


GDPS/Global Mirror
In this chapter we discuss the capabilities and prerequisites of the GDPS/Global Mirror (GM) offering.
The GDPS/GM offering provides a disaster recovery capability for businesses that have an RTO of as little as two hours or less, and an RPO as low as five seconds. It will typically be deployed in configurations where the application and recovery sites are more than 200 km apart and want to have integrated remote copy processing for mainframe and non-mainframe data.
The functions provided by GDPS/GM fall into two categories:
•Protecting your data
– Protecting the integrity of the data on the secondary data in the event of a disaster or suspected disaster.
– Managing the remote copy environment through GDPS scripts and NetView panels or the web interface.
– Optionally supporting remote copy management and consistency of the secondary volumes for Fixed Block Architecture (FBA) data. Depending on your application requirements, the consistency of the FBA data can be coordinated with the CKD data.
•Controlling the disk resources managed by GDPS during normal operations, planned changes, and following a disaster
– Support for recovering the production environment following a disaster.
– Support for switching your data and systems to the recovery site.
– Support for testing recovery and restart using a practice FlashCopy point-in-time copy of the secondary data while live production continues to run in the application site and continues to be protected with the secondary copy.
6.1 Introduction to GDPS/Global Mirror
GDPS/GM is a disaster recovery solution. It is similar in various respects to GDPS/XRC in that it supports virtually unlimited distances. However, the underlying IBM Global Mirror (GM), remote copy technology also supports both System z CKD data and distributed data, and GDPS/GM also includes support for both.
GDPS/GM can be viewed as a mixture of GDPS/PPRC and GDPS/XRC. Just as PPRC (IBM Metro Mirror) is a disk subsystem-based remote copy technology, GM is also disk-based, meaning that it supports the same mix of CKD and FBA data that is supported by GDPS/PPRC. Also, being disk-based, there is no requirement for a System Data Mover (SDM) system to drive the remote copy process. Also, like PPRC, Global Mirror requires that the primary and secondary disk subsystems are from the same vendor.
Conversely, GDPS/GM resembles GDPS/XRC in that it is asynchronous and supports virtually unlimited distances between the application and recovery sites. Also, similar to GDPS/XRC, GDPS/GM does not provide any automation or management of the production systems. Instead, its focus is on managing the Global Mirror remote copy environment and automating and managing recovery of data and systems in case of a disaster. Like GDPS/XRC, GDPS/GM supports the ability to remote copy data from multiple systems and sysplexes. In contrast, each GDPS/PPRC installation supports remote copy for only a single sysplex.
The capabilities and features of GDPS/GM are described in this chapter.
6.1.1 Protecting data integrity
Because the role of GDPS/GM is to provide disaster recovery support, its highest priority is protecting the integrity of the data, CKD and/or FB, in the recovery site. This section discusses the support provided by GDPS for these various data types.
Traditional System z (CKD) data
As described in 2.4.3, “Global Mirror” on page 31, Global Mirror protects the integrity of the remote-copied data by creating consistency groups, either continuously, or at intervals specified by the installation. The whole process is managed by the Master disk subsystem, based on the GDPS/GM configuration. There are no restrictions relating to which operating systems’ data can be supported; any system that writes to CKD devices (z/OS, z/VM, z/VSE, and Linux for System z) is supported. Regardless of which systems are writing to the devices, all management control is from the z/OS system running the GDPS/GM local Controlling system, also known as the K-sys.
How frequently a consistency group can be created depends on the bandwidth provided between the application and recovery site disks; IBM can perform a bandwidth analysis for you to help you identify the required capacity.
GDPS/Global Mirror uses devices in the primary and secondary disk subsystems to execute the commands to manage the environment. Some of these commands directly address a primary device, whereas others are directed to the LSS. To execute these LSS-level commands, you must designate at least one volume in each primary LSS as a GDPS utility device, which is the device that serves as the “go between” between GDPS and the LSS. These utility devices do not need to be dedicated devices; that is, they can be one of the devices that are being mirrored as part of your Global Mirror session. In fact, the utility devices also need to be mirrored.
Global Mirror supports both CKD and FBA devices. If the CKD and FBA devices are in the same Global Mirror session, they will be in the same consistency group. This means that they must be recovered together, which also means that the systems that use these disks must also be recovered together.
Distributed (FBA) data
GDPS/GM supports remote copy of FBA or FB devices written by distributed systems (including SCSI-attached FB disks written by Linux for System z). If the FB devices are in the same Global Mirror session as the CKD devices that are being global mirrored, they will have the same consistency point. If they are in a different Global Mirror session than the CKD disks, they will have a different consistency point. That is, if CKD and FB disks are in different sessions, the data for each session will be consistent within itself, but the data for the two sessions will not be consistent with each other.
There are certain disk subsystem microcode requirements needed to enable GDPS/GM management of FB disks. Refer to “Open LUN (FB disk) management prerequisites” on page 215 for details.
The Distributed Cluster Management (DCM) capability of GDPS can be used to manage the nodes in distributed system clusters that use the replicated data. Refer to 8.3, “Distributed Cluster Management” on page 222 for more information about DCM.
6.2 GDPS/Global Mirror configuration
At its most basic, a GDPS/GM configuration consists of one or more production systems, an application site Controlling system (K-sys), a recovery site Controlling system (R-sys), primary disks, and two sets of disks in the recovery site.
The GM copy technology uses three sets of disks. 2.4.3, “Global Mirror” on page 31 contains an overview of how GM works and how the disks are used to provide data integrity.
The K-sys is responsible for controlling all remote copy operations and for sending configuration information to the R-sys. In normal operations, most operator and system programmer interaction with GDPS/GM would be through the K-sys. The K-sys role is simply related to remote copy; it does not provide any monitoring, automation, or management of systems in the application site, nor any FlashCopy support for application site disks. There is no requirement for the K-sys to be in the same sysplex as the system or systems it is managing data for. In fact, it is recommended that the K-sys be placed in a monoplex on its own.
You can also include the K-sys disks in the GDPS-managed GM configuration and replicate them if you want to. The K-sys does not have the isolation requirements of the Controlling system in a GDPS/PPRC configuration.
The R-sys is primarily responsible for validating the configuration, monitoring the GDPS-managed resources such as the disks in the recovery site, and carrying out all recovery actions either for test purposes or in the event of a real disaster. See 6.7, “Flexible testing” on page 168 for more information about testing using FlashCopy.
The K-sys and R-sys communicate information to each other using a NetView-to-NetView network communication mechanism over the wide area network (WAN).
K-sys and R-sys are dedicated to their roles as GDPS Controlling systems.
GDPS/GM can control multiple Global Mirror sessions. Each session can consist of a maximum of 17 disk subsystems (combination of primary and secondary). All the members of the same session will have the same consistency point. Typically the data for all systems that must be recovered together will be managed through one session. For example, a z/OS sysplex is an entity where the data for all systems in the sysplex need to be in the same consistency group. If you have two production sysplexes under GDPS/GM control, the data for each can be managed through a separate GM session, in which case they can be recovered individually. You can also manage the entire data for both sysplexes in a single GM session, in which case if one sysplex fails and you have to invoke recovery, you will need to also recover the other sysplex.
Information about which disks are to be mirrored as part of each session and the intervals at which a consistency point is to be created for each session is defined in the GDPS remote copy configuration definition file (GEOMPARM). GDPS/GM uses this information to control the remote copy configuration. Like the other GDPS offerings, the NetView panel interface (or the web interface) is used as the operator interface to GDPS.
Although the panel interface or web interface support management of GM, they are primarily intended for viewing the configuration and performing some operations against single disks. GDPS scripts are intended to be used for actions against the entire configuration because this is much simpler (with multiple panel actions combined into a single script command) and less error-prone.
The actual configuration depends on your business and availability requirements, the amount of data you will be remote copying, the types of data you will be remote copying (only CKD or both CKD and FB), and your RPO.

Figure 6-1 GDPS/GM configuration
Figure 6-1 shows a typical GDPS/GM configuration. The application site contains:
•z/OS systems spread across a number of sysplexes
•A non-sysplexed z/OS system
•Two distributed systems
•The K-sys
•The primary disks (identified by A)
•The K-sys’ own disks (marked by L)
The recovery site contains:
•The R-sys
•A CPC with the CBU feature that also contains expendable workloads that can be displaced
•Two backup distributed servers
•The Global Mirror secondary disks (marked by B)
•The Global Mirror FlashCopy targets (marked by C)
•The R-sys’ own disks (marked by L)
Although there is great flexibility in terms of the number and types of systems in the application site, several items are fixed:
•All the GM secondary disks, the FlashCopy targets used by GM, and the GDPS R-sys must be in the recovery site2.
Aspects that are different in GDPS/GM as compared to the other GDPS offerings are listed here:
•Although the K-sys should be dedicated to its role as a Controlling system, it is not necessary to provide the same level of isolation for the K-sys as that required in a GDPS/PPRC or GDPS/HM configuration.
•GDPS/XRC, due to XRC time stamping, requires that all the systems writing to the primary disks have a common time source (Sysplex Timer or STP). GDPS/GM does not have this requirement.
•With GDPS/XRC, if there is insufficient bandwidth for XRC operations, writes to the primary disk subsystem will be paced. This means that the RPO will be maintained, but at the potential expense of performance of the primary devices.
With GDPS/GM, if there is insufficient bandwidth, the consistency points will fall behind. This means that the RPO might not be achieved, but performance of the primary devices will be protected.
In both cases, if you want to protect both response times and RPO, you must provide sufficient bandwidth to handle the peak write load.
The GDPS/GM code itself runs under NetView and System Automation, and is only run in the K-sys and R-sys.
GDPS/GM multiple R-sys co-location
GDPS/GM can support multiple sessions and therefore the same instance of GDPS/GM can be used to manage GM replication and recovery for a number of diverse sysplexes and systems. There are, however, certain cases where different instances of GDPS/GM are required to manage different sessions. One example is the GDPS/GM leg of a GDPS/MGM configuration: in such a configuration, GDPS/GM is restricted to managing only one single session. Clients might have other requirements based on workloads or organizational structure for isolating sessions to be managed by different instances of GDPS/GM.
When you have multiple instances of GDPS/GM, each instance will need its own K-sys. However, it is possible to combine the R-sys “functions” of each instance to run in the same z/OS image. Each R-sys function would run in a dedicated NetView address space in the same z/OS. Actions, such as running scripts, can be carried out simultaneously in these NetView instances. This reduces the overall cost of managing the remote recovery operations for customers that require multiple GDPS/GM instances.
6.2.1 GDPS/GM in a three-site configuration
GDPS/GM can be combined with GDPS/PPRC (or GDPS/HM) in a three-site configuration, where GDPS/PPRC (or GDPS/PPRC HM) is used across two sites within metropolitan distances (or even within a single site) to provide continuous availability through Parallel Sysplex exploitation and GDPS HyperSwap, and GDPS/GM provides disaster recovery in a remote site.
We call this combination the GDPS/Metro Global Mirror (GDPS/MGM) configuration. In such a configuration, both GDPS/PPRC and GDPS/GM provide some additional automation capabilities.
After you understand the base capabilities described in 2.4.4, “Combining disk remote copy technologies for CA and DR” on page 34, refer to Chapter 9, “Combining Local/Metro continuous availability with out-of-region disaster recovery” on page 245 for a more detailed discussion of GDPS/MGM.
6.2.2 Other considerations
The availability of the GDPS K-sys in all scenarios is a fundamental requirement in GDPS. The K-sys monitors the remote copy process, implements changes to the remote copy configuration, and sends GDPS configuration changes to the R-sys.
Although the main role of the R-sys is to manage recovery following a disaster or to enable DR testing, it is important that the R-sys also be available at all times. This is because the K-sys sends changes to GDPS scripts and changes to the remote copy or remote site configuration to the R-sys at the time the change is introduced on the K-sys. If the R-sys is not available when such configuration changes are made, it is possible that it might not have the latest configuration information in the event of a subsequent disaster, resulting in an impact to the recovery operation.
Also, the R-sys plays a role in validating configuration changes. Therefore, it is possible that a change containing errors that would have been rejected by the R-sys (if it had been running) will not be caught. This, again, impacts the remote copy or recovery operation.
Because GDPS/GM is in essence a disaster recovery offering rather than a continuous availability offering, it does not support the concept of site switches that GDPS/PPRC provides3. It is expected that a switch to the recovery site will only be performed in case of a real disaster.
If you want to move operations back to the application site, you must either set up GDPS/GM in the opposite direction (which means that you will also need two sets of disks in the application site), or use an alternate mechanism, like Global Copy, outside the control of GDPS. If you intend to switch to run production in the recovery site for an extended period of time, then providing two sets of disks and running GDPS/GM in the reverse direction would be the preferable option to provide disaster recovery capability.
6.3 GDPS/GM management for distributed systems and data
As previously mentioned, it is possible for GDPS/GM to manage FB disks on behalf of distributed systems that use these disks, either in the same session as System z CKD disks or in a separate session. However, for these distributed systems, although GDPS/GM manages the remote copy and recovery of the disks, it is not able to perform any system recovery actions for the distributed systems in the recovery site.
As an alternative configuration, GDPS/GM also provides the Distributed Cluster Management (DCM) capability for managing global clusters using Veritas Cluster Server (VCS) through the Global Cluster Option (GCO). When the DCM capability is used, GDPS/GM does not manage remote copy or consistency for the distributed system disks (this is managed by VCS). Therefore it is not possible to have a common consistency point between the System z CKD data and the distributed data.
However, for environments where a common consistency point is not a requirement, DCM together with VCS does provide various key availability and recovery capabilities that might be of interest. DCM is discussed in further detail in 8.3.2, “DCM support for VCS” on page 223.
Additionally, GDPS/GM provides the DCM capability for managing distributed clusters under IBM Tivoli System Automation Application Manager (SA AppMan) control. DCM provides advisory and coordinated functions between GDPS and SA AppMan-managed clusters. Data for the SA AppMan-managed clusters can be replicated using Global Mirror under GDPS control.
Thus, z/OS and distributed cluster data can be controlled from one point. Distributed data and z/OS data can be managed in the same consistency group (Global Mirror session) if cross-platform data consistency is required. Equally, z/OS and distributed data can be in different sessions and the environments can be recovered independently under GDPS control. Refer to “Integrated configuration of GDPS/GM and SA AppMan” on page 241 for details.
6.4 Managing the GDPS environment
As previously mentioned, GDPS/GM automation code only runs in one system in the application site, the K-sys, and it does not provide for any monitoring or management of the production systems in this site. The K-sys has the following responsibilities:
•It is the primary point of GDPS/GM control for operators and system programmers in normal operations.
•It manages the remote copy environment. Changes to the remote copy configuration (adding new devices into a running GM session or removing devices from a running session) are driven from the K-sys.
•Changes to the configuration definitions or scripts (including configuration definitions for recovery site resources and scripts destined to be executed on the R-sys) are defined in the K-sys and automatically propagated to the R-sys.
In the recovery site, GDPS/GM only runs in one system: the R-sys. However, the role and capabilities of the R-sys are different from those of the K-sys. Even though both are GDPS Controlling systems, there are fundamental differences between them. The R-sys has the following responsibilities:
•Validate the remote copy configuration in the remote site. This is a key role. GM is a hardware replication technology. Just because the GM primary disks can communicate to the GM secondary disks over remote copy links does not mean that in a recovery situation, systems can use these disks. The disks must be defined in that site’s I/O configuration. If you are missing some disks, this can cause recovery to fail because you will not be able to properly restart systems that need those disks.
•Monitor the GDPS-managed resources in the recovery site and raise alerts for not-normal conditions. For example, GDPS will use the BCP Internal Interface (BCPii) to perform hardware actions such as adding temporary CBU capacity to CPC(s), deactivating LPARs for discretionary workloads, activating LPARs for recovery systems and so on. The R-sys monitors that it has BCPii connectivity to all CPCs that it will need to perform actions against.
•Communicate status and alerts to the K-sys that is the focal management point during normal operations.
•Automate reconfiguration of the recovery site (recovering the Global Mirror, taking a FlashCopy, activating CBU, activating backup partitions and so on) for recovery testing or in the event of a true disaster.
The R-sys has no relation whatsoever to any application site resources. The only connection it has to the application site is the network connection to the K-sys for exchanging configuration and status information.
6.4.1 NetView panel interface
The operator interface for GDPS/GM is provided through NetView 3270 or the GDPS web interface (described in “Web graphical user interface” on page 157), which is also based on NetView facilities. In normal operations the operators interact mainly with the K-sys, but there is also a similar set of interfaces for the R-sys.
The NetView interface for GDPS actually consists of two parts. The first and potentially the most important part is the Status Display Facility (SDF). Any time there is a change of status to something that GDPS does not consider as “normal” and that can impact the ability to recover, something that requires investigation and manual intervention, GDPS sends an alert to SDF.
SDF provides a dynamically updated color-coded panel that provides the status of the systems and highlights any problems in the remote copy configuration. If something changes in the environment that requires attention, the color of the associated field on the panel will change. K-sys sends alerts to the R-sys and R-sys sends alerts to K-sys so that both Controlling systems are aware of any problems at all times.
During normal operations, the operators should always have a K-sys SDF panel within view so they will immediately become aware of anything requiring intervention or action. When R-sys is being used for managing testing or recovery operations, then operators should have access to the R-sys SDF panel as well.
The other part of the NetView interface consists of the panels provided by GDPS to help you manage and inspect the environment. The main GDPS panel is shown in Figure 6-2 on page 157. Notice that some of the options are not enabled (options 2 and 7, which are colored in blue). This is because those functions are not part of GDPS/GM.
From this panel, you can perform the following actions:
•Query and control the disk remote copy configuration.
•Initiate GDPS-provided standard actions (the ability to control and initiate actions against LPARs):
– On the K-sys, the only standard action supported is the ability to update IPL information for the recovery site LPARs.
– On the R-sys, all standard actions are available.
•Initiate GDPS scripts (Planned Actions).
•Manage GDPS Health Checks.
•View and refresh the definitions of the remote copy configuration.
•Run GDPS monitors.

Figure 6-2 GDPS Main panel (K-sys)
Web graphical user interface
The web interface is a browser-based interface designed to improve operator productivity. The web interface provides the same functional capability as the 3270-based panel, such as providing management capabilities for Remote Copy Management, Standard Actions, Sysplex Resource Management, and SDF Monitoring using simple point-and-click procedures. In addition, users can open multiple windows to allow for continuous status monitoring while performing other GDPS/GM management functions.
The web interface display has three sections:
•A menu bar on the left with links to the main GDPS options
•A window list on top allowing switching between multiple open frames
•An active task frame where the relevant information is displayed and activities are performed for a selected option
The main status panel of the GDPS/GM web interface is shown in Figure 6-3. The left frame, shown beneath GDPS Global Mirror links, allows you to select the menu options. These options can be displayed at all times, or you can optionally collapse the frame.
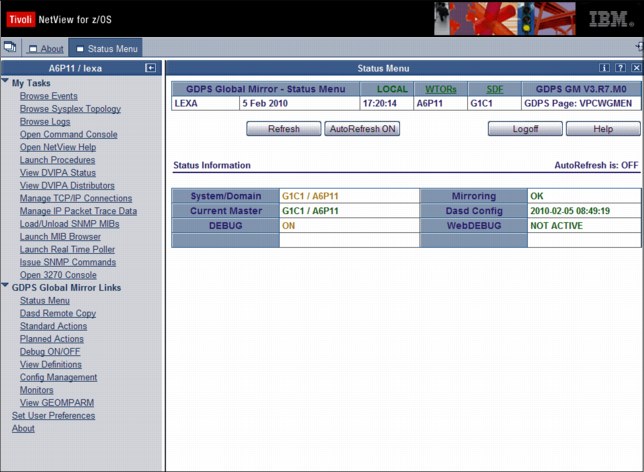
Figure 6-3 Full view of GDPS main panel with task bar and status information
Main Status panel
The GDPS web interface status frame shown in Figure 6-4 is the equivalent to the main GDPS panel. The information shown on this panel is what is found on the top portion of the 3270 GDPS Main panel.

Figure 6-4 GDPS web interface - Main Status panel
Remote copy panels
Although Global Mirror is a powerful copy technology, the z/OS operator interface to it is not particularly intuitive. To make it easier for operators to check and manage the remote copy environment, use the GDPS-provided Disk Remote Copy panels.
For GDPS to manage the remote copy environment, you first define the configuration to GDPS in the GEOMPARM file on the K-sys. The R-sys always gets the configuration information from the K-sys and validates the remote site disk configuration.
After the configuration is known to GDPS, you can use the panels to check that the current configuration matches the desired one. You can start, stop, pause, and resynch mirroring. These actions can be carried out at the device, LSS, or session level, as appropriate. However, we recommend that GDPS control scripts are used for actions at the session level.
Figure 6-5 shows the mirroring status panel for GDPS/GM as viewed on the K-sys. The panel for the R-sys is similar, except that the R-sys can only perform a limited number of actions (typically only those necessary to take corrective action) against the devices in the recovery site. Control of the GM session can only be carried out from the K-sys; the R-sys can only control the devices in the recovery site.

Figure 6-5 Disk Mirroring panel for GDPS/GM K-sys
Remember that these panels provided by GDPS are not intended to be a remote copy monitoring tool. Because of the overhead involved in gathering information about each and every device in the configuration to populate the NetView panels, GDPS only gathers this information on a timed basis, or on demand following an operator instruction. The normal interface for finding out about remote copy problems is the Status Display Facility, which is dynamically updated if or when a problem is detected.
Standard Actions
As previously explained, the K-sys does not provide any management functions for any systems, either in the application site or in the recovery site. The R-sys manages recovery in the recovery site. As a result, the Standard Actions that are available vary, depending which type of Controlling system you are using.
On the K-sys, the only Standard Action available is to define the possible IPL address and Loadparms that can be used for recovery systems (production systems when they are recovered in the recovery site) and to select which one is to be used in the event of a recovery action. Changes made on this panel are automatically propagated to the R-sys. The K-sys Standard Actions panel is shown in Figure 6-6.

Figure 6-6 GDPS/GM K-sys Standard Actions panel
Because the R-sys manages the recovery in the event of a disaster (or IPL for testing purposes) of the production systems in the recovery site, it has a wider range of functions available, as seen in Figure 6-7. Functions are provided to activate and deactivate LPARs, to IPL and reset systems, and to update the IPL information for each system.

Figure 6-7 Example GDPS/GM R-sys Standard Actions panel for a selected system
There are actually two types of resource-altering actions you can initiate from the panels: Standard Actions and Planned Actions. Standard Actions are really single-step and will impact one resource, such as deactivating an LPAR after a D/R test.
For example, if you want to (1) reset an expendable test system running in the recovery site; (2) deactivate the LPAR of the expendable system; (3) activate the recovery LPAR for a production system; and then (4) IPL the recovery system into the LPAR you just activated, this task consists of four separate Standard Actions that you initiate sequentially from the panel.
GDPS scripts
Nearly all the functions that can be initiated through the panels (and more) are also available from GDPS scripts. A script is a “program” consisting of one or more GDPS functions to provide a workflow. In addition to the low-level functions available through the panels, scripts can invoke functions with a single command that might require multiple separate steps if performed through the panels. For example, if you have a new disk subsystem and will be adding several LSS, populated with a large number of devices to your Global Mirror configuration, this can require a significantly large number of panel actions.
In comparison, it can be accomplished by a single script command. It is simply faster and more efficient to perform compound/complex operations using scripts.
Scripts can be initiated manually through the GDPS panels or through a batch job. In GDPS/GM, the only way to initiate the recovery of the secondary disks is through a GDPS script on the R-sys; invoking a recovery directly from the mirroring panels is not supported.
Scripts are written by you to automate the handling of certain situations, both planned changes and also error situations. This is an extremely important aspect of GDPS.
Scripts are powerful because they can access the full capability of GDPS. The ability to invoke all the GDPS functions through a script provides the following benefits:
•Speed
The script will execute the requested actions as quickly as possible. Unlike a human, it does not need to search for the latest procedures or the commands manual.
•Consistency
If you were to look into most computer rooms immediately following a system outage, what would you see? Mayhem! Operators will be frantically scrambling for the latest system programmer instructions. All the phones will be ringing. Every manager within reach will be asking when the service will be restored. And every system programmer with access will be vying for control of the keyboards. All this results in errors, because humans often make mistakes when under pressure. But with automation, your well-tested procedures will execute in exactly the same way, time after time, regardless of how much you shout at them.
•Automatic checking of results from commands
Because the results of many GDPS commands can be complex, manual checking of results can be time-consuming and presents the risk of missing something. In contrast, scripts automatically check that the preceding command (remember, that one command can have been six GM commands, each of the six executed against thousands of devices) completed successfully before proceeding with the next command in the script.
•Thoroughly tested procedures
Because scripts behave in a consistent manner, you can test your procedures over and over until you are sure they do everything that you want, in exactly the manner that you want. Also, because you need to code everything and cannot assume a level of knowledge (as you might with instructions intended for a human), you are forced to thoroughly think out every aspect of the action the script is intended to undertake. Finally, because of the repeatability and ease of use of the scripts, they lend themselves more easily to frequent testing than manual procedures.
Planned Actions
GDPS scripts can be initiated from the Planned Actions option on the GDPS main panel. In a GDPS/GM environment, all actions affecting the recovery site are considered planned actions. You can think of this as pre-planned unplanned actions. An example of a planned action in GDPS/GM is a script that prepares the secondary disks and LPARs for a disaster recovery test. Such a script will carry out the following actions:
•Recover the disks in the disaster site; this makes the B disks consistent with the C disks. The B disks will be used for the test; the C disks contain a consistent copy that ages during the test.
•Activate CBU capacity in the recovery site CPCs.
•Activate backup partitions that have been predefined for the recovery systems (that is, the production systems running in the recovery site).
•Activate any backup Coupling Facility partitions in the recovery site.
•Load the systems into the partitions in the recovery site using the B disks.
When the test is complete, you run another script in the R-sys to perform the following tasks:
•Reset the recovery systems that were used for the test
•Deactivate the LPARs that were activated for the test.
•Undo CBU on the recovery site CPCs.
•Issue a message to the operators to manually shut down any open systems servers in the recovery site that were used for the test.
•Bring the B disks back into sync with the C disks (which are consistent with the primary disks at the time of the start of the test).
•Finally, you run a script on the K-sys to resynchronize the recovery site disks with the production disks.
Batch scripts
In addition to the ability to initiate GDPS scripts from the GDPS panel interfaces, it is also possible to initiate a script from a batch interface. This is especially suited to processes that are run regularly, and have some interaction with the GDPS environment.
6.4.2 System Management actions
In a GDPS/GM environment, the remote Controlling system can use the hardware and system management actions to reconfigure the recovery site by adding temporary capacity, activating backup partitions, and IPLing production systems. This can be either for test purposes or for a real recovery. GDPS does not manage the systems or the hardware in the application site.
Most GDPS Standard Actions and many GDPS script commands require actions to be carried out on the HMC. The interface between GDPS and the HMC is through the BCP Internal Interface (BCPii), and it allows GDPS to communicate directly with the hardware for automation of HMC actions such as LOAD, RESET, and Activate or Deactivate an LPAR, and Activate or Undo CBU or OOCoD.
The GDPS LOAD and RESET Standard Actions (available through the Standard Actions panel or the SYSPLEX script statement) allow specification of a CLEAR or NOCLEAR operand. This provides the operational flexibility to accommodate client procedures.
Extensive facilities for adding temporary processing capacity to the CPCs in the recovery site are provided by the GDPS scripting capability.
6.5 GDPS/GM monitoring and alerting
We discuss the GDPS SDF panel in 6.4.1, “NetView panel interface” on page 156. This is the panel on which GDPS dynamically displays alerts, which are color-coded based on severity, if and when a non-normal status or situation is detected.
Alerts can be posted as a result of an unsolicited error situation that GDPS listens for. For example, if there is a problem with the GM session and the session suspends outside of GDPS control, GDPS will be aware of this because the disk subsystem that is the Master for the GM session will post an SNMP alert. GDPS listens for these SNMP alerts and, in turn, posts an alert on the SDF panel that notifies the operator of the suspension event.
Alerts can also be posted as a result of GDPS periodically monitoring key resources and indicators that relate to the GDPS/GM environment. If any of these monitoring items are found to be in a state deemed to be not normal by GDPS, an alert is posted on SDF. Because the K-sys and R-sys have different roles and affect different resources, they each monitor a different set of indicators and resources.
For example, the K-sys has TCP/IP connectivity to the A disk through which the GM Master disk subsystem posts SNMP alerts about GM problems. For this reason, it is important that the TCP/IP connectivity between the K-sys and the production disk is functioning properly. The K-sys, among other things, monitors this connection to ensure that it is functional so that if there is a GM problem, the SNMP alert will reach the K-sys.
Likewise, it is the R-sys that uses the BCP Internal Interface to perform hardware actions to reconfigure the recovery site, either for disaster testing or in the event of a real recovery scenario. One of the resources monitored by the R-sys is the BCP Internal Interface connection to all CPCs in the recovery site on which the R-sys can perform hardware operations such as CBU or LPAR activation.
Both the K-sys and the R-sys, in addition to posting alerts on their own SDF panel, will additionally forward any alerts to the other system for posting. Because the operator will be notified of R-sys alerts on the K-sys SDF panel, it is sufficient for the operator to monitor the K-sys SDF panel during normal operations as long as the K-sys is up and running.
If an alert is posted, the operator has to investigate (or escalate, as appropriate) and corrective action needs to be taken for the reported problem as soon as possible. After the problem is corrected, this is detected during the next monitoring cycle and the alert is cleared by GDPS automatically.
GDPS/GM monitoring and alerting capability is intended to ensure that operations are notified of and can take corrective action for any problems in their environment that can impact the ability of GDPS/GM to carry out recovery operations. This will maximize the installation’s chance of achieving its RPO and RTO commitments.
6.5.1 GDPS/GM health checks
In addition to the GDPS/GM monitoring described, GDPS provides health checks. These health checks are provided as a plug-in to the z/OS Health Checker infrastructure to check that certain settings related to GDPS adhere to GDPS best practices.
The z/OS Health Checker infrastructure is intended to check a variety of settings to determine whether these settings adhere to z/OS best practices values. For settings that are found to be not in line with best practices, exceptions are raised in the Spool Display and Search Facility (SDSF). Many products including GDPS provide health checks as a plug-in to the z/OS Health Checker. There are various parameter settings related to GDPS, such as z/OS PARMLIB settings or NetView settings, and the recommendations and best practices for these settings have been documented in the GDPS publications. If these settings do not adhere to recommendations, this can hamper the ability of GDPS to perform critical functions in a timely manner.
Although GDPS monitoring will detect that GDPS was not able to perform a particular task and raise an alert, the monitor alert might be too late, at least for that particular instance of an incident. Often, if there are changes in the client environment, this might necessitate adjustment of some parameter settings associated with z/OS, GDPS, and other products. It is possible that you can miss making these adjustments, which might result in affecting GDPS. The GDPS health checks are intended to detect such situations and avoid such incidents where GDPS is unable to perform its job, due to a setting that is perhaps less than ideal.
For example, there are a number of address spaces associated with GDPS/GM and best practices recommendations are documented for these. GDPS code itself runs in the NetView address space and there are DFSMS address spaces that GDPS interfaces with to perform GM copy services operations. GDPS recommends that these address spaces are assigned specific Workload Manager (WLM) service classes to ensure that they are dispatched in a timely manner and do not lock each other out. One of the GDPS/GM health checks, for example, checks that these address spaces are set up and running with the GDPS-recommended characteristics.
Similar to z/OS and other products that provide health checks, GDPS health checks are optional. Additionally, a number of the best practices values that are checked, and the frequency of the checks, are client-customizable to cater to unique client environments and requirements.
GDPS also provides a useful interface for managing the health checks using the GDPS panels. You can perform actions such as activate or deactivate or run any selected health check, view the customer overrides in effect for any best practices values, and so on. Figure 6-8 shows a sample of the GDPS Health Check management panel. In this example you see that all the health checks are enabled. The status of the last run is also shown, indicating whether the last run was successful or whether it resulted in an exception. Any exceptions can also be viewed using other options on the panel.

Figure 6-8 GDPS/GM Health Check management panel
6.6 Other facilities related to GDPS
In this section we describe miscellaneous facilities provided by GDPS/Global Mirror that can assist in various ways.
6.6.1 GDPS/GM Copy Once facility
GDPS provides a Copy Once facility to copy volumes that have data sets on them that are required for recovery but the content is not critical, such that they do not require to be copied all the time. Page data sets and work volumes that only contain truly temporary data such as sort work volumes are primary examples. The Copy Once facility can be invoked whenever required to refresh the information about these volumes.
To restart your workload in the recovery site, you need to have these devices or data sets available (the content is not required to be up-to-date). If you do not remote copy all of your production volumes, then you will need to either manually ensure that the required volumes and data sets are preallocated and kept up-to-date at the recovery site or use the GDPS Copy Once facility to manage these devices.
For example, if you are not replicating your paging volumes, then you must create the volumes with the proper volume serial with required data sets in the recovery site. Then, each time you change your paging configuration in the application site, you must reflect the changes in your recovery site. The GDPS Copy Once facility provides a method of creating an initial copy of such volumes plus the ability to recreate the copy if the need arises as the result of any changes in the application site.
If you plan to use the Copy Once facility, you need to ensure that no data that needs to be continuously replicated is placed on the volumes you define to GDPS as Copy Once because these volumes will not be continuously replicated. The purpose of Copy Once is to ensure that you have a volume with the correct VOLSER, and with the data sets required for recovery allocated, available in the recovery site. The data in the data sets is not time-consistent with the data on the volumes that are continuously mirrored.
6.6.2 GDPS/GM Query Services
GDPS maintains configuration information and status information in NetView variables for the various elements of the configuration that it manages. GDPS Query Services is a facility that allows user-written REXX programs running under NetView to query and obtain the value of various GDPS variables. This allows you to augment GDPS automation with your own automation REXX code for various purposes such as monitoring or problem determination.
Query Services allows clients to complement GDPS automation with their own automation code. In addition to the Query Services function, which is part of the base GDPS product, GDPS provides a number of samples in the GDPS SAMPLIB library to demonstrate how Query Services can be used in client-written code.
6.6.3 Global Mirror Monitor integration
GDPS provides a Global Mirror Monitor (also referred to as GM Monitor) that is fully integrated into GDPS. This function provides a monitoring and historical reporting capability for Global Mirror performance and behavior, and some autonomic capability based on performance. The GM Monitor provides the following capabilities:
•Ability to view recent performance data for a Global Mirror session, for example to understand if an ongoing incident might be related to Global Mirror.
•Generation of alerts and messages for Global Mirror behavior based on exceeding thresholds in a defined policy.
•Ability to perform automatic actions such as pausing a GM session or resuming a previously paused session based on a defined policy.
•Creation of SMF records with detailed historical Global Mirror performance and behavioral data for problem diagnosis, performance reporting, and capacity planning.
The GM Monitor function runs in the K-sys and supports both CKD and FB environments. An independent monitor can be started for each GM session in your GDPS configuration. GDPS stores the performance data collected by each active monitor. Recent data is viewable using the GDPS 3270 panels.
6.7 Flexible testing
If you want to conduct a disaster recovery test, you can use GDPS/GM to prepare the B disks to be used for the test. However, note that during the test, remote copying must be suspended. This is because the B disks are being used for the test, and the C disks contain a consistent copy of the production disks at the start of the test. If you were to have a real disaster during the test, the C disks will be used to give you a consistent restart point. All updates made to the production disks after the start of the test will need to be recreated, however. At the completion of the test, GDPS/GM uses the Failover/Failback capability to resynchronize the A and B disks without having to do a complete copy.
GDPS/GM supports an additional FlashCopy disk device, referred to as F disks or FC1 disks. F disks are additional “practice” FlashCopy target devices that may optionally be created in the recovery site. These devices may be used to facilitate stand-alone testing of your disaster recovery procedures. Disaster testing can be conducted by IPLing recovery systems on the F disk while live production continues to run in the application site and continues to be protected by the B and C disks. In addition, the F disk can be used to create a “gold” or insurance copy of the data in the event of a disaster situation. If you have this additional practice FlashCopy, you will be able to schedule disaster tests on demand much more frequently because such tests will have little or no impact on your RPO and DR capability.
For added scalability, GDPS allows the GM FC disks (C) to be defined in alternate subchannel set MSS1. It is also possible for GDPS/GM to support the F disk without adding a requirement for the FC1 disks to be defined to the R-sys. Refer to “Scalability in a GDPS/XRC environment” on page 30 for more information.
By combining Global Mirror with FlashCopy, you can create a usable copy of your production data to provide for on-demand testing capabilities and other nondisruptive activities. If there is a requirement to perform disaster recovery testing while maintaining the currency of the production mirror or for taking regular additional copies, perhaps once or twice a day, for other purposes, then consider installing the additional disk capacity to support F disks in your Global Mirror environment.
6.7.1 Usage of FlashCopy Space Efficient
As discussed in “FlashCopy Space Efficient (FlashCopy SE)” on page 39, by using FlashCopy Space Efficient (SE) volumes, you might be able to lower the amount of physical storage needed, and thereby reduce the cost associated with providing a tertiary copy of the data. GDPS has support to allow FlashCopy Space Efficient volumes to be used as FlashCopy target disk volumes.
This support is transparent to GDPS; if the FlashCopy target devices defined to GDPS are Space Efficient volumes, GDPS will simply use them. All GDPS FlashCopy operations with the NOCOPY option, whether through GDPS scripts or panels, can use Space Efficient targets.
Because the IBM FlashCopy SE repository is of fixed size, it is possible for this space to be exhausted, thus preventing further FlashCopy activity. Consequently, we recommend using Space Efficient volumes for temporary purposes, so that space can be reclaimed regularly.
GDPS/GM may use SE volumes as FlashCopy targets for either the C-disk or the F-disk. In the GM context, where the C-disk has been allocated to Space Efficient volumes, each new Consistency Group reclaims used repository space since the previous Consistency Group, as the new flash is established with the C-disk. Therefore, a short Consistency Group Interval in effect ensures the temporary purpose recommendation for FlashCopy data. However, if the Consistency Group Interval grows long due to constrained bandwidth or write bursts, it is possible to exhaust available repository space. This will cause a suspension of GM, because any subsequent FlashCopy will not be possible.
Using Space Efficient volumes for F disks depends on how you intend to use the F disks. These can be used for short-term, less-expensive testing, but are suitable for actual recovery due to their non-temporary nature.
6.8 GDPS tools for GDPS/GM
GDPS ships tools which provide function that is complementary to GDPS function. The tools represent the kind of function that many clients are likely to develop themselves to complement GDPS. Using the GDPS-provided tools eliminates the necessity for you to develop similar function yourself. The tools are provided in source code format, which means that if the tool does not completely meet your requirements, you can modify the code to tailor it to your needs.
The following GDPS tool is available for GDPS/GM:
•GDPS Distributed Systems Hardware Management Toolkit provides an interface for GDPS to monitor and control distributed systems’ hardware and virtual machines (VMs) by using script procedures that can be integrated into GDPS scripts. This tool provides REXX script templates that show examples of how to monitor/control; IBM AIX HMC, VMware ESX server, IBM BladeCenters, and stand-alone x86 servers with Remote Supervisor Adapter II (RSA) cards. This tool is complementary to the heterogeneous, distributed management capabilities provided by GDPS, such as the Distributed Cluster Management (DCM) and Open LUN management functions.
6.9 Services component
As demonstrated, GDPS touches on much more than simply remote copy. It also includes automation, disk and system recovery, testing processes, and disaster recovery processes.
Most installations do not have all these skills readily available. Also, it is extremely rare to find a team that possesses this range of skills across many implementations. However, the GDPS/GM offering provides access to a global team of specialists in all the disciplines you need to ensure a successful GDPS/GM implementation.
Specifically, the Services component includes some or all of the following services:
•Planning to determine availability requirements, configuration recommendations, implementation and testing plans. Planning session topics include hardware and software requirements and prerequisites, configuration and implementation considerations, cross-site connectivity planning and potentially bandwidth sizing, and operation and control.
•Assistance in defining Recovery Point and Recovery Time objectives.
•Installation and necessary customization of NetView and System Automation.
•Remote copy implementation.
•GDPS/GM automation code installation and policy customization.
•Education and training on GDPS/GM setup and operations.
•Onsite implementation assistance.
•Project management and support throughout the engagement.
The sizing of the Services component of each project is tailored for that project based on many factors, including what automation is already in place, whether remote copy is already in place, and so on. This means that the skills provided are tailored to the specific needs of each implementation.
6.10 GDPS/GM prerequisites
|
Important: For the latest GDPS/GM prerequisite information, refer to the GDPS product web site:
|
6.11 Comparison of GDPS/GM versus other GDPS offerings
There are so many features and functions available in the various members of the GDPS family that it is sometimes difficult to remember them all, and to recall which offerings support them. To position the offerings Table 6-1 lists the key features and functions and indicates which ones are delivered by the various GDPS offerings.
Table 6-1 Supported features matrix
|
Feature
|
GDPS/PPRC
|
GDPS/PPRC HM
|
GDPS/XRC
|
GDPS/GM
|
|
Continuous availability
|
Yes
|
Yes
|
No
|
No
|
|
Disaster recovery
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Supported distance
|
200 km
300 km (BRS configuration)
|
200 km
300 km (BRS configuration)
|
Virtually unlimited
|
Virtually unlimited
|
|
FlashCopy support
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Reduced impact initial copy/resynch
|
Yes
|
Yes
|
N/A
|
N/A
|
|
TS7700 support
|
Yes
|
No
|
No
|
No
|
|
PtP VTS support
|
Yes
|
No
|
Yes
|
No
|
|
Production sysplex automation
|
Yes
|
No
|
No
|
No
|
|
Span of control
|
Both sites
|
Both sites
(disk only)
|
Recovery site
|
Disk at both sites.
Recovery Site (CBU / LPARs)
|
|
GDPS scripting
|
Yes
|
No
|
Yes
|
Yes
|
|
Monitoring, alerting, and Health Checks
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Query Services
|
Yes
|
Yes
|
Yes
|
Yes
|
|
MGM
|
Yes
(IR or non-IR)
|
Yes
(Non-IR only)
|
N/A
|
Yes
(IR or non-IR)
|
|
MzGM
|
Yes
|
Yes
|
Yes
|
N/A
|
|
Open LUN
|
Yes
|
Yes
|
No
|
Yes
|
|
z/OS equivalent functionality for Linux for System z
|
Yes
|
No
|
Yes
|
Yes
|
|
Heterogeneous support through DCM
|
Yes (VCS and SA AppMan)
|
No
|
Yes (VCS only)
|
Yes (VCS and SA AppMan)
|
|
Web interface
|
Yes
|
Yes
|
No
|
Yes
|
6.12 Summary
GDPS/GM provides automated disaster recovery capability over virtually unlimited distances for both CKD and FBA devices. It does not have a requirement for a z/OS System Data Mover system as XRC does, but it does require an additional set of recovery disks when compared to GDPS/XRC. It also does not provide the vendor independence that GDPS/XRC provides.
The two Controlling systems in a GDPS/GM configuration provide different functions. The K-sys, in the application site, is used to set up and control all remote copy operations. The R-sys, in the recovery site, is used primarily to drive recovery in case of a disaster. You define a set of scripts that can reconfigure the servers in the recovery site, recover the disks, and start the production systems. The powerful scripting capability allows you to perfect the actions to be taken, either for planned or unplanned changes, thus eliminating the risk of human error. Both the K-sys and R-sys monitor key indicators and resources in their span of control and alert the operator of any non-normal status so that corrective action can be taken in a timely manner to eliminate or minimize RPO and RTO impact.
The B disks in the recovery site can be used for disaster recovery testing. The C disks contain a consistent (although, aging) copy of the production volumes. Optionally, a practice FlashCopy (F disks) can be integrated to eliminate the risk of RPO impact associated with testing on the B disks.
In addition to its DR capabilities, GDPS/GM also provides a user-friendly interface for monitoring and managing the remote copy configuration.
1 The application site is the site where production applications whose data is to be mirrored normally run, and it is the site where the Global Mirror primary disks are located. You might also see this site referred to as the “local site” or the “A-site.”
2 The recovery site is the site where the mirrored copy of the production disks are located, and it is the site into which production systems are failed over to in the event of a disaster. You might also see this site referred to as the “remote site” or the “R-site.”
3 Region switches are supported by GDPS/MGM in an Incremental Resynch configuration.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.