
Sentic Computing for Social Network Analysis
F. Bisioa; L. Onetoa; E. Cambriab a University of Genoa, Genoa, Italy
b Nanyang Technological University, Singapore, Singapore
Abstract
Sentiment analysis and opinion mining have been acquiring a crucial role in both commercial and research applications because of their possible applicability to several different fields. Therefore a large number of companies have included the analysis of opinions and sentiments of customers as part of their mission. One of the most interesting applications of these approaches involves the automatic analysis of social network messages, on the basis of the feelings and emotions conveyed. This chapter aims to relate the most recent state-of-the-art sentiment-based techniques and tools to the affective characterization that may be inferred from social networks. The main result consists of a review of the most interesting methods employed to compare and classify messages on social media platforms and a description of advanced tools in this area.
Keywords
Sentiment analysis; Automatic analysis; Social network messages; Sentic computing; Affective commonsense reasoning; Emotion categorization
1 Introduction
Sentiment analysis or opinion mining can be defined as a particular application of data mining, which aims to aggregate and extract emotions and feelings from different types of documents [1]. The amount of data available on the web is growing exponentially; these data, however, are mainly in an unstructured format and hence are not machine processable and machine interpretable. Therefore graph-mining and natural language processing (NLP) techniques may contribute to the distillation of knowledge and opinions from the huge amount of information present in the web.
Sentiment analysis can enhance the capabilities of customer relationship management and recommendation systems by allowing one, for example, to find out which features customers are particularly interested in or to exclude from ads items that have received unfavorable feedback. Likewise, it can be used in social communication to enhance antispam systems.
Business intelligence can also benefit from sentiment analysis. Since predicting the attitude of the public toward a brand or a product has become of crucial importance for companies, an increasing amount of money has been invested in marketing strategies involving opinion and sentiment mining.
That scenario led to sentic computing [2], which tackles those crucial issues by exploiting affective commonsense reasoning (ie, the intrinsically human capacity to interpret the cognitive and affective information associated with natural language). In particular, sentic computing leverages a commonsense knowledge base built through crowdsourcing [3, 4]. Common sense is useful in many different computer science applications, including data visualization [5], text recognition [6], and human-computer interaction [7]. In this context, common sense is used to bridge the semantic gap between word-level natural language data and the concept-level opinions conveyed by these [8].
To perform affective commonsense reasoning [9], a knowledge database is required for storage and extraction of the affective and emotional information associated with word and multiword expressions. Graph-mining [10] and dimensionality reduction [11] techniques have been employed on a knowledge base obtained by the blending of ConceptNet [12], a directed graph representation of commonsense knowledge, with WordNet-Affect [13], a linguistic resource for the lexical representation of feelings. Unlike WordNet-Affect, SenticNet [14] and its extended versions [15, 16] exploit an ensemble of common and commonsense knowledge to go beyond word-level opinion mining, and hence to associate semantics and sentics with a set of natural language concepts.
With the rise of the Social Web, there are now millions of humans offering their knowledge online, which means that the information is stored, searchable, and easily shared. This trend has created and maintained an ecosystem of participation, where the value is created by the aggregation of many individual user contributions. Such contributions, however, are meant for human consumption and hence are hardly accessible and processable by computers. Making sense of the huge amount of social data available on the web requires the adoption of novel approaches to natural language understanding that can give a structure to such data in a way that they can be more easily aggregated and analyzed [17, 18].
Social networks are indeed a popular means of sharing data and ideas, and have witnessed an ever-increasing diffusion. The amount of data generated in 30 seconds on the Internet is about 600 GB of traffic1: this fact confirms that online information, with a particular focus on social networks, has become a source of big data. For example, considering the specific case of the Twitter community, every minute more than 320 new accounts are created and more than 98,000 tweets are posted. This makes the analysis of Twitter microblogging a topmost and significant domain for business intelligence and marketing strategies. A multiplicity of users populate this social network, sharing different types of information. The average age of users on Twitter ranges from 14 to 60 years, equally distributed among individuals of both genders. Hence among the multitude of tweets, one may want to retrieve information associated with specific relevant topics and identify the related polarity and affective characterization. Therefore one of the most interesting applications of sentiment analysis in recent years has involved social networks, so as to be able to analyze opinions on Twitter, Facebook, or other digital communities in real time [19–21]. In this context, sentic computing can be exploited for NLP tasks requiring the inference of semantic and/or affective information associated with both text (eg, for the analysis of social network interaction dynamics) [22] and online multimodal data [23].
This chapter presents an overview of the most recent and advanced technologies of sentiment analysis, with particular focus on the applications related to social networks. The main result consists of a review of the most interesting methods employed to compare, classify, and visualize messages on social media platforms. The chapter is organized as follows: Section 2 provides a description of state-of-the-art sentiment analysis techniques, with particular regard to the affective characterization of the data; Section 3 describes an affective characterization of emotions and sentiments; Section 4 describes several applications that employ sentiment analysis methods; Section 5 discusses some future trends and directions; and Section 6 presents our conclusions and final remarks.
2 Related Work
The Social Web has provided people with new content-sharing services that allow them to create and share personal content, ideas, and opinions, in a time-and cost-efficient way, with virtually millions of other people connected to the World Wide Web. Since this amount of information is mainly unstructured, research has so far focused on online information retrieval, aggregation, and processing.
The potential applications of concept-level sentiment analysis are countless and span interdisciplinary areas, such as stock market prediction, political forecasting, social network analysis, social stream mining, and man-machine interactions.
Today, most of the existing approaches still rely on word co-occurrence frequencies (ie, the syntactic representation of text). Therefore computational models aim to bridge the cognitive gap by emulating the way the human brain processes natural language. For instance, by leveraging semantic features that are not explicitly expressed in text, one may accomplish complex NLP tasks such as word-sense disambiguation, textual entailment, and semantic role labeling. Computational models are useful for both scientific purposes (such as exploring the nature of linguistic communication),and practical purposes (such as enabling effective human-machine communication [24]).
Most existing approaches to sentiment analysis rely on the extraction of a vector representing the most salient and important text features, which is later used for classification purposes [25, 26]. Commonly used features include term frequency and the presence and the position of a token in a text. An extension of this feature is the presence of n-grams, typically bigrams and trigrams. Other methods rely on the distance between terms or on the part-of-speech information: for example, certain adjectives may be good indicators of sentiment orientation. A drawback of these approaches is the strict dependency on the domain of application considered and the related topics.
Sentiment analysis systems aim to classify entire documents by associating content with some overall positive or negative polarity or rating scores (eg, 1–5 stars) [27–31]. These approaches are typically supervised and rely on manually labeled samples [32, 33]. We can distinguish between knowledge-based systems [34], based on approaches such as keyword spotting and lexical affinity, and statistics-based systems [35]. At first, the identification of emotions and polarity was performed mainly by means of knowledge-based methods; recently, sentiment analysis researchers have been increasingly using statistics-based approaches, with a special focus on supervised statistical methods.
Keyword spotting is the most straightforward, and possibly also the most popular, approach thanks to its accessibility and economy. Text is classified into affect categories on the basis of the presence of fairly unambiguous “affect words” such as “happy,” “sad,” “afraid,” and “bored.” Elliott’s Affective Reasoner [36], for example, looks for 198 affect keywords plus affect intensity modifiers and a handful of cue phrases. Other popular sources of affect words are Ortony’s Affective Lexicon [37], which groups terms into affective categories, and Wiebe’s linguistic annotation scheme [38]. The crucial issue of these approaches lies in the ineffectiveness at handling negations and in the structure based on the presence of obvious affect words.
Rather than simply detecting affect words, lexical affinity assigns each word a probabilistic “affinity” for a particular emotion. These probabilities are usually learned from linguistic corpora [39–41]. Even if this method often outperforms pure keyword spotting, it still works at word level and can be easily tricked by negations and different senses of the same word. Besides, lexical affinity probabilities are often biased by the linguistic corpora adopted, which makes it difficult to develop a reusable, domain-independent model.
Statistical-based approaches, such as Bayesian inference and support vector machines (SVMs), have been used in several projects [27, 42–44]. By feeding a machine learning algorithm [45] a large training corpus of affectively annotated texts, one can learn not only the affective valence of affect keywords (as in the keyword spotting approach), but also the affective valence of other arbitrary keywords (like lexical affinity), punctuation, and word co-occurrence frequencies. Anyway, it is worth noting that statistical classifiers work well only when a sufficiently large text dataset is given as input. This is because, with the exception of affect keywords, other lexical or co-occurrence elements possess little predictive value individually.
For example, Pang et al. [27] used a movie review dataset to compare the performance of different machine learning algorithms: in particular, they obtained 82.90% accuracy when they used a large number of textual features. Socher et al. [46] proposed a recursive neural tensor network and improved the accuracy (85%). Yu and Hatzivassiloglou [47] identified polarity at sentence level using semantic orientation of words. Melville et al. [48] developed a framework exploiting word-class association information for domain-dependent sentiment analysis. Bisio et al. [49] tackled a particular aspect of the sentiment classification problem: the ability of the framework itself to operate effectively in heterogeneous commercial domains. The approach adopts a distance-based predictive model to combine computational efficiency and modularity.
Some approaches are based on the following assumption: many short n-grams are usually neutral, while longer phrases are well distributed among positive and negative subjective sentence classes. Therefore matrix representations for long phrases and matrix multiplication to model composition can also be used to evaluate sentiment. In such models, sentence composition is modeled with use of deep neural networks such as recursive auto-associated memories. Recursive neural networks predict the sentiment class at each node in the parse tree and try to capture the negation and its scope in the entire sentence.
Several unsupervised learning approaches have also been proposed, and rely on the creation of the lexicon via the unsupervised labeling of words or phrases with their sentiment polarity or subjectivity [50]. To this aim, early work was mainly based on linguistic heuristics. For example, Hatzivassiloglou and McKeown [51] built a system based on “opposition constraints” to help label decisions in the case of polarity classification.
Other work exploited the seed words, defined as terms for which the polarity is known, and propagated them to terms that co-occur with them in general text, or in specific WordNet-defined relations. Popescu and Etzioni [52] proposed an algorithm that, starting from a global word label computed over a large collection of generic topic text, gradually tried to redefine such a label for a more and more specific corpus, until the one that is specific to the particular context in which the word occurs. Snyder and Barzilay [53] exploited the idea of utilizing discourse information to aid in the inference of relationships between product attributes.
Concept-based approaches [54–57] focus on a semantic analysis of text through the use of web ontologies or semantic networks, which allow the handling of conceptual and affective information associated with natural language opinions. By relying on large semantic knowledge bases, such approaches step away from blind use of keywords and word co-occurrence counts, and rather rely on the implicit meaning/features associated with natural language concepts. Unlike purely syntactical techniques, concept-based approaches are also able to detect sentiments that are expressed in a subtle manner (eg, through the analysis of concepts that do not explicitly convey any emotion but are implicitly linked to other concepts that do so).
More recent studies [58–61] tackled the problem of sentiment analysis in social networks: for example, by enhancing sentiment analysis of tweets by exploiting microblogging text or Twitter-specific features such as emoticons, hashtags, URLs, @ symbols, capitalization, and elongations. Tang et al. [62] developed a convolutional neural network–based approach to obtain word embeddings for the words mostly used in tweets. These word vectors were then fed to a convolutional neural network for sentiment analysis. A deep convolutional neural network for sentiment detection in short text was also proposed by dos Santos and Gatti [63]. The approach based on sentiment-specific word embeddings [64] considers word embeddings based on a sentiment corpus: this means the inclusion of more affective clues than regular word vectors and the production of a better result.
3 Affective Characterization
Emotions and affective information can be represented through the hourglass of emotions model [65], an affective categorization model that allows emotions to be deconstructed into independent but concomitant affective dimensions, whose different levels of activation compose the total emotional state of the mind. Such a reinterpretation is inspired by Minsky’s theory of the mind, according to which brain activity consists of different independent resources and that emotional states result from turning some set of these resources on and turning another set of them off.
The model can potentially synthesize the full range of emotional experiences in terms of four affective dimensions—pleasantness, attention, sensitivity, and aptitude—which define the intensity of the expressed/perceived emotion in the interval ∈ [−1,+1]. Each affective dimension is characterized by six levels of activation, termed “sentic levels,” which are also labeled as a set of 24 basic emotions (six for each affective dimension) (see Table 5.1). In the model the vertical dimension represents the intensity of the different affective dimensions (ie, their level of activation). The model follows the pattern used in color theory and research to obtain judgments about combinations (ie, the emotions that result when two or more fundamental emotions are combined).
Table 5.1
The Sentic Levels of the Hourglass Model
| Interval | Pleasantness | Attention | Sensitivity | Aptitude |
| G(1),G(2/3) | Ecstasy | Vigilance | Rage | Admiration |
| [G(2/3),G(1/3)) | Joy | Anticipation | Anger | Trust |
| [G(1/3),G(0)) | Serenity | Interest | Annoyance | Acceptance |
| (G(0),G(−1/3)] | Pensiveness | Distraction | Apprehension | Boredom |
| (G(−1/3),G(−2/3)] | Sadness | Surprise | Fear | Disgust |
| (G(−2/3),G(−1)] | Grief | Amazement | Terror | Loathing |

The transition between different emotional states is modeled, within the same affective dimension, by means of the function ![]() , for its symmetric inverted bell curve shape that quickly rises up toward 1. In particular, the function models how the valence or intensity of an affective dimension varies according to different values of arousal or activation, ranging from 0 (emotional void) to 1 (heightened emotionality). Mapping this space of possible emotions leads to a hourglass shape (see Fig. 5.1). The justification for assuming that the Gaussian function (rather than a step or simple linear function) is appropriate for modeling the variation of emotion intensity is based on research into the neural and behavioral correlates of emotion, which are assumed to indicate emotional intensity in some sense.
, for its symmetric inverted bell curve shape that quickly rises up toward 1. In particular, the function models how the valence or intensity of an affective dimension varies according to different values of arousal or activation, ranging from 0 (emotional void) to 1 (heightened emotionality). Mapping this space of possible emotions leads to a hourglass shape (see Fig. 5.1). The justification for assuming that the Gaussian function (rather than a step or simple linear function) is appropriate for modeling the variation of emotion intensity is based on research into the neural and behavioral correlates of emotion, which are assumed to indicate emotional intensity in some sense.

It is worth noting that, in the model, the state of “emotional void” is adimensional, which contributes to the creation of the hourglass shape. Total absence of emotion can be associated with the total absence of reasoning (or, at least, consciousness), which is not an envisaged mental state as, in the human mind, there is never nothing going on.
Complex emotions can be synthesized by use of different sentic levels, as shown in Table 5.2, which represent the intensity thresholds of the expressed or perceived emotion.
Table 5.2
The Emotions Generated by Pairwise Combination of the Sentic Levels of the Hourglass Model
| Attention >0 | Attention <0 | Aptitude >0 | Aptitude <0 | |
| Pleasantness >0 | Optimism | Frivolity | Love | Gloat |
| Pleasantness <0 | Frustration | Disapproval | Envy | Remorse |
| Sensitivity >0 | Aggressiveness | Rejection | Rivalry | Contempt |
| Sensitivity <0 | Anxiety | Awe | Submission | Coercion |

4 Applications
This section describes how sentic computing tools and techniques can be employed for the development of applications in the context of big social data analysis.
4.1 Troll Filtering
The democracy of the web has allowed a high degree of freedom of expression, which also gave birth to negative side effects: in the Social Web context the possibility of anonymity often results in the posting of inflammatory, extraneous, or off-topic messages in an online community, with the primary intent of provoking other users into making a desired emotional response or of otherwise disrupting normal on-topic discussion.
Such practice is usually referred to as “trolling,” and the generator of such messages is called a “troll.” Trolling appears to have spread a lot recently and it is alarming most of the biggest social networking sites since, in extreme cases such as abuse, it has led some teenagers to commit suicide. These attacks usually address not only individuals but also entire communities.
At present, users cannot do much other than to manually delete abusive messages. Current antitrolling methods mainly consist in identifying additional accounts that use the same IP address and blocking fake accounts on the basis of the name and anomalous site activity (eg, users who send lots of messages to nonfriends or whose friend requests are rejected at a high rate). Even though there is the possibility of reporting trouble, social networking websites usually cannot react instantly to these alarms.
A prior analysis of the trustworthiness of statements published on the web was presented by Rowe and Butters [66]. Their approach adopts a contextual trust value determined for the person who asserted a statement as the trustworthiness of the statement itself. Their study, however, focuses not on the problem of trolling but rather on defining a contextual accountability for the detection of web, email, and opinion spam.
The main aim of the troll filter [67] is to identify malicious content in natural language text with a certain confidence level and hence to automatically block trolls. To train the system, the concepts most commonly used by trolls are first identified by use of the concept frequency–inverted opinion frequency technique [2], and then this set is expanded through spectral association. In particular, after a set of 1000 offensive phrases extracted from Wordnik2 had been analyzed, it was found that, statistically, a post is likely to be edited by a troll when its average sentic vector has a high absolute value of sensitivity (one of the dimensions of the hourglass of emotions [65]) and a very low polarity. Hence the trollness ti associated with a concept ci ∈ [0,1] is
where si ∈ [0,1] is the semantic similarity of ci with any of the concept frequency–inverted opinion frequency seed concepts, pi ∈ [−1,1] is the polarity associated with the concept ci, and 3 is the normalization factor. Hence the total trollness of a post containing N concepts is defined as
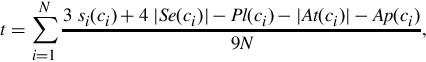
where Se is the sensitivity, Pl the pleasantness, At the attention, and AP the aptitude. This information is stored, together with the post type and content plus the sender ID and the receiver ID, in an interaction database that keeps track of all the messages and comments interchanged between users within the same social network.
Posts with a high level of trollness (with a threshold set, by means of a trial-and-error approach, to 60%) are labeled as troll posts and, whenever a specific user addresses more than two troll posts to the same person or community, his/her sender ID is labeled as a troll for that particular receiver ID. All the past troll posts sent to that particular receiver ID by that specific sender ID are then automatically deleted from the website. Moreover, any new post with a high level of trollness edited by a user labeled as a troll for that specific receiver is automatically blocked.
The evaluation of this approach [67] was performed by consideration of a set of 500 tweets manually annotated as troll and nontroll posts, most of which were fetched from Wordnik.
In Table 5.3 a comparison of three different vector space representations for commonsense concepts is presented. AnalogySpace [68] forms the analogical closure of a semantic network through dimensionality reduction. IsaCore [69] is a strongly connected core of hyponym-hypernym common knowledge. AffectNet is a semantic network in which commonsense concepts are linked to a hierarchy of affective domain labels (eg, “joy,” “amazement,” “fear,” “admiration”). To enable affective analogical reasoning on natural language concepts, AffectiveSpace [70] is obtained as the vector space representation of such a semantic network.
Table 5.3
Precision, Recall, and F Score for the Troll Filter Evaluation
| Metric | IsaCore (%) | AnalogySpace (%) | AffectiveSpace (%) |
| Precision | 57.1 | 69.1 | 82.5 |
| Recall | 40.0 | 56.6 | 75.1 |
| F score | 47.0 | 62.2 | 78.6 |

The results show that, by use of the troll filtering process, inflammatory and outrageous messages can be identified with good precision (82.5%) and a good recall rate (75.1%). In particular, the F score (78.6%) is significantly high compared with the corresponding F scores obtained by use of IsaCore and AnalogySpace in place of the AffectiveSpace process (Table 5.3).
4.2 Social Media Marketing
The online review of commercial services and products allows users to share their opinions about services they have received or products they have bought, and it constitutes an immeasurable value for other potential buyers. This trend opened new doors to enterprises that want to reinforce their brand and product presence in the market by investing in online advertising and positioning. Given the growing interest in social media marketing, several commercial tools have been developed recently to provide companies with the possibility to analyze the blogosphere on a large scale so they can extract information about the trend of the opinions relative to their products. Nevertheless, most of the existing tools and research efforts are limited to a polarity evaluation or a mood classification according to a very limited set of emotions. In addition, such methods mainly rely on parts of text in which emotional states are explicitly expressed, and hence they are unable to capture opinions and sentiments that are expressed implicitly.
To this end, a novel social media marketing tool has been proposed [71] to provide marketers with a tool for the management of social media information at the semantic level, able to capture both opinion polarity and affective information.
In particular, YouTube was selected as a social media source since, with its more than 2 billion views per day, 24 hours of video uploaded every minute, and 15 minutes a day spent by the average user, it represents more than 40% of the online video market.3 Specifically, the focus was on video reviews of cell phones because of the quantity and the quality of the comments usually associated with them.
The social media analysis was performed through three main steps: firstly, comments are analyzed with an opinion mining engine; secondly, the extracted information is encoded on the basis of different web ontologies; finally, the resulting knowledge base is made available for browsing through a multifaceted classification website.
To make the tool applicable to most online resources (videos, images, text), the information relative to multimedia resources and people is encoded with use of the descriptors provided by the Ontology for Media Resources (OMR)4 and Friend of a Friend (FOAF) ontology5 respectively.
OMR offers a core vocabulary to describe media resources on the web, introducing descriptors such as “title,” “creator,” “publisher,” “createDate,” and “rating,” and it defines semantic-preserving mappings between elements from existing formats to foster interoperability among them.
FOAF represents a recognized standard in describing people, providing information such as their names, birthdays, pictures, blogs, and especially other people they know, which makes it particularly suitable for representing data that appear in social networks and communities.
OMR and FOAF together supply most of the vocabulary needed to describe media and people; other descriptors are added only when necessary. For example, OMR does not currently supply vocabulary for describing comments, which are hereby analyzed to extract the affective information relative to media. Hence the ontology is extended by the introduction of the “Comment” class and by defining for it the “author,” “text,” and “publicationDate” properties.
In the human emotion ontology (HEO) [72], properties to link emotions to multimedia resources and people are introduced (see Fig. 5.2). Additionally, WordNet-Affect [13] is exploited as an ontology to improve the hierarchical organization of emotions in HEO. Thus the combination of HEO and WordNet-Affect, OMR, and FOAF provides a complete framework to describe not only multimedia content and the users that have created, uploaded, or interacted with it but also the opinions and the affective content carried by the media and the way they are perceived by web users. To make this information visualizable, the multifaceted categorization paradigm is exploited (see Fig. 5.3). Faceted classification allows the assignment of multiple categories to an object, enabling the classifications to be ordered in multiple ways, rather than in a single, pre-determined, and taxonomic order. This makes it possible to perform searches combining the textual approach with the navigational one.


To evaluate the proposed system on the level of both opinion mining and sentiment analysis, its polarity detection accuracy was separately tested with a set of like/dislike-rated video reviews from YouTube and its affect recognition capabilities were evaluated with a corpus of mood-tagged blogs from LiveJournal.
To evaluate the system in terms of polarity detection accuracy, the YouTube data application programming interface was used to retrieve from the YouTube database the ratings relative to 220 video reviews of cell phones. On YouTube, users can express their opinions about videos either by adding comments or by simply rating them using a like/dislike button. The YouTube data application programming interface makes this kind of information available by providing, for each video, the number of raters and the average rating (ie, the sum of likes and dislikes divided by the number of raters).
This takes a value in the range [1,5] and indicates if a video is generally considered bad (values in the range [1,3]) or good (values in the range [3,5]). This information was compared with the polarity values previously extracted by use of sentic computing on the comments relative to each of the 220 videos. True positives were identified as videos with both an average rating r ∈ [3,5] and a polarity p ∈ [0,1] (for positively rated videos), or videos with both an average rating r ∈ [1,3] and a polarity p ∈ [−1,0] (for negatively rated videos). The evaluation showed that, by use of the system to perform polarity detection, negatively and positively rated videos (37.7% and 62.3% of the total respectively) can be identified with a precision of 97.1% and recall of 86.3% (F score of 91.3%).
Since no mood-labeled dataset regarding commercial products is currently available, the LiveJournal database was used to test the system’s affect recognition capabilities. For this test, a reduced set of 10 moods was considered: ecstatic, happy, pensive, surprised, enraged, sad, angry, annoyed, scared, and bored. After relevant data and metadata for 5000 posts had been had been retrieved and stored, the sentics extraction process was conducted on each of these and the outputs were compared with the relative LiveJournal mood tags to compute recall and precision rates as evaluation metrics.
On average, each post contained around 140 words and, from this about 4 affective valence indicators and 60 sentic vectors were extracted. According to this information, mood labels were assigned to each post and compared with the corresponding LiveJournal mood tags, resulting in very good accuracy for each of the 10 selected moods (Table 5.4). Among these, “happy” and “sad” posts were identified with particularly high precision (89.2% and 81.8% respectively) and good recall rates (76.5% and 68.4%). The F scores obtained were also good (82.3% and 74.5% respectively), especially when compared with the corresponding F scores for a standard keyword spotting system based on a set of 500 affect words (65.7% and 58.6%).

4.3 A Model for Sentiment Classification in Twitter
This section describes a Twitter sentiment analysis system able to classify a tweet as positive or negative on the basis of its overall tweet-level polarity. The need for such a tool comes from the following consideration: supervised learning classifiers often misclassify tweets containing conjunctions such as “but” and conditionals such as “if” because of their special linguistic characteristics. Moreover, tweets often contain misspelled words, slang, URLs, elongations, repeated punctuation, emoticons, abbreviations, and hashtags. To counter these challenges, a system that enhances supervised learning for polarity classification by leveraging linguistic rules and sentic computing resources is proposed [61]. The general scheme of the system is presented in Fig. 5.4.

First all tweets are preprocessed to change all the @<username> references to @USER and all the URLs to http://URL.com. Then tweets are tokenized and a part-of-speech tag is assigned to each token. Then all the emoticons are identified. Since people often repeat certain punctuation to emphasize emoticons, all repeated characters from every emoticon string are removed to obtain the bag of emoticons present in the tweet.
The number of positive and negative emoticons in the tweet are counted and the following rules are applied:
• If a tweet contains one or more positive emoticons and no negative emoticons, it is labeled as positive.
• If a tweet contains one or more negative emoticons and no positive emoticons, it is labeled as negative.
• If neither of the two rules above can be applied, the tweet is labeled as unknown.
If these emoticon-based rules label a tweet as positive or negative, this is considered the final label outputted by the system. Otherwise all tweets labeled as unknown are passed into a supervised learning classifier. In this case, each tweet is represented as a feature vector of case-sensitive n-grams (unigrams, bigrams, and trigrams). These n-grams are frequencies of sequences of one, two, or three contiguous tokens in a tweet. Besides, negation is taken into consideration. Moreover, all tweets containing the conjunction “but” and the conditionals “if,” “unless,” “until,” and “in case” are considered, and specific linguistic rules are formulated to enable removal of irrelevant or oppositely oriented n-grams from the tweet’s feature vector.
Finally, a SVM classifier is trained so as to obtain the tweet’s label. For tweets with an absolute decision score or confidence below 0.5, the class labels assigned by the SVM are discarded and an unsupervised classifier is employed. This unsupervised classification process works as follows:
1. Single-word and multiword concepts are extracted from the tweets so as to fetch their polarities from SenticNet [14].
2. If a single-word concept is not found in SenticNet, it is queried in SentiWordNet [73], and if it is not found in SentiWordNet, it is searched for in the list of positive and negative words from the Bing Liu lexicon [74].
3. On the basis of the number of positive and negative concepts, and the most polar value occurring in the tweet, the following rules are applied:
• If the number of positive concepts is greater than the number of negative concepts and the most polar value occurring in the tweet is greater than or equal to 0.6, the tweet is labeled as positive.
• If the number of negative concepts is greater than the number of positive concepts and the most polar value occurring in the tweet is less than or equal to –0.6, the tweet is labeled as negative.
• If neither of the two rules stated above can be applied, the tweet is labeled as unknown by the rule-based classifier, and the SVM’s low confidence prediction is taken as the final output of the system.
An SVM classifier [75] was trained on 1.6 million positive and negative tweets provided by Go et al. [76]. After a standard 10 cross-validation procedure to set the model parameters [77, 78], the method was evaluated on two publicly available datasets: SemEval 2013 [79] and SemEval 2014 [80]. Tables 5.5 and 5.6 show the results obtained on these two datasets. In these tables, each row shows the precision, recall, and F score for the positive and negative classes, followed by the average positive and negative precision, recall, and F score. In the tables we indicate as modified n-grams the method that takes into account the linguistic rules employed on conjunctions and conditionals.
Table 5.5
Results Obtained on 1794 Positive/Negative Tweets From the SemEval 2013 Dataset
| Positive | Negative | Average | |||||||
| Method | P | R | F | P | R | F | P | R | F |
| n-grams | 90.48 | 82.67 | 86.40 | 61.98 | 76.45 | 68.46 | 76.23 | 79.56 | 77.43 |
| n-grams and emoticon rules | 90.62 | 83.36 | 86.84 | 62.99 | 76.65 | 69.15 | 76.80 | 80.00 | 78.00 |
| Modified n-grams | 89.95 | 84.05 | 86.90 | 63.33 | 74.59 | 68.50 | 76.64 | 79.32 | 77.70 |
| Modified n-grams and emoticon rules | 90.10 | 84.73 | 87.33 | 64.41 | 74.79 | 69.22 | 77.26 | 79.76 | 78.27 |
| Modified n-grams, emoticon rules, and word-level unsupervised rules | 91.40 | 86.79 | 89.04 | 68.55 | 77.89 | 72.92 | 79.97 | 82.34 | 80.98 |
| Modified n-grams, emoticon rules, and concept-level unsupervised rules | 92.42 | 86.56 | 89.40 | 68.96 | 80.79 | 74.41 | 80.69 | 83.68 | 81.90 |

F, F score; P, precision; R, recall.
Table 5.6
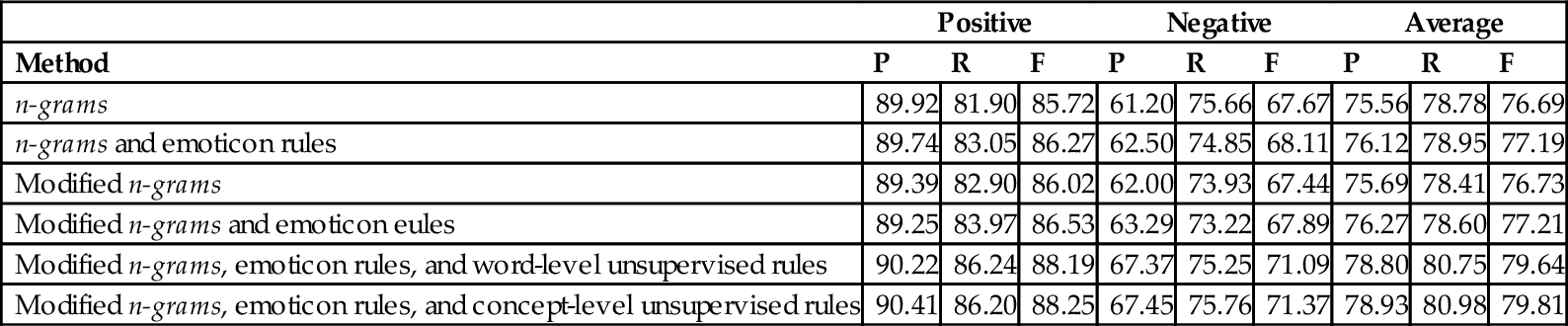
Results Obtained on 3584 Positive/Negative Tweets From the SemEval 2014 Dataset
| Positive | Negative | Average | |||||||
| Method | P | R | F | P | R | F | P | R | F |
| n-grams | 89.92 | 81.90 | 85.72 | 61.20 | 75.66 | 67.67 | 75.56 | 78.78 | 76.69 |
| n-grams and emoticon rules | 89.74 | 83.05 | 86.27 | 62.50 | 74.85 | 68.11 | 76.12 | 78.95 | 77.19 |
| Modified n-grams | 89.39 | 82.90 | 86.02 | 62.00 | 73.93 | 67.44 | 75.69 | 78.41 | 76.73 |
| Modified n-grams and emoticon eules | 89.25 | 83.97 | 86.53 | 63.29 | 73.22 | 67.89 | 76.27 | 78.60 | 77.21 |
| Modified n-grams, emoticon rules, and word-level unsupervised rules | 90.22 | 86.24 | 88.19 | 67.37 | 75.25 | 71.09 | 78.80 | 80.75 | 79.64 |
| Modified n-grams, emoticon rules, and concept-level unsupervised rules | 90.41 | 86.20 | 88.25 | 67.45 | 75.76 | 71.37 | 78.93 | 80.98 | 79.81 |
F, F score; P, precision; R, recall.
When comparing the standard n-grams model with the n-grams and emoticon rules model, one may notice that emoticon rules increase the average F by 0.57 and 0.50 in the 2013 and 2014 datasets respectively. A comparison between the modified n-grams model and the modified n-grams and emoticon rules model also shows that emoticon rules increase the average F by 0.57 and 0.48 in the two datasets respectively. This confirms that emoticon rules may significantly improve the classification. Moreover, modification of n-grams with use of linguistic rules for conjunctions and conditionals increases the average F by 0.27 and 0.04 in the two datasets respectively. Even if the increase is not very significant for the 2014 dataset, modified n-grams are still useful since a typical Twitter corpus usually contains a very small percentage of tweets with such conjunctions and conditionals.
A further comparison involves the analysis of the unsupervised rules: the results obtained by use of a bag-of-concepts model are compared with the ones obtained by use of a bag-of-words (or single-word concepts only) model. The average F for the bag-of-concepts model is 0.92 greater than for the bag-of-words model for the 2013 dataset, and 0.17 greater than the bag-of-words model for the 2014 dataset, thus confirming the effectiveness of the concept-level sentiment features. Overall, the final sentiment analysis system achieves an average F score that is greater by 4.47 and 3.12 than for the standard n-grams model.
5 Future Trends and Directions
The research work carried out so far has formed a solid base for the development of a variety of emotion-sensitive systems and applications in the fields of opinion mining and sentiment analysis. This chapter has presented an overview of approaches to the analysis of opinions and sentiments in social networks, which go beyond keyword-based methods by using commonsense reasoning tools and affective ontologies. The techniques developed, however, are still far from perfect as the common and commonsense knowledge bases need to be further expanded and the reasoning tools built on top of them adjusted accordingly.
To overcome these limitations, current research work is focusing on expanding the affective knowledge by employing external resources (eg, Cyc, Freebase, and Yago). New graph-mining and multidimensionality reduction techniques are also being explored to perform reasoning on the commonsense knowledge bases. Moreover, new classification techniques are being tested, together with the ensemble application of dimensionality reduction and neural networks techniques for emulation of fast affective learning. Therefore, looking ahead, we believe the combined use of different knowledge bases and affective commonsense reasoning techniques will, eventually, pave the way for the development of more bio-inspired approaches to the design of intelligent systems capable of handling knowledge, making analogies, learning from experience, and perceiving and expressing affect.
6 Conclusion
With the advent of the Social Web, the way people express their views and opinions has dramatically changed. Social networks now represent huge sources of information with many practical applications. However, finding opinion sources and monitoring them can be a formidable task because there are a large number of diverse sources and each source may also have a huge volume of opinionated text. Thus automated opinion discovery and summarization systems are needed. Because of their tremendous value for practical applications, there has been an explosive growth of sentiment analysis techniques in both research in academia and applications in industry. However, most of the existing approaches still rely on syntactical structure of text, which is far from the way the human mind processes natural language.
In this chapter we have presented an overview of the most recent state-of-the-art sentiment-based techniques applied to social networks applications and tools. To assess the capability of sentiment analysis to tackle real-world NLP tasks, we considered several applications in different domains. Specifically, sentiment analysis tools and techniques were used for the design of Social Web applications (ie, a troll filtering system, a social media marketing tool, and a Twitter sentiment analysis system).
All these applications demonstrate how sentiment analysis can be a useful resource for the analysis of affective information in social platforms, relying not on domain-dependent keywords but rather on commonsense knowledge bases that allow one to extrapolate the cognitive and affective information associated with natural language text.