
Chapter 4
Testing
There are few topics in the software development world more polarizing than testing. Almost everybody agrees that testing software is a necessary activity, and to develop software professionally without testing would be irresponsible. In some communities such as the Ruby on Rails community, they advocate test driven development, or TDD, and due to their heavy focus on testing they have pioneered and inspired many testing frameworks and techniques.
Some people may get the impression that many in the Clojure community are not serious about testing, or even flat out anti-testing; however, nothing could be further from the truth. Many of the maintainers and developers in the community are very much in favor of testing, and they feel it would be irresponsible to deliver software without quality tests proving that your software does as it intends.
No amount of testing can make up for not being able to reason about your code. Having tests alone doesn't mean that you are safe from defects and able to confidently make changes to your code. You must first have a deep understanding of what constitutes a good test for your particular problem.
This chapter covers the basics of testing Clojure code using the clojure.test framework. The chapter also details examples that are more difficult and investigates some common testing strategies, such as how to handle external dependencies and things outside of your control to make your tests more deterministic.
The chapter then moves on to the topic of how to measure code quality and identify areas of concern, so that you can help reduce technical debt. You will also measure your test coverage using the cloverage plugin, run static analysis against your code using the kibit plugin, and identify low hanging fruit using the bikeshed plugin. You will also learn how to keep a close eye on the dependencies of your project and make sure they're up to date using lein-deps and lein-ancient.
Finally, because we realize that there are other alternatives out there besides clojure.test, this chapter takes a quick survey of other testing tools available for Clojure. You'll also examine frameworks such as expectations, frameworks that are inspired by the popular testing frameworks from the Ruby world such as speclj, and frameworks such as cucumber that have been ported to the JVM and have excellent Clojure support.
TESTING BASICS WITH CLOJURE.TEST
When it comes to testing in Clojure there are many choices you can make, but the de facto standard seems to be the clojure.test library, and for good reasons. It is the testing library that is included with the Clojure runtime itself, meaning that you need to just have Clojure installed in order to make use of it. It's also simple in its API, meaning that you can learn what you need to know very quickly. Don't let its simplicity fool you though; there is a lot of depth to this library, which supports various styles of testing.
At the heart of the library you'll find the is macro. This seemingly simple construct is what allows you to make assertions about any expression you would like. Just keep in mind that the expression itself is evaluated according to Clojure's rules for determining truthiness that was discussed earlier in Chapter 1. An example of how to use this macro is shown here:
user> (require '[clojure.test :refer :all])
nil
user> (is (= 4 (+ 2 2)))
true
user> (is (= 4 (+ 2 2 3)))
FAIL in clojure.lang.PersistentList$EmptyList@1 (form-init2032220466808583016.clj:1)
expected: (= 4 (+ 2 2 3))
actual: (not (= 4 7))
false
user>You may also specify an optional second argument to the is macro providing a documentation string like the following:
(is (= 3 (+ 1 1)) "Only for large values of 1")This will include the message in the test output report if this test fails.
There are basically two ways to write tests using the clojure.test library. The first is to use the with-test macro and the second, more common way, is to use the deftest macro.
with-test
The with-test macro is a way to package up your tests as metadata with your function:
(with-test
(defn my-add [x y]
(+ x y))
(is (= 4 (my-add 2 2)))
(is (= 7 (my-add 3 4))))In this example, we've defined a function that will be available to call as if you didn't wrap it using the with-test macro. Evaluating the expression above will not actually run the tests. In order to run the tests, you must use the function run-tests as shown here:
user> (run-tests)
Testing user
FAIL in (my-add) (test.clj:7)
expected: (= 7 (my-add 3 5))
actual: (not (= 7 8))
Ran 1 tests containing 2 assertions.
1 failures, 0 errors.
{:test 1, :pass 1, :fail 1, :error 0, :type :summary}While it is nice to have the ability to keep the tests close to the code, you are having to pollute your namespace by requiring clojure.test inside of your production code.
deftest
A better way to write tests is to use the deftest macro. The main benefit to using deftest over with-test is that it allows you to define your tests in a separate namespace from the function you are trying to test, which will feel more familiar to people experience with testing frameworks like JUnit or RSpec. The other benefit is that when you go to package up your application and distribute it, you're not also packaging up all of your tests to distribute along with it. You can see a rewritten example of the my-add function using deftest:
(ns ch4.core-test
(:require [clojure.test :refer :all]))
(defn my-add [x y]
(+ x y))
(deftest addition
(testing
(is (= 4 (my-add 2 2)))
(is (= 7 (my-add 3 4)))))
ch4.core-test> (run-tests)
Testing ch4.core-test
Ran 1 tests containing 2 assertions.
0 failures, 0 errors.
{:test 1, :pass 2, :fail 0, :error 0, :type :summary}You can also nest the testing macro arbitrarily deep to create multiple contexts similar to a style made popular by RSpec:
(deftest addition
(testing "using let to bind x to 2"
(let [x 2]
(is (= 4 (my-add x 2)))
(is (= 7 (my-add x 5)))
(testing "and y to 3"
(let [y 3]
(is (= 5 (my-add x y)))))))
(testing "adding negative numbers"
(is (= -3 (my-add -10 7)))
(is (= 5 (my-add 10 -5)))))If you were to change the test for (is (= 5 (my-add x y))) to be incorrect, such as (is (= 6 (my-add x y))), then the test runner will simply append the strings following the testing macro to give you a context where the test is failing.
Testing ch4.core-test
FAIL in (addition) (core_test.clj:15)
using let to bind x to 2 and y to 3
expected: (= 6 (my-add x y))
actual: (not (= 6 5))
Ran 1 tests containing 5 assertions.
1 failures, 0 errors.
{:test 1, :pass 4, :fail 1, :error 0, :type :summary}As you can see in the output, the error occurs inside of the addition test, but more specifically: using let to bind x to 2 and y to 3.
are
If typing is over and over in the same testing block feels like you're violating DRY (Don't Repeat Yourself) principles, then you're in luck. There is also a macro called are, which allows you to define a template and provide concrete examples:
(deftest addition
(testing
(are [expected actual] (= expected actual)
7 (my-add 2 5)
4 (my-add 2 2)))
(testing "adding negative numbers"
(are [expected actual] (= expected actual)
5 (my-add 10 -5)
-3 (my-add -10 7))))As you can see—because the test in the is macro follows a similar pattern—you can clean it up a bit and provide a more concise definition to the test. If you later discover another example you want to test for one of these functions, you can simply add the two parameters to your list of examples, instead of having to duplicate an entire is macro.
Using Fixtures
If you're at all familiar with other testing frameworks, you may be asking yourself right now, “How do I execute setup and teardown code in my tests?” If you need to set up some sort of state before running tests, such as inserting data into a database, you need to leverage fixtures to do so. The way to define fixtures in clojure.test is to define a normal function, which takes a single argument, or a function. The body of the fixture function then performs any setup tasks that need to occur before executing the function passed to the fixture, before performing any cleanup after calling the passed function. To tell clojure.test to execute these functions around your tests, just hook them into the testing lifecycle by using the use-fixtures form as shown here:
(ns ch4.core-test
(:require [clojure.test :refer :all]
[ch4.core :refer :all]))
(defn my-add [x y]
(+ x y))
(defn my-sub [x y]
(- x y))
(deftest addition
(is (= 4 (my-add 2 2))))
(deftest subtraction
(is (= 3 (my-sub 7 4))))
(defn once-fixture [f]
(println "setup once")
(f)
(println "teardown once"))
(defn each-fixture [f]
(println "setup each")
(f)
(println "teardown each"))
(use-fixtures :each each-fixture)
(use-fixtures :once once-fixture)Fixtures that are specified with the :each keyword are run around every deftest macro defined, and fixtures configured with the :once keyword are executed only once for all tests defined. You can see the output below after running lein test.
Testing ch4.core-test
setup once
setup each
teardown each
setup each
teardown each
teardown once
Ran 2 tests containing 2 assertions.
0 failures, 0 errors.
{:test 2, :pass 2, :fail 0, :error 0, :type :summary}Notice that you only see setup once being output at the very beginning of the test execution, then teardown once being executed at the very end.
TESTING STRATEGIES
In some ways, testing in Clojure is much easier than testing in any imperative language. Because of Clojure's focus on values and immutability, many classes of tests simply fade away into obscurity. For example, in many other languages, because there are methods that are executed solely for their side effects, you have to rely on a testing construct called a spy to verify that some interaction between the objects under test happened. In Clojure, you should be concerned with the values that are returned from the functions, so you don't generally need to concern yourself with such tests.
Let's examine some of the likely scenarios that you'll encounter when testing your Clojure applications. You will use the sample code that can be found at https://github.com/backstopmedia/clojurebook. This sample application is a simple ROI (Return On Investment) calculator that interacts with the Yahoo Financial APIs in order to retrieve historical stock pricing information. It's simple enough so you don't get bogged down in too many details; however, it illustrates most of the testing and design concepts covered in the rest of this chapter. Hopefully, you'll see how much simpler testing in Clojure seems when compared to other testing ecosystems.
In an ideal world, all tests would be simple and isolated, but in the real world, you're often required to interact with some sort of external service in order to get things done. Whether you're running queries against a database, fetching some data from the file system, or calling a web service, your tests should be repeatable and not dependent on the availability of these services. In the next few sections we'll discuss strategies to help in mitigating this non-deterministic behavior.
Tests Against DB
When it comes to testing against a database, there are usually two schools of thought. The first is to start with a pristine database, then set up whatever data you'll need for the test, and once the test is done, do it all over again. One problem with this approach is that as your application gets larger, it will cause your tests to run slower and slower. The other issue is that sometimes you don't have the luxury of starting with a clean database. Finally, you may require entirely too much data to exist in the database in order to run meaningful tests, so it would be cumbersome to try and manage that.
The other option is to have each of your tests run inside a transaction, and then have that transaction automatically rolled back at the end of your test run. To illustrate, let's create a simple database and table to hold a list of stock symbols you may want to use with the sample application. Let's begin by opening up the REPL by typing lein repl in the root of your project. First, create a variable to hold the database connection information:
user=> (def db "postgresql://localhost:5432/fincalc")
#'user/dbNow you can go ahead and create the table using the following command.
user=> (sql/db-do-commands db (sql/create-table-ddl :stocks [:symbol "varchar(10)"]
))
(0)This will create a table with a single column named symbol and mark it as being the primary key for the table. Once that is created, go ahead and populate it with some data using the following command.
(sql/insert! db :stocks {:symbol "AAPL"}
{:symbol "MSFT"}
{:symbol "YHOO"}
{:symbol "AMZN"}
{:symbol "GOOGL"}
{:symbol "FB"})Here are two simple database functions that you want to test:
(ns fincalc.db
(:require [clojure.java.jdbc :as sql]))
(defn get-symbols [db-spec]
(map :symbol (sql/query db-spec ["select * from stocks"])))
(defn add-symbol [db-spec sym]
(sql/insert! db-spec :stocks {:symbol sym}))Now let's take a look at the code for the test.
(ns fincalc.db-test
(:require [clojure.test :refer :all]
[clojure.java.jdbc :as sql]
[fincalc.db :refer :all]))
(declare ∧:dynamic *txn*)
(def db "postgresql://localhost:5432/fincalc")
(use-fixtures :each
(fn [f]
(sql/with-db-transaction
[transaction db]
(sql/db-set-rollback-only! transaction)
(binding [*txn* transaction] (f)))))
(deftest retrieve-all-stocks
(testing
(is (some #{"AAPL"} (get-symbols *txn*)))
(is (some #{"YHOO"} (get-symbols *txn*)))))
(deftest insert-new-symbol
(testing
(add-symbol *txn* "NOK")
(is (some #{"NOK"} (get-symbols *txn*)))))
(deftest inserted-symbol-rolled-back
(testing
(is (not (some #{"NOK"} (get-symbols *txn*))))))In this example, you can see that you can leverage the use-fixtures functionality provided by clojure.test. This fixture is initiating a transaction, then immediately marking it as db-set-rollback-only!. This ensures that the transaction is rolled back regardless of what happens in the test function. This will help ensure that the tests are good citizens, and that you don't leave the database in an inconsistent state. As you can see in the insert-new-symbol test, the new stock symbol “NOK” is added to the database, so when calling get-symbols you can see that it exists in the list of stocks. In the very next test, however, you'll check to see if it exists in the table to make sure the previous insert has indeed been rolled back.
Testing Ring Handlers
When developing web apps in Clojure using Ring, your handlers are simple functions. This means that you can test them as you would any other function. For example, if you want to test the /api/stocks endpoint in the sample application that returns a list of stock symbols stored in the database as a JSON array, you can write a test like the one here, which you can find in the test/fincalc/api_test.clj file:
(ns fincalc.api-test
(:require [fincalc.api :refer :all]
[cheshire.core :as json]
[clojure.test :refer :all]))
(deftest get-all-stocks
(testing
(is (some #{"AAPL"} (json/parse-string (all-stocks))))))As you can see, you can test the all-stocks function as if it were any normal function, which it really is. Testing your Ring handlers as simple functions will only get you so far. This does nothing to ensure that your URL mappings and request parameter bindings are behaving as expected. It also does not allow you to test other things such as HTTP response code, headers, or other things about the actual response. To better enable this level of testing you can leverage the ring-mock library. Rewrite the above test to be a bit better:
(ns fincalc.api-test
(:require [fincalc.handler :refer [app]]
[fincalc.api :refer :all]
[cheshire.core :as json]
[clojure.test :refer :all]
[ring.mock.request :as mock]))
(deftest get-all-stocks
(testing
(is (some #{"AAPL"} (json/parse-string (all-stocks))))))
(deftest get-all-stocks-ring-mock
(let [response (app (mock/request :get "/api/stocks"))]
(is (= (:status response) 200))
(is (some #{"AAPL"} (json/parse-string (:body response))))))The ring-mock library allows you to construct mock HTTP requests to pass to your application object you've defined in the src/fincalc/handler.clj file, as if the servlet container were making a real request. While the ring-mock library is nice, it does have its limitations. If you need to test complex interactions, or things that rely on some session state, you'll have a hard time using the ring-mock library alone. To allow this level of testing, there is another library you can use called the peridot (https://github.com/xeqi/peridot) library. Peridot is a testing library that is based on the Rack::Test suite from Ruby.
Not only does Peridot allow you to test your handlers by calling their endpoints, it also allows you to test complex interactions across multiple requests, because it maintains cookies and sessions for you across requests. It manages to do this by use of the threading macro ->, which it's designed around. This means that you can do things like authenticate in one request, then call a secured endpoint without having to mock or do devious things to simulate an authenticated state.
To illustrate how to use the Peridot library, let's create a simple example. Here is a sample definition of a simple Ring handler:
(ns simple-api.handler
(:require [compojure.core :refer :all]
[compojure.route :as route]
[ring.middleware.session :as session]
[ring.middleware.defaults :refer [wrap-defaults site-defaults]]))
(defn login [req]
(let [user (get-in req [:params :user])
session (get-in req [:session])]
{:body "Success"
:session (assoc session :user user)}))
(defn say-hello [{session :session}]
(if (:user session)
{:body (str "Hello, " (:user session))}
{:body "Hello World"}))
(defroutes app-routes
(GET "/" req say-hello)
(POST "/login" req login)
(route/not-found "Not Found"))
(def app
(-> app-routes session/wrap-session))Here are two very simple endpoints. The first is the /login endpoint, which is simply going to store a user in the session. The second endpoint is the /, which will return a generic Hello World if no user is stored in the session, and a more personalized one if there is. Here is the test code showing how to leverage Peridot:
(ns simple-api.handler-test
(:require [clojure.test :refer :all]
[peridot.core :refer :all]
[simple-api.handler :refer :all]))
(deftest test-app
(testing "main route logged in user"
(let [response (:response (-> (session app)
(request "/login"
:request-method :post
:params {:user "Jeremy"})
(request "/")))]
(is (= (:status response) 200))
(is (= (:body response) "Hello World"))))
(testing "main route"
(let [response (:response (-> (session app)
(request "/")))]
(is (= (:status response) 200))
(is (= (:body response) "Hello World")))))As you can see, you can exercise a test that spans multiple requests.
Mocking/Stubbing Using with-redefs
Sometimes, though, you don't want your tests to interact with external services. In those instances, you need to leverage some sort of mocking/stubbing technique. In Clojure you have that ability built right into the language itself with two functions called with-redefs and with-redefs-fn. To illustrate, let's take a look at the src/fincalc/core.clj file:
(ns fincalc.core
(:require [clj-time.core :as t]
[clj-time.format :as f]
[cemerick.url :refer (url)]
[cheshire.core :as json]
[clj-http.client :as client]))
(defn today []
(t/today))
(defn one-year-ago
([] (one-year-ago (today)))
([date] (t/minus date (t/years 1))))
(defn yesterday []
(t/minus (today) (t/days 1)))
...You can see the two methods here that are very dependent on the current date. You can test these:
(ns fincalc.core-test
(:require [clojure.test :refer :all]
[clj-time.core :as t]
[fincalc.core :refer :all]))
(deftest date-calculations
(testing "1 year ago"
(is (= (t/minus (t/today) (t/years 1)) (one-year-ago)))))If you look at this test above, it exhibits a distinct code smell known as The Ugly Mirror (http://jasonrudolph.com/blog/2008/07/30/testing-anti-patterns-the-ugly-mirror/). If the test itself mirrors the exact implementation as the actual code, then it's not a very useful test. So how do you rewrite this test to more accurately express the intent of the test without having to resort to mirroring the implementation? You can leverage Clojure's built in ability to mock functions using with-redefs as shown here:
(ns fincalc.core-test
(:require [clojure.test :refer :all]
[clj-time.core :as t]
[fincalc.core :refer :all]))
(deftest date-calculations
(testing "1 year ago"
(is (= (t/minus (t/today) (t/years 1)) (one-year-ago)))))
(deftest date-calculations-with-redefs
(with-redefs [t/today (fn [] (t/local-date 2016 1 10))]
(testing "1 year ago"
(are [exp actual] (= exp actual)
(t/local-date 2015 1 10) (one-year-ago)
(t/local-date 2015 1 1) (one-year-ago (t/local-date 2016 1 1))))
(testing "yesterday"
(is (= (t/local-date 2016 1 9) (yesterday))))))As you can see, the date calculations have been rewritten to test using with-redefs. You make use of it in the same way that you use let and let* to define local variables. Using with-redefs creates a local binding that will call your mock implementation of a function within the form; then when execution leaves the form, the local binding goes out of scope and Clojure rebinds the original function as it was before.
You must take great care when using with-redefs, because running tests concurrently could permanently change the binding if you aren't careful. This occurs when the execution of your code is complete and it tries to rebind the function or variable back to its original value. If there are many threads executing at once, the function or variable may have already had its binding changed, so when with-redefs gets executed again, it will store off what it thinks is the original implementation of the function. Then when it is finished executing, it will rebind the bogus implementation as illustrated here from the ClojureDocs for with-redefs:
user> (defn ten [] 10)
#'user/ten
user> (doall (pmap #(with-redefs [ten (fn [] %)] (ten)) (range 20 100)))
...
user> (ten)
79This is more of an issue if your actual code, not your tests, uses with-redefs. However, this may be what you're experiencing, if you are seeing inconsistent behavior in your tests that are making heavy use of with-redefs.
Redefining Dynamic Vars
Another technique for mocking out your dependencies involves using dynamic vars and changing the binding during the execution of your tests. This provides the thread safety that is missing when using with-redefs; however, you must now define your functions that you may want to mock out as being dynamic. You can rewrite the date functions from earlier to show this technique:
(ns fincalc.core
(:require [clj-time.core :as t]
[clj-time.format :as f]
[cemerick.url :refer (url)]
[cheshire.core :as json]
[clj-http.client :as client]))
(defn ∧:dynamic today []
(t/today))
(defn one-year-ago
([] (one-year-ago (today)))
([date] (t/minus date (t/years 1))))
(defn yesterday []
(t/minus (today) (t/days 1)))Notice the only thing that had to change in the source was to add the ∧:dynamic decoration to the today function? Now you can update your tests:
(ns fincalc.core-test
(:require [clojure.test :refer :all]
[clj-time.core :as t]
[fincalc.core :refer :all]))
(deftest date-calculations
(testing "1 year ago"
(is (= (t/minus (t/today) (t/years 1)) (one-year-ago)))))
(deftest date-calculations-with-redefs
(binding [today (fn [] (t/local-date 2016 1 10))]
(testing "1 year ago"
(are [exp actual] (= exp actual)
(t/local-date 2015 1 10) (one-year-ago)
(t/local-date 2015 1 1) (one-year-ago (t/local-date 2016 1 1))))
(testing "yesterday"
(is (= (t/local-date 2016 1 9) (yesterday))))))Record/Replay with VCR
If your application makes use of external APIs that return a significant amount of data, sometimes mocking is not a feasible solution. The sheer amount of setup code that would be required is time consuming not only to create, but to maintain if you need to change it later on. As an example, let's create a function that will call the Yahoo Finance APIs to fetch data about stocks, and return the closing price for a given stock on a given day. Knowing that this data changes quite frequently, how in the world can you test that your function returns the correct data? Mocking and stubbing would work; however, the tests would be littered with all kinds of noise for setting up the mock data to be returned from the service.
Instead, you can use a library called vcr-clj (https://github.com/gfredericks/vcr-clj) to record and play back calls to this external service. Here is the src/fincalc/core.clj file that contains the test functions:
(ns fincalc.core
(:require [clj-time.core :as t]
[clj-time.format :as f]
[cemerick.url :refer (url)]
[cheshire.core :as json]
[clj-http.client :as client]))
(defn ∧:dynamic today []
(t/today))
(defn one-year-ago
([] (one-year-ago (today)))
([date] (t/minus date (t/years 1))))
(defn yesterday []
(t/minus (today) (t/days 1)))
(defn build-yql [sym date]
(let [formatted-date (f/unparse-local-date (f/formatters :year-month-day) date)]
(str "select * from yahoo.finance.historicaldata where symbol = "" sym ""
and startDate = "" formatted-date "" and endDate = ""
formatted-date """)))
(defn build-get-url [sym date]
(-> (url "https://query.yahooapis.com/v1/public/yql")
(assoc :query {:q (build-yql sym date)
:format "json"
:env "store://datatables.org/alltableswithkeys"})
str))
(defn get-close-for-symbol [sym date]
(loop [close-date date retries 5]
(let [result (get-in
(json/parse-string
(:body (client/get (build-get-url sym close-date))))
["query" "results" "quote" "Adj_Close"])]
(if (and (nil? result) (> retries 0))
(recur (t/minus close-date (t/days 1)) (dec retries))
(read-string result)))))
(defn roi [initial earnings]
(double (* 100 (/ (- earnings initial) initial))))As you can see, you're making a call to the Yahoo API by issuing a GET request in the get-close-for-symbol function. In order to test this and have repeatable results, you can record and replay the results from this HTTP request by wrapping the test using the with-cassette macro:
(ns fincalc.core-test
(:require [clojure.test :refer :all]
[clj-time.core :as t]
[vcr-clj.clj-http :refer [with-cassette]]
[fincalc.core :refer :all]))
...
(deftest vcr-tests
(with-cassette :stocks
(is (= 97.129997 (get-close-for-symbol "AAPL" (t/local-date 2016 1 17))))
(is (= 29.139999 (get-close-for-symbol "YHOO" (t/local-date 2016 1 17))))))Each time you run these tests, vcr-clj will check to see if there is a cassette in the /cassettes directory of the project, and if that cassette contains a recorded request that matches the HTTP request being called. If it does exist, it will simply return the previously recorded results. That way you can be sure that every time you call fetch-stock-price, it will return the same stock data as before. You could even disconnect from the network altogether and your tests will still run and pass.
If for some reason you wish to record new results, you simply delete the file in the /cassettes directory with the corresponding filename of the cassette you wish to re-record.
MEASURING CODE QUALITY
Having a comprehensive suite of quality tests is certainly a good thing to have when developing software, but how can you be certain that it's enough? Sometimes just measuring test coverage is not enough, and sometimes you need to analyze your code to identify potential bugs and improvements that can be made to the overall quality of your code. In this next section you'll get to peek at a few useful tools to help you with that.
Code Coverage with Cloverage
Code coverage, while being a useful metric, is not a golden hammer (http://c2.com/cgi/wiki?GoldenHammer). Unfortunately, it is a metric that is often misused and misrepresented. It will not guarantee that your code is free of defects if you somehow achieve 100 percent code coverage.
When used properly though, it is a very useful metric to help identify what areas of your code you may have overlooked when testing, especially if those areas that are lacking coverage are of high risk.
In order to measure code coverage in your Clojure projects, you need to leverage a tool called cloverage (https://github.com/lshift/cloverage). As of this writing, cloverage only supports measuring code coverage with the clojure.test library. In order to use the plugin, you can add [lein-cloverage "1.0.6"] to the :plugins section of your ∼/.lein/profiles.clj file. Once you have added that you will be able to run lein cloverage in your project directory. After it's done running your tests, you'll see a nice summary printed out to the console:
Loading namespaces: (fincalc.views.contents fincalc.api fincalc.db fincalc.core
fincalc.handler fincalc.views.layout)
Test namespaces: (fincalc.api-test fincalc.core-test fincalc.db-test
fincalc.handler-test fincalc.views.contents-test)
Loaded fincalc.core .
Loaded fincalc.db .
Loaded fincalc.api .
Loaded fincalc.views.layout .
Loaded fincalc.views.contents .
Loaded fincalc.handler .
Instrumented namespaces.
Testing fincalc.api-test
Testing fincalc.core-test
Testing fincalc.db-test
Testing fincalc.handler-test
Testing fincalc.views.contents-test
Ran 10 tests containing 18 assertions.
0 failures, 0 errors.
Ran tests.
Produced output in /Users/jeremy/Projects/clojure/fincalc/target/coverage .
HTML: file:///Users/jeremy/Projects/clojure/fincalc/target/coverage/index.html
| :name | :forms_percent | :lines_percent |
|------------------------+----------------+----------------|
| fincalc.api | 29.41 % | 55.56 % |
| fincalc.core | 59.78 % | 71.43 % |
| fincalc.handler | 51.13 % | 68.42 % |
| fincalc.views.contents | 55.04 % | 50.00 % |
| fincalc.views.layout | 53.26 % | 100.00 % |
Files with 100% coverage: 1
Forms covered: 54.39 %
Lines covered: 68.06 %Cloverage will also output an HTML report that you can drill down into and see exactly what lines of code have been covered by tests and which haven't. Figure 4.1 shows the HTML summary page, which can be found in the target/coverage folder of your project.

Then if you click on the hyperlink for an individual namespace, it will drill down into the coverage report and show you the actual line-by-line coverage as shown in Figure 4.2.
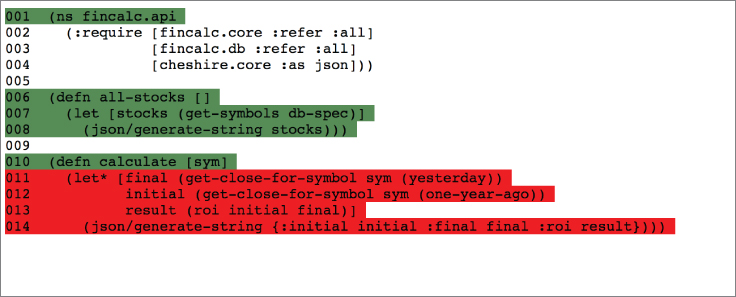
In Figure 4.2 you can see that we've managed to test the all-stocks function sufficiently, but have not tested the body of the calculate function. The cloverage plugin provides many options for how it measures coverage, as well as what format to output your report in to support various continuous integration servers. All of these options can be found in the parse-args function in the cloverage.clj source file within the project (https://github.com/lshift/cloverage/blob/master/cloverage/src/cloverage/coverage.clj#L78). Unfortunately, the project doesn't provide much in the way of documenting them elsewhere.
Static Analysis with kibit and bikeshed
A couple of very useful libraries that fall under the same category as cloverage, but should not be considered competing libraries, are kibit and bikeshed. Both provide static analysis of your code to help identify potential problems and make suggestions about your coding style to ensure it adheres to Clojure's best practices; they will, however, report different things about your code.
The first plugin to look at is lein-kibit (https://github.com/jonase/kibit), and to use this plugin you can add [lein-kibit "0.1.2"] to the :plugins section of your ∼/.lein/profiles.clj file. You can then run the analysis against your project by running lein kibit in your project directory. The output shown in the following snippet is a result of running lein kibit against the ring-core project:
At /Users/jeremy/Projects/clojure/ring/ring-core/src/ring/middleware/session.clj:61
:
Consider using:
(update-in response [:cookies] merge cookie)
instead of:
(assoc response :cookies (merge (response :cookies) cookie))
At /Users/jeremy/Projects/clojure/ring/ring-core/src/ring/middleware/session.clj:
102:
Consider using:
(session-response (handler new-request) new-request options)
instead of:
(-> (handler new-request) (session-response new-request options))
At /Users/jeremy/Projects/clojure/ring/ring-core/src/ring/util/request.clj:58:
Consider using:
(clojure.string/join (:body request))
instead of:
(apply str (:body request))You can see that kibit is primarily concerned with code style. It makes helpful suggestions about how you can improve your Clojure code to follow a style more in line with the community. There are some limitations, though, and you're likely to get some false positives returned in the analysis.
The second plugin to look at is the bikeshed plugin (https://github.com/dakrone/lein-bikeshed). This plugin is installed like other plugins discussed in this section. Simply add [lein-bikeshed "0.2.0"] to the :plugins section of your ∼/.lein/profiles.clj file. Then you can run lein bikeshed in your project directory. Once again we'll look as some output from running lein bikeshed against the ring-core library:
Checking for lines longer than 80 characters.
Badly formatted files:
/Users/jeremy/Projects/clojure/ring/ring-core/src/ring/middleware/cookies.clj:23:
:doc "Attributes defined by RFC6265 that apply to the Set-Cookie header."}
/Users/jeremy/Projects/clojure/ring/ring-core/src/ring/middleware/cookies.clj:81:
(instance? DateTime value) (str ";" attr-name "=" (unparse rfc822-formatter value))
/Users/jeremy/Projects/clojure/ring/ring-core/src/ring/middleware/file.clj:25:
(let [opts (merge {:root (str root-path), :index-files? true, :allow-symlinks?
false} opts)]
...
Checking for lines with trailing whitespace.
Badly formatted files:
/Users/jeremy/Projects/clojure/ring/ring-core/src/ring/middleware/params.clj:56:
Accepts the following options:
/Users/jeremy/Projects/clojure/ring/ring-core/src/ring/util/response.clj:20:
"Returns a Ring response for an HTTP 302 redirect. Status may be
...
Checking for files ending in blank lines.
No files found.
Checking for redefined var roots in source directories.
No with-redefs found.
Checking whether you keep up with your docstrings.
120/159 [75.47%] functions have docstrings.
Use -v to list functions without docstrings
Checking for arguments colliding with clojure.core functions.
#'ring.middleware.cookies/write-value: 'key' is colliding with a core function
#'ring.middleware.multipart-params.temp-file/do-every: 'delay' is colliding
with a core function
...The bikeshed plugin runs several different inspections. The first few inspections deal with the formatting of your source files, whether you have lines containing more than 80 characters long, trailing whitespace, or files ending with blank lines. These are of course simple housekeeping tasks. The next inspection checks to see if you are potentially introducing bugs into your code by using with-redefs. Then bikeshed checks to see if you're a good citizen with your code and ensures that you define docstrings on all of your functions. This last check is probably the most important, because it points out areas in your code where you are facing potential namespace collisions and may need to adjust your :requires statements in your files to exclude certain functions in namespaces you're requiring, or rename functions you are defining. You should take each and every one of these warnings seriously, and determine whether or not they need to be addressed.
Keeping Dependencies Under Control
Sometimes you run across strange bugs due to mismatched versions of dependencies. Even if you only directly depend on a small handful of libraries, the transient dependency graph can quickly become unwieldy. Leiningen provides you with the tools to help keep tabs on all of this. In order to retrieve a graph of all of the libraries your project depends on, you simply type lein deps :tree in your project directory. Leiningen will then gladly provide you with a multitude of information. The following snippet is from the output of running lein deps :tree on the sample project:
Possibly confusing dependencies found:
[lein-ring "0.9.7"] -> [org.clojure/data.xml "0.0.8"] -> [org.clojure/clojure
"1.4.0"]
overrides
[lein-kibit "0.1.2"] -> [jonase/kibit "0.1.2"] -> [org.clojure/core.logic
"0.8.10"] -> [org.clojure/clojure "1.6.0"]
and
[lein-ancient "0.6.8"] -> [jansi-clj "0.1.0"] -> [org.clojure/clojure "1.5.1"]
and
[lein-ancient "0.6.8"] -> [version-clj "0.1.2"] -> [org.clojure/clojure "1.6.0"]
and
[lein-ancient "0.6.8"] -> [rewrite-clj "0.4.12"] -> [org.clojure/clojure "1.6.0"
:exclusions [org.clojure/clojure]]
and
[lein-ancient "0.6.8"] -> [ancient-clj "0.3.11" :exclusions [com.amazonaws/aws-
java-sdk-s3]] -> [org.clojure/clojure "1.7.0" :exclusions [joda-time
org.clojure/clojure]]
and
[lein-kibit "0.1.2"] -> [jonase/kibit "0.1.2"] -> [org.clojure/clojure "1.6.0"]
Consider using these exclusions:
[lein-kibit "0.1.2" :exclusions [org.clojure/clojure]]
[lein-ancient "0.6.8" :exclusions [org.clojure/clojure]]
[lein-ancient "0.6.8" :exclusions [org.clojure/clojure]]
[lein-ancient "0.6.8" :exclusions [org.clojure/clojure]]
[lein-ancient "0.6.8" :exclusions [org.clojure/clojure]]
[lein-kibit "0.1.2" :exclusions [org.clojure/clojure]]As you can see, this shows you the few libraries that can potentially cause issues. It is telling you that several of the libraries included in your project depend on conflicting versions of org.clojure/clojure, and it gives you a helpful suggestion to mitigate this potential issue. The rest of the output is shown here:
[cheshire "5.5.0"]
[com.fasterxml.jackson.core/jackson-core "2.5.3"]
[com.fasterxml.jackson.dataformat/jackson-dataformat-cbor "2.5.3"]
[com.fasterxml.jackson.dataformat/jackson-dataformat-smile "2.5.3"]
[tigris "0.1.1"]
[cider/cider-nrepl "0.10.0-20151127.123841-44"]
[org.tcrawley/dynapath "0.2.3" :exclusions [[org.clojure/clojure]]]
[clj-http "2.0.0"]
[commons-codec "1.10" :exclusions [[org.clojure/clojure]]]
[commons-io "2.4" :exclusions [[org.clojure/clojure]]]
[org.apache.httpcomponents/httpclient "4.5" :exclusions [[org.clojure/clojure]]]
[commons-logging "1.2"]
[org.apache.httpcomponents/httpcore "4.4.1" :exclusions [[org.clojure/clojure]]]
[org.apache.httpcomponents/httpmime "4.5" :exclusions [[org.clojure/clojure]]]
[potemkin "0.4.1" :exclusions [[org.clojure/clojure]]]
[clj-tuple "0.2.2"]
[riddley "0.1.10"]
[slingshot "0.12.2" :exclusions [[org.clojure/clojure]]]
[clj-time "0.11.0"]
[joda-time "2.8.2"]
[clojure-complete "0.2.3" :exclusions [[org.clojure/clojure]]]
[com.cemerick/url "0.1.1"]
[pathetic "0.5.0"]
[com.cemerick/clojurescript.test "0.0.4"]
[org.clojure/clojurescript "0.0-1586"]
[com.google.javascript/closure-compiler "r2180"]
[args4j "2.0.16"]
[com.google.code.findbugs/jsr305 "1.3.9"]
[com.google.guava/guava "13.0.1"]
[com.google.protobuf/protobuf-java "2.4.1"]
[com.googlecode.jarjar/jarjar "1.1"]
[org.apache.ant/ant "1.8.2"]
[org.apache.ant/ant-launcher "1.8.2"]
[org.json/json "20090211"]
[org.clojure/google-closure-library "0.0-2029-2"]
[org.clojure/google-closure-library-third-party "0.0-2029-2"]
[org.mozilla/rhino "1.7R4"]
[com.gfredericks/vcr-clj "0.4.6" :scope "test"]
[fs "1.3.3" :scope "test"]
[org.apache.commons/commons-compress "1.3" :scope "test"]
[org.clojure/data.codec "0.1.0" :scope "test"]
[compojure "1.4.0"]
[clout "2.1.2"]
[instaparse "1.4.0" :exclusions [[org.clojure/clojure]]]
[medley "0.6.0"]
[org.clojure/tools.macro "0.1.5"]
[ring/ring-codec "1.0.0"]
[ring/ring-core "1.4.0"]
[commons-fileupload "1.3.1"]
[crypto-equality "1.0.0"]
[crypto-random "1.2.0"]
[org.clojure/tools.reader "0.9.1"]
[hiccup "1.0.5"]
[javax.servlet/servlet-api "2.5" :scope "test"]
[org.clojure/clojure "1.7.0"]
[org.clojure/java.jdbc "0.4.1"]
[org.clojure/tools.nrepl "0.2.12"]
[org.postgresql/postgresql "9.4-1201-jdbc41"]
[ring/ring-defaults "0.1.5"]
[ring/ring-anti-forgery "1.0.0"]
[ring/ring-headers "0.1.3"]
[ring/ring-ssl "0.2.1"]
[ring/ring-jetty-adapter "1.2.1"]
[org.eclipse.jetty/jetty-server "7.6.8.v20121106"]
[org.eclipse.jetty.orbit/javax.servlet "2.5.0.v201103041518"]
[org.eclipse.jetty/jetty-continuation "7.6.8.v20121106"]
[org.eclipse.jetty/jetty-http "7.6.8.v20121106"]
[org.eclipse.jetty/jetty-io "7.6.8.v20121106"]
[org.eclipse.jetty/jetty-util "7.6.8.v20121106"]
[ring/ring-servlet "1.2.1"]
[ring/ring-mock "0.3.0" :scope "test"]In the ever-changing world of software development, it's difficult to keep up with every version of every dependency of your project or library. Thankfully, someone has gone to the trouble to create a very useful plugin named lein-ancient that will look through each of the dependencies listed in your project.clj and determine whether or not there are newer versions available. In order to leverage this plugin just add [lein-ancient "0.6.8"] to the :plugins section in your ∼/.lein/profiles.clj. Once you have added this, you can run the lein-ancient command in your project directory. If there are any dependencies out of date in your project, you'll see them listed similar to the output shown here:
WARNING: update already refers to: #'clojure.core/update in namespace:
clj-http.client, being replaced by: #'clj-http.client/update
[ring/ring-jetty-adapter "1.4.0"] is available but we use "1.2.1"
[org.clojure/java.jdbc "0.4.2"] is available but we use "0.4.1"
[org.postgresql/postgresql "9.4.1207"] is available but we use "9.4-1201-jdbc41"Empowered with this knowledge, you can decide whether or not you want to update your dependencies.
TESTING FRAMEWORK ALTERNATIVES
Testing frameworks and styles of testing are very much a personal preference. Fortunately, there are a number of different testing frameworks available to you. In this last section, let's examine a few of these frameworks briefly, comparing and contrasting them to what was discussed earlier in this chapter.
Expectations
Expectations (http://jayfields.com/expectations/) is probably one of the simplest testing frameworks available. It is based on clojure.test, but it's stripped down to the very basics of testing and rooted in the belief that each test should test one and only one thing. To use expectations in your project, you can add [expectations "2.0.9"] to the :dependencies section in your project.clj and [lein-expectations "0.0.7"] to the :plugins section. Then you can write your tests as shown here:
(ns sample.test.core
(:use [expectations]))
(expect 2 (+ 1 1))
(expect [1 2] (conj [] 1 2))
(expect #{1 2} (conj #{} 1 2))
(expect {1 2} (assoc {} 1 2))As you can see, the entirety of the framework revolves around a single construct, expect. This single macro is extremely flexible and powerful, but don't let its simplicity fool you. As you may have guessed by now, you can run these tests by executing lein expectations in the root of your project.
Speclj
Speclj (https://github.com/slagyr/speclj), pronounced speckle, is a testing framework that seems to be a favorite of converted Rubyists, probably because it's heavily inspired by the RSpec framework. Similar to RSpec, your tests are referred to as “specs” and should follow the naming convention of being postfixed with _spec.clj. It will follow the same convention for directories and namespaces as before, only in a directory named spec instead of test. Here is an example directory structure for a project that uses speclj for testing:
├—— README.md
├—— project.clj
├—— spec
│ └—— speclj_project
│ └—— core_spec.clj
└—— src
└—— speclj_project
└—— core.cljIn order to use speclj in your project, you'll need to add the following configuration to your project.clj file:
:profiles {:dev {:dependencies [[speclj "3.3.1"]]}}
:plugins [[speclj "3.3.1"]]
:test-paths ["spec"])Once you have that configured, you can rewrite simple tests from earlier in the chapter for my-add and my-sub as specs:
(ns speclj-project.core-spec
(:require [speclj.core :refer :all]
[speclj-project.core :refer :all]))
(describe "addition"
(it "can add two numbers correctly"
(should (= 4 (my-add 2 2)))))
(describe "subtraction"
(it "can subtract two numbers"
(should (= 3 (my-sub 7 4)))))Let's take a look at the pieces that make up the simple spec. The describe macro is the topmost construct in your specification, and is typically used to describe the context of your test. The describe form will contain any number of specifications denoted by the it macro. Then within the it form, you can make any number of assertions using should, should-not, or any of the other variants of should. To run your specs, you simply run the command lein spec in your project directory.
Cucumber
Cucumber (http://cukes.info) is a framework for running automated acceptance tests, designed to support a behavior driven development style. It gained popularity in the Ruby community as a part of the RSpec framework, but it soon forked off into its own project. Shortly after that, it was ported to run on other platforms such as the JVM, and now runs on a number of different platforms. Cucumber is designed to enable and encourage discussion between the developer and the customer to create a sort of executable documentation using a generic language known as Gherkin. Here is the example that is shown on the homepage of the Cucumber project:
Feature: Addition
In order to avoid silly mistakes
As a math idiot
I want to be told the sum of two numbers
Scenario: Add two numbers
Given I have entered "50" into the calculator
And I have entered "70" into the calculator
When I press "add"
Then the result should be "120" on the screenAs you can see, the language used to write these specifications is very much written in plain English, and with a little training and practice it can be collaborated on, or possibly even written, by your business users. Notice that they are written at a very high level, and should only exercise the external most layer of your applications such as a REST API or by interacting with the browser using Selenium.
Cucumber executes code based on these feature files by trying to match a step from your feature file to a matching step definition in one of your step definition files. An example step definition for the feature file above looks like the following:
(Given #"∧I have entered "(.*?)" into the calculator$" [arg1]
(do-something-cool-here))The steps definition consists of a macro, in this case called Given, which contains a regular expression, with optional capture groups defined. These capture groups then get bound to the parameter list immediately following the regular expression. The rest of the macro consists of what you need to implement the step, whether that be to set up some state, click a link on the page, or assert some values.
Let's start off simply by defining a Cucumber feature to define the acceptance criteria for some REST APIs. Below is the feature file defined for interacting with the /api/stocks endpoints that can be found at /features/stocks_api.feature.
Feature: Stocks REST API
As an admin
I want to be view and modify the stocks table
So that I can manage it appropriately
Scenario: Get All Stocks
When I send a GET request to "/api/stocks"
Then the response status should be "200"
And I should see the following JSON in the body:
"""
["AAPL"]
"""
Scenario: Add New Stock
When I send a POST request to "/api/stocks" with the following params:
| param | value |
| sym | NOK |
Then the response status should be "201"
And the response body should be empty
And a stock with symbol "NOK" exists in the database
Scenario: Remove Stock
Given a stock with symbol "NOK" exists in the database
When I send a DELETE request to "/api/stocks/NOK"
Then the response status should be "204"
And a stock with symbol "NOK" does not exist in the databaseThe first time you run lein cucumber in your project you will be presented with the following output:
Running cucumber...
Looking for features in: [/Users/jeremy/Projects/clojure/fincalc/features]
Looking for glue in: [/Users/jeremy/Projects/clojure/fincalc/features/
step_definitions]
UUUUUUUUUUU
3 Scenarios (3 undefined)
11 Steps (11 undefined)
0m0.000s
You can implement missing steps with the snippets below:
(When #"∧I send a GET request to "(.*?)"$" [arg1]
(comment Write code here that turns the phrase above into concrete actions )
(throw (cucumber.api.PendingException.)))
(Then #"∧the response status should be "(.*?)"$" [arg1]
(comment Write code here that turns the phrase above into concrete actions )
(throw (cucumber.api.PendingException.)))
(Then #"∧I should see the following JSON in the body:$" [arg1]
(comment Write code here that turns the phrase above into concrete actions )
(throw (cucumber.api.PendingException.)))
(When #"∧I send a POST request to "(.*?)" with the following:$"
[arg1 arg2]
(comment Write code here that turns the phrase above into concrete actions )
(throw (cucumber.api.PendingException.)))
(Then #"∧the response body should be empty$" []
(comment Write code here that turns the phrase above into concrete actions )
(throw (cucumber.api.PendingException.)))
(Then #"∧a stock with symbol "(.*?)" exists in the database$" [arg1]
(comment Write code here that turns the phrase above into concrete actions )
(throw (cucumber.api.PendingException.)))
(Given #"∧a stock with symbol "(.*?)" exists in the database$" [arg1]
(comment Write code here that turns the phrase above into concrete actions )
(throw (cucumber.api.PendingException.)))
(When #"∧I send a DELETE request to "(.*?)"$" [arg1]
(comment Write code here that turns the phrase above into concrete actions )
(throw (cucumber.api.PendingException.)))
(Then #"∧a stock with symbol "(.*?)" does not exist in the database$" [arg1]
(comment Write code here that turns the phrase above into concrete actions )
(throw (cucumber.api.PendingException.)))This is exceptionally useful because it gives you the templates for implementing the step definitions without having to remember how to write the regular expressions. You can then go ahead and copy/paste this output directly into your steps definition file. The completed steps definition file for the stocks API can be found at /features/step-definitions/stock_api_steps.clj:
(require '[clojure.test :refer :all]
'[clj-http.client :as client]
'[cheshire.core :as json]
'[fincalc.db :as db])
(def response (atom nil))
(def base-url "http://localhost:3000")
(When #"∧I send a GET request to "(.*?)"$" [path]
(let [endpoint (str base-url path)]
(reset! response (client/get endpoint))))
(When #"∧I send a POST request to "(.*?)" with the following params:$"
[path req-params]
(let [endpoint (str base-url path)
form-params (kv-table->map req-params)]
(reset! response (client/post endpoint {:form-params form-params}))))
(When #"∧I send a DELETE request to "(.*?)"$" [path]
(let [endpoint (str base-url path)]
(reset! response (client/delete endpoint))))
(Then #"∧the response status should be "(.*?)"$" [status-code]
(assert (= (str status-code) (str (:status @response)))))
(Then #"∧I should see the following JSON in the body:$" [expected-body]
(assert (= (json/parse-string expected-body)
(json/parse-string (:body @response)))))
(Then #"∧the response body should be empty$" []
(assert (empty? (:body @response))))
(Given #"∧a stock with symbol "(.*?)" exists in the database$" [sym]
(assert (not (empty? (db/get-symbol db/db-spec sym)))))
(Then #"∧a stock with symbol "(.*?)" does not exist in the database$" [sym]
(assert (empty? (db/get-symbol db/db-spec sym))))Notice how at the beginning of the steps definition style, we set up some global state to store our HTTP response. Without this, since each step is defined as a separate function, you don't have the ability to query your response after making the request. In addition, notice that you're using assert instead of is in tests for testing correctness. This is due to the way that Cucumber works under the covers and expects to see a java.lang.AssertionError in order to determine whether or not a step has passed or failed. Next, define a value to store the base URL for all of the HTTP requests. The next thing to take note of is how to handle the data table in the POST step. Use the kv-table->map function to convert the data table into a map so you can pass it as :form-params in the POST request.
Now that you have the step definitions implemented, you can run the Cucumber tests by using lein cucumber in the project directory. Since Cucumber executes against an actual running application, you have to ensure that your app is running by typing lein ring server-headless in another terminal window; otherwise your Cucumber tests will all fail.
One other thing to watch out for is that given how the Cucumber tests run against a live running system, there's no good way to wrap the tests in a transaction to have them roll back as earlier in the DB tests. Therefore, you'll need to be mindful to clean up after yourself somehow using either the Before and After step definitions, or somehow within the tests themselves.
Now that you can see how to leverage Cucumber to test your REST APIs, let's leverage it to test your application from end-to-end by using Selenium's webdriver API to remotely control a web browser such as Firefox. Start by taking a look at the feature file, which can be found at features/roi_calc.feature.
@ui
Feature: ROI Calculator
As a budding investor
I want to be able to check the ROI on various stocks
So that I can determine whether or not to purchase a stock
Scenario: Link in navbar takes me to homepage
Given I am at the "homepage"
When I click the title bar
Then I should be at the "homepage"
Scenario: Submit a symbol for calculation
Given I am at the "homepage"
When I calculate the ROI for the symbol "AAPL"
Then I should see an initial value
And I should see a final value
And I should see an ROI
Scenario: Page not found
Given I am at an invalid page
Then I should see a message stating "Page Not Found"
When I click on the "Home" button
Then I should be at the "homepage"Notice the level of abstraction used to define these feature file steps. You don't define the feature as fine-grained steps of “click this field,” “type this string,” “click that button,” etc. Instead, keep it at a high enough level that your customer would leave some of the implementation details out of the feature. Therefore, if you have to move things around or implement them in a different way, you don't have to rewrite the feature file.
Before you can implement the steps definition, you need to create a helper to manage the connection to the browser. This file can be found at test/fincalc/browser.clj and is shown here:
(ns fincalc.browser
(:require [clj-webdriver.taxi :refer :all]))
(def ∧:private browser-count (atom 0))
(defn browser-up
"Start up a browser if it's not already started."
[]
(when (= 1 (swap! browser-count inc))
(set-driver! {:browser :firefox})
(implicit-wait 60000)))
(defn browser-down
"If this is the last request, shut the browser down."
[& {:keys [force] :or {force false}}]
(when (zero? (swap! browser-count (if force (constantly 0) dec)))
(quit)))For this example you're using the Firefox browser, but you can also configure it to use Chromium or even the headless PhantomJS browser if you wish. If you decide to use something other than Firefox, all you need to do is change the :browser symbol in set-driver!. Next, let's take a look at our step definitions for the feature:
(require '[clj-webdriver.taxi :as taxi]
'[fincalc.browser :refer [browser-up browser-down]]
'[clojure.test :refer :all])
(Before ["@ui"]
(browser-up))
(After ["@ui"]
(browser-down))
(Given #"∧I am at the "homepage"$" []
(taxi/to "http://localhost:3000/"))
(Given #"∧I am at an invalid page$" []
(taxi/to "http://localhost:3000/invalid"))
(When #"∧I click the title bar$" []
(taxi/click "a#brand-link"))
(Then #"∧I should be at the "homepage"$" []
(assert (= (taxi/title) "Home")))
(When #"∧I calculate the ROI for the symbol "(.*?)"$" [sym]
(taxi/input-text "input[name="sym"]" sym)
(taxi/click "button[type="submit"]"))
(Then #"∧I should see an initial value$" []
(taxi/wait-until #(= (taxi/title) "Results"))
(assert (re-find #"Stock price one year ago:" (taxi/text "#initial"))))
(Then #"∧I should see a final value$" []
(assert (re-find #"The latest close was" (taxi/text "#final"))))
(Then #"∧I should see an ROI$" []
(assert (re-find #"Calculated ROI" (taxi/text "#roi"))))
(Then #"∧I should see a message stating "(.*?)"$" [arg1]
(assert (= "Page Not Found" (taxi/text "h1.info-warning"))))
(When #"∧I click on the "Home" button$" []
(taxi/click "#go-home"))This steps file looks similar to what you saw earlier for the REST API, with a few differences. The first one to take note of is the usage of the Before and After macros to start and kill the browser at the beginning and end of every Scenario. The parameter being passed to these macros, "@ui" indicates that you only want to run these on Scenarios that have been tagged with the "@ui" tag in the feature file, as was done above. Next, see how you can leverage the clj.webdriver.taxi library to interact with the browser. The documentation for this API can be found at https://github.com/semperos/clj-webdriver/wiki/Taxi-API-Documentation.
Finally, there are several different ways to output the results from the execution of lein cucumber, and a common one is the HTML report. By default, it will simply produce output using the progress plugin, but you can specify that it should also use the HTML plugin by typing lein cucumber --plugin html:target/cucumber --plugin progress. If you then open the HTML report in a browser, you should see a report like what is shown in Figure 4.3.

This output can then also serve as documentation that lives on with your project and hopefully never becomes out of date, because it is generated every time you execute your Cucumber tests.
These two simple examples should give you a good taste of what you can do with Cucumber. Unfortunately, we can't cover every use case or bit of the API, yet there are entire books dealing with this subject that do an outstanding job. Most of them are written to the Ruby or Java versions of Cucumber, but with a little effort you can translate the information to Clojure.
Kerodon
One last framework to look at is the Kerodon (https://github.com/xeqi/kerodon) framework. It's similar to Cucumber, in that it allows you to do acceptance level testing through the browser, but this time using Capybara instead of Selenium. Where they differ is that Kerodon is designed with the developer in mind, and Cucumber is designed with the product owner or business analyst in mind. If you don't have a product owner, business analyst, or similar type of person to collaborate on acceptance tests with, the overhead of writing Cucumber features may not make sense.
If you were to write a test to exercise the ROI calculator page similar to what we did in Cucumber, you would end up with something similar to the following:
(ns fincalc.integration.roi-calc-test
(:require [clojure.test :refer :all]
[kerodon.core :refer :all]
[kerodon.test :refer :all]
[fincalc.handler :refer [app]]))
(deftest user-can-calculate-roi-on-stock
(-> (session app)
(visit "/")
(has (status? 200) "page exists")
(within [:h2]
(has (text? "Enter a Stock Symbol to calculate ROI on...")
"Header is there"))
(fill-in :input.form-control "AAPL")
(press :button)
(within [:h2]
(has (text? "Results") "made it to results page"))
(within [:#initial]
(has (some-text? "Stock price one year ago:")))
(within [:#final]
(has (some-text? "The latest close was:")))
(within [:#roi]
(has (some-text? "Calculated ROI")))))As you can see, the tests themselves are very fine grained and can get a bit verbose. So, consider abstracting some of the behaviors out to helper functions.
One thing to keep in mind when testing with Kerodon verse using Cucumber is how you don't need your application running when using Kerodon, because it doesn't run through an HTTP server. This allows you to use things like database transactions around your tests by leveraging fixtures. This will also make for faster execution times compared to using Cucumber, allowing them to run as part of your automated continuous integration suite. However, since it's not running through an actual browser against a running application, it may not detect and report errors stemming from issues specific to a web browser.
SUMMARY
We've covered a lot of information in this chapter, empowering you to more confidently test and improve your code. You were introduced to some common situations you'll encounter when trying to test your application code, from simple isolated unit tests, all the way to full end-to-end tests using both Kerodon and Cucumber.
The intent of this chapter was not to convince you to adopt any one testing methodology—whether it be test first, test last, or test during—but to instead show you how you can test your code more effectively. Testing, just like development itself, requires mindful practice to become comfortable and efficient, but keep at it and it will become like second nature.