
Introduction
1.1 Introduction to Heterogeneous Computing
Heterogeneous computing includes both serial and parallel processing. With heterogeneous computing, tasks that comprise an application are mapped to the best processing device available on the system. The presence of multiple devices on a system presents an opportunity for programs to utilize concurrency and parallelism, and improve performance and power. Open Computing Language (OpenCL) is a programming language developed specifically to support heterogeneous computing environments. To help the reader understand many of the exciting features provided in OpenCL 2.0, we begin with an introduction to heterogeneous and parallel computing. We will then be better positioned to discuss heterogeneous programming in the context of OpenCL.
Today’s heterogeneous computing environments are becoming more multifaceted, exploiting the capabilities of a range of multicore microprocessors, central processing units (CPUs), digital signal processors, reconfigurable hardware (field-programmable gate arrays), and graphics processing units (GPUs). Presented with so much heterogeneity, the process of mapping the software task to such a wide array of architectures poses a number of challenges to the programming community.
Heterogeneous applications commonly include a mix of workload behaviors, ranging from control intensive (e.g. searching, sorting, and parsing) to data intensive (e.g. image processing, simulation and modeling, and data mining). Some tasks can also be characterized as compute intensive (e.g. iterative methods, numerical methods, and financial modeling), where the overall throughput of the task is heavily dependent on the computational efficiency of the underlying hardware device. Each of these workload classes typically executes most efficiently on a specific style of hardware architecture. No single device is best for running all classes of workloads. For instance, control-intensive applications tend to run faster on superscalar CPUs, where significant die real estate has been devoted to branch prediction mechanisms, whereas data-intensive applications tend to run faster on vector architectures, where the same operation is applied to multiple data items, and multiple operations are executed in parallel.
1.2 The Goals of This Book
The first edition of this book was the first of its kind to present OpenCL programming in a fashion appropriate for the classroom. In the second edition, we updated the contents for the OpenCL 1.2 standard. In this version, we consider the major changes in the OpenCL 2.0 standard, and we also consider a broader class of applications. The book is organized to address the need for teaching parallel programming on current system architectures using OpenCL as the target language. It includes examples for CPUs, GPUs, and their integration in the accelerated processing unit (APU). Another major goal of this book is to provide a guide to programmers to develop well-designed programs in OpenCL targeting parallel systems. The book leads the programmer through the various abstractions and features provided by the OpenCL programming environment. The examples offer the reader a simple introduction, and then proceed to increasingly more challenging applications and their associated optimization techniques. This book also discusses tools for aiding the development process in terms of profiling and debugging such that the reader need not feel lost in the development process. The book is accompanied by a set of instructor slides and programming examples, which support its use by an OpenCL instructor. Please visit http://store.elsevier.com/9780128014141 for additional information.
1.3 Thinking Parallel
Most applications are first programmed to run on a single processor. In the field of high-performance computing, different approaches have been used to accelerate computation when provided with multiple computing resources. Standard approaches include “divide-and-conquer” and “scatter-gather” problem decomposition methods, providing the programmer with a set of strategies to effectively exploit the parallel resources available in high-performance systems. Divide-and-conquer methods iteratively break a problem into smaller subproblems until the subproblems fit well on the computational resources provided. Scatter-gather methods send a subset of the input data set to each parallel resource, and then collect the results of the computation and combine them into a result data set. As before, the partitioning takes account of the size of the subsets on the basis of the capabilities of the parallel resources. Figure 1.1 shows how popular applications such as sorting and a vector-scalar multiply can be effectively mapped to parallel resources to accelerate processing.

Programming has become increasingly challenging when faced with the growing parallelism and heterogeneity present in contemporary computing systems. Given the power and thermal limits of complementary metal-oxide semiconductor (CMOS) technology, microprocessor vendors find it difficult to scale the frequency of these devices to derive more performance, and have instead decided to place multiple processors, sometimes specialized, on a single chip. In their doing so, the problem of extracting parallelism from a application is left to the programmer, who must decompose the underlying tasks and associated algorithms in the application and map them efficiently to a diverse variety of target hardware platforms.
In the past 10 years, parallel computing devices have been increasing in number and processing capabilities. During this period, GPUs appeared on the computing scene, and are today providing new levels of processing capability at very low cost. Driven by the demands of real-time three-dimensional graphics rendering (a highly data-parallel problem), GPUs have evolved rapidly as very powerful, fully programmable, task- and data-parallel architectures. Hardware manufacturers are now combining CPU cores and GPU cores on a single die, ushering in a new generation of heterogeneous computing. Compute-intensive and data-intensive portions of a given application, called kernels, may be offloaded to the GPU, providing significant performance per watt and raw performance gains, while the host CPU continues to execute non-kernel tasks.
Many systems and phenomena in both the natural world and the man-made world present us with different classes of parallelism and concurrency:
• Molecular dynamics—every molecule interacting with every other molecule.
• Weather and ocean patterns—millions of waves and thousands of currents.
• Multimedia systems—graphics and sound, thousands of pixels and thousands of wavelengths.
• Automobile assembly lines—hundreds of cars being assembled, each in a different phase of assembly, with multiple identical assembly lines.
Parallel computing, as defined by Almasi and Gottlieb [1], is a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently (i.e. in parallel). The degree of parallelism that can be achieved is dependent on the inherent nature of the problem at hand (remember that there exists significant parallelism in the world), and the skill of the algorithm or software designer to identify the different forms of parallelism present in the underlying problem. We begin with a discussion of two simple examples to demonstrate inherent parallel computation: multiplication of two integer arrays and text searching.
Our first example carries out multiplication of the elements of two arrays A and B, each with N elements storing the result of each multiply in the corresponding element of array C. Figure 1.2 shows the computation we would like to carry out. The serial C++ program code would be follows:


This code possesses significant parallelism, though a very low compute intensity. Low compute intensity in this context refers to the fact that the ratio of arithmetic operations to memory operations is small. The multiplication of each element in A and B is independent of every other element. If we were to parallelize this code, we could choose to generate a separate execution instance to perform the computation of each element of C. This code possesses significant data-level parallelism because the same operation is applied across all of A and B to produce C.
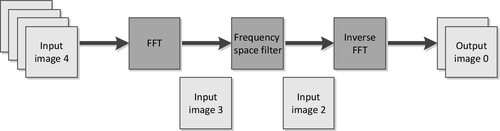
We could also view this breakdown as a simple form of task-level parallelism. A task is a piece of work to be done or undertaken, sometimes used instead of the operating system term process. In our discussion here, a task operates on a subset of the input data. However, task parallelism generalizes further to execution on pipelines of data or even more sophisticated parallel interactions. Figure 1.3 shows an example of task parallelism in a pipeline to support filtering of images in frequency space using a fast Fourier transform.
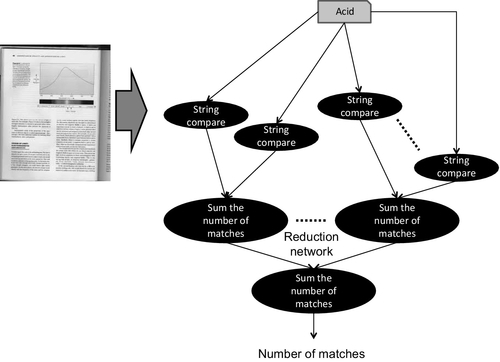
Let us consider a second example. The computation we are trying to carry out is to find the number of occurrences of a string of characters in a body of text (see Figure 1.4). Assume that the body of text has already been appropriately parsed into a set of N words. We could choose to divide the task of comparing the string against the N potential matches into N comparisons (i.e. tasks). In each task a string of characters is matched against the text string. This approach, although rather naïve in terms of search efficiency, is highly parallel. The process of the input text string being compared against each of the set of potential words presents N parallel tasks. Each parallel task is carrying out the same set of operations. There is even further parallelism within a single comparison task, where the matching on a character-by-character basis presents a finer-grained degree of parallelism. This example exhibits both data-level parallelism (we are going to be performing the same operation on multiple data items) and task-level parallelism (we can compare the input string against multiple different words concurrently).

Once the number of matches has been determined, we need to accumulate them to compute the total number of occurrences. Again, this summing can exploit parallelism. In this step, we introduce the concept of “reduction,” where we can utilize parallel resources to combine partial sums in a very efficient manner. Figure 1.5 shows the reduction tree, which illustrates this summation process performed in ![]() steps.
steps.
1.4 Concurrency and Parallel Programming Models
Next, we discuss concurrency and parallel processing models so that when attempting to map an application developed in OpenCL to a parallel platform, we can select the right model to pursue. Although all of the following models can be supported in OpenCL, the underlying hardware may restrict which model will be practical to use.
Concurrency is concerned with two or more activities happening at the same time. We find concurrency in the real world all the time—for example, carrying a child in one arm while crossing a road or, more generally, thinking about something while doing something else with one’s hands. When talking about concurrency in terms of computer programming, we mean a single system performing multiple tasks independently. Although it is possible that concurrent tasks may be executed at the same time (i.e. in parallel), this is not a requirement. For example, consider a simple drawing application, which is either receiving input from the user via the mouse and keyboard or updating the display with the current image. Conceptually, receiving input and processing input are operations (i.e. tasks) different from updating the display. These tasks can be expressed in terms of concurrency, but they do not need to be performed in parallel. In fact, in the case in which they are executing on a single core of a CPU, they cannot be performed in parallel. In this case, the application or the operating system should switch between the tasks, allowing both some time to run on the core.
Parallelism is concerned with running two or more activities in parallel with the explicit goal of increasing overall performance. For example, consider the following assignments:

The assignments of A and D in steps 1 and 2 (respectively) are said to be independent of each other because there is no data flow between these two steps. The variables E and G on the right side of step 2 do not appear on the left side of step 1. Vice versa, the variables B and C on the right sides of step 1 do not appear on the left side of step 2.). Also the variable on the left side of step 1 (A) is not the same as the variable on the left side of step 2 (D). This means that steps 1 and 2 can be executed in parallel (i.e. at the same time). Step 3 is dependent on both steps 1 and 2, so cannot be executed in parallel with either step 1 or step 2.
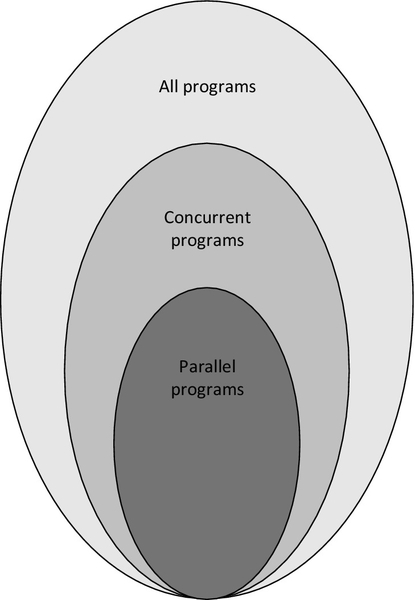
Parallel programs must be concurrent, but concurrent programs need not be parallel. Although many concurrent programs can be executed in parallel, interdependencies between concurrent tasks may preclude this. For example, an interleaved execution would still satisfy the definition of concurrency while not executing in parallel. As a result, only a subset of concurrent programs are parallel, and the set of all concurrent programs is itself a subset of all programs. Figure 1.6 shows this relationship.
In the remainder of this section some well-known approaches to programming heterogeneous, concurrent and parallel systems are introduced with the aim of providing a foundation before we introduce OpenCL in Chapters 2 and 3.
1.5 Threads and Shared Memory
A running program (called a process) may consist of multiple subprograms that each maintains its own independent control flow, and which as a group are allowed to run concurrently. These subprograms are called threads. All of the threads executing within a process share some resources (e.g., memory, open-files, global variables), but also have independent local storage (e.g., stack, automatic variables). Threads communicate with each other using variables allocated in the globally shared address space. Communication requires synchronization constructs to ensure that multiple threads are not updating the same memory location at the same time.
In shared memory systems, all processors have the ability to view the same address space (i.e., they view the same global memory). A key feature of the shared memory model is the fact that the programmer is not responsible for managing data movement. For these types of systems, it is especially important that the programmer and hardware have a well-defined agreement concerning updates to global data shared between threads. This agreement is called a memory consistency model. Memory consistency models are often supported in programming languages using higher-level constructs such as mutexes and semaphores, or acquire/release semantics as in the case of Java, C/C++11, and OpenCL. By having the programmer explicitly inform the hardware when certain types of synchronization must be performed, the hardware is able to execute concurrent programs with much greater efficiency.
As the number of processor cores increase, there is a significant cost to supporting shared memory in hardware. The length of wires (latency, power), number of interfaces between hardware structures, and number of shared bus clients quickly become limiting factors. The extra hardware required typically grows exponentially in terms of its complexity as we attempt to add additional processors. This has slowed the introduction of multicore and multiprocessor systems at the low end, and it has limited the number of cores working together in a consistent shared memory system to relatively low numbers because shared buses and coherence protocol overheads become bottlenecks. More relaxed shared memory systems scale better, although in all cases, scaling the number of cores in a shared memory system comes at the cost of complicated and expensive interconnects. Most multicore CPU platforms support shared memory in one form or another. OpenCL supports execution on shared memory devices.
1.6 Message-Passing Communication
An alternative to shared memory is to use a message-passing model. This model uses explicit intercommunication between a set of concurrent tasks that need to share data during computation. Multiple tasks can reside on the same physical device and/or across an arbitrary number of devices. Tasks exchange data through communications by sending and receiving explicit messages. Data transfer usually requires complementary operations to be performed by each process. For example, a send operation must have a matching receive operation.
From a programming perspective, message-passing implementations commonly comprise a library of hardware-independent routines for sending and receiving messages. The programmer is responsible for explicitly managing communication between tasks. Historically, a variety of message-passing libraries have been available since the 1980s. The Message Passing Interface (MPI) library is currently the most popular message-passing middleware [2]. Different implementations of the MPI library differ substantially from each other, making it difficult for programmers to develop performance-portable applications.
1.7 Different Grains of Parallelism
Whether we are using shared memory with threads, or explicit message passing, we can also vary the size (i.e. the grain) of the parallel unit of execution. The parallel unit of execution simply refers to the amount of independent work done by each executing thread. In discussion of parallel computing, granularity is a measure of the ratio of computation to communication.
The grain of parallelism is constrained by the inherent characteristics of the algorithms constituting the application. It is important that the parallel programmer select the right granularity to reap the full benefits of the underlying platform, because choosing the right grain size can help to expose additional degrees of parallelism. Sometimes the selection of granularity is referred to as chunking, determining the amount of data to assign to each task. Selecting the right chunk size can help provide further acceleration on parallel hardware. The following is a list of the trade-offs that factor into this key parallel programming attribute:
Chunking using fine-grained parallelism with a large number of independent tasks needs to consider the following:
• Compute intensity needs to be moderate so that each independent unit of parallelism has sufficient work to do.
• The cost of communication needs to be low so that each independent unit of parallelism can execute independently.
• Workload scheduling is important in fine-grained parallelism owing to the large number of independent tasks that can execute in parallel. The flexibility provided by an effective workload scheduler can and achieve load balance when a large number of tasks are being executed.
Chunking using coarse-grained parallelism needs to consider the following:
• Compute intensity needs to be higher than in the fine-grained case since there are fewer tasks that will execute independently.
• Coarse-grained parallelism would require the developer to identify complete portions of an application that can serve as a task.
Given these trade-offs, which granularity will lead to the best implementation? The most efficient granularity is dependent on the algorithm and the hardware environment in which it is run. In most cases, if the overhead associated with communication and synchronization is high relative to the amount of the computation in the task at hand, it will generally be advantageous to work at a coarser granularity as this will limit the overhead of communication and scheduling. Fine-grained parallelism can help reduce overhead due to load imbalance and memory delays (this is particularly true on a GPU, which depends on zero-overhead fine-grained thread switching to hide memory latencies).
If we have a computation that involves performing the same set of operations over a large amount of data, we can treat the data as a vector, and perform the same operation over multiple data inputs, generating multiple data outputs in a single vector operation. This grain of processing allows us to utilize a single instruction, multiple data (SIMD) style of operation, and typically leverages parallel hardware to perform the operation on different input data, in parallel. This grain of parallelism uses the size of the vector or the width of the SIMD unit to obtain execution speedup.
In the attempt to find the best computing grain, why not just issue copies of the same program to the available processing elements or nodes, relaxing the ordering between the execution of these copies so that they can run efficiently on a shared system with many processors? While an SIMD model has similarities to a single program, multiple data (SPMD) model, an SPMD model does not limit synchronization to instruction boundaries as does an SIMD model, and instead allows copies of the task or kernel to be run concurrently.
1.7.1 Data Sharing and Synchronization
A key factor to consider when developing heterogeneous software is the amount of data sharing that is inherent in a single task or across multiple tasks. Consider the case in which two tasks run that do not share any data. As long as the runtime system or operating system has access to adequate execution resources, the two tasks can be run concurrently or even in parallel. If halfway through the execution of the first task, the first task generates a result that was subsequently required by the second task, then we would have to introduce some form of synchronization into the system, and parallel execution—at least across the synchronization point—becomes more challenging.
When one is writing concurrent software, data sharing and synchronization play a critical role. Examples of data sharing in concurrent programs include the following:
• The input of a task is dependent on the result of another task—for example, in a producer-consumer or pipeline execution model.
• When intermediate results are combined together (e.g. as part of a reduction, as in our word search example shown in Figure 1.5).
Ideally, we would attempt to parallelize only portions of an application that are void of data dependencies, but that may not always be the case. Explicit synchronization primitives such as barriers and locks may be used to support synchronization when necessary. Although we only raise this issue here, later chapters revisit this question in OpenCL, providing a mechanism to support communication between host and device programs or when synchronization between tasks is required.
1.7.2 Shared Virtual Memory
In many heterogeneous systems, execution is split between different devices, and explicit synchronization and communication is used to communicate data values between the tasks running on each device. Shared virtual memory is a contract between the hardware and the software that allows devices to share a common view of memory, easing the task of programming and eliminating the need for explicit communication. OpenCL 2.0 introduces support for shared virtual memory, reducing expensive communication messages during execution, and removing the need to maintain multiple copies of a memory address on each device. We will discuss shared virtual memory in the context of OpenCL in detail in later chapters.
OpenCL 2.0 provides three different types of sharing:
• coarse-grained buffer sharing,
• fine-grained buffer sharing,
• fine-grained system sharing.
Using any flavor of shared virtual memory requires OpenCL implementations to make addresses meaningful between the host and devices in the system. This enables pointer-based data structures (such as linked lists) that could not previously be supported in OpenCL. Coarse-grained buffer sharing supports updates at the granularity of entire buffers and is achieved through API calls. Fine-grained buffer and system sharing support updates at the granularity of individual bytes within a buffer or anywhere in host memory, respectively. Fine-grained sharing support is achieved using synchronization points with ordering defined by the memory consistency model. These topics are covered in greater depth in Chapters 6 and 7.
1.8 Heterogeneous Computing with OpenCL
Now that the reader has more background on heterogeneous and parallel programming concepts, we will identify features that are supported in OpenCL. We begin with a brief history and overview of the language.
OpenCL is a heterogeneous programming framework that is managed by the nonprofit technology consortium the Khronos Group [3]. OpenCL is a framework for developing applications that execute across a range of device types made by different vendors. The first version of OpenCL, version 1.0, was released in 2008, and appeared in Apple’s Mac OSX Snow Leopard. AMD announced support for OpenCL in the same timeframe, and in 2009 IBM announced support for OpenCL in its XL compilers for the Power architecture. In 2010, the Khronos Group released version 1.1 of the OpenCL specification, and in 2011 released version 1.2. The first edition of this book covered many of the features introduced in OpenCL 1.2. In 2013, the Khronos Group released OpenCL 2.0, which includes the following features:
• Shared virtual memory
• Pipe memory objects
• C11 atomics
• Improved images
• Additional features
OpenCL supports multiple levels of parallelism and efficiently maps to homogeneous or heterogeneous, single- or multiple-device systems consisting of CPUs, GPUs, and other types of devices limited only by the imagination of vendors. OpenCL defines both a device-side language and a host management layer for the devices in a system. The device-side language is designed to efficiently map to a wide range of memory systems and execution models. The host language aims to support efficient plumbing for complicated concurrent programs with low overhead. Together, these provide the developer with a path to efficiently move from algorithm design to implementation.
OpenCL provides parallel computing using task-based and data-based parallelism. OpenCL kernels employ a SPMD-like model, where units of parallelism (called work-items) execute instances of the kernel in a way that maps effectively to both scalar and vector hardware. Support for OpenCL is rapidly expanding as a wide range of platform vendors have adopted OpenCL for their hardware. These vendors represent broad market segments, from mobile and embedded (ARM, Imagination, MediaTek, Texas Instruments) to desktop and high-performance computing (AMD, Apple, Intel, NVIDIA, and IBM). The architectures supported include multicore CPUs (including x86, ARM, and Power), throughput and vector processors such as GPUs, and fine-grained parallel devices such as field-programmable gate arrays (Altera, Xilinx). Most importantly, OpenCL’s cross-platform, industry-wide support makes it an excellent programming model for developers to learn and use, with the confidence that it will continue to be widely available for years to come with ever-increasing scope and applicability.
OpenCL 2.0 provides support for shared virtual memory, a topic we will treat in depth later in this book. Shared virtual memory is an important feature to ease programmer burden, especially when one is working with APU devices that share a common physical memory system. OpenCL 2.0 also introduces new memory consistency support, providing acquire/release semantics to relieve the programmer from fiddling with error-prone explicit locking. Support for shared memory communication, pipes, and other features of OpenCL 2.0 will be described in more detail in later chapters.
1.9 Book Structure
This book is organized as follows:
• Chapter 1 (this chapter) introduces many concepts related to the development of parallel algorithms and software. The chapter covers concurrency, threads, and different grains of parallelism: many of the fundamentals of parallel software development.
• Chapter 2 presents some of the architectures that support OpenCL, including CPUs, GPUs, and APUs. Different styles of architectures, including SIMD and very long instruction word, are discussed. This chapter also covers the concepts of multicore and throughput-oriented systems, as well as advances in heterogeneous architectures.
• Chapter 3 presents an introduction to OpenCL, including the host API and the OpenCL C language. The chapter includes a look into programming your first OpenCL application.
• Chapter 4 dives into OpenCL programming examples, including histogram, image rotation, and convolution, and demonstrates some of the OpenCL 2.0 features, such as pipe memory objects. An example in this chapter also utilizes OpenCL’s C++ wrapper.
• Chapter 5 discusses concurrency and execution in the OpenCL programming model. In this chapter we discuss kernels, work-items, and the OpenCL execution and memory hierarchies. We also show how queuing and synchronization work in OpenCL such that the reader gains an understanding of how to write OpenCL programs that interact with memory correctly.
• Chapter 6 covers the OpenCL host-side memory model, including resource and memory management.
• Chapter 7 continues with OpenCL’s device-side memory model. The device-side memory model deals with how units of execution access data in the various memory spaces. This chapter also includes updates to OpenCL’s consistency model, including memory ordering and scope.
• Chapter 8 dissects OpenCL on three very different heterogeneous platforms: (1) the AMD FX-8350 GPU, (2) the AMD Radeon R9 290X GPU, and (3) the AMD A10-7850K APU. This chapter also considers memory optimizations.
• Chapter 9 provides a case study, looking at imaging clustering and search.
• Chapter 10 considers OpenCL profiling and debugging using AMD CodeXL.
• Chapter 11 covers C++AMP, a version of C++ that allows the user to leverage the availability of parallel hardware.
• Chapter 12 discusses WebCL, enabling Web-based applications to harness the power of an OpenCL device from within a browser.
• Chapter 13 discusses how OpenCL can be accessed from within other languages such as Java, Python and Haskell.