
7.6 Bayes linear methods
7.6.1 Methodology
Bayes linear methods are closely related to point estimators resulting from quadratic loss. Suppose that we restrict attention to decision rules d(x) which are constrained to be a linear function ![]() of some known function y=y(x) of x and seek for a rule which, subject to this constraint, has minimum Bayes risk r(d). The resulting rule will not usually be a Bayes rule, but will not, on the other hand, necessitate a complete specification of the prior distribution. As we have seen that it can be very difficult to provide such a specification, there are real advantages to Bayes linear methods. To find such an estimator we need to minimize
of some known function y=y(x) of x and seek for a rule which, subject to this constraint, has minimum Bayes risk r(d). The resulting rule will not usually be a Bayes rule, but will not, on the other hand, necessitate a complete specification of the prior distribution. As we have seen that it can be very difficult to provide such a specification, there are real advantages to Bayes linear methods. To find such an estimator we need to minimize
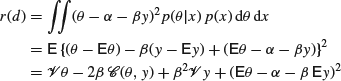
(since cross terms involving ![]() clearly vanish). By setting
clearly vanish). By setting ![]() , we see that the values
, we see that the values ![]() and
and ![]() which minimize r satisfy
which minimize r satisfy
![]()
and then setting ![]() we see that
we see that
![]()
so that the Bayes linear estimator is
![]()
It should be noted that, in contrast to Bayes decision rules, Bayes linear estimators do not depend solely on the observed data x – they also depend on the distribution of the data through ![]() ,
, ![]() and
and ![]() . For that reason they violate the likelihood principle.
. For that reason they violate the likelihood principle.
7.6.2 Some simple examples
7.6.2.1 Binomial mean
Suppose that ![]() and that y=x. Then using the results at the end of Section 1.5 on ‘Means and variances’
and that y=x. Then using the results at the end of Section 1.5 on ‘Means and variances’
![]()
Since ![]() , we see that
, we see that
![]()
so that
![]()
where
![]()
Note that the resulting posterior estimator for ![]() depends only on
depends only on ![]() and
and ![]() . This is an advantage if you think you can be precise enough about your prior knowledge of
. This is an advantage if you think you can be precise enough about your prior knowledge of ![]() to specify these quantities but find difficulty in giving a full specification of your prior which would be necessary for you to find the Bayes estimator for quadratic loss
to specify these quantities but find difficulty in giving a full specification of your prior which would be necessary for you to find the Bayes estimator for quadratic loss ![]() ; the latter cannot be evaluated in terms of a few summary measures of the prior distribution. On the other hand, we have had to use, for example, the fact that
; the latter cannot be evaluated in terms of a few summary measures of the prior distribution. On the other hand, we have had to use, for example, the fact that ![]() thus taking into account observations which might have been, but were not in fact, made, in contravention of the likelihood principle.
thus taking into account observations which might have been, but were not in fact, made, in contravention of the likelihood principle.
7.6.2.2 Negative binomial distribution
Suppose that ![]() and that y=z. Then similar formulae are easily deduced from the results in Appendix A. The fact that different formulae from those in the binomial case result when m=x and z=n–x, so that in both cases we have observed x successes and n − x failures, reflects the fact that this method of inference does not obey the likelihood principle.
and that y=z. Then similar formulae are easily deduced from the results in Appendix A. The fact that different formulae from those in the binomial case result when m=x and z=n–x, so that in both cases we have observed x successes and n − x failures, reflects the fact that this method of inference does not obey the likelihood principle.
7.6.2.3 Estimation on the basis of the sample mean
Suppose that x1, x2, … , xn are such that ![]() ,
, ![]() and
and ![]() but that you know nothing more about the distribution of the xi. Then
but that you know nothing more about the distribution of the xi. Then ![]() and
and

so that using the results at the end of Section 1.5 on ‘Means and variances’ ![]() and
and
![]()
Since ![]() , we see that
, we see that
![]()
It follows that
![]()
where
![]()
7.6.3 Extensions
Bayes linear methods can be applied when there are several unknown parameters. A brief account can be found in O’Hagan (1994, Section 6.48 et seq.) and full coverage is given in Goldstein and Wooff (2007).