
Chapter 12
The Hypercortex
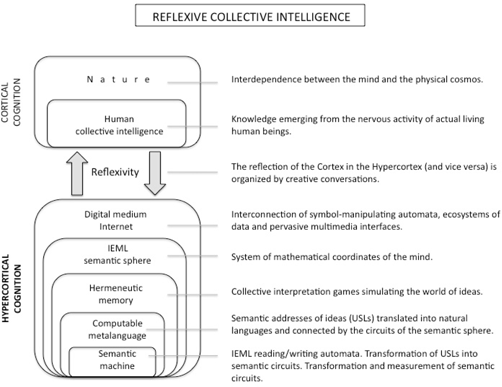
Having recalled the essential role played by media and symbolic systems in human cognition, I will now paint a general portrait of the contemporary digital medium and its likely evolution. I will elaborate on the idea I mentioned in preceding chapters, that the IEML semantic machine paves the way for the emergence of a Hypercortex capable of reflecting human collective intelligence by using the storage and calculation power of the digital medium. As shown in Figure 12.1, this chapter gives an overview of the hypercortical cognition that will be contained in the digital medium.
12.1. The role of media and symbolic systems in cognition
There is no doubt that human cognition is based on biologically determined cerebral organization and neural activity1. Nevertheless, recent decades have seen the publication of an impressive quantity of research on intellectual technologies and symbolic tools2. The main idea that unifies this interdisciplinary area of research is that mechanisms of memory, communication media and symbolic systems – all of which are cultural – play an essential role in shaping cognitive skills, both individually and collectively3.
Figure 12.1. Position of Chapter 12 on the conceptual map
The invention of writing permitted the development of systematically organized knowledge (lists, tables, archives, accounting and complex hermeneutic procedures) that went beyond the practical wisdom of oral cultures, which were organized around myths, stories and rituals4. The invention of the alphabet, i.e. a system of phonetic writing based on about 30 signs (as opposed to writing systems requiring thousands of ideographic signs or mixed systems), led to the social extension of writing and reading abilities and fostered the development of abstract thought5. The invention of the Indo-Arabic numerals, including the positional notation system and zero, made arithmetic simpler and easier, mainly by allowing the use of uniform algorithms6. Just try multiplying Roman numerals and you will understand the importance of symbolic systems in the execution of cognitive tasks. As well as being an unprecedented vehicle for the dissemination of information and knowledge, printing led indirectly to the development of many systems of scientific notation, including accurate maps based on the geometric projection of parallels and meridians, systems of biological classification and systems of mathematical and chemical notation7. Printing also favored the development and formalization of linguistic studies8 and the creation of systems of metadata for libraries and archives9. It should be noted that the development of new symbolic systems did not take place immediately after the invention of printing: it took several generations to assimilate and exploit the cognitive possibilities of this new medium. In general, cultural evolution follows technological evolution. By analogy, we can predict without too much risk that the full symbolic exploitation of the new environment of communication and processing provided by computer networks, i.e. the digital medium, is still to come.
These historical remarks suggest that many major advances in the evolution of human cognition are linked to the invention of media and symbolic systems.
12.2. The digital medium
12.2.1. General definition
The digital medium is an environment of ubiquitous interactive global multimedia communication that is open to growing numbers of communities of users. Its main characteristic is that it is driven by massively distributed symbolmanipulating automata. The growth of the digital medium is essentially the result of the convergence of three processes:
– First, the constant increase in calculating power: computer hardware and software are increasingly efficiently automating symbol manipulation.
– Second, the continuing expansion of the volume of digital data: human cultural memory — both short- and long-term — is gradually being digitized and put online. This creates the conditions for a unification of local memories in a shared ubiquitous virtual space, while digitization makes it possible to automate the processing of these data on a huge scale.
– Third, the continuous growth of the numbers of people making direct use of the digital medium: close to a third of the world population in 201110 versus less than 1% in 1995. We can safely predict that at least 50% of humanity will be connected to high-speed Internet long before the middle of the 21st Century.
12.2.2. The automation of symbol manipulation
Automation first occurred in agriculture, transportation, energy production and manufacturing. We now have technologies that can not only record, duplicate and instantaneously transmit symbols, but can also manipulate them automatically at electronic, and soon optical, speeds. Programmable symbol-manipulating automata (logical automata) have been available in a few political and industrial centers for half a century. They have been in the hands of the public in the richest countries for only about the last 30 years: scarcely more than a generation has passed since the introduction of the personal computer and the development of the Internet. Finally, less than a generation separates us, in 2011, from the emergence of the global hypertext mediasphere, the World Wide Web, in the mid-1990s.
Symbol-manipulating automata are practically capable of carrying out all formally definable operations on any type of information, as long as that information has been digitally encoded. According to the often-cited Moore’s law, which has held true for more than 20 years, the processing power of computers doubles every 18 months. We commonly use logical automata to write, publish and read texts; to produce and view images; to produce and listen to music; to manage our money, our economy and our administrations; and increasingly, to structure our learning and our organizational knowledge in an integrated way. Their capacity to help us make decisions, to produce and modify documents, and to provide interactive support for virtual environments is barely beginning to be explored.
12.2.3. The digitization of memory
The second process that is contributing to the growth of the digital medium is the digitization of cultural memory. By this I mean both long-term memory (archives, encyclopedias, libraries, museums, company records, etc.) and short-term memory (media, blogs, forums, correspondence, games, etc.). The digitization of memory is accelerating, whatever the subject (scientific, artistic, historical, economic, etc.) and whatever the original form of the information (texts, images, sounds or programs). This digitization fuels the activity of logical automata, which can only work with data encoded in 0 or 1. It enables a quantitative power of processing and a refinement of automatic transformation and analysis on a scale unimaginable half a century ago11. Most of the symbolic production of humanity is thus in the process of being represented in digital documents that are available online. As a result, constraints related to the physical location and material inscription of collective memories are vanishing12. Contemporary technology makes ubiquitous universal access possible and reduces the reproduction and copying costs to practically zero. Thus, as soon as information is somewhere on the network, it is potentially everywhere.
Digitized documents are virtually part of a dynamic universal hyperdocument that is fed, read and processed by all institutions and individuals participating in the digital medium. While the institutions traditionally responsible for memory and communication struggle to adapt to these new conditions, new forms of collective memory that have appeared in recent years give us a glimpse of the future. Wikipedia was launched in 2001, and by 2010 it had close to three million articles in 200 languages, more than 300,000 volunteer collaborators and millions of users every day, which makes it the most complete and most consulted encyclopedia in the world. Web sites permit hundreds of millions of Internet users to share and comment collectively on videos (YouTube) or photographs (Flickr). Sites such as Diigo allow Internet users to share their bookmarks and to index or tag sites they want to bring to the attention of others, using their own keywords. In this case, users take over the documentalist’s role of classification. The result is that the resources of the Web are organized as democratic “folksonomies” rather than taxonomies imposed by experts.
The latest example of these changes in collective memory is peer-to-peer (P2P) file exchange systems such as Kazaa, eMule, BitTorrent or GNUnet, which allow Internet users to share documents on their dispersed hard drives as if they were all connected to a shared memory combining their individual memories. These are the main channels for the large-scale exchange of “pirated” games, films and music, much to the chagrin of publishers, producers and recording companies threatened with bankruptcy. P2P file exchanges are thought to consume most of the bandwidth of the Internet.
These new forms of collective memory have at least four features in common:
– from the user’s point of view they are immediately global, dissociated from any territorial anchor point, even though they obviously rely on technical infrastructure (networks, huge computing centers) located on the surface of the Earth. This is known as cloud computing;
– they are egalitarian, non-hierarchical and inclusive, in the sense that authors/creators, readers/viewers, critics/curators and documentalists/organizers can exchange roles13;
– they are open, in the sense that they allow real-time interaction and direct access and manipulation;
– they have laid the foundations for a form (albeit still limited) of participatory collective intelligence through creative conversation, which I outlined in Chapter 4.
If the capacity for automatic manipulation by software agents is combined with the pervasiveness and interconnectedness of digital memory, we get the potential power of the collective intelligence of online communities. This power is still only potential, because there are major obstacles that prevent creative conversations from taking full advantage of the technical potential of the digital medium. These obstacles can be divided into three interdependent groups: (i) the compartmentalization of symbolic systems; (ii) the non-computable – or not readily computable – nature of these systems; and (iii) the opacity maintained by the big oligopolistic corporations that actually control access to shared memory.
12.2.4. The compartmentalization of symbolic systems
The first obstacle concerns the multiplicity of symbolic systems and their compartmentalization. In this regard, we need to distinguish between data and metadata. The term data designates archived documents (texts, images, sounds, programs, magazines, books, recordings and films, digitized or not) while metadata designates annotations added to the documents in order to organize, find and filter them (abstracts, key words, subjects, evaluations, etc.). With respect to data, to begin with there are huge numbers of natural languages and there are still no systems of automatic translation that are both general enough and reliable enough. With respect to metadata, there is the additional problem of the multiplicity of storage systems. During the 19th and 20th Centuries, many systems of indexing and cataloguing were developed by librarians and documentalists. Earlier in this book I mentioned Dewey’s hierarchical decimal system, Ranganathan’s faceted classification and Otlet’s pioneering attempt at hypertextual classification14. In their times, all these systems were essentially designed to manage collections of material documents in physical buildings. As long as the collections of libraries and documentation centers were separated by large geographic (and cultural) distances, the diversity of classification systems did not pose too many practical problems. In an era of online convergence of geographically dispersed memories, however, the absence of harmonization makes itself painfully felt. In addition to the many documentary languages used by administrators of important collections, each culture, intellectual tradition, discipline or theory has its own terminology and its own classification of concepts. The way “subjects” or concepts are organized is, like language itself, an essential dimension of thought. There is thus no question of imposing some uniform classification on anyone in order to facilitate online research, and even less of imposing English as the sole language. That is why I am hypothesizing that the solution can only come from a metalanguage capable of encoding the diversity of languages or, if you will, from a universal system of semantic coordinates through which as many different classifications as desired can be projected.
12.2.5. The non-computability of symbolic systems
The second group of obstacles concerns the difficulties encountered by computer engineering in expressing the meaning of documents, using general methods. It is well known that there is enormous grammatical variation in the actual use of natural languages (this is part of the normal life of languages), that words have many senses and that different expressions can mean practically the same thing, not to mention differences of interpretation depending on context. For this reason, the main methods of automatically analyzing texts in natural languages are based essentially on statistics, which means that algebraic or topological processing of meaning – which is more reliable – is currently largely unattainable.
In comparison, the positional number notation system (whether base 10, base 2 or other) permits a universal one-to-one interpretation of the meaning of every digit according to the place it occupies in an expression. The concept corresponding to the sequence of digits (the number) can therefore be deduced automatically from that sequence. In contrast, the alphabetical notation of words in natural languages results in arbitrary codes – chains of characters – that it is still possible to compare or connect with other chains of characters (other words that have the same meaning, for example), but without the characters or their arrangements being directly interpretable semantically. In fact, the elementary symbols here represent sounds, not elements of meaning. In short, for symbol-manipulating automata, numbers noted in Indo-Arabic ideography are directly accessible (or transparent), while expressions of concepts in natural languages, noted in alphabetical characters, are semantically opaque. The compartmentalization and non-computability of symbolic systems constitute a formidable obstacle to the ideal of semantic interoperability, as computer engineers call it. But the opacity of the Web is also caused by factors that are not technoscientific in nature.
12.2.6. The opacity of the Web
There is no question here of denying that commercial search engines provide a service to Internet users. I would simply like to point out the limitations of these services. I note, to begin with, that Google, Bing or Yahoo only index approximately 25% of the mass of documents on the Web. The rest is called the “deep Web” by experts in information research. In addition, commercial search engines base their searches on chains of characters, not on concepts15. For example, when a user enters a request for “dog”, this word is processed as the sequence of characters “d, o, g” and not as a concept translatable into many languages (chien, kelb, perro, cane, etc.), belonging to a subclass of mammals and domestic animals, and constituting a superclass that includes bulldogs, poodles, etc.
Not only do the major commercial engines not permit searches for concepts (instead of words in natural languages), but they are also incapable of adapting to atypical perspectives16, sorting results according to criteria chosen by the user, assigning a value to the information, etc. Their search algorithms are uniform and static. On top of all this, they are notoriously lacking in transparency, since their search algorithms are commercial secrets. Their main aim is to bring in maximum advertising revenues from Internet users’ clicks. All this explains why it is much easier to obtain a relevant result when you know what you are looking for than when you want to freely explore the mass of information available. Moreover, the big corporations of the Web Consortium (Google, Yahoo, Microsoft, AOL, etc.) and the leaders in social media (Facebook, Twitter, MySpace, etc.) exercise a powerful control over search services through their huge distributed databases. This control gives them the power to censor certain data or bias search results. Finally, the centralized services of search engines, messaging and social networks allow a small group of oligopolistic corporations to market the huge quantities of information produced by Internet users during their activities. In other words, contemporary Internet users are dispossessed of the information they collectively produce, which they could use to benefit their collective intelligence and human development in general.
12.2.7. An unfinished matrix
Information and its automatic processing agents are becoming materially unified in a virtual memory common to all of humanity, but because the barriers, compartmentalization and semantic incompatibilities have as yet only been very partially removed, the growth of collective intelligence, though remarkable, has fallen far short of what it could be. Should we be surprised by this? The vast majority of systems for encoding meaning that are available today were invented and refined long before the existence of the digital medium. This medium itself has existed for the global public for less than a generation. Techno-symbolic support for the new cultural matrix is unfinished. Promoters of the use of shared memory to serve creative conversations and human development are therefore confronting the problem of inventing, adapting and perfecting a new generation of symbolic systems that will be in keeping with the unity of memory and the processing power now available. In order to place my solution to this problem in context, I will now describe the progress that has been made in the construction of the digital medium, where the techno-symbolic matrix of the knowledge society and its information economy is gradually being created.
The basic structure of the contemporary online collective memory can be analyzed as a nested series of layers of addressing. These different layers of the digital medium were developed successively over time and each one needs the existence of the preceding ones in order to function. The first layer (the operating systems of computers) addresses the elementary bits of information at the physical level of the circuits and hardware of the symbol-manipulating automata. The second layer (the Internet) addresses the automata that receive, manipulate and transmit digitized information in the communication network of cyberspace. The third layer (the Web) addresses the pages of documents and, soon, the data of which those pages are composed. The addressing system of the Web makes it possible to create hypertext links among data. As readers already know, I feel that it has now become necessary to implement a fourth layer of addressing: a system of coordinates for mathematically mapping out a universal and practically infinite semantic space. This fourth layer of addressing will make it possible to address, manipulate and evaluate data automatically, based on the semantic metadata that represent them, while paving the way for a multitude of semantic perspectives and games of the information economy (or collective interpretation games). For purposes of demonstration, the approach proposed here emphasizes the logical and symbolic dimensions of the digital medium more than its hardware.
12.3. The evolution of the layers of addressing in the digital medium
12.3.1. The era of big computers (addressing of bits)
The entire structure of the digital medium is based on mathematical logic and binary encoding of information, which became standardized in the mid-20th Century. Conceptually, the two main components of a computer are its memory and its processor. The processor reads, writes and deletes information in the memory. Thus the memory’s addressing system is essential to the functioning of logical automata. It is usually the operating systems of computers that manage the physical addresses in the memory.
From 1950 to 1970, computers were still only operated by experts. Human– machine communication took place, logically and symbolically, through complex programming languages, and physically through perforated cards or tapes and rudimentary printing systems. They were used mainly by big corporations and public administrations in rich countries, for scientific calculation, statistics and accounting. Computer technology in this era was centralized, centralizing and dominated by the major hardware manufacturers (IBM).
Figure 12.2. The first three addressing layers of the digital medium

The development of computer technology starting in the 1950s created the technical conditions for a remarkable increase in the arithmetic and logical processing of information. The layer of addressing of bits of information on the hardware, an inheritance from the early days, is still present today and is the basis of the digital medium. At the level of the machines that make up the nodes of the big network, this addressing is managed in a decentralized way by various computer operating systems (such as Unix, Windows, MacOS, etc.) and is used by software applications.
12.3.2. The age of personal computers and the Internet (addressing of automata)
With the mass production and falling prices of microprocessors, the 1980s and early 1990s saw profound changes in the world of automatic calculation. Thanks to new communication interfaces (icons, mice, multiple windows, etc.) between machines and users and the marketing of applications adapted to users’ needs, nonexperts were beginning to operate machines and manipulate data without programming. The PC increasingly became the essential tool for calculating a budget or creating and publishing texts, images and music, and there was a proliferation of recreational and educational applications. This period of decentralization in information technology was dominated by companies that designed the interactive experience of users (Microsoft, Apple). Scientists, professionals, urban youth and office employees in rich countries took possession of the power of computers. At the same time, personal computers and information servers were starting to be interconnected in many networks, which would later be linked in the Internet. Computers became a medium for communication and collaboration, and increasing numbers of virtual communities began to develop. A powerful drive to digitize information led to a convergence of the previously separate fields of telecommunications, media and computer science.
During this period, a new layer of universal addressing was adopted. In order to be able to exchange information with other computers, every information server now had an address assigned according to the universal protocol of the Internet. IP (Internet Protocol) addresses are used by the information routing – or switching – system that makes the interconnected networks function. In the 1980s, the main uses of the Internet were electronic mail, discussion forums, file transfers and remote calculations: the Web did not yet exist.
12.3.3. The era of the Web (addressing of data)
The small team assembled around Tim Berners-Lee at the CERN in the early 1990s succeeded in giving technical expression to the long-cherished dream of visionaries such as Vannevar Bush, Douglas Engelbart and Ted Nelson, who had foreseen the interconnection of digital documents, whatever their physical location, through hypertext links.
The secret of this technical exploit, which was simple in principle, was once again a universal addressing system. After the addressing of bits in the memories of individual computers and the addressing of servers in the network that makes the Internet work, the third layer of the digital medium, the World Wide Web, addresses the pages of documents or other information resources. The address of a page is called a URL (Uniform Resource Locator) and the links between documents are processed according to the HTTP (Hypertext Transfer Protocol) standard. Browsers and search engines would obviously be incapable of processing hypertext links in a standard way if their source pages and target pages were not addressed according to a universal protocol. Note that the HTML (Hypertext Markup Language) standard permits the graphic display of pages independently of the many operating systems and browsers employed by Internet users.
The spread of the Web beginning in 1995 led to the opening up of the global multimedia public sphere we see developing in the early 21st Century. Based on high-speed communication, wireless technologies and portable devices of all kinds, this new public sphere has given rise to an explosion of electronic commerce, the growth of online social networks, the development of virtual massively multi-player gaming environments and the spread of collaborative knowledge management technologies in education and business.
After the decentralization of the era of PCs and the Internet, the era of the Web marks a new phase of centralization. Information search services (Google, Microsoft’s Bing, Yahoo), personal contact services (wireless telephone, major social media such as Facebook or Twitter) and sales services (Ebay, Amazon) are concentrated in the hands of a few big corporations that operate huge data centers. These veritable information factories – the new hardware of cloud computing – assemble hundreds of thousands of interconnected computers in buildings under tight security, consuming the amount of energy produced by a small electrical plant. In practice, then, the constantly expanding global online memory is being used by “central computers” of a new kind. Scattered around the world to be closer to demand, these data centers are directly connected to the main channels of the Internet and are capable of processing staggering amounts of information.
The third layer of the digital medium is further enriched by a set of technologies its promoters – mainly Tim Berners-Lee and his collaborators in the World Wide Web consortium – were calling the “semantic Web” a few years ago and now call the “web of data”17. In a recent article, I discussed the web of data, its formats (XML (Extensible Mark-up Language), RDF) and its OWL18. Suffice it to say here that from my perspective – and as Tim Berners-Lee himself says – the web of data is an improvement of the World Wide Web or completes it. It is not a new basic layer of the digital medium. Indeed, the fundamental addressing system of the web of data is still the familiar URLs19. These are opaque because of the way they are constructed20. They function like physical addresses in a telecommunications network or access codes to information in a distributed database, and not as coherent semantic variables of a transformation group. The very axiomatics of the Web require the absence of an essential relationship between Web address and meaning.
12.3.4. The era of the semantic sphere (addressing of ideas)
With respect to the digital medium, the only thing that is certain is that the story is just beginning. There is no reason to believe that the technological basis of the new cultural matrix, the major features of which I outlined in the previous sections, has reached its final state. Digital encoding, while it is certainly fundamental, is only the first layer of a gigantic pyramid of superimposed codes, norms, languages and interfaces that link electronic circuits (and soon optical or bioelectronic circuits) to human users. This multilayered structure of transcoding is likely very far from finished. Paradoxically, just when the growth and diversification of the uses of the digital medium are strongest, software engineering (which today excels in the design of interfaces and applications) is having difficulty renewing its fundamental concepts. Problems involving the complexity of meaning and its interpretation – which are among the classic themes of the human sciences – can no longer be circumvented by the builders of the new global communication space. It may be that the initiative for the construction of the digital medium will, at least in part, lie with intellectuals trained in the human and social sciences. After all, the logic incorporated into computer programs and electronic circuits was first formalized by philosophers, starting with Aristotle. We have seen that semantic refinements (which are even more subtle than those of logic) can also be formalized mathematically. Who better than human sciences researchers (with the help of computer scientists) to tackle the task of creating a scientific mapping of socio-semantic phenomena?
To supplement the Web’s opaque data addressing system, I am therefore proposing the construction of a transparent addressing system for metadata based on the grid provided by the STAR-IEML semantic sphere. As shown in Figure 12.3, the USLs of the semantic sphere are the counterparts of the URLs of the Web. It is thus not a matter of replacing the Web, since it will still be indispensable for addressing data in the digital medium, but of adding a new layer of addressing – a public, transparent protocol – that will permit us to interpret and use the data of the Web much better than we do today.
Coordinated by the semantic sphere, all the symbol-manipulating automata interconnected by the Internet and all the data interconnected by the Web would enter into a form of higher synergy, qualitatively different from that existing today. The addition of this fourth layer of addressing would enable the digital medium to cross a threshold and begin to reflect our collective intelligence scientifically. With the Hypercortex addressed by IEML, the digital medium will reach maturity.
Figure 12.3. Addressing layers of the Hypercortex

12.4. Between the Cortex and the Hypercortex
12.4.1. Parallels between the Cortex and the Hypercortex
To put the anthropological function of the Hypercortex that will soon emerge from cultural evolution into perspective, I will compare it to the human cortex that emerged from biological evolution.
As we have seen in Part 1, human cognition combines sensory-motor experience of the phenomenal world (which is common to all animals with nervous systems) with discursive thought based on symbol manipulation. We can consider phenomenal experience as an implicit, or opaque, kind of knowledge, and its creative translation into the terms of symbolic systems as an explicit, transparent kind of knowledge. Insofar as it is symbolized (explicated), knowledge can be shared and transformed more easily than the (opaque) knowledge that is part of phenomenal experience. Supported by the human Cortex that has emerged from biological evolution, the dialectic between phenomenal experience and discursive symbolization expresses the original form of our intelligence. It is because of this engine of reciprocal transformation between implicit perception and explicit language that we are able to socially coordinate our cognitive processes more effectively than other social animals and share a cultural memory. The symbolic representation of the categories that organize our experience opens up for us a dimension of reflexivity unknown to other animals: we are able to represent our own cognitive processes to ourselves, recognize the gaps in our knowledge and ask questions. We can also envision the cognitive processes of others, imagine their subjectivity, negotiate the meaning of shared situations and agree on norms for reasoning and interpretation. We are capable of dialog. Finally, our narrative capacities permit us to produce and receive complex space–time models of phenomena, stories in which actors (grammatical subjects) bring about various changes (verbs) in objects in a complex intertwining of causal sequences and cascading citations. We all produce different narratives of our lives and the environments in which they unfold, but the narrative capacity is universal in the human species.
Now let us draw a parallel between the huge mass of interconnected multimedia digital data that oscillates and fluctuates on the Web and the phenomenal experience or implicit knowledge contained in the vast techno-cultural Hypercortex. The Web is certainly a hypertext, but it is an opaque hypertext, fragmented among languages, classifications, ontologies and commercial platforms, a hypertext whose nodes are ultimately only physical addresses. If we want to use the Web to coordinate our collective intelligence and share our cultural memories on a new scale; if we want to more clearly represent our processes of social cognition to ourselves, identify blind spots in our knowledge and augment our capacities for critical questioning; if we want to progress toward better intercultural understanding and cultivate the effectiveness of our creative conversations; if we want, finally, to increase our capacity to construct and interpret digital narratives by using the calculating power available, then we will have to complete the digital medium with a new layer of addressing and semantic calculation. This new layer will creatively translate the real but implicit (its interconnection is opaque) knowledge content of today’s Web into a knowledge content whose explicit meaning is transparent to automatic symbol manipulation (the transparent hypertext of USLs, as shown in Figure 12.4, coordinated by the IEML semantic sphere). Symbolic manipulation based on the explication of categories is a “trick”, an inherent capacity, of the human species. Here this means simply using the same old trick on another level – the meta-level of automatic processing of semantic information in a universal, ubiquitous memory.
Figure 12.4. Augmentation of the cortex by the Hypercortex
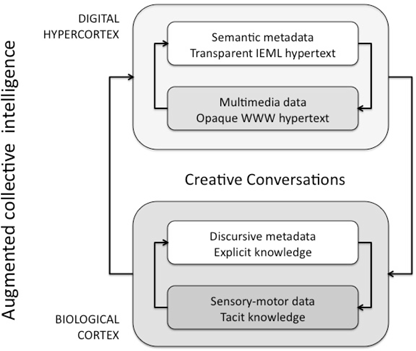
Just as the secret of the human biological cortex lies in a dialectic between phenomenal experience and discursive thought, the secret of the digital Hypercortex may be found in a reciprocal correspondence between opaque networks of multimedia data and transparent circuits of semantic metadata. Since discursive thought can only be expressed in phenomenal form (the signifiers of the symbols are classes of sounds, images, etc.), the process of calculation on the semantic metadata will necessarily have to take the form of calculations on data: once again, the addressing system of the Web as it exists today will still be necessary as the “physical” medium for the semantic mechanism. Going from one layer of addressing to the next, the semantic sphere is based on the Web, which is based on the Internet, which itself interconnects physical automata whose operating systems address bits21.
How autonomous will the new Hypercortex be? I am well aware that science fiction stories and the prospect of a “singularity” as discussed by Kurzweil often evoke the threat of machine intelligences becoming autonomous. I have elaborated on this point already22, but I must mention here that in the early decades of the development of computers, all journalists and most scientists talked about nothing but artificial intelligence and autonomous machines. Only a few rare visionaries (such as Douglas Engelbart and Joseph Licklider) were working – amid general indifference – toward the augmented intelligence and collaboration that would follow. In fact, the actual development of the digital medium gave rise to a new universe of communication and cultural creation rather than to artificial intelligence (unless we call any symbol-manipulating automaton artificial intelligence). The coming Hypercortex is techno-cultural and socio-semantic. It has no existence outside its link to the biological Cortex. Of course, the production and interpretation of data will be augmented by symbol-manipulating automata, programs themselves supported by physical machines. It will always be living human beings – driven by their phenomenal experience and discursive thought steeped in emotion – who will read, write and program, who will express themselves and interpret the messages of their peers, who will interweave the virtual multimedia universes of culture and the space–time territories of nature. What is more, the addition of semantic metadata to the data of the Web, like the translation of these metadata into multimedia images, will involve interpretation. This interpretation will be able to be automated, but this could be done in any imaginable way, depending on the needs, desires and orientations of widely varied communities. It is the processes of creative conversation that will organize the relationship between the biological Cortex of an individual and the digital Hypercortex of the species. It is creative conversations that will link the (opaque) network of the data of the Web and the (transparent) circuits of the metadata of the semantic sphere.
12.5. Toward an observatory of collective intelligence
As shown in Figure 12.3, the Hypercortex develops over time, emerging from the superimposition of successive layers of addressing. In Figure 12.4, the emphasis is on the structural symmetry between cortical cognition and hypercortical cognition, and on the central role of creative conversations in controlling the relationship between the Cortex and the Hypercortex. I would now like to present a third perspective on the Hypercortex: that of the conditions required for the construction of a mirror of collective intelligence, as shown in Figure 12.5.
The Hypercortex is represented here as an observatory or mirror of cortical cognition. The mirror as a whole may be seen as two linked spheres: the logical sphere (the Internet) and the IEML semantic sphere. Materially, the existence of the Internet is obviously necessary for the functioning of the semantic sphere. The semantic circuits are simulated by electronic circuits coordinated by the Internet. The units of semantic information (IEML models of ideas) connect URLs to USLs and, finally, Web applications implement collective interpretation games of the hermeneutic memory.
Figure 12.5. Model of the Hypercortex

12.5.1. Sensory-motor interfaces
The contemporary (2011) digital medium corresponds roughly to what could be called the logical sphere. This sphere is based on digital encoding, the availability of logical automata for operating on binary encoded data, universal communication of these automata through the Internet and, finally, universal addressing of data by the Web. I defined this universal logical sphere in terms of a few basic characteristic properties, which I recall here. First, it permits automatic manipulation of symbols and, consequently, of multimedia digital data of all kinds. Next, it should be noted that these data can be interconnected, compiled and differentiated at will. Finally, both the interconnected multimedia data and the calculating power are now available ubiquitously by means of all kinds of non-invasive interfaces (pervasive computing, various wireless devices and augmented reality). There is thus no doubt that the digital medium has the technical capacity to reflect back to creative conversations and the individuals participating in them personalized images, calculated in real time, of the subjects or processes that interest them. It is through the logical sphere of the Internet and its sensory-motor interfaces that the Hypercortex will be linked to human bodies, and thus to the Cortex.
12.5.2. The IEML semantic machine
The semantic sphere corresponds to what I have called the fourth layer of encoding of the digital medium. The semantic sphere is itself generated by the IEML semantic machine. This machine may be visualized as an abstract mechanical spider navigating and weaving the semantic sphere. As we saw above, this machine may be broken down into: (i) a textual machine based on IEML; (ii) a linguistic engine based on the STAR dialect; and, finally, (iii) a conceptual machine that traces and measures circuits in the semantic sphere. Let us consider the nodes of the semantic sphere (the USLs translated into natural languages) and their relationships as the variables of an algebraic system of symmetric transformations. The conceptual machine can then be defined as the interoperable set of automata manipulating these variables. No one will be surprised to find that the heart of this mechanism of reflection is a machine implementing a system of symmetrical operations.
12.5.3. The semantic sphere
The semantic machine models the heart of the human symbolic faculty: the semantic functions, which permit the manipulation of explicit concepts. Woven by the semantic machine, the semantic sphere coordinates the universe of concepts. The mathematical demonstration that the semantic machine can actually be implemented also proves that the semantic sphere can be simulated.
Let us imagine a huge fractaloid circuit in which the junctions (the USLs) and the channels (the semantic relationships) are translated into natural languages. This hypertext, which is transparent to calculation, places the world of ideas in a unique system of semantic coordinates. Symbolic cognition then belongs to a practically infinite nature that is coherent and describable in calculable functions that combine – as much as possible – the operations of transformation groups. It thus becomes scientifically knowable.
The USLs translated into natural languages are the densely interconnected nodes of a conceptual monadology. Each USL represents a concept that is formally defined by its relationships or semantic links with other concepts. The set of semantic links among the USLs forms the topology of a consistent cosmos. The semantic sphere encodes a huge number (beyond the recording capacities of the physical universe) of distinct concepts and semantic relationships among these concepts. Both the USLs (representing concepts) and the semantic circuits among the USLs belong to a single system of algebraic transformations and thus form the variables of an unlimited diversity of functions that are calculable by the semantic machine. The transformations and paths in the universe of concepts modeled in this way represent the movements of discursive thought.
12.5.4. The IEML metalanguage: the key to semantic interoperability
The Web is gradually encompassing all of human memory, and its public content is increasingly becoming the corpus of the human sciences. The new scope of this memory confronts us with a unique problem of coordination, which has two facets: semantic interoperability is a serious problem for engineering, and knowledge management is a serious problem for the human sciences23. The existence of a calculable, interoperable scientific language for encoding concepts solves both the problem of semantic engineering and that of the human sciences by providing a system of semantic coordinates that has until now been lacking. The nucleus of this language exists. All it needs to become fully operational is to be developed lexically and instrumentally.
The STAR dictionary contains 3,000 terms in 2011. This is obviously not enough, but it nevertheless proves that the construction of a dictionary is possible. Since its scientific (mathematical and linguistic) foundations are solid, a team of engineers and researchers in the human sciences could work with full confidence on the development of the STAR dictionary and computer applications for using the metalanguage. With the STAR linguistic engine, each valid IEML expression will be translated automatically into a multitude of natural languages. IEML could thus be used as a bridge language, which means that the solution to the problem of semantic interoperability is in sight. For the human sciences, the availability of a scientific metalanguage will lead to new methods of knowledge management. IEML will improve collaboration among research teams working with different hypotheses, theories or organizing narratives. In fact, the same metalanguage makes it possible to say a thing and its opposite, to categorize the same data differently and to categorize different data the same way. Rival schools of thought will thus be able to use the same language of semantic metadata exactly the way enemy armies use the same system of geographic coordinates. If we want a Hypercortex that serves the needs of knowledge management and competitive cooperation in the human sciences (whose basic corpus is now none other than the Web itself, i.e. logical memory), then this Hypercortex must reflect collective human intelligence from all possible points of view while ensuring the interoperability and comparability of these points of view.
12.5.5. Ecosystems of ideas: introduction to hermeneutic memory
The Hypercortex will reflect collective human intelligence not only in terms acceptable to the human sciences, but also in a manner that will improve their tools, methods and modes of collaboration, without imposing any kind of epistemological, theoretical or cultural bias24. I express this condition by saying that the Hypercortex will contain a hermeneutic memory. As we know, hermeneutics is the art of interpretation of texts or signs in general. I have chosen the adjective hermeneutic to describe the memory of the Hypercortex in order to clearly indicate its perspectivist dimension25. The memory of the Hypercortex will accommodate open hermeneutic activity without imposing any particular method of interpretation.
There can be no intelligence without memory. Human collective intelligence is a mechanism of memory: cultural traditions (i.e. trans-generational memories) are organized by symbolic systems such as languages, sciences, religions, laws, esthetic rules and genres, and political structures. This means that a memory that contributes to the reflection of collective intelligence cannot just be a simple accumulation of data. It must also represent the divergent points of views from a multitude of cultural traditions and symbolic systems. This requirement implies complete freedom of interpretation of data. That is why the hermeneutic memory will allow the conception of all kinds of functions of categorization and evaluation of data (functions of perception) and of production and association of ideas (functions of thought), as well as the composition of a multitude of collective interpretation games combining these functions. To represent the value or weight of the symbolic energy that is distributed and exchanged in ecosystems of ideas, the collective interpretation games will model dynamics of current in the circuits of the semantic sphere. The hermeneutic memory of the Hypercortex will thus contain an open semantic information economy, in the sense defined in Chapter 6.
The openness of the hermeneutic memory accommodates the need to explore new points of view on the shared corpus and allow competition among different methods of categorization, evaluation and semantic interconnection of data, i.e. different ways of knowing and interpreting. This point is as essential for the vitality of the human sciences as for freedom of thought in general. The semantic addressing, evaluation and theoretical or narrative presentation of data are hermeneutic constructions (i.e. interpretations) that are free and plural, and as such deconstructable. All schools of thought will be able to model their own universes of discourse and their collective interpretation games in the Hypercortex. It will be impossible to impose a collective interpretation game on a creative conversation that wants a different one. At the same time, on a broader scale, the rivalry of schools of thought will serve cognitive cooperation. Indeed, since the different collective interpretation games organizing the memory will use the same metalanguage, the same semantic playing field, it will become possible to compare meanings, knowledge and practical orientation effects produced by competing universes of discourse, narratives and games.
12.6. Conclusion: the computability and interoperability of semantic and hermeneutic functions
As shown in Figure 12.5, the logical sphere (the Internet) and the semantic sphere (IEML) cooperate to make the Hypercortex work.
The logical sphere performs the functions of data storage and arithmetic and logical calculation. It makes a multitude of ubiquitous sensory-motor interfaces available to users.
The semantic sphere ensures the computability and interoperability of semantic functions (production, connection and transformation of concepts) and hermeneutic functions (production, connection and transformation of ideas). It is based on an artificial language that generates a “semantic topology”, i.e. a universal system of calculable semantic coordinates. This system of coordinates permits the collaborative categorization and evaluation of data by means of a multitude of collective interpretation games.
The Hypercortex reflecting collective human intelligence responds to a “transcendental deduction” of the conditions of possibility of a scientific modeling of the mind26. The most fundamental condition for the possibility of the Hypercortex is a semantic machine capable of working with a universe of concepts. Since this machine is abstract, or formal, in nature, its existence depends on its mathematical definition and proof of the calculability of its operations. Since I have formally defined this machine and demonstrated the calculability of its operations, it therefore exists (formally)27. The virtual existence of this machine ensures that scientific modeling of the world of ideas is possible. The beginnings of a multilingual STARIEML dictionary show that it is also possible to weave the semantic sphere of USLs and translate its great hypertext network into natural languages28. Therefore it seems to me that it has been established that IEML can effectively play the role of a system of semantic coordinates for a multitude of collective interpretation games driving a huge ecosystem of ideas. I deduce from this that it is practically feasible to organize the data of the Web (which are currently rather opaque) in a perspectivist and transparent hermeneutic memory. Finally, it is obvious that if this hermeneutic memory were to take form, the ubiquitous multimedia digital medium could reflect back to creative conversations and their participants the synthetic, personalized, interoperable images of their collective interpretation games.
Once again, it is difficult to predict the pace of these developments and all their scientific and cultural implications. The technical and organizational effort required will certainly be considerable. Since the conditions of possibility of a Hypercortex containing a hermeneutic memory already exist formally, and since the network of creative conversations that will decide whether to take this path to cognitive augmentation will gain some advantage from it in terms of human development, I predict that the digital medium will sooner or later become the scientific mirror of collective intelligence.
1 See Neuronal Man, by Jean-Pierre Changeux [CHA 1985], or Neural Darwinism, by Gerald Edelman [EDE 1987]. It should be noted that I am not saying that human cognition is determined by neural activity, but that it is based on neural activity.
2 I am referring to the work of Goody, Ong, Havelock, Logan, Jaynes, etc. See the bibliography: [BOT 1987, GOO 1977, GOO 1987, HAV 1988, JAY 1976, LOG 2007, ONG 1982]. On the way in which intellectual disciplines such as rhetoric (including its spatial and iconic dimensions) have influenced cognitive activities, see Yates and Carruthers [CAR 2000, YAT 1974].
3 See Edwin Hutchins, Cognition in the Wild [HUT 1995].
4 See [GOO 1977, GOO 1987, HAV 1988, ONG 1982].
5 See Innis, McLuhan and, more recently, Robert Logan: [INN 1950, LOG 2004, MAC 1964].
6 On this point, see Robert Kaplan, The Nothing That Is: A Natural History of Zero [KAP 1999], and Georges Ifrah, Universal History of Numbers: From Prehistory to the Invention of the Computer [IFR 1998].
7 The reference on this subject is Elisabeth Eisensteins book [EIS 1983].
8 See Sylvain Auroux [AUR 1994].
9 See Elaine Svenonius [SVE 2000].
10 See Internet World Stats: http://www.internetworldstats.com.
11 I am writing this in 2010.
12 On this point, see section 4.3.3.
13 In reality, of course, certain actors produce more or are more influential than others. I am speaking here of the general organization of the communication mechanism, which gives no privilege or monopoly in principle to certain professions or certain institutions.
14 See section 4.3.2.
15 I remind the readers that RDF means Resource Description Framework and that OWL means Ontology Web Language. Both are standard file formats recommended by the WWW consortium. The fact that many major search engines recently began to take metadata into account using the RDFa standard only solves this problem very partially, as we will see. Moreover, “semantic” search engines (Powerset, Hakia, etc.) using algorithms for processing natural languages usually process English only, and very imperfectly at that. The purchase of Metaweb (which organizes the Freebase database with the tools of the web of data, RDF and OWL) by Google seems to be a sign of a “semantic” change in direction for Google, but within the limited paradigm of traditional artificial intelligence; see my (constructive) criticism of artificial intelligence in Chapter 8.
16 The search and “page ranking” algorithms are not customizable.
17 Or “linked data”.
18 See [LÉV 2010a].
19 I will not go into the subtle distinction between URLs and URIs in this book (more information can be found by consulting experts on the web of data or WC3 documents, such as: http://www.w3.org/TR/uri-clarification/) and I will still talk about URLs.
20 See the basic WWW Consortium document on this subject: http://www.w3.org/DesignIssues/Axioms.html#opaque.
21 See Figure 12.2.
22 See section 8.2.
23 See Chapters 4 and 5.
24 See Chapter 5 on the epistemological transformation of the human sciences.
25 Perspectivism is used here in the philosophical sense, as in Leibniz or Nietzsche.
26 On the concepts the transcendental and conditions of possibility of knowledge in general, see The Critique of Pure Reason, by Immanuel Kant [KAN 1787].
27 See the chapter on semantic topology in Volume 2 and, meanwhile, [LÉV 2010b].
28 On the work under way in building the dictionary, see [LÉV 2010c].