1 Reliability as one from interacted performance components in the real world.
As was previously discussed, there are many methodological approaches to different aspects of engineering prediction; these include Refs [47–59], but there are many other publications on the subject.
The problems remain:
- How can one obtain common methodological (strategic and tactical) aspects of interacted components performance for successful prediction? Reliability is only one of many interacted factors of a product's or a technology's performance (Figure 1.1).
- How does one obtain accurate initial information necessary for each particular product's successful performance prediction, including reliability, safety, durability, life cycle cost, and others?
In order to solve these problems, one needs to understand the basic causes of why the approaches used until now cannot solve problems of successfully predicting reliability.
One frequently encountered cause is that the management structure of many large and middle‐size companies is hierarchical, with managerial responsibilities that provide no, or inadequate, interconnections or interactions with other areas of the organization, or with outside entities supplying components or services to their companies.
Too often this leads to parochial thinking and inadequate consideration of how other sections of their organization influence their product's effectiveness. Figure 1.2 demonstrates sectors of responsibility of four vice presidents (1, 2, 3, 4) in a large organization. Each vice‐president's sector of responsibility consists of some subsectors, shown as subsectors 3a, 3b, and 3c, each with a corresponding responsible technical director, or some similar title (example in Figure 1.2). These subsector directors do not communicate enough with each other, because each sub‐director's responsibility relates to their particular subsector only. But their work interacts and influences the final reliability of the product.

Figure 1.2 Common scheme of company's vice‐president's sectors of responsibility. 1: one vice‐president's area; 2: second vice‐president's area; 3: third vice‐president's area; 4: fourth vice‐president's area; 3a: area of responsibilities of director of first department; 3b: area of responsibilities of director of second department; 3c: area of responsibilities of director of third department.
Let us consider some examples from author's practice. After reading author's publications, Mr. Takashi Shibayama, Vice President of Jatco Ltd (Japan) (design and manufacturing for automobile transmissions), indicated that he was very interested in implementing these practices at Jatco Ltd. Mr. Shibayama came to the SAE World Congress bringing his copy of author's book Accelerated Reliability and Durability Testing Technology, published by Wiley, which he had studied. After discussion with Dr. Klyatis, Mr. Shibayama and Jatco's engineers and managers returned to Japan and asked by e‐mail if I could meet with Nissan management. It was agreed that a meeting would be scheduled during the next SAE World Congress in Detroit. This meeting would be attended by leaders in the Powertrain Engineering Division at Nissan. Mr. Shibayama indicated these people would all be the expert leaders in Nissan reporting directly to the highest levels in Nissan.
One participant was from the Engine Department, and another from the Drive Train Department, one was the engineering director involved directly in human factor problems, and another the engineering director in engine problems. They first attended author's presentation at the SAE 2013 World Congress, Technical Session IDM300 Trends in Development Accelerated Reliability and Durability Testing, as well as author's “Chat with the Expert” session. The company's personnel had studied his book, Accelerated Reliability and Durability Testing Technology, prior to the meeting. During the meeting, they asked if he would help them to improve each of their separate areas for reliability, and he replied that he could not. The reason for this answer was that each of them was responsible for their specific area and they did not interact with the other areas of Nissan's engineering. He said that all sectors and components of the vehicle interact and are interconnected, and if we consider each component separately then you could not hope to obtain a successful improvement in prediction. He pointed out that page 65 in his book emphasized the need for solving reliability issues in a complex product, and that as long as each area of the business worked independently, overall product reliability prediction could not be improved.
From discussions with other industrial companies' managements, as well as reviewing their work, it became evident that similar situations are prevalent in other areas of industry, including, for example, the aircraft industry.

Figure 1.3 The reasons why accelerated stress testing cannot provide information for successful reliability prediction.
Figure 1.3 is provided as an aid in understanding why the current discussions in Sections 1.1 and 1.2 fail to provide accurate information for successful reliability prediction. A short description of the basic causes depicted in Figure 1.3 follows:
- Reliability and durability evaluation results are usually provided directly after stress testing either in the laboratory or from proving grounds testing. This evaluation only relates to the test conditions (the laboratory or proving ground testing). But in order to know the test subject's reliability or durability in actual use, the laboratory or proving ground testing results are not adequate, as field use normally entails probabilistic, random (often nonstationary) characteristics that require more complicated methods than evaluation based on laboratory (with simple simulation of the field) or proving ground test protocols. But, this more complex methodology is seldom used. As a result, simpler evaluation methods are used, but these are not reliable predictors.
- Typical testing is performed for several separate parameters, such as vibration or temperature, with allowances possibly including a few others. But in real‐world operation there are many other factors influencing or affecting the test subject. Temperature, humidity, air pollution (mechanical and chemical), radiation (visible, ultraviolet, and infrared), air fluctuation, features of the road (type of road, profile, density, etc.), speed of movement, input voltage, electrostatic discharge, and other factors may be present in different combinations. If laboratory or proving grounds simulations use only several of the multi‐environmental real‐world input influences described here, this ignores what may well be significant interactions between different factors that will influence reliability and durability. This is one reason why current accelerated stress testing fails to accurately predict the reliability and durability of the product, whether it be components or the completed product in the field.
- Often, companies' suppliers use only components (details) and assemblies (units) stress testing, ignoring the interconnections between these components and assemblies. Therefore, the stress testing results are different from the test subject's results in the real world. These results cannot help to predict accurately the reliability and durability of the product in the field.
- A basic reason for many product recalls is inaccurate simulation and mistakes in using stress testing results, which lead to inaccurate prediction of a product's reliability. The result is that an organization's profit is reduced from that which was projected or potentially could have been achieved. As Kanapady and Adib noted [22], “Money was saved years earlier by gambling with a substandard reliability program, but the short‐term gain was not a good long‐term investment.”
- In an attempt to compensate for unknown field factors, companies sometimes use accelerated stress testing with loads greater than maximum field loads. This alters the physics‐of‐degradation or the chemistry‐of‐degradation process obtained in actual field use. As a result, the time and character to failures, as well as the number and cost of failures, during this testing can be different from the failures in the field situation.
- As each failure mechanism responds to stress differently, and each component of the product has several different failure mechanisms, using accelerated test data plus a single acceleration factor can result in a time between failures (MTBF) estimate that is erroneous and misleading [37].
- There is no standard stress stimulus portfolio. Because of the vast diversity of products, each product and program will have differences. This is often forgotten.
- Reliability assumptions based on statistically determined sample sizes are often invalid, because the samples rarely are truly random representations of production parts.
- Often, the parameters used for field loading simulation for stress testing are not based on the truly representative region, and do not represents all areas (including climatic) of the product's use in the field.
- Some accelerated testing uses simulation at constant stress, or step stress, or cycling stress that contradicts the real‐world situation, where loading has a random stress nature.
- As Wong noted [46], inaccurate reliability predictions could lead to disasters, such as in the case of the US Space Shuttle failure. The question is: “What is wrong with the existing reliability prediction methods?” This textbook answers this question.
These are some of the reasons, why current accelerated stress testing does not help accurately predict reliability and durability. But these limitations can be reduced or eliminated by switching to ART and ADT. Descriptions of these types of testing can be found in the literature [30,60–66]. These publications provide guidance on how to accurately simulate the field situation for obtaining initial information for accurate reliability development and prediction.
For successful ART/ADT technology implementation, a multidisciplinary team will be needed to manage and engineer the application of this technology to a particular product. The team should include, as a minimum, the following:
- A team leader who is both a high‐level manager and who also understands the strategy of this technology. The team leader must understand the principles of accurate simulation of the field situation, and what other professional disciplines need to be included in the team.
- A program manager to act as a guide throughout the process and who can remove any barriers that prevent the team from succeeding. The program manager must also be knowledgeable in the design and technology of both the product and the testing.
- Engineering resources to actually perform much of the testing. This includes selection of appropriate candidate test units, failure analysis, chemical problems solution in simulation, physical problems solution in simulation, prediction methodology, system of control development, design, diagnostic, and corrective action for mechanical, electrical, hydraulic, and so on, as well as both hardware and software development and implementation.
The team must work closely with those departments that are responsible for design, manufacturing, marketing, and selling the product.
References
- 1 O'Connor P, Kleyner A. (2012). Practical Reliability Engineering, 5th edition. John Wiley & Sons.
- 2 Naval Surface Warfare Center, Carderock Division. (2011). Handbook of Reliability Prediction Procedures for Mechanical Equipment. Logistic Technology Support, Carderockdiv, NSWC‐10. West Naval Surface Warfare Center, Carderock Division, Bethesda, MD.
- 3 Atiyeh C, Blackwell R. (2016). Massive Takata airbag recall: everything you need to know, including full list of affected vehicles. Update: December 29. Car and Driver. https://blog.caranddriver.com/massive‐takata‐airbag‐recall‐everything‐you‐need‐to‐know‐including‐full‐list‐of‐affected‐vehicles/ (accessed January 18, 2018).
- 4 National Council on Measurement in Education. (2017). Glossary of important assessment and measurement terms. http://www.ncme.org/ncme/NCME/Resource_Center/Glossary/NCME/Resource_Center/Glossary1.aspx?hkey=4bb87415‐44dc‐4088‐9ed9‐e8515326a061#anchorR (accessed January 18, 2018).
- 5 Carlson NR. Miller HL Jr, Heth DS, Donahoe JW, Martin GN. (2009). Psychology: The Science of Behaviour, 4th Canadian edn. Pearson, Toronto.
- 6 Web Center for Social Research Methods. (2006). Types of reliability, in The Research Methods Knowledge Base. https://www.socialresearchmethods.net/kb/reltypes.php (accessed January 18, 2018).
- 7 Weibull.com (2005). Standards based reliability prediction: applicability and usage to augment RBDs. Part I: introduction to standards based reliability prediction and lambda predict. Reliability HotWire Issue 50 (April). http://www.weibull.com/hotwire/issue50/hottopics50.htm (accessed January 18, 2018).
- 8 ReliaSoft. Reliability prediction methods for electronic products. Reliability EDGE 9(1). http://www.reliasoft.com/pubs/reliabilityedge_v9i1.pdf (accessed January 18, 2018).
- 9 ANSI/VITA 51.2 (2016). Physics of Failure Reliability Predictions.
- 10 Blischke WR, Prabhakar Murthy DN. (2000). Reliability: Modeling, Prediction, and Optimization. John Wiley & Sons.
- 11 Wiley Online Library. (2000). Short Book Reviews, 20(3).
- 12 Misra KB. (1992). Reliability Analysis and Prediction, Volume 15. A Methodology Oriented Treatment. Elsevier Science.
- 13 Jones TL (2010). Handbook of Reliability Prediction Procedures for Mechanical Equipment. Naval Surface Warfare Center, Carderock Division.
- 14 An YH, Draughn RA. (1999). Mechanical Testing of Bone–Implant Interface. CRC Press.
- 15 European Power Supply Manufacturers Association. (2005). Guidelines to understanding reliability prediction. http://wwwepsma.org/MTBF%20Report_24%20June%202005.pdf (accessed January 18, 2018).
- 16 Gipper J. (2014). Choice of Reliability Prediction Methods. http://vita.mil‐embedded.com/articles/choice‐reliability‐prediction‐methods/ (accessed February 2, 2018).
- 17 Cai Y‐K, Wei D, Ma X‐B, Zhao Y. Reliability prediction method with field environment variation. In 2015 Annual Reliability and Maintainability Symposium (RAMS). IEEE Press, pp. 1–7.
- 18 Chigurupati A, Thibaux R, Lassar N. (2016). Predicting hardware failure using machine learning. In 2016 Annual Reliability and Maintainability Symposium (RAMS). IEEE Press, pp. 1–6.
- 19 Wang Q, Chen D, Bai H. (2016). A method of space radiation environment reliability prediction. In 2016 Annual Reliability and Maintainability Symposium (RAMS). IEEE Press, pp. 1–6.
- 20 Wang L, Zhao X, Wang X, Mu M. (2016). A lifetime prediction method with hierarchical degradation data. In 2016 Annual Reliability and Maintainability Symposium (RAMS). IEEE Press, pp. 1–6.
- 21 Jakob F, Schweizer V, Bertsche B, Dobry A. (2014). Comprehensive approach for the reliability prediction of complex systems. In 2014 Reliability and Maintainability Symposium. IEEE Press, pp. 1–6.
- 22 Kanapady R, Adib R. Superior reliability prediction in design and development phase. In 2013 Proceedings Annual Reliability and Maintainability Symposium (RAMS). IEEE Press, pp. 1–6.
- 23 Hava A, Qin J, Bernstein JB, Bo Y. Integrated circuit reliability prediction based on physics‐of‐failure models in conjunction with field study. In 2013 Proceedings Annual Reliability and Maintainability Symposium (RAMS). IEEE Press, pp. 1–6.
- 24 Thaduri A, Verma AK, Gopika V, Kumar U. Reliability prediction of constant fraction discriminator using modified PoF approach. In 2013 Proceedings Annual Reliability and Maintainability Symposium (RAMS). IEEE Press, pp. 1–7.
- 25 Thaduri A, Verma AK, Kumar U. Comparison of reliability prediction methods using life cycle cost analysis. In 2013 Proceedings Annual Reliability and Maintainability Symposium (RAMS). IEEE Press, pp. 1–7.
- 26 DAU. (1995). MIL‐HDBK‐217F (Notice 2). Military Handbook: Reliability Prediction of Electronic Equipment. Department of Defense, Washington, DC.
- 27 Telecordia. (2016). SR‐332, Issue 4, Reliability Prediction Procedure for Electronic Equipment.
- 28 Lu H, Kolarik WJ, Lu SS. (2001). Real‐time performance reliability prediction. IEEE Transactions on Reliability 50(4): 353–357.
- 29 NIST/SEMATECH. (2010). Assessing product reliability. In Engineering Statistics e‐Handbook. US Department of Commerce, Washington, DC, chapter 8.
- 30 Klyatis L. (2016) Successful Prediction of Product Performance: Quality, Reliability, Durability, Safety, Maintainability, Life‐Cycle Cost, Profit, and Other Components. SAE International, Warrendale, PA.
- 31 DAU. (1991). MIL‐HDBK‐217F (Notice 1). Military Handbook: Reliability Prediction of Electronic Equipment. Department of Defense, Washington, DC.
- 32 Telcordia. (2001). SR‐332, Issue 1, Reliability Prediction Procedure for Electronic Equipment.
- 33 Telcordia. (2006). SR‐332, Issue 2, Reliability Prediction Procedure for Electronic Equipment.
- 34 ITEM Software and ReliaSoft Corporation. (2015). D490 Course Notes: Introduction to Standards Based Reliability Prediction and Lambda Predict.
- 35 Foucher B, Boullie J, Meslet B, Das D. (2002). A review of reliability prediction methods for electronic devices. Microelectronics Reliability 42(8): 1155–1162.
- 36 Pecht M, Das D, Ramarkrishnan A. (2002). The IEEE standards on reliability program and reliability prediction methods for electronic equipment. Microelectronics Reliability 42: 1259–1266.
- 37 Talmor M, Arueti S. (1997). Reliability prediction: the turnover point. In Annual Reliability and Maintainability Symposium: 1997 Proceedings. IEEE Press, pp. 254–262.
- 38 Hirschmann D, Tissen D, Schroder S, de Doncker RW. (2007). Reliability prediction for inverters in hybrid electrical vehicles. IEEE Transactions on Power Electronics, 22(6): 2511–2517.
- 39 NIST Information Technology Library. https://www.itl.nist.gov.
- 40 SeMaTech International. (2000) Semiconductor Device Reliability Failure Models. www.sematech.org/docubase/document/3955axfr.pdf (accessed January 19, 2018).
- 41 Nicholls D. An objective look at predictions – ask questions, challenge answers. In 2012 Proceedings Annual Reliability and Maintainability Symposium. IEEE Press, pp. 1–6.
- 42 Theil N. (2016). Fatigue life prediction method for the practical engineering use taking in account the effect of the overload blocks. International Journal of Fatigue 90: 23–35.
- 43 Denson W. (1998). The history of reliability prediction. IEEE Transactions on Reliability 47(3‐SP, Part 2): SP‐321–SP‐328.
- 44 Klyatis L. The role of accurate simulation of real world conditions and ART/ADT technology for accurate efficiency predicting of the product/process. In SAE 2014 World Congress, paper 2014‐01‐0746.
- 45 Jones JA. (2008). Electronic reliability prediction: a study over 25 years. PhD thesis, University of Warwick.
- 46 Wong KL. (1990). What is wrong with the existing reliability prediction methods? Quality and Reliability Engineering International 6(4): 251–257.
- 47 Black AI. (1989). Bellcore system hardware reliability prediction. In Proceedings Annual Reliability and Maintainability Symposium.
- 48 Bowles JB. (1992). A survey of reliability prediction procedures for microelectronic devices. IEEE Transactions in Reliability 41: 2–12.
- 49 Chan HT, Healy JD. (1985). Bellcore reliability prediction. In Proceedings Annual Reliability and Maintainability Symposium.
- 50 Healy JD, Aridaman KJ, Bennet JM. (1999). Reliability prediction. In Proceedings Annual Reliability and Maintainability Symposium.
- 51 Leonard CT, Recht M. (1990). How failure prediction methodology affects electronic equipment design. Quality and Reliability Engineering International 6: 243–249.
- 52 Wymysłowski A. (2011). Editorial. 2010 EuroSimE international conference on thermal, mechanical and multi‐physics simulation and experiments in micro‐electronics and micro‐systems. Microelectronics Reliability 51: 1024–1025.
- 53 Kulkarni C, Biswas G, Koutsoukos X. (2010). Physics of failure models for capacitor degradation in DC–DC converters. https://c3.nasa.gov/dashlink/static/media/publication/2010_MARCON_DCDCConverter.pdf (accessed January 19, 2018).
- 54 Eaton DH, Durrant N, Huber SJ, Blish R, Lycoudes N. (2000). Knowledge‐based reliability qualification testing of silicon devices. International SEMATECH Technology Transfer # 00053958A‐XFR. http://www.sematech.org/docubase/document/3958axfr.pdf (accessed January 19, 2018).
- 55 Osterwald CR, McMahon TJ, del Cueto JA, Adelstein J, Pruett J. (2003). Accelerated stress testing of thin‐film modules with SnO2:F transparent conductors. Presented at the National Center for Photovoltaics and Solar Program Review Meeting Denver , Colorado. https://www.nrel.gov/docs/fy03osti/33567.pdf (accessed January 19, 2018).
- 56 Vassiliou P, Mettas A. (2003). Understanding accelerated life‐testing analysis. In 2003 Annual Reliability and Maintainability Symposium.
- 57 Mettas A. (2010). Modeling and analysis for multiple stress‐type accelerated life data. In 46th Reliability and Maintainability Symposium.
- 58 Dodson B, Schwab H. (2006). Accelerated Testing: A Practitioner's Guide to Accelerated and Reliability Testing. SAE International, Warrendale, PA.
- 59 Ireson WG, Combs CF Jr, Moss RY. (1996). Handbook on Reliability Engineering and Management. McGraw‐Hill.
- 60 Klyatis LM, Klyatis EL. (2006). Accelerated Quality and Reliability Solutions. Elsevier.
- 61 Klyatis LM, Klyatis EL. (2002). Successful Accelerated Testing. Mir Collection, New York.
- 62 Klyatis LM, Verbitsky D. Accelerated Reliability/Durability Testing as a Key Factor for Accelerated Development and Improvement of Product/Process Reliability, Durability, and Maintainability. SAE Paper 2010‐01‐0203. Detroit. 04/12/2010. (Also in the book SP‐2272).
- 63 Klyatis L. (2009). Specifics of accelerated reliability testing. In IEEE Workshop Accelerated Stress Testing. Reliability (ASTR 2009) [CD], October 7–9, Jersey City.
- 64 Klyatis L, Vaysman A. (2007/2008). Accurate simulation of human factors and reliability, maintainability, and supportability solutions. The Journal of Reliability, Maintainability, Supportability in Systems Engineering (Winter).
- 65 Klyatis L. (2006). Elimination of the basic reasons for inaccurate RMS predictions. In A Governmental–Industry Conference “RMS in A Systems Engineering Environment”, DAU‐West, San Diego, CA, October 11–12.
- 66 Klyatis LM. (2012). Accelerated Reliability and Durability Testing Technology. John Wiley & Sons, Inc., Hoboken, NJ.
Exercises
- 1.1 List three currently used traditional methods of reliability prediction.
- 1.2 Briefly describe the concept of the basic methods in Example 1.1.
- 1.3 Why are these methods mostly theoretical?
- 1.4 Why do most publications in reliability prediction relate to electronics?
- 1.5 Why are most approaches to reliability prediction of a theoretical nature?
- 1.6 What is the description of classical test theory?
- 1.7 What is the basic approach of the Bellcore/Telecordia prediction method?
- 1.8 What is the basic approach of the MIL‐HDBK‐17 predictive method?
- 1.9 What is the basic approach of the ReliaSoft analysis in reliability prediction?
- 1.10 Describe some of the advantages and disadvantages of empirical methods of reliability prediction.
- 1.11 Describe the basic concept of the physics‐of‐failure method of reliability prediction.
- 1.12 What factors does the Black model for electromigration in electronic products add to reliability prediction modeling?
- 1.13 What is the basic content of the reliability software modules of the ITEM Toolkit?
- 1.14 What is the background for the reliability prediction as used by Bellcore for hardware and software?
- 1.15 What are some of the software and hardware prediction procedures used by Bellcore?
- 1.16 What procedures are used when employing the Bellcore reliability prediction procedure?
- 1.17 What problems are encountered with attempts to predict product reliability of mechanical systems using the Handbook of Reliability Prediction Procedures of Mechanical Equipment?
- 1.18 What is the real cause of many recalls?
- 1.19 What are the basic methods of failure analysis?
- 1.20 Give a short description of the methods you gave in Exercise 1.19.
- 1.21 What are the general classes of reliability estimates?
- 1.22 What are some of the major factors in general model reliability prediction?
- 1.23 What are the basic strategies of estimating reliability methods?
- 1.24 Describe some of the advantages and disadvantages of using standards‐based reliability prediction.
- 1.25 Describe some of the advantages and disadvantages of using the physics‐of‐failure methods.
- 1.26 What is the reliability factor projected by the life testing method?
- 1.27 Why are traditional approaches to reliability prediction not successful in industrial practice?
- 1.28 Why should accurate reliability prediction be so important to a company's management?
- 1.29 Give some of the reasons traditional methods of reliability prediction in electronics have not been successful?
- 1.30 Provide a short overview of both qualitative and quantitative aspects of reliability, and their differences.
- 1.31 Provide a short synopsis of any nine of the articles on reliability prediction from the Reliability and Maintainability Symposium (RAMS) Proceedings that have been discussed in this chapter.
- 1.32 What are some of the key elements of the Telecordia reliability prediction procedure?
- 1.33 What is the basic meaning of the Bayesian approach to reliability prediction?
- 1.34 List several of the basic causes for why traditional solutions using theoretical aspects of reliability prediction are not successful in industrial applications of reliability prediction.
- 1.35 What is David Nicholls's key conclusion in his published overview of reliability prediction methods?
- 1.36 Why is fatigue life not an accurate prediction method for successful reliability prediction?
- 1.37 Describe the basic history of reliability prediction methods.
- 1.38 Why are most traditional prediction methods related to computer science and manufacture?
- 1.39 What is the problem with using separate testing aspects to make engineering predictions?
- 1.40 Why are most presently used approaches failing to produce successful product reliability predictions?
- 1.41 Describe some of the performance components that interact and affect reliability.
- 1.42 Why does currently used accelerated stress testing not obtain accurate needed information for successful reliability prediction? Describe some of these causes and their potential effects on prediction.