
Introduction
In this book, we bring together the essentials to high performance programming for a Intel® Xeon Phi™ coprocessor. As we’ll see, programming for the Intel Xeon Phi coprocessors is mostly about programming in the same way as you would for an Intel® Xeon® processor-based system, but with extra attention on exploiting lots of parallelism. This extra attention pays off for processor-based systems as well. You’ll see this “Double Advantage of Transforming-and-Tuning” to be a key aspect of why programming for the Intel Xeon Phi coprocessor is particularly rewarding and helps protect investments in programming.
The Intel Xeon Phi coprocessor is both generally programmable and tailored to tackle highly parallel problems. As such, it is ready to consume very demanding parallel applications. We explain how to make sure your application is constructed to take advantage of such a large parallel capability. As a natural side effect, these techniques generally improve performance on less parallel machines and prepare applications better for computers of the future as well. The overall concept can be thought of as “Portable High Performance Programming.”
Sports cars are not designed for a superior experience driving around on slow-moving congested highways. As we’ll see, the similarities between an Intel Xeon Phi coprocessor and a sports car will give us opportunities to mention sports cars a few more times in the next few chapters.

Sports Car in Two Situations: Left in Traffic, Right on Race Course.
Trend: more parallelism
To squeeze more performance out of new designs, computer designers rely on the strategy of adding more transistors to do multiple things at once. This represents a shift away from relying on higher speeds, which demanded higher power consumption, to a more power-efficient parallel approach. Hardware performance derived from parallel hardware is more disruptive for software design than speeding up the hardware because it benefits parallel applications to the exclusion of nonparallel programs.
It is interesting to look at a few graphs that quantify the factors behind this trend. Figure 1.1 shows the end of the “era of higher processor speeds,” which gives way to the “era of higher processor parallelism” shown by the trends graphed in Figures 1.2 and 1.3. This switch is possible because, while both eras required a steady rise in the number of transistors available for a computer design, trends in transistor density continue to follow Moore’s law as shown in Figure 1.4. A continued rise in transistor density will continue to drive more parallelism in computer design and result in more performance for programs that can consume it.
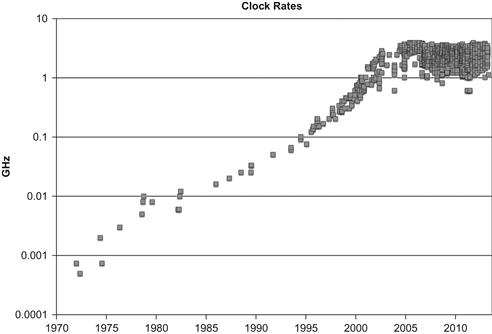
Figure 1.1 Processor/Coprocessor Speed Era [Log Scale].
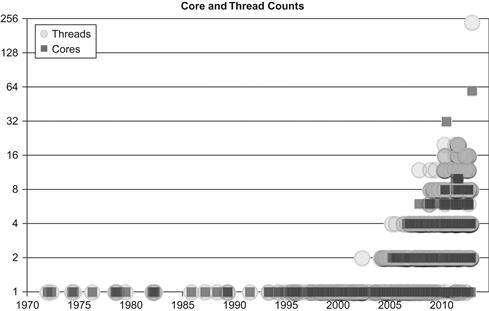
Figure 1.2 Processor/Coprocessor Core/Thread Parallelism [Log Scale].

Figure 1.3 Processor/Coprocessor Vector Parallelism [Log Scale].
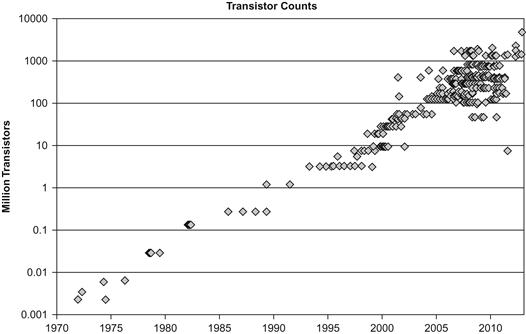
Figure 1.4 Moore’s Law Continues, Processor/Coprocessor Transistor Count [Log Scale].
Why Intel® Xeon Phi™ coprocessors are needed
Intel Xeon Phi coprocessors are designed to extend the reach of applications that have demonstrated the ability to fully utilize the scaling capabilities of Intel Xeon processor-based systems and fully exploit available processor vector capabilities or memory bandwidth. For such applications, the Intel Xeon Phi coprocessors offer additional power-efficient scaling, vector support, and local memory bandwidth, while maintaining the programmability and support associated with Intel Xeon processors.
Most applications in the world have not been structured to exploit parallelism. This leaves a wealth of capabilities untapped on nearly every computer system. Such applications can be extended in performance by a highly parallel device only when the application expresses a need for parallelism through parallel programming.
Advice for successful parallel programming can be summarized as “Program with lots of threads that use vectors with your preferred programming languages and parallelism models.” Since most applications have not yet been structured to take advantage of the full magnitude of parallelism available in any processor, understanding how to restructure to expose more parallelism is critically important to enable the best performance for Intel Xeon processors or Intel Xeon Phi coprocessors. This restructuring itself will generally yield benefits on most general-purpose computing systems, a bonus due to the emphasis on common programming languages, models, and tools across the processors and coprocessors. We refer to this bonus as the dual-transforming-tuning advantage.
It has been said that a single picture can speak a thousand words; for understanding Intel Xeon Phi coprocessors (or any highly parallel device) it is Figure 1.5 that speaks a thousand words. We should not dwell on the exact numbers as they are based on some models that may be as typical as applications can be. The picture speaks to this principle: Intel Xeon Phi coprocessors offer the ability to make a system that can potentially offer exceptional performance while still being buildable and power efficient. Intel Xeon processors deliver performance much more readily for a broad range of applications but do reach a practical limit on peak performance as indicated by the end of the line in Figure 1.5. The key is “ready to use parallelism.” Note from the picture that more parallelism is needed to make the Intel Xeon Phi coprocessor reach the same performance level, and that requires programming adapted to deliver that higher level of parallelism required. In exchange for the programming investment, we may reach otherwise unobtainable performance. The transforming-and-tuning double advantage of these Intel products is that the use of the same parallel programming models, programming languages, and familiar tools to greatly enhance preservation of programming investments. We’ll revisit this picture later.
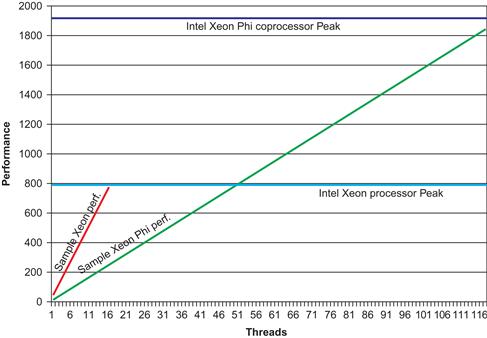
Figure 1.5 This Picture Speaks a Thousand Words.
Platforms with coprocessors
A typical platform is diagrammed in Figure 1.6. Multiple such platforms may be interconnected to form a cluster or supercomputer. A platform cannot consist of only coprocessors. Processors are cache coherent and share access to main memory with other processors. Coprocessors are cache-coherent SMP-on-a-chip1 devices that connect to other devices via the PCIe bus, and are not hardware cache coherent with other processors or coprocessors in the node or the system.

Figure 1.6 Processors and Coprocessors in a Platform Together.
The Intel Xeon Phi coprocessor runs Linux. It really is an x86 SMP-on-a-chip running Linux. Every card has its own IP address. We logged onto one of our pre-production systems in a terminal window. We first got a shell on the host (an Intel Xeon processor), and then we did “ssh mic0”, which logged me into the first coprocessor card in the system. Once we had this window, we listed /proc/cpuinfo. The result is 6100 lines long, so we’re showing the first 5 and last 26 lines in Figure 1.7.

Figure 1.7 Preproduction Intel® Xeon Phi™ Coprocessor “cat /proc/cpuinfo”.
In some ways, for me, this really makes the Intel Xeon Phi coprocessor feel very familiar. From this window, we can “ssh” to the world. We can run “emacs” (you can run “vi” if that is your thing). We can run “awk” scripts or “perl.” We can start up an MPI program to run across the cores of this card, or to connect with any other computer in the world.
If you are wondering how many cores are in an Intel Xeon Phi coprocessor, the answer is “it depends.” It turns out there are, and will be, a variety of configurations available from Intel, all with more than 50 cores. Preserving programming investments is greatly enhanced by the transforming-and-tuning double advantage. For years, we have been able to buy processors in a variety of clock speeds. More recently, an additional variation in offerings is based on the number of cores. The results in Figure 1.7 are from a 61-core pre-production Intel Xeon Phi coprocessor that is a precursor to the production parts known as an Intel Xeon Phi coprocessor SE10x. It reports a processor number 243 because the threads are enumerated 0..243 meaning there are 244 threads (61 cores times 4 threads per core).
The first Intel® Xeon Phi™ coprocessor
The first Intel® Xeon Phi™ coprocessor was known by the code name Knights Corner early in development. While programming does not require deep knowledge of the implementation of the device, it is definitely useful to know some attributes of the coprocessor. From a programming standpoint, treating it as an x86-based SMP-on-a-chip with over fifty cores, with multiple hardware threads per core, and 512-bit SIMD instructions, is the key. It is not critical to completely absorb everything else in this part of the chapter, including the microarchitectural diagrams in Figures 1.8 and 1.9 that we chose to include for those who enjoy such things as we do.
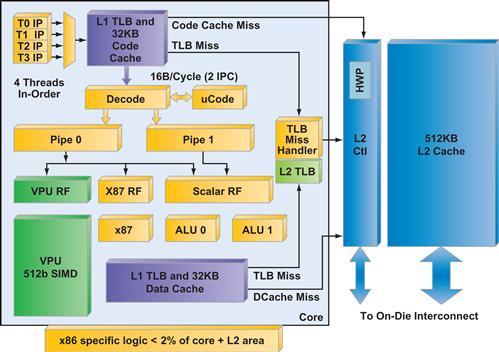
Figure 1.8 Architecture of a Single Intel® Xeon Phi™ Coprocessor Core.
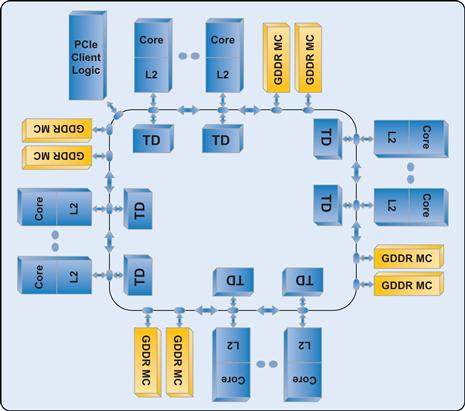
Figure 1.9 Microarchitecture of the Entire Coprocessor.
The cores are in-order dual issue x86 processor cores, which trace some history to the original Pentium® design, but with the addition of 64-bit support, four hardware threads per core, power management, ring interconnect support, 512-bit SIMD capabilities, and other enhancements, these are hardly the Pentium cores of 20 years ago. The x86-specific logic (excluding L2 caches) makes up less than 2 percent of the die area for an Intel Xeon Phi coprocessor.
Here are key facts about the first Intel Xeon Phi coprocessor product:
• A coprocessor (requires at least one processor in the system), in production in 2012.
• Runs Linux (source code available http://intel.com/software/mic).
• Manufactured using Intel’s 22 nm process technology with 3-D Trigate transistors.
• Supported by standard tools including Intel® Parallel Studio XE 2013. A list of additional tools available can be found online (http://intel.com/software/mic).
– More than 50 cores (it will vary within a generation of products, and between generations; it is good advice to avoid hard-coding applications to a particular number).
– In-order cores support 64-bit x86 instructions with uniquely wide SIMD capabilities.
– Four hardware threads on each core (resulting in more than 200 hardware threads available on a single device) are primarily used to hide latencies implicit in an in-order microarchitecture. In practice, use of at least two threads per core is nearly always beneficial. As such, it is much more important that applications use these multiple hardware threads on Intel Xeon Phi coprocessors than they use hyper-threads on Intel Xeon processors.
– Cores interconnected by a high-speed bidirectional ring.
– Cores clocked at 1 GHz or more.
– Cache coherent across the entire coprocessor.
– Each core has a 512-KB L2 cache locally with high-speed access to all other L2 caches (making the collective L2 cache size over 25 MB).
– Caches deliver highly efficient power utilization while offering high bandwidth memory.
• Special instructions in addition to 64-bit x86:
– Uniquely wide SIMD capability via 512-bit wide vectors instead of the narrower MMX™, Intel® SSE, or Intel® AVX capabilities.
– High performance support for reciprocal, square root, power, and exponent operations.
– Scatter/gather and streaming store capabilities to achieve higher effective memory bandwidth.
– On package memory controller supports up to 8 GB GDDR5 (varies based on part).
– PCIe connect logic is on-chip.
– Power management capabilities.
– Performance monitoring capabilities for tools like Intel VTune™ Amplifier XE 2013.
Keeping the “Ninja Gap” under control
On the premise that parallel programming can require Ninja (expert) programmers, the gaps in knowledge and experience needed between expert programmers and the rest of us have been referred to as the “ninja gap.” Optimization for performance is never easy on any machine, but it is possible to control the level of complexity to manageable levels to avoid a high ninja gap. To understand more about how this ninja gap can be quantified, you might read “Can Traditional Programming Bridge the Ninja Performance Gap for Parallel Computing Applications?” (Satish et al. 2012). The paper shares measurements of the challenges and shows how Intel Xeon Phi coprocessors offer the advantage of controlling the ninja gap to levels akin to general-purpose processors. This approach is able to rely on the same industry standard methods as general-purpose processors and the paper helps show how that benefit can be measured and shown to be similar to general-purpose processors.
Transforming-and-tuning double advantage
Programming should not be called easy, and neither should parallel programming. We can however, work to keep the fundamentals the same: maximizing parallel computations and minimizing data movement. Parallel computations are enabled through scaling (more cores and threads) and vector processing (more data processed at once). Minimal data movement is an algorithmic endeavor, but can be eased through the higher bandwidth between memory and cores that is available with the Intel Many Integrated Core (MIC) Architecture that is used by Intel Xeon Phi coprocessors. This leads to parallel programming using the same programming languages and models across Intel products, which are generally also shared across all general-purpose processors in the industry. Languages such Fortran, C, and C++ are fully supported. Popular programming models such as OpenMP, MPI, and Intel TBB are fully supported. Newer models with widespread support such as Coarray Fortran, Intel Cilk™ Plus and OpenCL can apply as well.
Tuning on Intel Xeon Phi coprocessors, for scaling, vector usage, and memory usage, all stand to also benefit an application when run on Intel Xeon processors. This protection of investment by maintaining a value across processors and coprocessor is critical for helping preserve past and future investments. Applications that initially fail to get maximum performance on Intel Xeon Phi coprocessors generally trace problems back to scaling, vector usage, or memory usage. When these issues are addressed, these improvements to an application usually have a related positive effect when run on Intel Xeon processors. Some people call this the double advantage of “transforming-and-tuning,” as shown in Figure 1.10, and have found it to be among the most compelling features of the Intel Xeon Phi coprocessors.
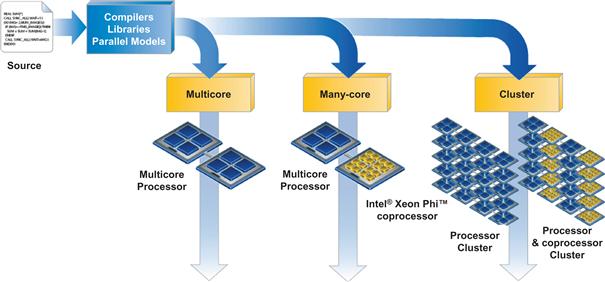
Figure 1.10 Double Advantage of Transforming-and-Tuning.
When to use an Intel® Xeon Phi™ coprocessor
Applications can use both Intel Xeon processors and Intel Xeon Phi coprocessors to simultaneously contribute to application performance. Applications should utilize a coprocessor for processing when it can contribute to the performance of a node. Generally speaking that will be during the portions of an application that can exploit high degrees of parallelism. For some workloads, the coprocessor(s) may contribute significantly more performance than the processor(s) while on others it may be less. System designs that include Intel Xeon Phi coprocessor(s) extend the range of node performance beyond what is possible with processors only. Because of the sophisticated power management in both Intel Xeon processors and Intel Xeon Phi coprocessors, the power efficiency of a node can be maintained across a broad range of applications by consuming power only when needed to contribute to node performance.
Maximizing performance on processors first
We have often seen that the single most important lesson from working with Intel Xeon Phi coprocessors is this: the best way to prepare for Intel Xeon Phi coprocessors is to fully exploit the performance that an application can get on Intel Xeon processors first. Trying to use an Intel Xeon Phi coprocessor without having maximized the use of parallelism on Intel Xeon processor will almost certainly be a disappointment.
Figure 1.11 illustrates a key point: higher performance comes from pairing parallel software with parallel hardware because it takes parallel applications to access the potential of parallel hardware. Intel Xeon Phi coprocessors offer a corollary to this: higher performance comes from pairing highly parallel software with highly parallel hardware. The best place to start is to make sure your application is maximizing the capabilities of an Intel Xeon processor.

Figure 1.11 High Performance Comes from Parallel Software+Parallel Hardware.
Why scaling past one hundred threads is so important
In getting an application ready for utilizing an Intel Xeon Phi coprocessor, nothing is more important than scaling. An application must scale well past one hundred threads to qualify as highly parallel. Efficient use of vectors and/or memory bandwidth is also essential. Applications that have not been created or modified to utilize high degrees of parallelism (task, threads, vectors, and so on) will be more limited in the benefit they derive from hardware that is designed to offer high degrees of parallelism.
Figures 1.12 and 1.13 show examples of how application types can behave on Intel Xeon processors versus Intel Xeon Phi coprocessors in two key cases: computationally bound and memory bound applications. Note that a logarithmic scale is employed in the graph, therefore the performance bars at the bottom represent substantial gains over bars above; results will vary by application. Measuring the current usage of vectors, threads, and aggregate bandwidth by an application can help understand where an application stands in being ready for highly parallel hardware. Notice that “more parallel” enhances both the processor and coprocessor performance. A push for “more parallel” applications will benefit Intel Xeon processors and Intel Xeon Phi coprocessors because both are general-purpose programmable devices.
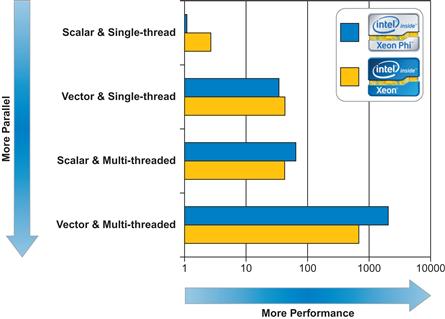
Figure 1.12 Combining Threads and Vectors Works Best. Coprocessors Extend.

Figure 1.13 High Memory Needs Can Benefit From Threading. Coprocessors Extend.
Thinking back to the picture that speaks a thousand words, Figures 1.14, 1.15, and 1.16 offer a view to illustrate the same need for constructing to use lots of threads and vectors. Figure 1.14 illustrates model data to make a point: Intel Xeon Phi coprocessors can reach heights in beyond performance that of an Intel Xeon processor, but it requires more parallelism to do so. Figures 1.15 and 1.16 are simply close-ups of parts of Figure 1.14 to make a couple of points. Figure 1.15 illustrates the universal need for more parallelism to reach the same performance level on a device optimized for high degrees of parallelism (in this case, an Intel Xeon Phi coprocessor). Figure 1.16 illustrates that limiting “highly parallel” to the levels of parallelism that peak an Intel Xeon processor are insufficient to be interesting on an Intel Xeon Phi coprocessor. These close-up looks drive home the point of Figure 1.14: to go faster, you need more parallelism, while adding the less obvious “to go the same speed, you need more parallelism.”
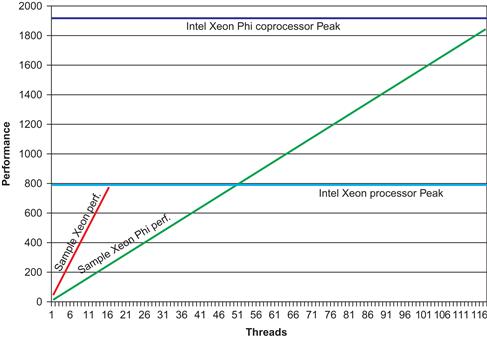
Figure 1.14 The Potential is Higher, But So is the Parallelism Needed to Get There.

Figure 1.15 Within the Range of a Processor, the Processor Needs Fewer Threads.
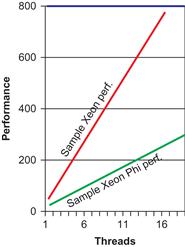
Figure 1.16 Limiting Threads Is Not Highly Parallel.
Maximizing parallel program performance
Whether making a choice to run an application on Intel Xeon processors or Intel Xeon Phi coprocessors, we can start with two fundamental considerations to achieve high performance:
1. Scaling: Is the scaling of an application ready to utilize the highly parallel capabilities of an Intel Xeon Phi coprocessor? The strongest evidence of this is generally demonstrated scaling on Intel Xeon processors.
2. Vectorization and memory usage: Is the application either:
a. Making strong use of vector units?
b. Able to utilize more local memory bandwidth than available with Intel Xeon processors?
If these two fundamentals (both #1 and #2) are true for an application, then the highly parallel and power-efficient Intel Xeon Phi coprocessor is most likely to be worth evaluating.
Measuring readiness for highly parallel execution
To know if your application is maximized on an Intel Xeon processor-based system, you should examine how your application scales, uses vectors, and uses memory. Assuming you have a working application, you can get some impression of where you are with regards to scaling and vectorization by doing a few simple tests.
To check scaling, create a simple graph of performance as you run with various numbers of threads (from one up to the number of cores, with attention to thread affinity) on an Intel Xeon processor-based system. This can be done with settings for OpenMP, Intel® Threading Building Blocks (Intel TBB) or Intel Cilk Plus (for example, OMP_NUM_THREADS for OpenMP). If the performance graph indicates any significant trailing off of performance, you have tuning work you can do to improve your application scaling before trying an Intel Xeon Phi coprocessor.
To check vectorization, compile your application with and without vectorization. For instance, if you are using Intel compilers auto-vectorization: disable vectorization via compiler switches: -no-vec -no-simd, use at least –O2 -xhost for vectorization. Compare the performance you see. If the performance difference is insufficient you should examine opportunities to increase vectorization. Look again at the dramatic benefits vectorization may offer as illustrated in Figure 1.13. If you are using libraries, like the Intel Math Kernel Library (Intel MKL), you should consider that math routines would remain vectorized no matter how you compile the application itself. Therefore, time spent in the math routines may be considered as vector time. Unless your application is bandwidth limited, the most effective use of Intel Xeon Phi coprocessors will be when most cycles executing are vector instructions2. While some may tell you that “most cycles” needs to be over 90 percent, we have found this number to vary widely based on the application and whether the Intel Xeon Phi coprocessor needs to be the top performance source in a node or just needs to contribute performance.
Intel VTune Amplifier XE 2013 can help measure computations on Intel Xeon processors and Intel Xeon Phi coprocessors to assist in your evaluations.
Aside from vectorization, being limited by memory bandwidth on Intel Xeon processors can indicate an opportunity to improve performance with an Intel Xeon Phi coprocessor. For this to be most efficient, an application needs to exhibit good locality of reference and must utilize caches well in its core computations.
The Intel VTune Amplifier XE product can be utilized to measure various aspects of a program, and among the most critical is L1 compute density. This is greatly expanded upon in a paper titled “Optimization and Performance Tuning for Intel® Xeon Phi™ Coprocessors, Part 2: Understanding and Using Hardware Events” (Intel 2012) available at http://tinyurl.com/phicount.
When using MPI, it is desirable to see a communication versus computation ratio that is not excessively high in terms of communication. The ratio of computation to communication will be a key factor in deciding between using offload versus native model for programming for an application. Programs are also most effective using a strategy of overlapping communication and I/O with computation. Intel® Trace Analyzer and Collector, part of Intel® Cluster Studio XE 2013, is very useful for profiling MPI communications to help visualize bottlenecks and understand the effectiveness of overlapping with computation.
What about GPUs?
While GPUs cannot offer the programmability of an Intel Xeon Phi coprocessor, they do share a subset of what can be accelerated by scaling combined with vectorization or bandwidth. In other words, applications that show positive results with GPUs should always benefit from Intel Xeon Phi coprocessors because the same fundamentals of vectorization or bandwidth must be present. The opposite is not true. The flexibility of an Intel Xeon Phi coprocessor includes support for applications that cannot run on GPUs. This is one reason that a system built including Intel Xeon Phi coprocessors will have broader applicability than a system using GPUs. Additionally, tuning for GPU is generally too different from a processor to have the dual-transforming-tuning benefit we see in programming for Intel Xeon Phi coprocessors. This can lead to a substantial rise in investments to be portable across many machines now and into the future.
Beyond the ease of porting to increased performance
Because an Intel Xeon Phi coprocessor is an x86 SMP-on-a-chip, it is true that a port to an Intel Xeon Phi coprocessor is often trivial. However, the high degree of parallelism of Intel Xeon Phi coprocessors are best suited to applications that are structured to use the parallelism. Almost all applications will benefit from some tuning beyond the initial base performance to achieve maximum performance. This can range from minor work to major restructuring to expose and exploit parallelism through multiple tasks and use of vectors. The experiences of users of Intel Xeon Phi coprocessors and the “forgiving nature” of this approach are generally promising but point out one challenge: the temptation to stop tuning before the best performance is reached. This can be a good thing if the return on investment of further tuning is insufficient and the results are good enough. It can be a bad thing if expectations were that working code would always be high performance. There ain’t no such thing as a free lunch! The hidden bonus is the “transforming-and-tuning” double advantage of programming investments for Intel Xeon Phi coprocessors that generally applies directly to any general-purpose processor as well. This greatly enhances the preservation of any investment to tune working code by applying to other processors and offering more forward scaling to future systems.
Transformation for performance
There are a number of possible user-level optimizations that have been found effective for ultimate performance. These advanced techniques are not essential. They are possible ways to extract additional performance for your application. The “forgiving nature” of the Intel Xeon Phi coprocessor makes transformations optional but should be kept in mind when looking for the highest performance. It is unlikely that peak performance will be achieved without considering some of these optimizations:
• Memory access and loop transformations (for example: cache blocking, loop unrolling, prefetching, tiling, loop interchange, alignment, affinity)
• Vectorization works best on unit-stride vectors (the data being consumed is contiguous in memory). Data structure transformations can increase the amount of data accessed with unit-strides (such as AoS3 to SoA4 transformations or recoding to use packed arrays instead of indirect accesses).
• Use of full (not partial) vectors is best, and data transformations to accomplish this should be considered.
• Vectorization is best with properly aligned data.
• Large page considerations (we recommend the widely used Linux libhugetlbfs library)
• Algorithm selection (change) to favor those that are parallelization and vectorization friendly.
Hyper-threading versus multithreading
The Intel Xeon Phi coprocessor utilizes multithreading on each core as a key to masking the latencies inherent in an in-order microarchitecture. This should not be confused with hyper-threading on Intel Xeon processors that exists primarily to more fully feed a dynamic execution engine. In HPC workloads, very often hyper-threading may be ignored or even turned off without degrading effects on performance. This is not true of Intel Xeon Phi coprocessor hardware threads, where multithreading of programs should not be ignored and hardware threads cannot be turned off.
The Intel Xeon Phi coprocessor offers four hardware threads per core with sufficient memory capabilities and floating-point capabilities to make it generally impossible for a single thread per core to approach either limit. Highly tuned kernels of code may reach saturation with two threads, but generally applications need a minimum of three or four active threads per core to access all that the coprocessor can offer. For this reason, the number of threads per core utilized should be a tunable parameter in an application and be set based on experience in running the application. This characteristic of programming for Intel products will continue into the future, even though the “hyper-threading versus hardware threading” and the number of hardware threads may vary. Programs should parameterize the number of cores and the number of threads per core in order to easily run well on a variety of current and future processors and coprocessors.
Coprocessor major usage model: MPI versus offload
Given that we know how to program the Intel Xeon processors in the host system, the question that arises is how to involve the Intel Xeon Phi coprocessors in an application. There are two major approaches:
1. A processor-centric “offload” model where the program is viewed as running on processors and offloading select work to coprocessors.
2. A “native” model where the program runs natively on processors and coprocessors and may communicate with each other by various methods.
The choice between offload and native models is certain to be one of considerable debate for years to come. Applications that already utilize MPI can actually use either method by either limiting MPI ranks to Intel Xeon processors and use offload to the coprocessors, or distribute MPI ranks across the coprocessors natively. It is possible that the only real MPI ranks be established on the coprocessor cores, but if this leaves the Intel Xeon processors unutilized then this approach is likely to give up too much performance in the system.
Being separate and on a PCIe bus creates two additional considerations. One is the need to fit problems or subproblems into the more limited memory on the coprocessor card, and the other is the overhead of data transfers that favor minimization of communication to and from the card. It is worth noting also that the number of MPI ranks used on an Intel Xeon Phi coprocessor should be substantially fewer than the number of cores in no small part because of limited memory on the coprocessor. Consistent with parallel programs in general, the advantages of overlapping communication (MPI messages or offload data movement) with computation are important to consider as well as techniques to load-balance work across all the cores available. Of course, involving Intel Xeon processor cores and Intel Xeon Phi coprocessor cores adds the dimension of “big cores” and “little cores” to the balancing work even though they share x86 instructions and programming models. While MPI programs often already tackle the overlap of communication and computation, the placement of ranks on coprocessor cores still have to deal with the highly parallel programming needs and limited memory. This is why an offload model can be attractive, even within an MPI program where ranks are on the processors.
The offload model for Intel Xeon Phi coprocessors is quite rich. The syntax and semantics of the Intel Language Extensions for Offload are generally a superset of other offload models including nVidia’s OpenACC. This provides for greater interoperability with OpenMP, ability to manage multiple coprocessors (cards), and the ability to offload complex program components that an Intel Xeon Phi coprocessor can process but that a GPU could not (hence nVidia’s OpenACC does not allow). We expect that OpenMP 4.0 (standard to be finalized in 2013) will include offload directives that provide support for these needs, and Intel supports the draft (TR1) from OpenMP and plans to support OpenMP 4.0 after it is finalized. Intel Xeon Phi coprocessors as part of our commitment to providing OpenMP capabilities. Intel Language Extensions for Offload also provides for an implicit sharing model that is beyond what OpenMP 4.0 will support. It rests on a shared memory model supported by Intel Xeon Phi coprocessors that allow a shared memory-programming model (Intel calls “MYO”) between Intel Xeon processors and Intel Xeon Phi coprocessors. This bears some similarity to PGAS (partitioned global address space) programming models and is not an extension provided by OpenMP 4.0. The Intel “MYO” capability offers a global address space within the node allowing sharing of virtual addresses, for select data, between processors and coprocessor on the same node. It is offered in C and C++, but not Fortran since future support of Coarray will be a standard solution to the same basic problem. Offloading is available as Fortran offloading via pragmas, C/C++ offloading with pragmas and optionally shared (MYO) data. Use of MPI can distribute applications across the system as well.
Compiler and programming models
No popular programming language was designed for parallelism. In many ways, Fortran has done the best job adding new features, such as DO CONCURRENT, to address parallel programming needs as well as benefiting from OpenMP. C users have OpenMP as well as Intel Cilk Plus. C++ users have embraced Intel Threading Building Blocks and more recently have Intel Cilk Plus to utilize as well. C++ users can use OpenMP as well.
Intel Xeon Phi coprocessors offer the full capability to use the same tools, programming languages and programming models as an Intel Xeon processor. However, as a coprocessor designed for high degrees of parallelism, some models are more interesting than others.
In a way, it is quite simple: an application needs to deal with having lots of tasks, and deal with vector data efficiently (also known as vectorization).
There are some recommendations we can make based on what has been working well for developers. For Fortran programmers, use OpenMP, DO CONCURRENT, and MPI. For C++ programmers, use Intel TBB, Intel Cilk Plus, and OpenMP. For C programmers, use OpenMP and Intel Cilk Plus. Intel TBB is a C++ template library that offers excellent support for task oriented load balancing. While Intel TBB does not offer vectorization solutions, it does not interfere with any choice of solution for vectorization. Intel TBB is open source and available on a wide variety of platforms supporting most operating systems and processors. Intel Cilk Plus is a bit more complex in that it offers both tasking and vectorization solutions. Fortunately, Intel Cilk Plus fully interoperates with Intel TBB. Intel Cilk Plus offers a simpler set of tasking capabilities than Intel TBB but by using keywords in the language so as to have full compiler support for optimizing.
Intel Cilk Plus also offers elemental functions, array syntax and “#pragma SIMD” to help with vectorization. Best use of array syntax is done along with blocking for caches, which unfortunately means naïve use of constructs such as A[:]=B[:]+C[:]; for large arrays may yield poor performance. Best use of array syntax ensures the vector length of single statements is short (some small multiple of the native vector length, perhaps only 1X). Finally, and perhaps most important to programmers today, Intel Cilk Plus offers mandatory vectorization pragmas for the compiler called “#pragma SIMD.” The intent of “#pragma SIMD” is to do for vectorization what OpenMP has done for parallelization. Intel Cilk Plus requires compiler support. It is currently available from Intel for Windows, Linux, and Apple OS X. It is also available in a branch of gcc.
If you are happy with OpenMP and MPI, you have a great start to using Intel Xeon Phi coprocessors. Additional options may be interesting to you over time, but OpenMP and MPI are enough to get great results when used with an effective vectorization method. Auto-vectorization may be enough for you especially if you code in Fortran with the possible additional considerations for efficient vectorization such as alignment and unit-stride accesses. The “#pragma SIMD” capability of Intel Cilk Plus (available in Fortran too) is worth a look. The SIMD pragmas/directives are expected to be part of OpenMP 4.0 (standard to be finalized in 2013).
Dealing with tasks means specification of task, and load balancing among them. MPI has provided this capability for decades with full flexibility and responsibility given to the programmer. Shared memory programmers have Intel TBB and Intel Cilk Plus to assist them. Intel TBB has widespread usage in the C++ community, and Intel Cilk Plus extends Intel TBB to offer C programmers a solution as well as help with vectorization in C and C++ programs.
Cache optimizations
The most effective use of caches comes by paying attention to maximizing the locality of references, blocking to fit in L2 cache, and ensuring that prefetching is utilized (by hardware, by compiler, by library or by explicit program controls).
Organizing data locality to fit 512 K or less L2 cache usage per core generally gives best usage of the L2 cache. All four hardware threads per core share their “per core” local L2 cache but have high-speed access to the caches associated with other cores. Any data used by a particular core will occupy space in that local L2 cache (it can be in multiple L2 caches around the chip). While Intel Xeon processors have a penalty for “cross-socket” sharing, which occurs after about 16 threads (assuming 8 cores, two hyper-threads each), the Intel Xeon Phi coprocessors have a lower penalty across more than 200 threads. There is a benefit to having locality first organized around the threads being used on a core (up to four) first, and then around all the threads across the coprocessor. While the defaults and automatic behavior can be quite good, ensuring that code designed for locality performs best will likely include programmatic specification of affinity such as the use of KMP_AFFINITY when using OpenMP and I_MPI_PIN_DOMAIN with MPI. Note that while there is a strong benefit to sharing for threads on the same core, beyond that you should not expect to see performance variations based on how close a core is to another core on coprocessor. While this may seem surprising, the hardware design is so good in this respect we have yet to see any appreciable performance benefit based on adjacency of cores within the coprocessor so I would not advise spending time trying to optimize placement beyond locality to a core and then load balancing across the cores (for instance using KMP_AFFINITY=scatter to round-robin work allocation).
The coprocessor has hardware prefetching into L2 that is initiated by the first cache miss within a page. The Intel compilers issue software prefetches aggressively for memory references inside loops by default (-O2 and above, report on compiler decisions available with -opt-report3 -opt-report-phase hlo). Typically, the compiler issues two prefetches per memory reference: one from memory into L2 and a second one for prefetching from L2 into L1. The prefetch distance is computed by the compiler based on the amount of work inside the loop. Explicit prefetching can be added either with prefetch pragmas (#pragma prefetch in C/C++ or CDEC$ prefetch in Fortran) or prefetch intrinsics (_mm_prefetch in C/C++, or mm_prefetch in Fortran); you may want to explicitly turn off compiler prefetching (-opt-prefetch=0 to turn off all compiler prefetches or -opt-prefetch-distance=0,2 to turn off compiler prefetches into L2) when you are adding prefetch intrinsics manually. Software prefetches do not get counted as cache misses by the performance counters. This means that “cache misses” can truly be studied with performance tools with a goal of driving them to essentially zero (aim for low single-digit percentages of memory accesses counted as misses) inside loops when you can successfully fetch all data streams with prefetches. Prefetching needs to be from memory to L2 and separately from L2 to L1. Utilizing prefetches from memory to L1 directly should not be expected to yield great performance because the latency of such will generally lead to more outstanding L1 prefetches than are available in the hardware. Such limits mean that organizing data streams is best when the number of streams of data per thread is less than eight and prefetching is actively used on each stream of data. As a rule of thumb, the number of active prefetches per core should be managed to about 30 or 40 and be divided across the active data streams.
Beyond the caches, certain memory transforms can be employed for additional tuning for TLBs including the ability to use large or small pages, organizing data streams, and to organizing data to avoid hot spots in the TLBs.
Examples, then details
We use the next three chapters to dive into a number of instructive examples in order to learn the essentials of high performance parallel programming. We’ll ponder the similarities between an Intel Xeon Phi coprocessor and a sports car. In this chapter, we made the case that a sports car is not designed for a superior experience driving around on slow-moving congested highways. In the next few chapters, we’ll move the sports car to more favorable roads where the opportunity is there to open up the performance. In this way, the information in this chapter, combined with that in the subsequent three chapters, is sufficient to learn the programming. The remaining chapters of this book provide more in-depth explanation of many details these first four chapters have only touched upon. Documentation and additional information is also available at http://intel.com/software/mic.
For more information
Some additional reading worth considering includes:
• “Optimization and Performance Tuning for Intel® Xeon Phi™ Coprocessors, Part 2: Understanding and Using Hardware Events” (Intel 2012) available at http://tinyurl.com/phicount.
• “An Overview of Programming for Intel® Xeon® processors and Intel® Xeon Phi™ coprocessors” (Intel 2012) available at http://tinyurl.com/xeonphisum.
• Satish, N., C. Kim, J. Chhugani, H. Saito, R. Krishnaiyer, M. Smelyanskiy, M. Girkar, and P. Dubey. “Can traditional programming bridge the Ninja performance gap for parallel computing applications?” Computer Architecture (ISCA), 2012 39th Annual International Symposium on, vol. no. 9–13 June 2012, pp. 440–451.
• Documentation and additional information is also available at http://intel.com/software/mic.