
Chapter 12
vCloud Design
In this chapter, we'll examine how server profiling, networking design, storage design, high availability, DRS, and many other technologies apply to a vCloud Director design. This chapter assumes that you already understand many of the definitions and the terminology used with vCloud Director.
This chapter will cover the following topics:
- Differences between cloud and server virtualization
- Role of vCloud Director in cloud architecture
- vCloud Director use cases
- Components of the vCloud management stack
- vCloud cell and NFS design considerations
- Management vs. consumable resources
- Database concepts
- vCenter design
- vCloud management physical design
- Physical side of provider virtual datacenters
- Logical side of provider virtual datacenters
- Virtual network switch
- Network pool decisions
- External networks
- Designing organizations, catalogs, and policies
- Correlating organizational networks to design
- End users and vApp networking
- Designing organization virtual datacenters
- Multiple sites
- Backup and disaster recovery
Differences between Cloud and Server Virtualization
We've often sat in presentations and heard the question, “Who is running a private cloud today?” and watched 95% of the hands in the room reach for the sky. Of course, everyone has their own opinion on this topic, because the term cloud is always open for debate. This conversation has taken place with many influential people in the industry, and the same question continually arises: What's the difference between cloud and server virtualization?
Server virtualization (or a virtualized datacenter) is what many of us have been doing for years: acquire a couple of servers, switches, and a storage array; install vSphere; and make the components talk to one another. From here we can begin to do some P2Vs or create new VMs through wizards, templates, and scripting. The main drivers behind virtualization are consolidation, simplifying disaster-recovery (DR) efforts and administration, and achieving a lower total cost of ownership. At the heart of this is running a multitude of virtualized operating systems on a hypervisor that virtualizes the underlying hardware. Pretty fascinating stuff, but is that cloud? Of course not; it's just a cool technology.
Transitioning to a cloud operating model is completely different. You've probably heard this analogy a thousand times: cloud is like electricity. When you flip on a light switch, the light comes on. You don't care if that electricity was generated by coal, solar, or water, but that the light is on. It takes more than just virtualization to move to a cloud operational model. Virtualization is a key enabler of cloud because without it, we couldn't dynamically create resources at such a rapid pace.
What does it take to move beyond server virtualization and into cloud? Let's break this down into a few components:
Role of vCloud Director in Cloud Architecture
VMware's definition covers many of these components, but it doesn't cover them all. Here is how vCloud Director addresses some of these components:
vCenter Chargeback uses vCloud Director polling to collect the data necessary to assign dollar values to virtual and physical resources and to provide automated reporting.
vCloud Director is complemented by vCenter Operations with a vCloud Director plug-in to collect data for operational readiness, offering a proactive approach to troubleshooting and to model the capacity of consumed resources and future planning.
It's fair to say that vCloud Director doesn't cover all facets of cloud architecture. vCloud Director is one component of an entire cloud infrastructure, but depending on your use case it may be all that is needed. Many vendors, including VMware, have additional products to fill in the gaps where vCloud Director is lacking in terms of portal use, automation, and chargeback. Like any good architect, it's your job to determine requirements and define the products that will fit your design. We'll examine these pieces further in the next section.
vCloud Director Use Cases
Before beginning to create a cloud architecture, you need to understand if the vCloud Director product is necessary for a particular scenario. There are often misunderstandings about vCloud Director's functionalities, and as an architect you need to know when and where it fits. Project Redwood was the internal codename of vCloud Director, and it was touted as the new generation of VMware's IaaS cloud offering. Vendors are working on vCloud integration by creating plug-ins with their products, and partners, contractors, and vendors are pushing for rapid adoption. VMware has a vision of vCloud as the next step in datacenter transformation. What does this mean for you as an architect? Virtualization is a key component, but it's only a stepping stone. If you're thinking of adopting vCloud, you have to ask yourself, “What am I really trying to accomplish?” The answer to this question is unique to each scenario.
Are you architecting for yourself or a service provider, an enterprise customer, or a Small to Medium Business? Are you looking for a portal with a self-service catalog? Are you trying to create multitenant networks? The answer to this question is unique for everyone.
Let's look at what vCloud Director offers in terms of a product. From VMware's definition of cloud and vCloud Director, we can examine what vCloud offers and start identifying requirements.
If you've looked at the vCloud Director user interface for an end user, it may not be that simple. Many times, you need to demonstrate how an end user deploys a vApp after vCloud is installed. Many users may find it very complex and that it won't meet their expectations and standards. Depending on the technical capabilities of the end user, you may need another off-the-shelf product to build a simple portal or to custom build a new portal from scratch to hook back into vCloud Director through APIs. After determining the requirements, you may discover that a portal with a few simple orchestrated workflows into vSphere is all that is needed to satisfy a customer's need and that vCloud Director isn't a necessary component.
A key point to mention is that vCloud Director can only provision virtual resources into vSphere. What if, in addition to VM provisioning, you also want to provide bare-metal provisioning, or to poke holes in a firewall somewhere, or to allow a user to request a new IP phone for their desk in a single catalog? vCloud Director won't be able to accomplish these tasks. This is another case where a custom-built portal or off-the-shelf product with integrations into orchestration tools will accomplish this goal.
First, vCloud can contain multiple global catalogs instead of a single ordering mechanism. Perhaps one global catalog has standard operating-system images of Win2K8R2, WinXP, WinXP_x64, Win7, Win7_x64, Ubuntu, and SuSE. Another global catalog offers ISOs of applications, such as SQL, Office, and Exchange. Yet another global catalog contains sets of VMs and applications packaged as a vApp, such as vApp1 = DB, app, and web server; and vApp2 = vCenter on 2K8, SQL on 2K8, and two ESXi hosts for a nested deployment of vSphere.
The other unique feature gives control to organizations so they can manage their own private catalogs. If a user in the development organization has a new beta code and they want to give other developers access to try it, they can upload that vApp into the development catalog to allow other developers to deploy it and test it out. This unique feature enables end-user capabilities without the constant need for IT intervention.
Let's examine some use cases and see if vCloud Director will fit.
Use Case #1
ACME Inc. has asked you to evaluate its environment to determine how it can become more streamlined. Today, a user requests a VM by sending IT an email with an attached Word document that specifies which OS and sets of applications are needed. The user has permission to request this VM from their manager. The VM will have an in-house application and will be used for test and development purposes. The VM can't interfere with the production network where the production application lives.
Is vCloud Director a good fit here? You have identified that the process to request VMs isn't efficient. The vCloud Director portal can easily accommodate itself to enable end users' requests. No approvals of workflows are necessary after IT receives the document; therefore, no additional orchestration is needed. The VM in question needs to be on a segregated network. You can assume that the network security team must use VLANs and ACLs to maintain segregation and not interfere with the production network. vCloud Director can create segregated Layer 2 networks to maintain isolation while using pools, so as not to burn up VLANs. This virtual machine is being requested for test and development teams, which is a good fit for vCloud Director.
Use Case #2
ACME Inc. wants to automate more of its processes. Users currently request everything through IT via an email ticketing system. The requests can range from fixing Outlook, to provisioning new applications on VMs, to facility maintenance. The infrastructure on the backend is completely segregated, and every department is billed for every request that comes into the ticketing system. For legal reasons, the security team is very stringent about making sure there isn't any information sharing between departments.
Is vCloud Director a good fit in this case? ACME has a system in place that creates tickets for requests beyond VM provisioning. There is also a chargeback system in place, but it's generic and doesn't take into account actual CPU, memory, storage, and network utilization. ACME has a critical need for segregated networks. vCloud Director could be a very good fit here. The vCloud Director portal wouldn't be used, but the API combined with an orchestration engine can substitute. When a new VM request is submitted through the email ticketing system, an orchestration engine can take over to complete approval emails and begin the provisioning of the vApps to vCloud Director. Because vCloud Director functionality includes segregated multitenant networks, it's much easier to satisfy requests in a shorter period of time. vCloud Director can use network pools to quickly create segregated Layer 2 networks without any interaction from the network team or security team. In addition, the chargeback process can be more granular based on certain VM types and utilization instead of a fixed cost per VM.
Use Case #3
ACME Inc. wants to enable its development teams to provision their own VMs but not have access to vCenter. The requirements state that there should be a portal with a catalog containing the VMs available to a team. After the team chooses the VM they wish to provision from the portal, the VM should be customized, added to the domain, and given an IP address on a specific VLAN in the corporate network so it can be easily accessed to test against production systems.
Is vCloud Director a good fit? In this case, vCloud Director wouldn't be a necessary component. Instead, as an architect you should focus on a series of orchestrated events through a custom-built portal. This custom-built portal can have a series of drop-down and text boxes for the user to specify the OS, application, computer name, and Active Directory forest for customizations. There isn't any stringent access control or segregation policy for the development teams, and the VM needs to have corporate network access.
As we dive further into vCloud networking, you'll see that external networks will satisfy this request without the need for vCloud's segregated Layer 2 networks. If the customer still wanted vCloud Director, it could be a component in this stack, but it wouldn't be necessary. The only thing vCloud Director can offer is a portal, a simple catalog, and workflows of creating VMs already prepackaged.
Use Case #4
ACME Inc. is a service provider that has built a successful vSphere hosting environment. Many of the tasks done today are scripted and automated to streamline the efforts of getting new customers online. ACME is continuing to expand within its datacenter and plans to add an additional datacenter 100 yards away to meet its growing needs. It needs a solution that can scale to meet future business-development needs.
Is vCloud Director a good fit in this situation? ACME has a good system, but it needs to be able to scale, and vCloud Director has that ability. You can assume that ACME has varying degrees of hardware available to its customers and charges based on the service-level agreement (SLA). Because vCloud Director can consume multiple vCenter Servers, the portal and orchestration engines will enable end users to choose the SLA that meets their needs more quickly instead of relying on homegrown logic. As ACME continues to grow, its range of VLANs and IP address space will diminish. If ACME's current solution is to dedicate 1 VLAN per customer, then its plan to grow beyond 4,000 customers in a single location is limited. In most cases with service providers, customers have 1 to 5 VLANs dedicated. vCloud Director can play an important role by creating segregated Layer 2 networks and making VLANs and IP address space go further with network pools.
vCloud Director was built with the service provider in mind—so much so that it requires a change in thinking. For an enterprise customer, the adoption of vCloud Director means IT becomes the service provider for their organization. It's hard for IT to own everything in vCloud Director, but it depends on the architecture. In some instances, the end user becomes responsible for many aspects of the VM, such as patching and policies. vCloud Director can contain mission-critical production VMs, but making sure they adhere to correct policies for continual maintenance is a different process.
Components of the vCloud Management Stack
You need to understand the components of vCloud Director so you can design for logical and physical management. To get vCloud Director up and running, the following minimum components are required:
- 1 vCloud Director cell (a cell is an instance of the software in a single server) installed on Red Hat Enterprise Linux (as of vCloud 5.1, the vCD Virtual Appliance isn't intended for production use)
- 1 vCenter Server (Windows or the Virtual Appliance can be used with 5.1)
- 1 DRS-enabled vSphere cluster
- 1 vCNS Manager server (formally known as vShield Manager)
- 1 SQL Server (contains the database for vCloud Director and vCenter)
vCloud Director may not satisfy all the requirements for a cloud environment, so other supplemental products are available to round out the portfolio. Adding any of the following products can potentially make up a cloud offering based on requirements:
- vCenter Server management components
- vCenter Server for vCloud resources
- Database servers, SQL/Oracle (1 required, 2 optional)
- Multiple vCloud Director cells (the number of nodes depends on the size of the vCloud environment and the level of redundancy)
- VMware vCenter Chargeback server (additional nodes can be added for data collectors)
- vCenter Orchestrator server (optional if other workflows need to be initiated)
- RabbitMQ server (Advanced Message Queuing Protocol [AMQP] based messaging; optional)
- vCenter Operations servers (1 database and 1 UI; optional components for monitoring and capacity planning)
- vCloud Automation Center server (originally DynamicOps)
- vCloud Connecter server
- vCloud Connector node
- vCloud Request Manager
- vFabric Application Director
- Load balancer (for incoming connections to vCloud nodes)
In this chapter, we'll focus solely on vCloud Director's required components and not on the entire ecosystem.
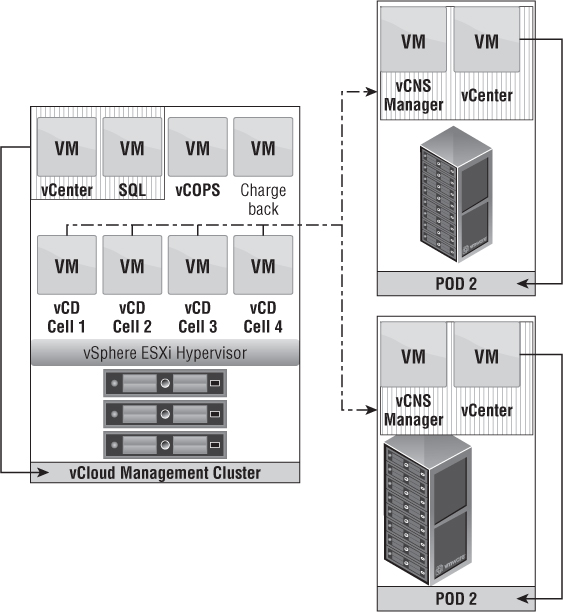
Figure 12.1 is a representation of the communication between components in a vCloud Director configuration. vSphere 5.1 added single sign-on (SSO) capabilities and can be used against vCenter and vCloud Director. SSO can only be used for cloud administrators and not for organizations within vCloud. In this diagram, vCenter has a DRS cluster of three hosts; vCenter has configured storage profiles for the datastores, and the DRS cluster can access all datastores; vCNS Manager has deployed edge devices to the cluster; and vCloud Director has a line of communication to the vCenter Server, vCNS Manager, and vSphere Hosts.
The vCloud Director software works as a scale-out application. You can install vCloud Director on multiple servers, and they will all handle incoming connections from a load balancer to satisfy end-user requests. As a cloud continues to grow, and so do end-user requests, additional cells can be added to satisfy those requests. Adding cells increases the resiliency of the application as well as redundancy. Every cell is mapped to the same database to keep changes consistent across the cloud. Best practice requires two cells at minimum for every production instance of vCloud Director. Having two or more cells provides cell redundancy, allows for planned upgrades and maintenance of the cells, and requires a shared NFS datastore for storing SSL certificates and the response.properties file for adding new cells.
Figure 12.1 There are many dependencies in the vCloud Director stack.
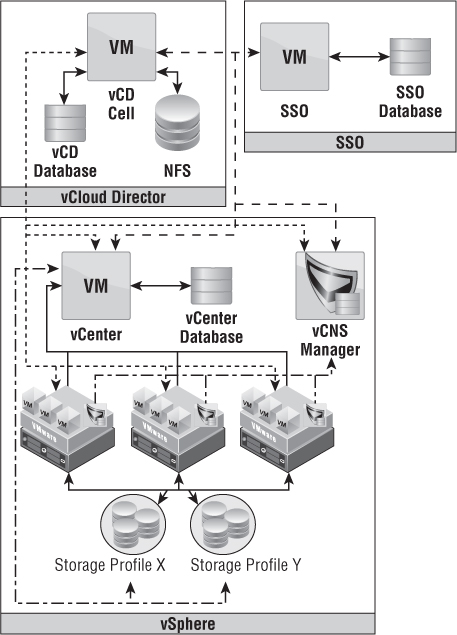
Every vCenter Server instance is paired with a vCNS Manager server. These two pieces work in a 1:1 fashion and are presented to vCloud Director as a pair when you add a new vCenter to vCloud Director.
Figure 12.2 shows the architecture of a multinode environment where two vSphere farms are added to vCloud Director.
vCloud Cell and NFS Design Considerations
Cell servers make fine candidates for VMs, but it's worth pointing out that cell servers can be physical as well—a design decision that you may need to make if a management or infrastructure cluster doesn't exist. Choosing a physical server may also be attractive for repurposed P2V hardware.
Depending on the vCloud requirements and vSphere architecture, vCloud Director cells may be fitted with various forms of hardware. Every vCloud Director cell should be provisioned with a minimum of two virtual NICs. One NIC is required for vCloud communication tasks, and the other NIC is bound to vCloud console connections. The vCloud console connection is pretty straightforward. It brokers the communication of the vCloud cell and the VM console to the end user. vCloud communication tasks are a bit more complex and include common server communication like DNS, vCenter Servers for API calls, the NFS server share for transfers, and the vCloud Director user interface.
Figure 12.2 vCloud Director relies on a 1:1 : mapping of vCenter Server to a vCNS Manager server.

If you plan to make the vCloud Director portal publicly accessible from the Internet, you may want to add an additional vNIC. Two vNICs are responsible for the vCloud portal and remote console connections from the Internet, and other vNICs are responsible for communication to internal systems and NFS shares. Other customizations on the interfaces are required, such as static routing to satisfy communication.
Every production instance of vCloud Director should include a NFS share that is greater than or equal to 200 GB. This NFS share is mapped to the vCloud cell's transfer directory and satisfies the transfer of vApps between cloud cells, transfers between vCenter Servers, and uploading and downloading vApps into catalogs. NFS servers may or may not be accessed via Layer 3. Therefore, an additional vNIC mapped to the NFS VLAN may be necessary to satisfy Layer 2 communication.
The NFS share design is dependent on the architecture of your cloud. Deploying vApps between vCloud cells and vCenter Servers into different Provider virtual datacenters (vDCs) relies on the NFS share. There can be three or more copy processes that need to take place for a vApp to finally find its home. The input/output operation (IOP) capabilities of the NFS share and the IP connection between vCloud components (1 GB versus 10 GB) play a role in how fast vApps are copied between locations. If your cloud doesn't consist of multiple vCenter Servers, then the NFS server isn't used because native vSphere cloning is used to speed up the process.
The NFS share can be hosted in a multitude of places. The preferred form is to have the NFS share created on the storage array that is also hosting the vCloud Director cells. This method puts the copy traffic very close to the source. Many storage arrays are not equipped with file capabilities and must rely on block storage. In this scenario, we can create a VM on a VMFS datastore to serve as the NFS share using a product like OpenFiler or any other standard operating system. Standard vSphere HA protection for this VM is suitable because traffic is only occurring during copy processes. The final option is to create an NFS share on a vCloud cell. This is not a suggested approach because the share may be inaccessible during vCloud upgrades on the hosted cell.
Management vs. Consumable Resources
When beginning to architect a vCloud Director design, you should always first identify two logical constructs. First is the infrastructure management cluster and second are the vCloud consumable resources:
- The infrastructure management cluster is a vSphere cluster that contains VMs responsible for the management construct of vCloud Director. This includes the core set of vCloud components such as vCloud Director, vCenter Server, vCenter Chargeback, vCenter Orchestrator, and vCNS Manager.
- vCloud consumable resources are groups of vSphere clusters managed by vCenter Server(s) that are designated as vCloud consumable resources where provisioned vApps will live. This is typically where SLAs are tied to the infrastructure, such as Gold, Silver, or Bronze.
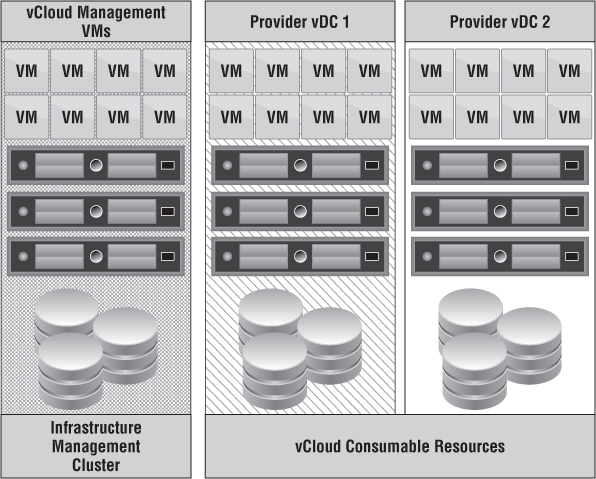
Identifying these two key constructs allows you to scale vCloud Director in parallel ways. As your cloud continues to expand, so must your management footprint. Separating these two constructs allows the following:
Figure 12.3 shows how a management cluster is responsible for the management VMs, whereas vCloud consumable resources are used to create Provider vDCs.
Figure 12.3 As your cloud : continues to grow, so must your management footprint.
Database Concepts
A vCloud Director cell is considered a scale-out application. Even though there are multiple vCloud Director cells, only a single database is created and shared among all cells. The design concept for the vCloud Director database is dictated by physical location and security access. The vCloud Director database won't incur high input/output (I/O) even during peak usage; many standard database servers can handle the additional database load from vCloud Director. vCloud Director only needs to write to its database for changes to the UI, to map resources to vCenter, and to handle other small pieces. It's mainly responsible for sending API calls to the vCenter Server and the vCNS Manager to deploy objects that affect their database I/O and not vCloud Director's. In addition, during the configuration of the database, parameters are set to make sure the database doesn't grow out of hand.
There are a few locations where you can place the vCloud Director database:
- You can use a highly resilient SQL cluster with sufficient bandwidth (>= 1 GB) to the vCloud cells.
- Depending on the size of the cloud infrastructure, the vCloud database can live on the same database server that is hosting other databases such as vCenter, vCenter Orchestrator (vCO), and SRM. This scenario keeps new database servers from being provisioned; additional databases can be added to the regularly scheduled backups or replication without much administrative overhead. This VM can live in the same management infrastructure as the cloud cells or have >= 1 GbE communication.
- A dedicated database server can be provisioned for vCloud Director. The vCloud Director database must use local authentication (LDAP isn't supported); therefore, it may be in the best interest of the security team to not compromise a primary database server with local logins. This creates a separation of management and allows the cloud administrator to be responsible for database activity.
- The SQL Server resources in all these scenarios should be identified and considered according to the input/output profile or workload that will be running on them.
vCenter Design
Two vCenter Servers are mentioned in the cloud portfolio model. This design concept correlates to the infrastructure management cluster and vCloud consumable resources discussion.
A vCloud Director recommended practice is to have at least two vCenter Servers. The first vCenter Server is responsible for hosting vSphere and/or vCloud infrastructure components related to the infrastructure management cluster. This vCenter is called the vCloud Infrastructure vCenter. The second vCenter Server (and subsequent vCenter Servers) is called the vCloud Resource vCenter(s) and is responsible for hosting vCloud consumable resources. Why are two vCenter Servers necessary?
Figure 12.4 depicts a scenario where a large organization already has a management cluster with servers such as Active Directory, DNS, SQL, and an existing vCenter Server to manage current operations. In this case, the existing vCenter Server becomes the vCloud Infrastructure vCenter. If the physical resources are available, you want to create a new cluster called a vCloud management cluster. This management cluster houses the vCloud Resource vCenter, SQL, vCNS Manager, vCD cells, and potentially more VMs. We're choosing to add a second SQL server because the vCloud Resource vCenter, vCloud Resource vCenter Update Manager, and vCloud Director applications all need access to a database where transactions don't have to traverse the network a far distance to limit latency and unexpected downtime. As shown in Figure 12.4, the vCloud Infrastructure vCenter owns the management cluster and the vCloud management cluster. The vCloud Resource vCenter owns the vCloud Provider vDC Resource clusters.
Figure 12.4 An existing : management : cluster can be used for vCenter design.
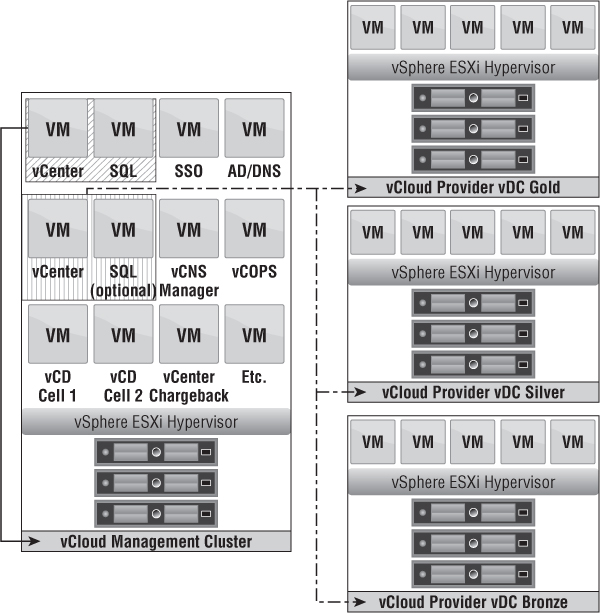
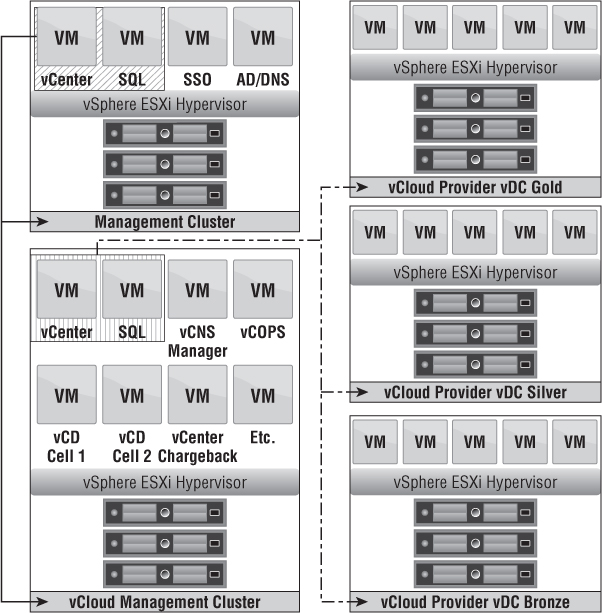
Figure 12.5 shows a singular global management infrastructure. Instead of having a dedicated vCloud management cluster (sometimes as a cost-saving measure), it's integrated into a global management cluster. This is a pooling of all the VMs required for the management operations of the infrastructure as well as the cloud. The second SQL server paired with the vCloud Resource vCenter is optional because the existing SQL server may support the new necessary databases, depending on requirements.
Figure 12.5 vCenter design can rely on a single management infrastructure.
Converged infrastructure is beginning to achieve market traction, and adoption is accelerating. In many converged infrastructure solutions, a vCenter Server is configured as part of the delivery process and can't be integrated into an existing vCenter instance. This can be seen as a constraint with organization vDC (Org vDC) design, but the design is very simple and makes the procurement and integration of converged infrastructure much easier. In this case, every vCenter delivered in a converged infrastructure pod can be defined as a vCloud Resource vCenter, as shown in Figure 12.6. The preferred method is to integrate with an existing vCenter Server to use elastic vDCs whenever possible.
Figure 12.6 Adopting converged infrastructure with an integrated vCenter into vCloud Director
vCloud Management: Physical Design
The physical design is unique in every situation. As an architect, you're responsible for determining the requirements to derive assumptions and constraints. The size of your management infrastructure depends on a single question: “How big is the cloud I have to manage?” This question must be answered in concert with the vCloud maximums.
vCloud Director recommended practice suggests a management infrastructure for vCloud Director infrastructure resources. This management infrastructure is beyond a single cluster of resources. It suggests dedicated servers, networking, and storage. This is a typical design in large vSphere implementations as well. The goal of this design is to make sure an environment isn't managing itself. If there is an issue on the production systems, how can the management tools troubleshoot it if they're experiencing the same issues? This can be related to physical outages and misconfigurations in the logical components. Having a dedicated management infrastructure ensures that a problem with the production infrastructure can be accessed and troubleshot through the management infrastructure. And vice versa: if the management infrastructure experiences an outage, it doesn't affect the production infrastructure. You take the same approach with vCloud Director, but more caveats are involved. The management infrastructure is critical to the survival of vCloud Director.
In a normal vSphere environment, the loss of vCenter doesn't impact running workloads, and HA continues to function. With vCloud Director, the loss of a vCloud Resource vCenter can introduce unanticipated consequences. The communication between vCloud Director and a vCloud Resource vCenter is responsible for instantiating the provisioning of new vApps and new networks, and brokering access to the remote console of VMs. The vCloud Resource vCenter(s) become critical components of the functioning cloud. In the case of the vCloud management infrastructure, you should adhere to recommended practices for vSphere design.
The market is seeing a growing adoption of vCloud Director. Some cases are not for production workloads but instead for specific use cases, such as development and test environments or proof of concepts. Therefore, cost may be a limiting factor. vCloud Director infrastructure management VMs can be aggregated into an existing vSphere management infrastructure farm where Active Directory, DNS, and SQL already exist. The assumption is that this existing cluster has ample capacity to satisfy vCloud Director cells; vCNS managers; additional vCenter Servers; and any ecosystem VMs, such as vCenter Operations Manager (vCOPs) or vCenter Chargeback, as shown in Figure 12.5.
A second option is to create a management cluster, alongside Provider vDC resources. The vCloud infrastructure management VMs use the same networking and storage infrastructure as the Provider vDC clusters, but you have separation at the cluster level. This option works well for most cases, assuming the storage and networking infrastructures are resilient. If problems arise in the storage or networking infrastructure, it will directly impact both the vCloud management cluster and Provider vDCs.
The physical design for the management infrastructure looks like a typical vSphere infrastructure based on capacity and the size of the cloud it manages. A VMware best practice is a minimum of three servers to satisfy HA, DRS, and N+1 capacities. If this design is for a proof of concept (POC), cost plays a larger role. POCs, test and development, and other use cases might dictate that more consolidation is necessary. With these scenarios, you may opt for a two-server cluster until it's time to move into production. As the use case progresses toward production, you can add additional servers for resiliency and scale. The number of servers depends on the number of VMs you plan to host, such as multiple vCenter Servers (perhaps adding vCenter Heartbeat as well for a total of three or four vCenter Servers), vCenter Chargeback that can expand to multiple collectors, vCNS Managers, multiple vCloud Director cells, a SQL server or two (perhaps more if you want to implement clustering services), redundant AD/DNS, a load balancer for the cells, and vCenter Orchestrator. The number and types of servers depend on requirements.
Storage design of the management cluster also depends on the number and types of VMs living in this cluster. This cluster is the center of your entire cloud, so you need a production-ready storage solution. The amount of I/O driven by these VMs varies. The core vCloud Director products (vCloud Director, vCenter, SQL, and vCNS Manager) don't generate a heavy I/O load. As an architect, defining the ecosystem products that generate high I/O load is a constraint. For example, vCOPs Enterprise can require up to 6,000 input/output operations per second (IOPS) to monitor more than 6,000 VMs.
Network design of the management cluster depends on the number of connections the cluster is servicing. The management cluster is responsible for API calls to vCenter and ESXi hosts to issue the creation, deletion, and modification of objects in vSphere. The networking connections for this can be satisfied with both 1 GbE and 10 GbE connections. As more consumers of your cloud access the vCloud Director portal, many console sessions can occur simultaneously. Network bandwidth monitoring will be an administrative effort as it relates to the NICs dedicated to standard VM networking. As consumers of the cloud increase, additional 1 GbE NICs may be needed, or a transition to 10 GbE may be necessary.
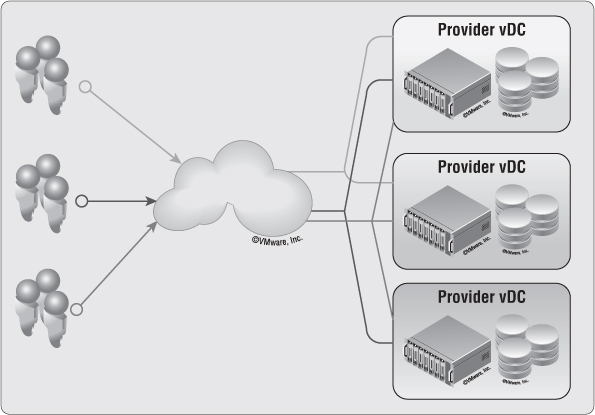
The Physical Side of Provider Virtual Datacenters
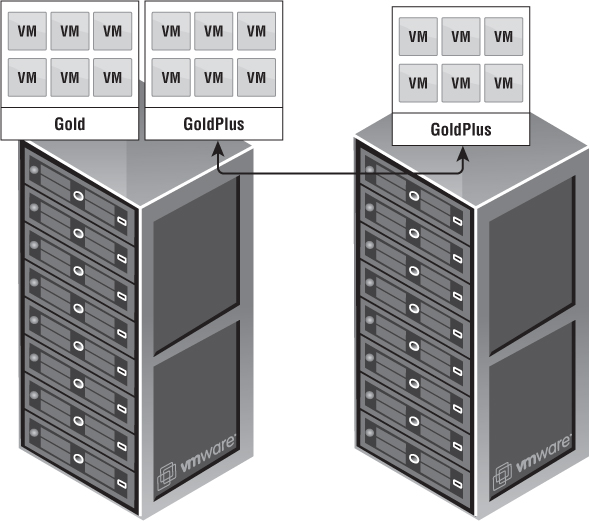
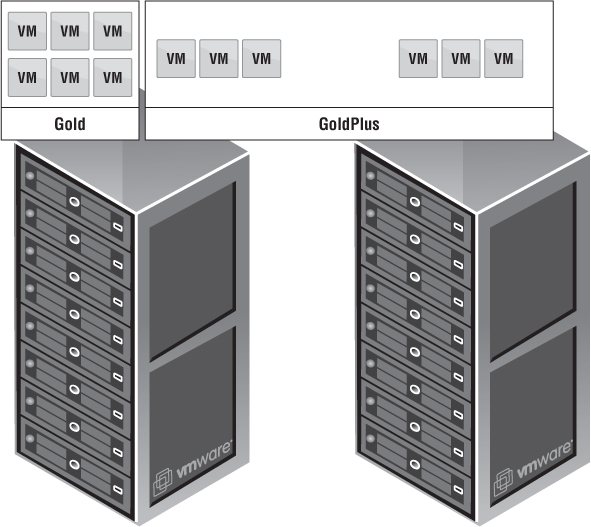
In vCloud Director, physical resources must be provided for organizations to consume, as shown in Figure 12.7. These resources are considered Provider vDCs. Everyone has a different Provider vDC strategy. Provider vDCs in vCloud Director can consist of any type of vSphere infrastructure. The key point to understanding what a Provider vDC can accomplish is to tie it to an SLA. The SLA defined by a Provider vDC depends on many different options. Most people are familiar with Gold, Silver, and Bronze approaches, and we'll use them going forward for our examples.
To simplify, a Provider vDC can be a cluster or clusters of servers with associated datastores mapped to storage profiles. A standard best practice is to associate a cluster of servers and datastores as a tier of service. Stay away from using resource pools as the root of a Provider vDC. It's also important to note that a good vSphere design is crucial to a good vCloud design.
Figure 12.7 Provider vDCs are the resources for deployment of vApps in vCloud Director.
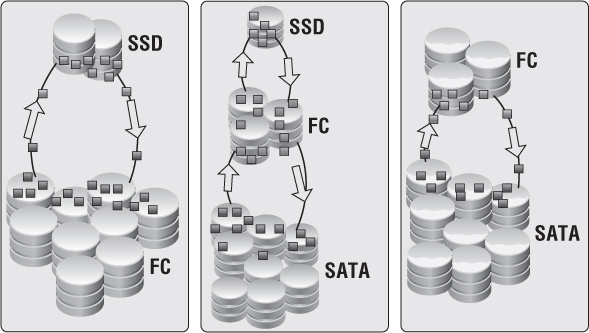
The simplest approach to tie an SLA to a Provider vDC is based on the types of disks shown in Figure 12.8. This should be relatively easy because everyone understands the differences in performance between EFD/SSD, Fibre Channel/SAS, and SATA drives. Assigning an appropriate SLA is simple because you know the Gold service level is aligned with EFD/SSD, Silver with FC/SAS, and Bronze with SATA, based on performance characteristics. The disadvantage of this method is the inability to appropriately estimate the number of each type you'll need and the wasted costs. If you fail to determine your tenants' needs, then you'll over or under purchase for a particular tier. Perhaps you wasted a capital expenditure on Gold EFD/SSD drives, and you don't have single tenant that wants to pay for that sort of premium. The wasted costs are risky.
A second approach also relates to disks, but it builds on multiple tiers by using multiple types of RAID groups as shown in Figure 12.9. This is a tough scenario to standardize because there are lots of RAID offerings, and you could once again waste money on unused disks. Different applications may warrant RAID 5 versus RAID 6 versus RAID 1+0 for performance characteristics. Now you have to decide where to spend your money on types of disks. An example would be setting a Gold tier as SAS/FC Raid 1+0, Silver as SAS/FC in RAID 5, Bronze Plus as SATA in RAID 5, and Bronze as SATA in RAID 6.
Figure 12.8 Storage capability is an easy differentiator for service levels.

Not only do types of media have varying performance characteristics, but they also offer differing levels of redundancy. We opted not to include an EFD/SSD tier to keep everything simple. We could just as easily add EFD/SSDs and more RAID offerings on all tiers of media to make a multitude of offerings. The goal is to keep costs in mind and find that sweet spot for return on investment.
Going with RAID types as a differentiating factor might not be the most efficient because the applications hosted in vCloud Director probably aren't critical enough to warrant this lengthy thought process. Sticking with one standard RAID type and moving forward may be a better plan to make sure you aren't over- or under-allocating resources.
Another piece of information to keep in mind is that VMs inside of vCloud Director can only belong to a single datastore. In vSphere, we could take a high I/O VM and place the operating system VMDK on a RAID-5 datastore, and the VMDK needing more IOPS can be placed on a RAID 1+0 datastore. As of vCloud Director 5.1, this is not possible and all VMDKs belonging to a VM must reside on a single datastore.
Figure 12.9 RAID type can be an acceptable form of differentiating service levels but isn't recommended.

The third approach to tie an SLA to a Provider vDC still uses types of media, but it focuses on storage technology. Many storage vendors have a feature that allows the dynamic movement of blocks to different media depending on accessibility, as shown in Figure 12.10. Some storage vendors that offer this type of technology include EMC, Dell Compellent, HDS, HP 3PAR, IBM, NetApp, and many others. In this example, we'll use EMC's fully automated storage tiering (FAST) technology.
Figure 12.10 Dynamic movement of blocks can dictate levels of performance.
FAST can determine your Provider vDC strategy based on the types of disks because you can offer this technology based on single datastores. FAST allows multiple types of disks to be aggregated into a single LUN/datastore while an algorithm determines where data will be stored. You can put SSD, FC, and SATA into a single pool, and datastores can then be carved up. The algorithm determines when hot blocks need to be moved to a higher tier of disk, and other unused blocks can be moved to a lower tier. If those lower-tier blocks start seeing action, then they can potentially move up a tier or two based on how often the algorithm runs.
FAST lets cloud administrators offer multiple kinds of disk-based SLA offerings. For example:
- Gold = 30% EFD and 70% FC, giving Gold tenants more room to burst into EFD while not paying a premium for EFD drives in the short term.
- Silver = 5% EFD, 70% FC, and 25% SATA, which gives tenants an offering that allows a little burst room but warrants good performance when needed.
- Bronze Plus = 25% FC and 75% SATA, allowing tenants to burst into FC-type performance while still keeping costs minimal.
- Bronze = 100% SATA without FAST technology, for a predictable performance tier.
This strategy gives the cloud provider greater options for the level of service they can offer tenants while also saving money on expensive EFD drives. The only downside to a FAST offering is that you can't guarantee tenants a predictable I/O pattern or particular level of performance. vCloud Director sees datastores equally in a Provider vDC, and if multiple tenants use the same FAST datastore, they will compete for those higher-grade tiers based on their workload.
Of course, we can stretch this same type of thinking to servers, as shown in Figure 12.11. Perhaps you still had a single SAN, but you were refreshing or expanding your compute cluster. You can use old servers to create vSphere clusters that run older dual- or quad-core processors and that are assigned a Silver or Bronze SLA, and give a Gold SLA to newer hex-core servers that have greater clock speeds and RAM densities. Both clusters still rely on the same backend storage array, but the differentiating factor is the processing power given to the VMs. Typical vSphere design comes into play here as well. Don't cross-pollinate datastores between clusters. vSphere hosts have a maximum datastore connection threshold, and cross-pollinating can lead to reaching that maximum.
Figure 12.11 Cluster together hosts with similar CPU speeds, and create offerings based on processing power.

Stay away from tying an SLA to FC/block versus NFS/file. Both solutions are great, and they both achieve what you need. Instead, think about how you would tie SLAs to connections on 1 GbE versus 10 GbE NFS and 4 GbE versus 8 GbE FC. If there is a mixed environment, you could have 1 GbE IP = Bronze, 4 GbE FC = Silver, and 8 GbE FC = Gold or 10 GbE NFS = Gold. The battle of block- versus file-based storage will never end, so stay neutral about how you tie an SLA to a type of network medium.
In addition to speed, take reliability into account. What type of switch or fabric switch is in the middle? Are the fabric switches redundant? If the loss of a switch occurs, what is the impact to the throughput and availability?
Now that we have looked at a few types of Provider vDC approaches, let's start thinking a bit bigger. Many companies are adopting converged infrastructure or pod types of computing. Basing your Provider vDC on disk is good for use in a single pod because it can easily be managed. The great thing about vCloud Director is that it gives the cloud provider the freedom and control to adopt multiple infrastructures that can determine Provider vDC offerings.
Many companies have older VMware farms, or somewhat new VMware farms, but are looking either for a refresh or to expand. You can now use vCloud Director Provider vDCs in a pod approach instead of thinking in terms of granular disk. For instance, suppose you have a collection of Dell R610 servers connected to two Cisco 3650s via iSCSI 1 GbE to a Hitachi array. You also have a few clusters of HP DL380 G7 servers connected to a single Cisco 4507R where storage is supplied from a NetApp FAS6080 via 10 GbE NFS. You've also purchased a new Virtual Computing Environment (VCE) Vblock 300HX of converged infrastructure. For simplicity's sake, let's say each pod has a single cluster of eight hosts and datastores of only FC/SAS storage. From this, you can derive a few differentiating factors. First, the servers keep getting newer, and you can tie appropriate SLAs to them. In addition, the connection medium is capable of higher throughput and is also more redundant. Pod 1 has 1 GbE connections on 2x Cisco 3560s of which only one is used for the uplink to overcome Spanning-Tree Protocol (STP). Pod 2 has much better throughput using a 10 GbE connection but falls short of true redundancy because the 4507-R is a single-chassis solution, even though it has two supervisor engines. Pod 3 uses 8 GbE FC and 10 GbE NFS storage for maximum throughput and is fully redundant by using Virtual Port Channels (vPCs) between Nexus 5548UP Switches and a redundant FC network. In all of these vSphere infrastructures, the backend storage stays the same. Sure, the storage processors are fresher on the newer arrays, but it's still the same 300 GbE FC disks spinning in RAID 5 delivering the same number of IOPS. This is an example of thinking in a pod-based approach because all of this equipment can still be used by a cloud provider; the provider can reuse older hardware as a service tier to continue to realize profits.
As we start thinking further down the line about newer capabilities of vCloud Director and integrations into more products, we can imagine more capable Provider vDC scenarios. Today, we can replicate datastores across the WAN to create a Provider vDC offering with built-in DR, as shown in Figure 12.12. For this scenario, you can create a few datastores that are characterized as replicated and have a higher cost. This is where a new service offering can be created, such as Gold Plus or Silver Plus.
Figure 12.12 Use replication as a value added to types of offerings.
Many companies are also looking at implementing stretched clusters for mission-critical applications that require little to no downtime. As vCloud becomes an increasingly trusted platform, more mission-critical workloads will be placed there. To satisfy the needs of these mission-critical workloads, the Provider vDC may need to be modified with technologies that can introduce these possibilities. Today, technologies like EMC VPLEX along with Cisco Nexus 7000s for Overlay Transport Virtualization (OTV) and Locator/ID Separation Protocol (LISP) can create stretched-cluster scenarios to give that level of availability; see Figure 12.13. In both of these scenarios, you must take into account the architecture of the management infrastructure to accompany a successful DR failover.
Figure 12.13 Stretched clusters can give an offering a lower recovery point objective (RPO) and help avoid disasters.
The Logical Side of Provider Virtual Datacenters
In previous versions of vCloud Director (1.0, 1.5, and 1.5.1), a Provider vDC was mapped to a physical cluster, and the datastores were attached to that cluster. If you wanted to create a Gold offering at the cluster level, all datastores attached to those hosts had to have similar characteristics. vCloud 5.1 brings more feature parity from vSphere: datastore clusters and storage profiles that enable much greater flexibility.
When you're designing Provider vDCs in vCloud 5.1, the server becomes less of an issue and there is a greater focus on storage. With vCloud 1.5.1 and earlier, the datastores defined in a Provider vDC were the ones you needed to use, as shown in Figure 12.14. vCloud Director didn't know you were combining SATA and FC drives in a single Provider vDC offering, so when a VM was provisioned, it could go to either SATA or FC.
When you're buying storage for a cloud infrastructure, you probably won't buy an entire storage array with just one kind of disk. Storage profiles bring a new type of architecture to vCloud Director: they let Provider vDCs be more flexible in their offerings. Traditionally, a Provider vDC could be considered Gold or Silver depending on the types of storage backing it. Storage profiles can create Provider vDCs with a mix of storage types. They allow better utilization of the server environment because clusters aren't dedicated to specific types of disk. In addition, vSphere 5.1 can now expose datastore clusters to vCloud 5.1, which lets you balance workloads across resources and enables flexibility of the pools being offered.
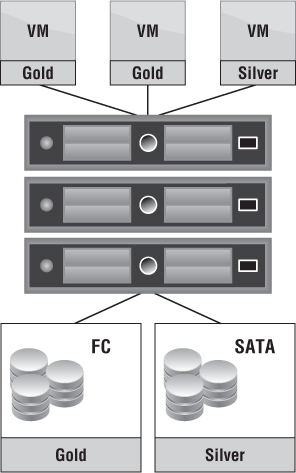
Figure 12.15 shows that provisioning a vApp to a particular Provider vDC dictates the type of storage depending on the storage profile assigned. In this case, the datastores in the FC datastore cluster have been assigned the storage profile Gold, whereas the datastores in the SATA datastore cluster have been assigned the storage profile Silver.
Figure 12.14 vCloud 1.5.1 and earlier couldn't use storage profiles; therefore, : deploying vApps was unintelligent and used any : datastore available to a cluster of hosts.
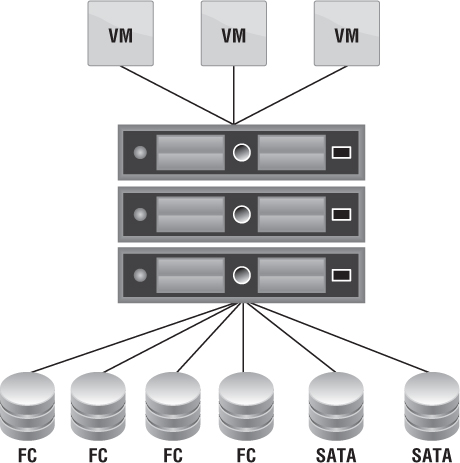
Figure 12.15 Choosing a storage profile type allows better utilization : of the server environment.
Before you configure storage profiles, individual datastores need to be defined with capabilities. There are two ways to create datastore capabilities: use vSphere APIs for Storage Awareness (VASA), or create them manually as user-defined. When you're deciding on a storage array for the architecture, the ability to use VASA can be a time saver. Many storage manufacturers are adopting VASA to make using storage profiles much easier. Figure 12.16 shows the storage capabilities exposed to vSphere after adding an EMC VNX array as a storage provider
Figure 12.16 VASA integration can natively define datastore characteristics.
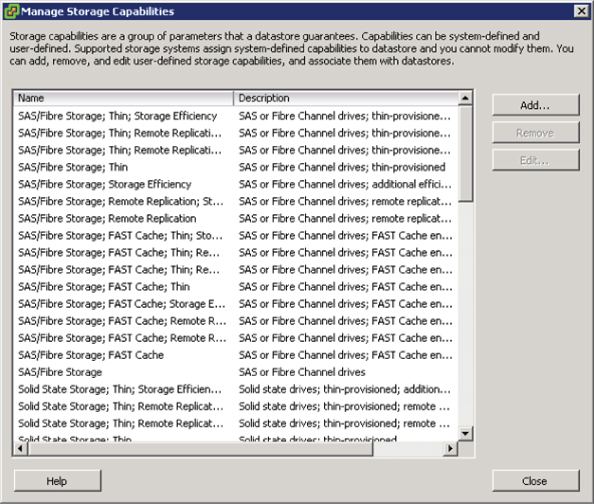
Notice in Figure 12.16 that many of the capabilities are almost duplicated. For instance:
- SAS/Fibre Storage
- SAS/Fibre Storage; Thin
- SAS/Fibre Storage; Thin; Remote Replication
The reasoning behind this methodology is that a datastore can only be defined with a single datastore characteristic string. If datastores need to be more granular and well defined, you can manually create your own specific user-defined profile. If you had a sample datastore that was based on SAS drives and was being thin-provisioned, you could give it a name such as
User-defined storage capabilities can be more granular. Giving your datastores a specific characteristic makes it much easier to define a storage profile.
As your capabilities are defined, you may or may not want to begin using datastore clusters. Datastore clusters let you group datastores with similar characteristics to achieve better storage utilization. Datastore clustering allows vSphere to manage the initial placement of VMs into datastores based on the space available. In addition, vSphere can also be responsible for the real-time migration (via Storage vMotion or Storage DRS) of VM files based on available capacity or I/O latency thresholds. Datastore clusters are supported in vCloud 5.1 with vSphere 5.1 or later. They're recommended in most scenarios, contingent on an array vendor's best practice, because they relieve the administrator of having to monitor storage use.
There is a particular scenario in which you should disable Storage DRS for datastore clusters: when a datastore is backed by an auto-tiering technology (such as EMC FAST). The array is responsible for moving blocks of data, and a Storage vMotion event would place the VM's storage on another datastore. The placement of blocks could be unpredictable, and performance could suffer. These types of datastores should be placed in a datastore cluster for initial VM placement during provisioning, but Storage DRS capabilities should be disabled to allow the storage array to perform its duties.
Storage vMotion in vCloud Director is supported and enables the live migration of VM disk files to another datastore. This is only possible when
- The target datastore is part of the same Org vDC as the original vApp.
- All the virtual disks for a single VM are migrated to the same datastore (the VM can't have virtual disks in separate datastores).
- The vCloud API is invoked to initiate the Storage vMotion for fast-provisioned VMs to preserve the tree (performing a Storage vMotion using the vSphere Client can cause the inflation of the delta disks).
Using datastore clusters isn't required in vCloud Director but is recommended. Always consult your storage-array manufacturer on its recommended practice. The correlation of storage profiles for use in Provider vDCs is directly related to defining storage characteristics; a storage profile can be mapped to multiple datastore clusters.
You're now ready to implement storage profiles in the design. The key is mapping all three of the following storage components together: assign a datastore capability to each individual datastore, create a datastore cluster for datastores that share similar or identical characteristics, and then create a storage profile to define a class of service. This tree is depicted in Figure 12.17.
When you're defining a name or a class of service in the storage profile, it needs to be both relevant and relative to what is being offered. The name needs to be easily discernable by end users who choose to provision to this particular storage class. Some suggested names are as follows:
- Extreme Performance = SSD/EFD
- Standard = SAS/FC
- Standard with Replication = replicated SAS/FC datastores
- Capacity = SATA
Of course, the standard Gold, Silver, and Bronze may be suitable. The key thing to understand is that technology will mature over time. A Gold level of service today could be tomorrow's Bronze level. In addition, how do you differentiate your cloud against someone else's if you're competing in that space? Your Silver offering could be someone else's Gold. The definition of your storage profile should be apparent to the end user to simplify their placement decision, as shown in Figure 12.18.
Figure 12.17 A storage profile depends on : datastore : capabilities. You can use datastore clusters to group similar datastores.
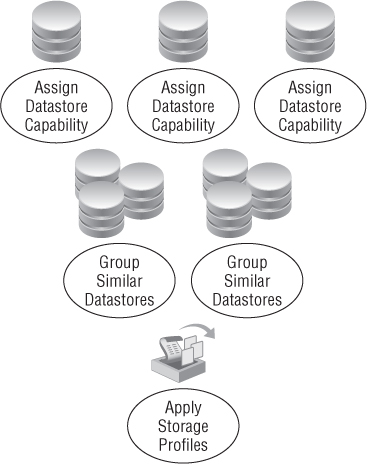
Figure 12.18 Create easily : understood names for storage profiles.
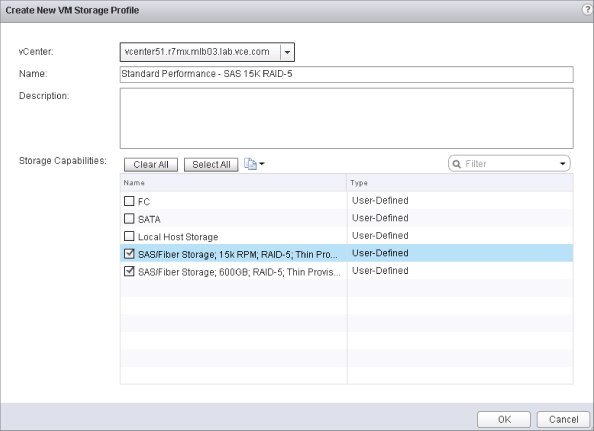
Figure 12.19 is an example of what it looks like to provision a vApp as a tenant in vCloud Director. Each individual VM in a vApp can be associated with a particular storage profile. Making these names easy for the end user to understand improves the experience.
Figure 12.19 The easily : understood names make it easier for an end user to choose where to deploy vApps in vCloud Director
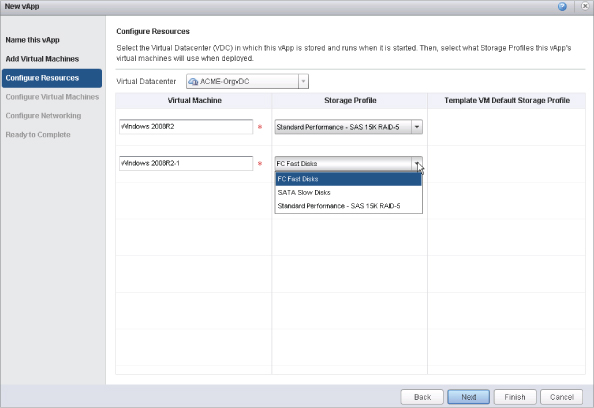
For scalability knowledge, a storage profile is associated to a single vCenter. Creating the same storage profile on multiple vCenter instances will be viewed as independent Provider vDC resources to vCloud Director.
On the server side, vCloud 5.1 has extended the capabilities of block-based datastores along with fast provisioning to support 32-node clusters if vSphere 5.1 Virtual Machine File System 5 (VMFS-5) volumes are on the backend. Traditionally, the maximum number of supported nodes in a cluster when using fast provisioning was eight hosts because of a limitation with VMFS volumes. NFS datastores, on the other hand, could support more than 8 hosts but less than or equal to 32 host clusters. vCloud 5.1, along with vSphere 5.1 VMFS-5, brought feature parity at the host and cluster level to support vSphere's maximum cluster size of 32 with Fault Domain Manager (FDM—vSphere's new and improved HA agent). It's still a best practice to combine into clusters servers with similar characteristics, such as amount of memory, processor families, and number of cores. Different Provider vDCs have differing hardware capabilities, so tying an SLA and chargeback profile to each will be unique.
vCloud 1.5 featured the ability to have elastic Provider vDCs. This lets an existing Provider vDC add computing, memory, and storage resources. As discussed earlier, a cluster can scale to 32 hosts. If the resources in that cluster are being consumed at a rate that is maxing out all consumable resources, then additional clusters can be added to the existing Provider vDC. This capability has the constraint that all clusters in a single Provider vDC must exist in the same vCenter Server, in the same logical datacenter, and must use the same distributed virtual switch (DVS). The easiest implementation of an elastic Provider vDC uses a single DVS to make sure all clusters have similar networking properties. The vSphere Distributed Switch (vDS) is mapped at the logical datacenter level.
Elastic Provider vDCs play a role in design because they can cause vSphere, vCenter, and vDS pieces to potentially reach their maximums. Depending on the number of hosts you're adding to an elastic Provider vDC, you may create conflict with vSphere maximum thresholds.
Network Pool Decisions
The role of a network pool is to enable the creation of Layer 2 segmented networks, including organization routed networks, vApp networks, and isolated networks (discussed later). Every Layer 2 segmented network can reuse the same IP address space, which allows networks to scale. Let's examine what's available and how to architect for each type:
The isolation of the networks relies on the configuration of the upstream switches. This requires that VLANs given to vCloud Director for pool creation must be configured on the upstream switches. The constraint is that the number of VLANs is finite, and this method eliminates usable VLANs in the network. The vDS is a requirement for this type of pool.
There can be a maximum of only 10 VCD-NI network pools per vCloud Director instance. This option is more secure than VLAN-backed network pools because vCloud Director is in control of the networking and not relying on outside configuration.
If you plan to implement VXLAN, many prerequisites must be defined early in the process, such as the following:
- Acquiring a Layer 3 VLAN with a default gateway and addressable IP space
- Enabling Internet Group Management Protocol (IGMP) snooping on switches taking part in multicast traffic
- Assigning an IGMP querier address on the routers taking part in multicast traffic
- Use of IGMP by hosts and adjacent routers to establish multicast group membership
- Enabling Protocol Independent Multicast (PIM) on the router if VTEPs are on different Layer 2 segments
- Aligning the vDS uplinks properly with failover, Link Aggregation Control Protocol (LACP), or EtherChannel (LACP and EtherChannel require port groups to be configured with the Route Based on IP Hash option)
You need to know your NIC teaming policy ahead of time as well. vSphere 5.1 brought the functionality of true LACP and EtherChannel for configuration of vDS uplinks. This functionality was made available because VXLAN can only use LACP or EtherChannel when teaming multiple NICs together for communication. If you want to use LACP or EtherChannel, it must be supported and configured on your upstream switch. The other option, which may be the path of least resistance, is failover. The failover option will choose only one NIC for communication; the other NIC is put in standby. This option still works very well when network I/O control (NIOC) is enabled and all other port groups are set to Route Based on Physical NIC Load. vSphere is smart enough to move traffic on any uplink that has free resources in this scenario.
External Networks
Talking about the vDS is a good segue into the next portion about networking. As you design your vCloud environment, one key is defining the external networks. An external network is a shared-services network that can be given to any organization or tenant in the cloud.
This external network comes in many different forms. The key question to ask is, “What do the tenants in the cloud need access to?” Every situation is different, but here are some of the most common external networks:
- Public Internet access
- Tunneled Internet access
- Dedicated access to an existing network per business function
- Backup network for agent-based solutions
- Initial implementation of vCloud Director networking
One key thing to understand is that anything sitting on an external network is supposed to be viewed as sitting beyond a firewall. Anything connected to a shared external network can communicate with one another, unless of course the VM itself has a firewall with rules configured. Therefore, this configuration is different for every environment.
How does the external-network configuration relate to vSphere networking? The external network is the simplest form of vCloud networking. It's no different than a manually provisioned port group. Yes, it's that simple. Today, every vSphere administrator knows how to configure a port group on a virtual switch, and that directly maps as an external network in vCloud Director.
The external network you're creating as a port group should follow many of the best practices set today:
- Use static binding with elastic port allocation.
- Reject forged transmits, MAC address changes, and promiscuous mode.
- Assign a VLAN ID to limit broadcast traffic.
- Set a proper load-balancing technique.
- Use uplinks properly in conjunction with the load-balancing technique.
In previous versions of vCloud Director and vSphere, the external port group was manually changed to Ephemeral Port Binding. This is because the cloud administrator was never conscious of how many devices would be consumed on the external network, and this allowed the dynamic creation and deletion of ports. The new static binding with elastic port allocation brings the security features of static port binding while also dynamically increasing the number of ports available on the port group. Thus you'll make fewer administrative mistakes during installation and configuration of vCloud Director because the port-binding types can't be modified until all ports are free.
When you're configuring external networks in vCloud Director, there are some prerequisites for the port group that has been provisioned:
- Gateway address
- Network mask
- Primary DNS
- Secondary DNS (optional)
- DNS suffix/FQDN (optional)
- Static IP pool
- Unique name for identification
Many of these attributes are common knowledge, so we'll touch on the two design pieces. The static IP pool is a range of IP addresses that vCloud Director can use to allocate external access to tenants in the cloud. These IP addresses are necessary for external communication in organization routed networks, which we'll discuss later. In addition, any virtual NIC or device placed on this network will consume an IP address from the static pool that is defined. It's important to note that the same external network can be created with the same VLAN multiple times, and the range of IP addresses can be segmented out based on each tenant. This is more complicated, but such a use case may exist. Understanding how to design for vCloud networking is important.
Let's examine some possible scenarios of using external networking in vCloud Director. For this exercise, we'll keep things simple and not dive into organizational networks but will show where the logical mapping takes place for accessing resources outside the cloud.
In Figure 12.20, there are four external networks, and each one has access to different types of networks. You may also notice that a VM is connected to each of these networks. For this exercise, the VM may represent a live VM or a vCloud Networking and Security gateway appliance. For simplicity's sake, we've chosen to use VMs; we'll examine vCloud Networking and Security gateway appliances more in depth in the next section.
The first use case in Figure 12.20 is the public Internet. This use case will resonate with service providers more than enterprise customers. In this scenario, a VM placed on the external network is given an IP address from the static pool of 74.11.123.2–74.11.123.40 along with the corresponding gateway and network mask. Perhaps you want to give a VM that will sit on the public Internet a static IP because the nature of a static IP pool is that if the VM is powered off, the static IP from the pool is released back to the pool. On reboot, the VM may be given a different IP address from the static pool. Because this Class A subnet address has 74.11.123.41–74.11.123.62 still available, you can allocate that to a VM as well, outside of the specified static IP pool. Giving a VM an IP from the static pool could create IP address conflicts. If you want to retain the IP assigned from the static pool, then select the Retain IP/MAC Resources check box (see Figure 12.21).
To create a scenario in which a single organization or tenant is given a certain number of public IPs—for instance, five—you can create multiple external networks with the same VLAN: 90. The static IP pool given to this tenant can be five addresses from the large pool of 74.11.123.2–74.11.123.62. This makes managing network subnet masks much easier, instead of assigning 255.255.255.248 network masks to everyone as well as future upgrades when a tenant needs more IP addresses. To create this scenario, select the Allow Overlapping External Networks check box, as shown in Figure 12.22.
The next scenario in Figure 12.20 is tunneled Internet. Both service providers and enterprise users can relate to this type of external network. This scenario is very similar to the previous scenario where there was direct access to the public internet. In this case, you create another layer of security by using an internal network address class and a traditional corporate firewall before accessing the Internet. This method allows the network security teams to remain in control of what enters and leaves the network by having granular control over an advanced firewalling appliance. This type of scenario could also be used for many enterprise networks where VMs in the cloud (behind organization routed networks) can access other system servers such as Active Directory or SMTP.
Figure 12.20 An external network is a shared-services network. All vApps that bind to this network can communicate with one another.
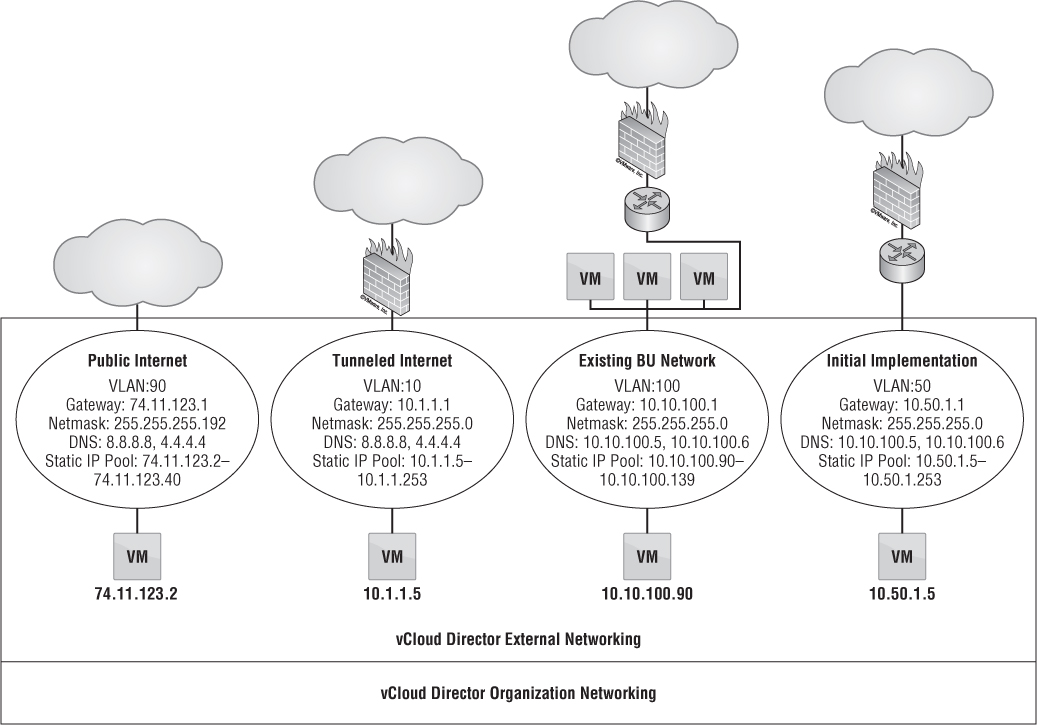
Figure 12.21 Selecting the Retain IP/MAC Resources check box enables the vApp to consistently maintain the same IP characteristics even after you power off the vApp.
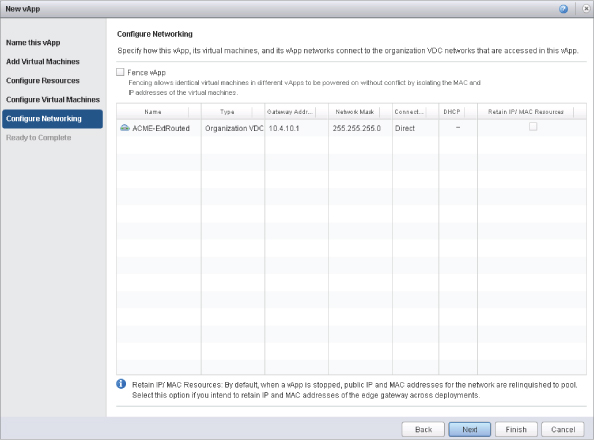
Figure 12.22 Enabling overlapping networks lets you create multiple external networks using the same VLAN.
The existing business unit (BU) network is a use case where VMs in the cloud need access to existing resources outside of the cloud but must be segregated. For instance, if VLAN 100 is given to the engineering group, then this ensures that VMs accessing this external network will only be able to talk to resources on this network. As you can see in Figure 12.20, the static IP pool given to this external network is 10.10.100.90–10.10.100-139, giving it a total of 50 IP addresses. This IP pool must be excluded from the Dynamic Host Configuration Protocol (DHCP) range that may or may not exist for this VLAN from an outside DHCP server so there aren't IP conflicts. This type of scenario relates to any network resource outside vCloud Director, such as a backup network for access to a backup proxy for agent-based backups.
The last scenario in Figure 12.20 is called initial implementation. As companies continue to adopt vCloud Director, there is a major transition to its networking aspect. This scenario is also known as an organization direct connected external network. As we've discussed, the external network is nothing more than a direct mapping of a vSphere port group. The easiest way to transition into vCloud Director is not to create vast amounts of change within your company. Keeping existing processes in place without making users of the cloud learn new concepts right away allows for a smoother adoption of the cloud throughout the company. As users deploy VMs on this network, each VM receives an IP address on an existing VLAN or a new VLAN and integrates seamlessly with existing processes. We'll explore this development more in the next section on organization networks.
Designing Organizations, Catalogs, and Policies
vCloud Director allows multiple tenants to consume shared resources without traversing or seeing another tenant's data. Within the constructs of vCloud Director, a tenant is called an organization.
The cloud administrator is responsible for creating all organizations in vCloud Director. The first organization that should be created for the cloud is for the service provider of the cloud. This usually maps to IT or the name of the actual service-provider company. The cloud provider must have an organization created for it because you need an authority for the public catalog offering, which we'll touch on later.
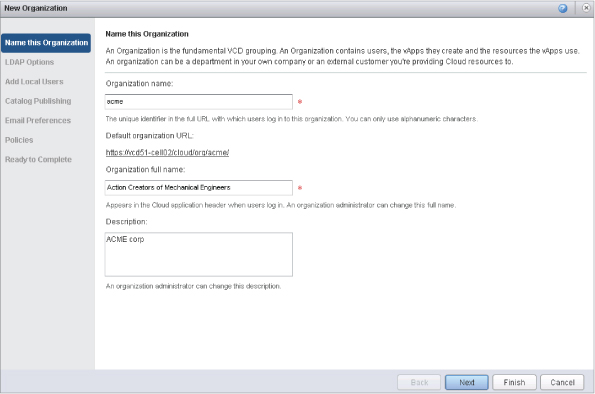
When you're creating an organization in vCloud Director, give it a simple, short name that can be remembered easily, as shown in Figure 12.23. For instance, if Action Creators of Mechanical Engineers comes to you for business, the simple name is “acme.” Many enterprises can be given their department name because that should be easy to recognize. This short name is used for creating the URL that tenants use to access their organization.
Figure 12.23 Create a short name for an organization so it can be easily remembered.
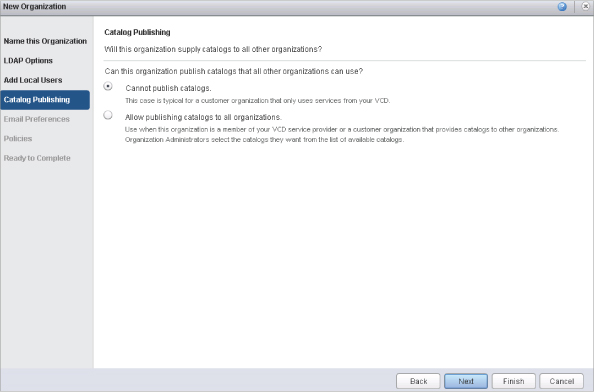
When you create an organization in vCloud Director, you have the option to dictate how catalogs will be handled. This is where the cloud provider will need to have the rights to publish a public catalog. Figure 12.24 shows the options for publishing catalogs that all organizations can use. Choosing the option Allow Publishing Catalogs to All Arganizations allows the organization to turn on the sharing capability among all organizations and tenants of the cloud. The cloud provider can create a public catalog with sample templates such as Windows servers, multiple types of Linux distribution, and any type of ISO media. On the other hand, most organizations should select the Cannot Publish Catalogs option for security reasons. This option is crucial to the security of data between differing organizations, because giving an organization administrator the ability to accidentally create a public catalog could compromise information.
Figure 12.24 Allowing an : organization to publish catalogs to all organizations gives the organization the ability : to create global catalogs accessible to all tenants in the cloud.
Catalogs play a significant role in enabling end users of the cloud. Every organization can create private catalogs and offerings. As suggested earlier, the cloud provider can provide standard OS templates and ISO images. In addition, every organization administrator can create a catalog accessible to only their organization. This catalog can contain OS images with corporate applications or additional ISO types that are different from what is in the public catalog. After deploying an image from the public or organization catalog, an end user can customize that image with whatever they need. Whether it's a hardened OS, installation of a database, or installation of customized applications, the end user (if given proper permissions) can move it into another catalog. Organization catalogs can be created to give Read, Read/Write, or Full Write access to every user in an organization, certain users (local or LDAP), or certain groups (local or LDAP).
Let's look at a use case for this type of operation. A group of developers is experimenting with a new upgrade for their application. The original version of this application lives in a vApp in the organization-wide catalog. The organization administrator creates a catalog called ProjectX-Catalog and gives the developers Read/Write access to it. The first developer provisions the original version from the organization-wide catalog into their cloud and performs the first stage of the upgrade process. Once the upgrade is completed on the original version, the developer uploads this upgraded version to ProjectX-Catalog. The next piece of the upgrade is to see which developer has created the best plug-in. Each developer provisions the upgraded vApp from ProjectX-Catalog and implements their plug-in. After implementation, they upload their vApp into ProjectX-Catalog, and everyone can provision any vApp to see what the others have done. After ProjectX is completed, the organization administrator copies the upgraded vApp to the organization-wide catalog. This process allows end users to keep track of their own code and bug changes without having to share VMs. It also gives IT a simple way to allow end users to enable provisioning of their own resources.
During the creation of an organization, another key concept to keep in mind is the policy of leases. Leases play a crucial role in the amount of resources that can continue to be consumed in the cloud. vApp leases and vApp template leases have similar concepts. The difference is that a vApp lease pertains to vApps that have been provisioned from catalogs, whereas vApp templates are the vApps that are in the catalog. The values represented for each type of lease will differ among organizations.
Before designing leases, you have to understand what each type of lease means. The length of a lease can range from a minimum of 1 hour to indefinite:
- The vApp maximum runtime lease dictates how long a vApp will run before it's automatically stopped. By default, this setting is set at seven days. This stopgap is put in place to make sure vApps aren't consuming CPU and RAM during extended periods. The timer for this lease begins as soon as the vApp is powered on. After seven days, when the lease expires, the vApp will be stopped even if a user is controlling the vApp actively and has a remote console session open to it. The only way to mitigate this lease is either to come to an agreement with the cloud provider to extend the lease or for the end user to reset the vApp lease by powering the vApp off and then back on or by resetting the lease in the vApp properties.
- The vApp maximum storage lease timer begins immediately after the vApp maximum runtime lease expires. This lease ensures that space isn't being wasted on storage. The default for this setting is 30 days. If the vApp sits dormant for 30 days without being powered on, it's handled by the Storage Cleanup option. Storage Cleanup has two possible values: Move to Expired Items or Permanently Delete. By default, this option is set to Move to Expired Items.
Moving a vApp to Expired Items makes the vApp disappear from the end user's My Cloud homepage view but keeps it in the organization administrator's Expired Items view. The organization admin can reset the lease so the end user can access the vApp again or can delete it permanently. When a vApp goes to Expired Items, it's never automatically deleted. Therefore, the organization admin must be conscious of this setting to avoid overconsuming storage resources. On the other hand, if this option is set to Permanently Delete, then the vApp is unrecoverable unless a backup has been saved elsewhere.
- The vApp template maximum storage lease follows the same rules as the vApp maximum storage lease but only applies to vApps in catalogs. The default setting is to have the vApp template expire in 90 days and be moved to Expired Items.
The storage leases designed for an organization depend on what the cloud provider has defined as their standard or what the provider and tenant have agreed on. The amount of consumable resources must also take into account dormant VMs when you're designing storage leases.
As pointed out previously, organization administrators need to keep up with expired items. The cloud provider organization, on the other hand, should have different settings. The vApp template storage lease should be set to Never Expire. The reason for this is that if you as the cloud provider create a public catalog with default vApp templates and have only a single Windows 2008 R2 image, then after 90 days no organization can provision that vApp template. The Never Expire setting makes sure templates aren't moved to a different location and doesn't interfere with daily operations.
Correlating Organizational Networks to Design
When an organization deploys a vApp, it needs some type of networking to communicate. The type of networking the vApp requires depends on the use case. Three types of Org vDC networks are available to facilitate many needs.
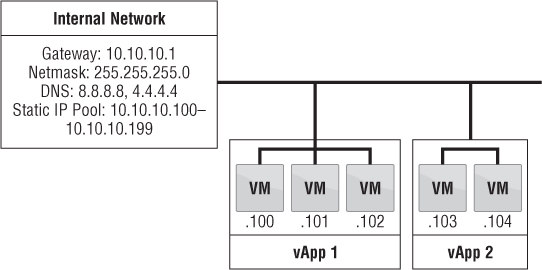
One of the simpler types of networks, called an organization internal network, is completely isolated. The only communication that takes place on this network is between the vApps on the network. There is no connection from this network to the outside world, as shown in Figure 12.25. Such a network can be used for applications when you need to make sure nothing can be compromised. For example, an internal network can be created for internal projects to ensure that they don't interfere with anything and potentially disrupt production workloads.
Figure 12.25 Organization : internal networks are isolated from communication to any external networks. Only vApps connected to this network can : communicate with each other.
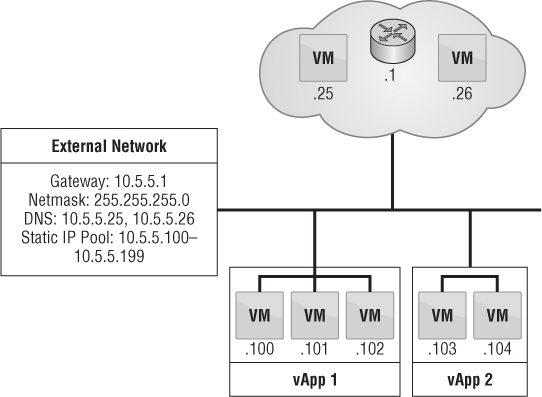
Another type of networking, called an organization direct-connect external network, directly maps to external networks and correlates to a vSphere port group. When a vApp is placed on this type of network, it grabs an IP address and the personality of a normal functioning port group, as shown in Figure 12.26. There is no masking of IP addresses or firewalling.
A vApp is placed on this type of network when it needs to directly communicate to the outside world, such as a web server that needs to be accessible from the Internet. This type of networking is suitable for many initial adoptions of vCloud Director because it doesn't interrupt current processes. For instance, existing processes for provisioning VMs may include being added to an Active Directory domain, added to a configuration management database (CMDB), or probed on the network for adding to a patch and maintenance cycle. Many of these scenarios come into play when IT needs to maintain control of every VM.
If IT can't probe the network to discover new VMs and add them into a scheduled patch routine, then how can the VMs be managed? In this scenario, the VM is placed on a vSphere port group that is no different than many current processes. The OS team is responsible for patches and maintenance, and the network team is responsible for network security at the firewall and the router. The downside is that you aren't getting all the benefits that vCloud Director offers in terms of multitenancy and isolated Layer 2 networks. The IT staff can eventually learn to pick up new tricks to allow management to happen in the next type of networking we'll explore.
Figure 12.26 Connecting a vApp to an organization direct-connect external network allows the vApp to maintain the : characterization of a vSphere port group while still being managed by vCloud Director.
The final type of network is called an organization routed external network. This type of networking allows for multiple Layer 2 networks to be isolated in multitenant scenarios. vCloud Director 5.1 brought some new enhancements to this type of networking that changes the architecture just a bit.
The vCNS Manager server is responsible for deploying an Edge (formerly vShield Edge) gateway appliance. This device is deployed into an Org vDC that is provisioned for an organization when needed. The Edge gateway is responsible for everything going in and out of an organization routed external network.
The Edge gateway can be considered a mini-firewall. It's the hub of multiple networks to facilitate many IP connections from both inside and outside. It can facilitate multiple external network connections as well as multiple organization routed external networks, up to a maximum of 10 different connections total.
Figure 12.27 shows where the Edge gateway connects to two external networks. The Edge gateway consumes one IP address from the static IP pool of the external networks during creation. The diagram also shows that the Edge has two different organization routed external networks attached to it as well. During the creation of the organization routed external networks, the Edge appliance assumes the role of the gateway for this network. During the configuration of the Edge gateway, one of the external networks must be selected as the default gateway for all traffic of the organization routed external networks.
The Edge gateway plays a few more significant roles as well, such as 5-tuple firewall ruling, static routing, NATing, DHCP, VPN, load balancing, and network throttling (features depend on the level of vCNS licensing purchased). If one of the organization routed external networks must communicate with an external network, the Edge gateway must be configured with a source NAT rule to translate the internal IP addresses and a firewall rule that allows traffic to exit; and if the default gateway isn't the destination, then a static routing rule must be in place.
In Figure 12.27, virtual machines on organization routed external network 1 and virtual machines on organization routed external network 2 won't be able to communicate with one another unless a firewall rule is put into place.
Figure 12.27 Organization routed external : networks use an Edge gateway device to allow Layer 2 isolated networks to access an external network through NAT and firewall rules.
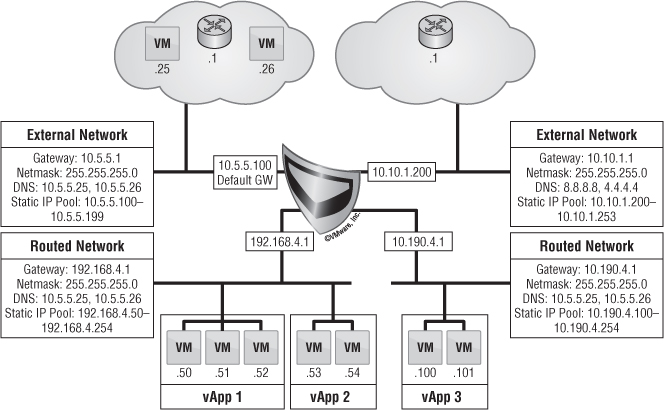
This type of networking is where we really get into what vCloud Director was intended for when we talk about multitenancy. A single organization can have multiple networks. The number of networks given to an organization by a vCloud administrator will vary depending on the use cases. The networks can be categorized as production or test, based on different applications, or everything can go on one organization routed external network.
When you're designing organization routed external networks, you must be careful not to confuse the end user. Keep the networking simple and familiar. Naming a network Org-Routed-50 means nothing to an end user. But if you name the network something like ACME Production versus ACME Test, then it's clearly defined, even though the end user is unaware that these two networks could be internal, routed, or external. For initial implementations, you may only have only a single network available for vApp provisioning, because bringing too many networks into a single offering can be confusing to end users.
Figure 12.28 depicts two organizations, ACME and EMCA. Each organization uses the same external network to access the Internet and uses the cloud provider's DNS servers. Each organization has a Edge gateway appliance that creates a separate Layer 2 organization routed external network. The organization routed external network is clearly identified to the end user during provisioning of vApps. Both networks use the same IP subnet, 192.168.4.0/24, yet neither has a clue about the other's existence. The Edge gateway is responsible for source NAT to the external network and masking internal IPs. Therefore, the two organizations are logically separated.
End Users and vApp Networking
What do you do if end users want to make sure the vApp they're provisioning is segregated out onto a network they can control? This means they aren't using up network resources on what has been provisioned by the vCloud administrator. Here is where vApp networking takes over.
vApp networks are created by the consumers of the cloud and are used to aggregate VMs together in a vApp. The same types of organization networks apply in vApp networks. Designing for vApp networks doesn't take any networking knowledge but instead focuses on resources. Some types of vApp networks consume CPU and memory resources because they require Edge devices. As you build the physical design for Provider vDCs, you need to understand how knowledgeable your tenants are about vCloud networking. If a tenant understands that they can automatically create segregated networks on their own, then more resources will be consumed and must be accounted for in the Provider vDC.
Figure 12.28 Two organizations can share the same external network but are logically separated by Edge gateway appliances. This allows multitenancy in the cloud.
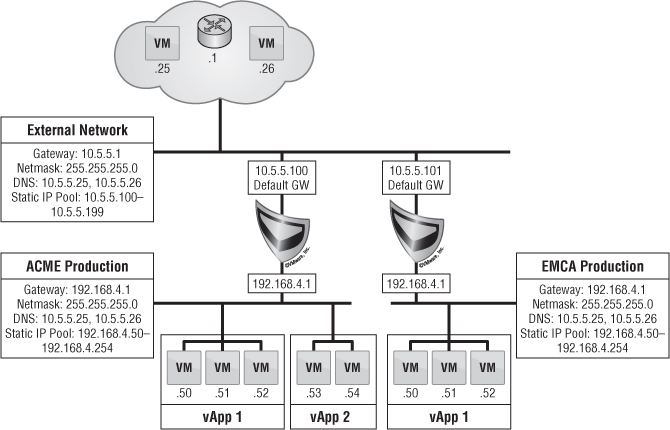
The first type of vApp network is called a direct vApp network. In this scenario, the end user does nothing. The tenant doesn't configure anything networking related. During the provisioning of a vApp, the end user chooses the type of organization network it will live on. After the vApp is provisioned, the user can turn on the vApp, and it will consume IP addresses from the organization network as shown in Figure 12.29. This is typically what is used in most deployments because the tenants don't know enough about what is available to them. In most cases, this is also an easy way to begin the adoption of vCloud Director. To recap, this is simply provisioning a vApp from a catalog directly onto an organization network that can be an organization internal network, organization external direct network, or organization routed external network.
The second type of vApp network is called a fenced vApp network. During vApp provisioning, this scenario requires the end user to check a box that asks whether to fence the vApp. By default, the vApp isn't fenced. If fencing is enabled, an Edge device is deployed and creates a boundary for the vApp. Fencing makes sense when you need to test an application but can't change the IP or MAC addresses associated with the VMs.
This type of networking allows an end user to make identical copies of a vApp without changing a single characteristic. Of course, the use cases could be for developers who write code tied to IP or MAC addresses. In regard to organization internal networks and organization external direct networks, a NAT is necessary for communication and is automatically assigned on the Edge device. If this networking is being deployed on an organization routed external network, then a double NAT must occur because two Edge appliances need to be configured with NAT rules, as shown in Figure 12.30.
Figure 12.29 A direct vApp network consumes ports and IP addresses on the organization : network it's : connected to.
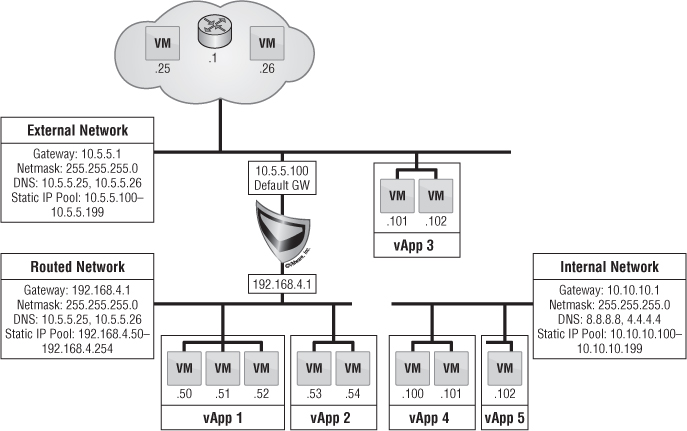
Figure 12.30 A fenced vApp : creates an identical copy of an existing vApp and inherits the same IP and MAC addresses but is front-ended by an Edge appliance to communicate on : a network without : experiencing overlapping IP addresses.
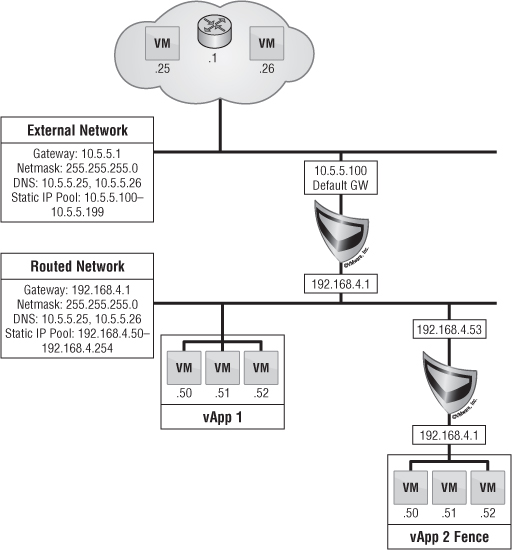
The third type is called a routed vApp network. This requires the end user to create a brand-new network for communication. The end user is responsible for creating a gateway, a subnet mask, and a static IP pool just as if it were an organization routed external network.
The topology in Figure 12.31 looks very much like deploying a fenced vApp network, except now the end user has the responsibility of maintaining the Edge device that is deployed. The end user can set NAT and firewall rules depending on the vApp requirements.
This scenario is useful in situations where the end user wants to be responsible for networking and making sure only certain VM ports are accessible from the organization network. The routed vApp network creates an extra layer of security that gives the end user total control. This scenario is like an onion. At the cloud provider layer, you create multiple organization networks so every organization can have a place to run their VMs without interfering with other tenants. As you dig into the organization, the end user can spawn Edge devices to run their VMs without interfering with anyone else in their organization.
Figure 12.31 A routed vApp : network uses an Edge device to : create an additional layer of security by allowing an end user to maintain firewall rules for their specific vApp when connecting to a particular organization network.
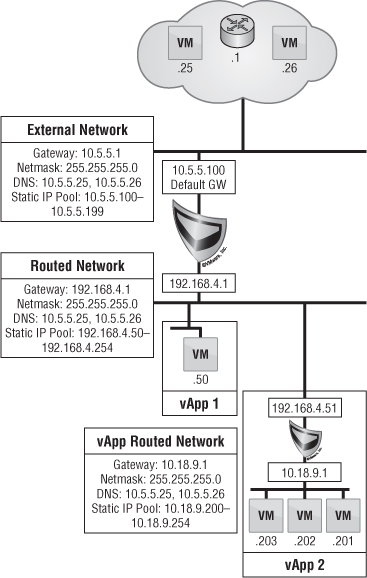
In the last type of network, called an isolated vApp network, the end user creates a vApp network that has the same properties as an organization internal network. Anything connected to this network can't talk outside of it, and the VMs on this network can only communicate with one another. These types of networks can be useful to organizations and are most commonly seen in three-tier applications. Organizations that need to analyze how an application will react to a virus can also benefit from this type of network.
Figure 12.32 depicts a scenario with web, application, and database servers in a three-tier vApp. The web server needs to be publicly accessible. The web server can be given multiple virtual interfaces to connect to an organization network while the other interfaces communicate on an isolated network. The web server VM will acquire IP addresses from both networks.
Figure 12.32 Isolated vApp networks allow vApps to communicate only with each other without connecting to an organization network. A VM can be given multiple NIC interfaces that can be connected to any type of organization network.
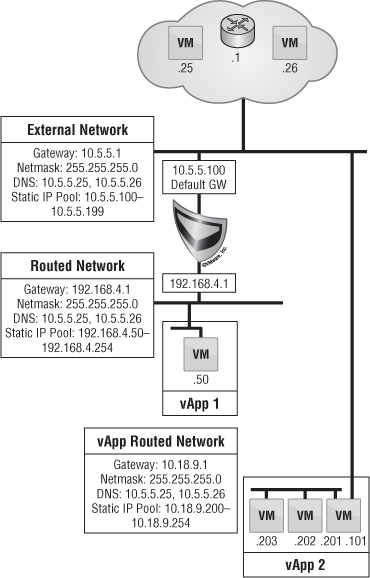
Designing Organization Virtual Datacenters
The last piece of the puzzle is defining the Org vDC. It brings all the earlier parts of this chapter into context:
- A single organization (tenant) can have multiple Org vDCs.
- An Org vDC allocates resources from a single Provider vDC in different allocation models.
- Multiple Org vDCs can consume resources from a single Provider vDC.
- Network pools provide network resources for Org vDCs to consume.
Designing Org vDCs depends on the resources required by the tenant. If you have multiple types of Provider vDCs, and the tenant needs access to each type of resource, then you must create an Org vDC for every type of Provider vDC. In most cases, the Provider vDCs can use multiple types of storage defined by storage profiles. Therefore, when designing Org vDCs, you need to know how many tenants are subscribed to a single Provider vDC.
For instance, if you have a single large Provider vDC and 20 tenants, then all Org vDCs must consume resources from the same Provider vDC. Here, you can easily predict when resources would be consumed and when they reach a limit. If you had 3 Provider vDCs, you wouldn't want all 20 tenants consuming a single Provider vDC. Therefore, you need to determine the amount and type of resources a tenant will need in an Org vDC and map them to a Provider vDC with appropriate resources.
The cloud administrator is responsible for playing the role of “initial placement DRS” for Org vDCs. Remember, the Org vDC that is being created maps directly to a Provider vDC for resources, so understanding what hardware profile the tenant needs for their apps will dictate the mapping. This is where elastic Provider vDCs play a crucial role. If it's possible to combine all three Provider vDCs without reaching vSphere maximums, doing so will require less administrative management. Yet multiple Provider vDCs may be needed to satisfy different performance and availability characteristics.
In some cases you may have to maintain physical separation of the vSphere resources because of compliance or other regulatory restrictions. In this scenario you can have a Provider vDC be consumed by a single Org vDC, which ensures that only a single organization can use those resources. Of course, this doesn't give you the benefits of being a cloud provider and having multiple tenants consume the same resources while maintaining isolation.
Every Org vDC must be tied to a specific allocation model. The allocation model is a mechanism for distributing resources from a Provider vDC to an Org vDC. Such allocation models are necessary for chargeback and showback functionalities to relate costs. You can assign three different allocation models to an Org vDC. They differ in how CPU and memory are allocated in vCloud:
Figure 12.33 A reservation pool model guarantees a percentage of resources to the Org vDC from the backing Provider vDC.
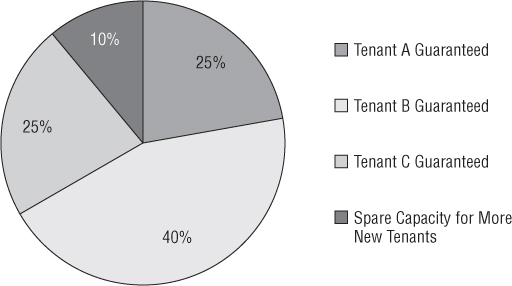
Figure 12.34 An allocation : pool model will guarantee a : percentage of resources to the Org vDC from the backing Provider vDC but also allow : consumption of unallocated resources.
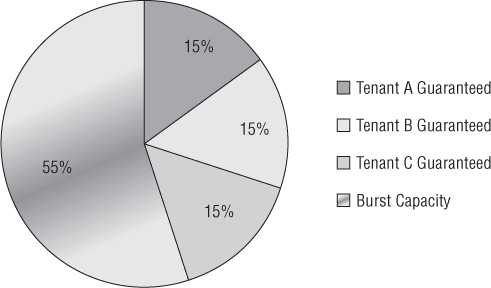
Figure 12.35 A pay-as-you-go pool model sets guarantees on the VMs that are provisioned to a Provider vDC in an Org vDC.
Designing for allocation models varies depending on each type of organization and how users will be consuming resources.
The reservation pool makes sense when an organization knows how much it wants to be charged on a monthly basis. This is equivalent to something like budget billing. Every month you're guaranteed a certain set of resources, and you consistently pay the same amount. There will be no surprises. The flip side is that there is no capacity to burst beyond the allocated resources. If you're given 30 GHz and 64 GB of RAM with a reservation pool, then that is all the resources available to be consumed. If you need more capacity, then it must be changed globally, and the changes affect the reservation and limits of the resource pool defined for the Org vDC.
This type of allocation model is useful in enterprises to make sure certain departments don't spin up unnecessary vApps and wildly consume resources. It's an easy way to define how many resources are dedicated to engineering versus finance versus HR versus IT. It's a failsafe to make sure the consumption of resources doesn't impact another tenant. If you're a service provider, you can verify that two organizations, such as ACME and EMCA, won't fight for resources.
The reservation pool model isn't compatible with elastic Provider vDCs and therefore is constrained to a single cluster of hosts or resource pool. This is a big constraint on choosing reservation pools as your allocation model.
The allocation pool is useful when some resources need to be reserved. It's a way to set aside guaranteed resources for provisioning vApps without paying for unused resources. The ability to burst beyond shared resources makes it more flexible than the reservation model. The down side is that the resources that aren't being reserved are consumed on a first-come, first-served basis. Many times, an organization thinks it needs 30 GHz and 64 GB of RAM but really only uses 50%. Making sure there is no overallocation of resources works well in many enterprise environments. A bigger portion of resources can be given to demanding organizations such as engineering and development, and a smaller portion can go to HR and finance. The remaining resources in the Provider vDC can be acquired by any organization if needed. This allocation model will still require the cloud administrator to monitor resource usage among the organizations and make distribution changes as necessary. The allocation pool model is compatible with elastic Provider vDCs.
The final allocation model is pay-as-you-go. There is no reservation of resources in a resource pool in vSphere; instead, the limits and reservations are enforced at the VM level. Reservations and limits are set on the VM during power-on operations. If a VM is powered off, then reservations and limits aren't enforced on the VM.
In this scenario, if there is an unforeseen boot storm, some vApps may not power on because the reservation for the VM can't be met by the Provider vDC. This model creates some unpredictability and uncertainty in a large cloud model when many vApps may be powered off. On the other hand, many enterprises may use this as an initial implementation scenario because it requires little overhead work of administering limits and reservations on a resource pool level and allows a quick way to begin working with vCloud Director. The pay-as-you-go model is compatible with elastic Provider vDCs.
You may have noticed that these allocation models don't include storage. The allocation models focus on CPU and RAM, but allocating storage to an Org vDC is uniform among the three. As described earlier in “Logical Side of Provider Virtual Datacenters,” storage profiles are necessary components. During the configuration of an allocation model, the cloud administrator needs to choose the storage profiles available to an Org vDC as well the amount of storage that can be consumed from that profile, as shown in Figure 12.36. The default profile must also be selected. For design, it would be safe to say that you should choose the most economical storage profile. Thin provisioning can be enabled to over-allocate storage as well but isn't enabled by default.
You can't change the type of allocation model once it has been defined for an Org vDC. The only thing you can change is the amount of resources to be set as reservations and limits. If you want a vApp on another allocation model, it will need to be migrated to a new Org vDC.
Fast provisioning is a feature that deploys space-efficient linked clones from a base disk image to quickly provision vApps into an Org vDC. If this option is disabled, then thick clones are created during deployment into an Org vDC. Using fast provisioning with vSphere 5.1, VMFS-5, or NFS with vCloud 5.1 allows for 32-host clusters.
Figure 12.36 Storage profiles dictate the class : of service or I/O characteristics that can be given to a particular Org vDC. The Org vDC must be allocated a certain amount of storage as well, for provisioning vApps.
Fast-provisioned VMs use chain lengths and shadow VMs. If the original VM lives in the catalog and a new VM is provisioned, then it can have a chain length of 29 linked clones. The linked clone chain is a clone of the cloned VM. If more than 29 clones are created in the same tree, then the next clone to be provisioned will be a full clone, and a new tree will begin. Before the creation of the clone occurs, vCloud Director determines which datastore has the most available free space and the same storage profile. The datastore with the most available free space will be the target for the next deployed VM. A shadow VM is deployed when the vApp in question must be deployed to another datastore in a different Provider vDC or vCenter instance.
You need to gather storage-capacity requirements for thick- versus fast-provisioned vApps. This brings in a key datastore design consideration. vSphere 5.1 can use 64 TB VMFS-5 datastores supported under vCloud Director. Storage design for vCloud Director should follow the same best practices with regard to vSphere design. Most architects will agree that many smaller datastores are better than a handful of large datastores in a vSphere design, but you must find a good balance between restore time, efficiency of Storage DRS, and IOPS. In terms of vCloud Director, you must be conscious of the maximums. vCloud Director can support a maximum of 1,000 datastores in vCloud 5.1. If you have a very large cloud offering, it may be in your best interest to configure larger datastores.
The next step is defining the network pool to be used in an Org vDC. As discussed earlier, you can choose any type of network pool that has been created. The type of network pool chosen matters only in the context of the actions used on the backend. The end user is unaware of network pools. The cloud administrator is responsible for defining how many networks an Org vDC can create, as shown in Figure 12.37. The number of networks allocated to an Org vDC makes sense only in terms of port-group and VLAN-backed networks. If only 20 VLANs are available in a VLAN-backed network pool, then you have to divvy them up among all organizations. If you overcommit networks when there are only 20 VLANs, then the creation of new networks will fail. VCD-NI and VXLAN, on the other hand, can create thousands of networks. Figure 12.37 shows a VXLAN example; by default, 1,000 networks can be consumed by a single Org vDC without running into a maximum. Of course, this number may be changed for VCD-NI because it has a maximum of 1,000, so you may want to distribute networks differently.
Figure 12.37 Network pools must : be allocated to an Org vDC for the provisioning of networks in vCloud Director such as organization routed external networks, organization internal networks, vApp routed networks, and vApp isolated networks.
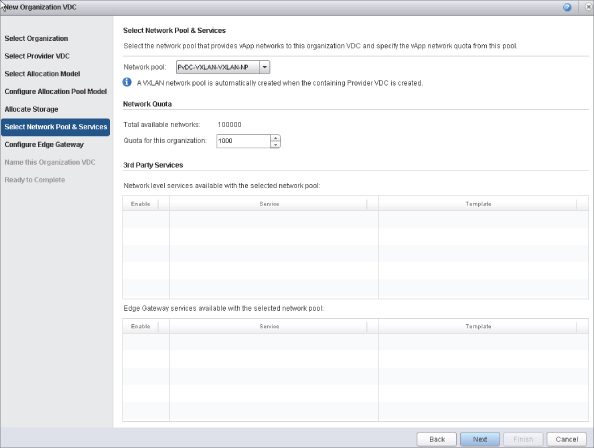
The configuration of an Org vDC relies heavily on networking. During configuration, as shown in Figure 12.38, you have the option to create a new Edge gateway as well as to create an organization routed external network. The Edge gateway appliance has two modes: Compact and Full. The compact version will consume less CPU and memory resources. The full version is needed if an Org vDC grows so large that network latency is experienced due to all the requests. The compact version can be converted to full with minimal downtime if necessary. The Edge gateway can be put in high-availability mode and a secondary Edge gateway appliance provisioned in standby mode. This is useful to overcome a vSphere HA event. If high availability doesn't protect the Edge gateway, then vApps in that Org vDC can't communicate externally until the Edge gateway has been rebooted onto another host in the cluster.
What if you have an Org vDC configured with an allocation pool, but you want a new Org vDC to be configured with pay-as-you-go and to be able to use an existing organization network? Another new feature of vCloud 5.1 is the ability to share organization networks between Org vDCs. During the creation of an organization routed external network, as shown in Figure 12.39, there is a check box for sharing. By default, this option isn't checked, but it's checked in this example.
Figure 12.38 If you're using organization routed external networks, an Edge gateway device must be configured to allow access to the : external networks.
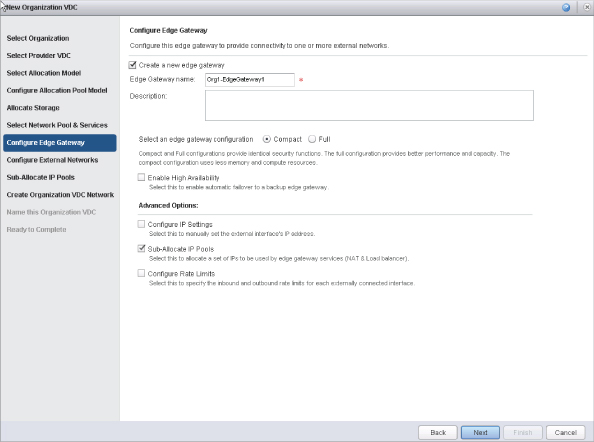
Figure 12.39 vCloud 5.1 allows the sharing of : organization : networks between multiple Org vDCs when backed by a single Provider vDC in an organization.
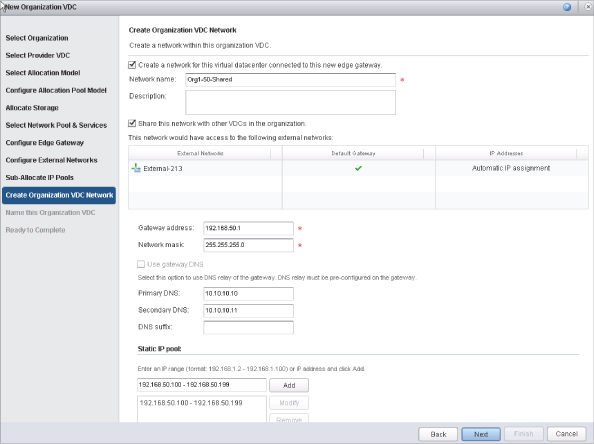
Multiple Sites
Now that you have an idea about how to architect and build a vCloud environment, let's think about scale. What do you do about bringing multiple datacenters into the mix? vCloud Director was originally intended to be located in a single physical datacenter. As you've seen, a lot of components make up vCloud Director, from the management stack to the consumable resources. Creating boundaries based on physical location makes implementation easier because resources don't have to travel distances and experience latency. Let's consider an example of bringing multiple cloud environments together to be more seamless.
Suppose you have three locations—Las Vegas, Dallas, and Omaha—tied together through a Multiprotocol Label Switching (MPLS) network. There is a 10 MBps connection between all three sites. You want to create a centralized cloud where a user can request a VM. Because you have only a 10 MBps connection, you don't want the user to access their VM over the WAN; you want the VM local to their site.
This scenario can have a vCloud Director instance in each site. Using a load balancer, you can create a single DNS record that accepts traffic at the load balancer; depending on the originating requester's IP address, they will be directed to the vCloud Director instance nearest to them. Another option is to create a custom-built portal where the user can choose the datacenter where they would like the vApp deployed. The scenario also plays well with the vCloud management infrastructure because each site can be localized for everything while the custom portal takes care of API calls.
Now suppose each office has a 1 Gbps connection with less than 10 ms of latency between them. Can you create one big cloud? It depends. 1 Gbps is plenty of bandwidth to satisfy many operations, such as a console requests when a user in Dallas provisions their VM in Las Vegas. The amount of bandwidth will also play a major role in the process of copying vApps and shadow VMs between cells and datastores in different geographies.
The vCloud management infrastructure is a bit different in this scenario because there are a few options. Depending on bandwidth and latency, all vCloud cells and vCenter Servers can live in a single management domain. For instance, the vCenter Servers hosted in Dallas can control the vSphere hosts residing in Las Vegas and Omaha. Perhaps the distribution of management is deemed more suitable because it can overcome a link failure between sites. vCenter Servers can be localized to their vSphere hosts this way.
vCloud Director cells can be spread out among sites and front-ended by a load balancer to satisfy incoming connections. Less than 20 ms of round-trip time (RTT) latency is required for the communication of vCD cells to vCenter Servers and databases.
Remember, a single database is used by all vCloud Director cells, so traffic must traverse the WAN if cells live in disparate datacenters. This scenario also poses a problem in the way communication is handled by a requestor. There is no guarantee that a vCloud cell won't cross WAN links. If a user in Las Vegas requests console access to a VM in Las Vegas, it's not possible to control which vCloud cell acts as the proxy for the vCenter in Las Vegas. Therefore, a user may end up traveling between sites to access a remote console. This solution is best implemented in a scenario where bandwidth and latency aren't concerns, such as a MAN or campus.
Backup and Disaster Recovery
The backup and disaster-recovery process of vCloud Director 5.1 is tricky. The infrastructure management VMs work seamlessly with existing backup and disaster-recovery processes because these VMs live at a vSphere level and can follow traditional vSphere policies. The vApps that live in vCloud Director, on the other hand, have certain characteristics that make them unique and troublesome.
Backing up VMs in vCloud Director is the easy part; the hard part is restoration. You may have 50 instances of a Windows 2008 R2 server deployed, with the only differentiator being the unique set of trailing characters. Of course, you can back up every single one of these images, but if you need to restore something, how do you know which VM to use? It's a manual process to grab a VM's universally unique identifier (UUID) to make sure you're restoring the correct VM. When it comes time to restore a backup, backup software doesn't have the notion of Org vDCs and doesn't know where to place the VM. Therefore, it's replaced into a vCloud consumable resource outside of vCloud Director. It's then the administrator's responsibility to take that VM and import it into vCloud Director, placing it in an Org vDC or catalog that is relevant to the tenant. This is why you may want to use agent-based backups that understand the personality of the VM in question and can restore directly to the VM. This isn't an optimal solution by any means. Many backup vendors are hard at work figuring out alternative ways to back up VMs in the cloud.
Disaster recovery is an even tougher situation. The infrastructure management VMs can be protected today with SRM 5.1 and can seamlessly fail over to a DR site. The vApps that live in vCloud Director, on the other hand, can't, due to the UUID situation. When vCloud Director is configured, datastores in Provider vDCs are mapped with specific UUIDs, and the translation of the vApp to the datastore relies on those UUIDs to tell vCloud Director where they live. If SRM were to fail over vApps from vCloud Director to another vSphere infrastructure, then vCloud Director would be unaware of the UUIDs of the datastores at this new vSphere instance. This is the same reason you can't forklift a vCloud Director instance to another vSphere infrastructure.
A process is available from the VMware Professional Services organization to use native array replication with a series of scripts to perform a successful disaster recovery of the cloud. If you want to learn more about disaster recovery of the cloud, visit www.vmware.com. In addition, many service providers offer the ability to do disaster recovery to the cloud. As the technology matures, SRM will be able to satisfy automated disaster-recovery efforts for vCloud Director.
Summary
In this chapter, we looked at how many of the technologies previously discussed in this book, such as server profiling, networking design, storage design, and high availability, apply to a vCloud Director design. Let's summarize some of the key points.
Your cloud architecture has two key components, the management infrastructure and the consumable cloud resources. The growth of one directly impacts the other's design. The size of the management infrastructure depends on the size of the cloud deployment and the ecosystem of products used to create a cloud offering. The cloud resources can be any kind of vSphere design, but you need to define SLAs to create a level of service for Provider vDCs. Use user-friendly storage profiles for the tenants of your cloud.
We determined good use cases for external networks where end users need communication. The types of network pools are determined by feature availability of vSphere licensing as well as physical network capability.
The type of organization network you deploy for tenants of your cloud should directly reflect the needs and knowledge of your end users. Don't rush too much change with routed networks if your company isn't ready. If they're ready, more complex vApp networks are available to your end users and will let them maintain control.
Finally, remember that multiple sites can work in a single cloud, given the right amount of network resources, but a suggested implementation is to create isolated clouds.