
In this chapter, we will briefly examine the concepts of business continuity (BC), which looks at the business as a whole, and disaster recovery (DR), which looks at just the IT infrastructure and which usually forms a component part of an organisation’s business continuity programme.
Although business continuity covers a much broader area than just cyber security, it is important to understand the underlying principles since it is a means of preparing for possible cyber security incidents. Likewise, disaster recovery is not all about cyber security but can play a major part in recovering from cyber security incidents.
Both business continuity and disaster recovery have a proactive and a reactive element to their contribution to cyber security; the proactive side attempts to reduce the likelihood that a threat or hazard may cause a disruption, and the reactive side is intended to take care of the recovery if one does occur.
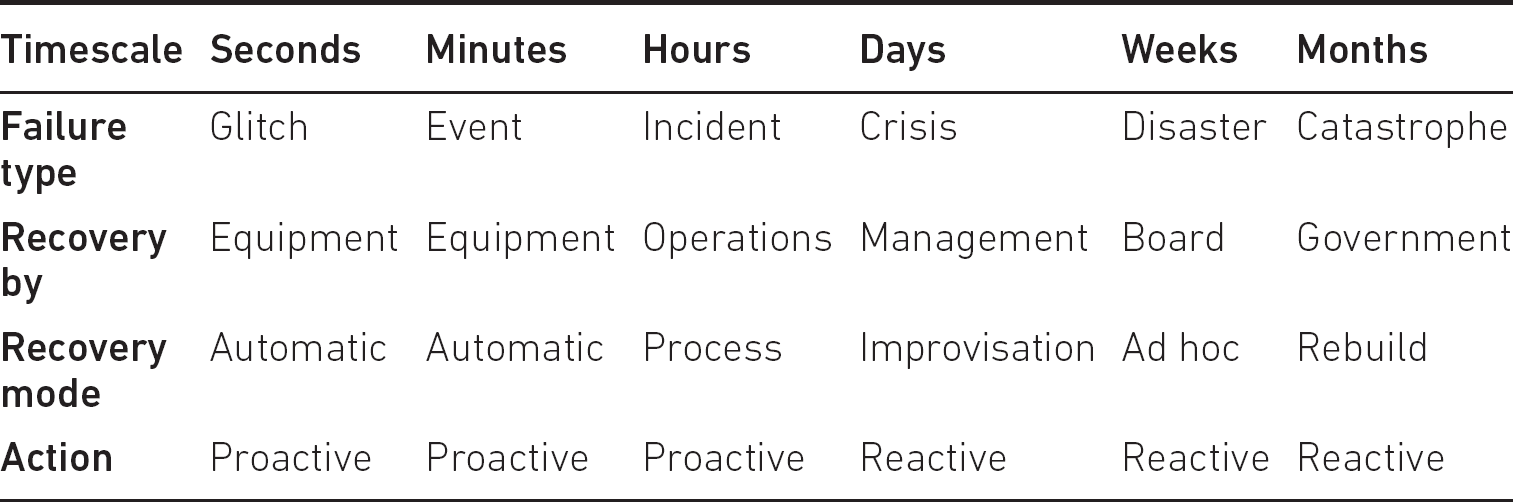
Generally speaking, the longer a disruption lasts, the greater the impact on the organisation, so it helps to clarify the type of disruption, its duration and impact, and how an organisation manages the situation. Table 7.1 provides an example of this, and the failure types are covered in more detail below.
Table 7.1 Incident durations and recovery methods
FAILURES
Glitches
These are extremely short occurrences, usually lasting just a few seconds at the most, and are generally caused by brief interruptions in power or loss of radio or network signal. Activities usually return to normal following most glitches as equipment self-corrects automatically.
Events
Events normally last no more than a few minutes. As with glitches, the equipment they affect is frequently automatically self-correcting, but may on occasion require a degree of manual intervention.
Incidents
Incidents are usually viewed as lasting no more than a few hours. Unlike glitches and events, they require operational resolution, normally involving manual intervention that follows some form of process.
The methods of dealing with glitches, events and incidents are mostly proactive in nature in that processes and procedures are developed in advance and are followed when the incident occurs.
Crises
Crises can often last for several days. Although organisations may have plans, processes and procedures to deal with them, and although operational staff will carry out any remedial actions, some degree of improvisation may be required. Crises almost invariably require a higher layer of management to take control of the situation, make decisions and communicate with stakeholders and the media.
Disasters
Disasters frequently last for weeks. As with crises, operational staff will carry out immediate remedial actions, although at this stage a degree of ad hoc action may be necessary. Although a higher management layer will control activities, the senior management layer will usually take overall charge of the situation.
Catastrophes
Catastrophes are the most serious level, often lasting for months, or in some cases for years. Their scale tends to affect many communities, and so although individual organisations may be operating their own recovery plans, it is likely that local, regional or even national government will oversee the situation and that either a partial or complete rebuilding of the infrastructure may be required.
Despite any proactive planning or activities to lessen their impact or likelihood, crises, disasters and catastrophes all require significant reactive activity, and each will demand an increasing amount of incident management capability.
It is important for organisations to understand that the more time spent in proactive work, the less time will generally be required in reactive work following a cyber-attack.
Business continuity and disaster recovery share the same fundamental Plan–Do–Check–Act cycle as discussed in Chapter 6. During the ‘Plan’ stage, we carry out the risk assessment (risk identification, risk analysis and risk evaluation); in the ‘Do’ stage, we implement the risk treatment options and assemble the plans; in the ‘Check’ stage, we verify that the plans are fit for purpose by testing and exercising; and finally in the ‘Act’ stage, we put the plans into practice when a disruptive incident occurs.
BUSINESS CONTINUITY
Putting business continuity into practice is strongly linked to the process of risk management described in Chapter 6, in which we identify all the organisation’s assets, owners and impacts; assess the likelihood of risks happening; and combine the two to provide a perceived level of risk. From this, we are able to propose strategic, tactical and operational controls, one of the main components of which will be the business continuity plan (BCP) itself.
The plan should include the actions that will cause it to be triggered; who (or which departments) will be responsible for what actions; how they will be contacted; what actions they will take; how, where and when they will communicate with senior management and other stakeholders; and finally, how they will determine when business has resumed a pre-determined level of normality.
The plan itself may not always contain detailed instructions, as these may change at intervals, but they should be referred to in the plan.
Although cyber security covers only a part of the overall business continuity process, there are certain aspects, especially with regard to the ongoing availability of information and resources, that are very much an integral part of cyber security.
The most obvious of these is that of disaster recovery of ICT systems, in which the systems that are likely to be impacted require some form of process in order to permit short-term or even immediate recovery.
Business continuity is often referred to as a journey rather than a destination. It looks at the organisation as a whole as opposed to just the IT aspects. However, that said, the generic business continuity process applies extremely well to cyber security and can be used to help an organisation to place itself in a very strong position.
The Business Continuity Institute (BCI) describes business continuity as: ‘The capability of the organisation to continue delivery of its products or services at acceptable redefined levels following a disruptive incident.’ It provides excellent guidance on the entire process, and its latest Good Practice Guidelines (2018 version)1 can be purchased for around £30 for a downloaded copy, free of charge to BCI members.
Over several years, the BCI has developed a business continuity management life cycle, with six distinct areas known as Professional Practices (PPs). It is basically a variation on the theme of risk management.
Firstly, there are two Management Professional Practices:
PP1 Business continuity policy and programme management, in which the overall organisation’s business strategy is used to develop the programme of work, each component of which is then managed as a project.
PP2 Embedding business continuity into the organisation’s culture, which includes training, education and awareness, and is covered in Chapter 10 of this book.
Then there are four Technical Professional Practices:
PP3 Analysis is all about understanding the organisation, its priorities and objectives, its assets, potential impacts, its threats or hazards and the vulnerabilities it faces. From this a risk assessment can be undertaken, and the key metrics such as the recovery time objective (RTO),2 maximum acceptable outage (MAO)3 and maximum tolerable data loss (MTDL)4 can be derived.
PP4 Determining the business continuity management strategy (also referred to as Design) and designing the approach to deliver this can now take place, based on the metrics arrived at in the analysis stage, and decisions can be made regarding what proactive measures should be put in place; how response to an incident will be organised; and how the organisation will recover to normal operational levels or to a new, revised level of normality.
PP5 Implementing the business continuity response will require the efforts of people in various parts of the organisation to put in place the proactive and reactive measures agreed in the previous stage.
PP6 Validation, which includes exercising, maintaining and reviewing, is a separate activity to embedding the business continuity culture into the organisation, since it deals with the inclusion of people who may already have been involved in the previous stages, and who need no introduction to the subject; rather they need to be able to exercise the various response and recovery plans, validate them and fine-tune them where necessary.
The general timeline for business continuity is illustrated in Figure 7.1. If the organisation is well organised, all six stages of the life cycle should have been completed before an incident occurs.
The first actions will be to respond to the incident itself, bringing together the incident management team, gaining an understanding of the situation and agreeing which aspects of the plan are to be implemented. At this time, it will also be important to consider preparing some form of statement that can be given to the media, customers and suppliers so that their expectations are managed.
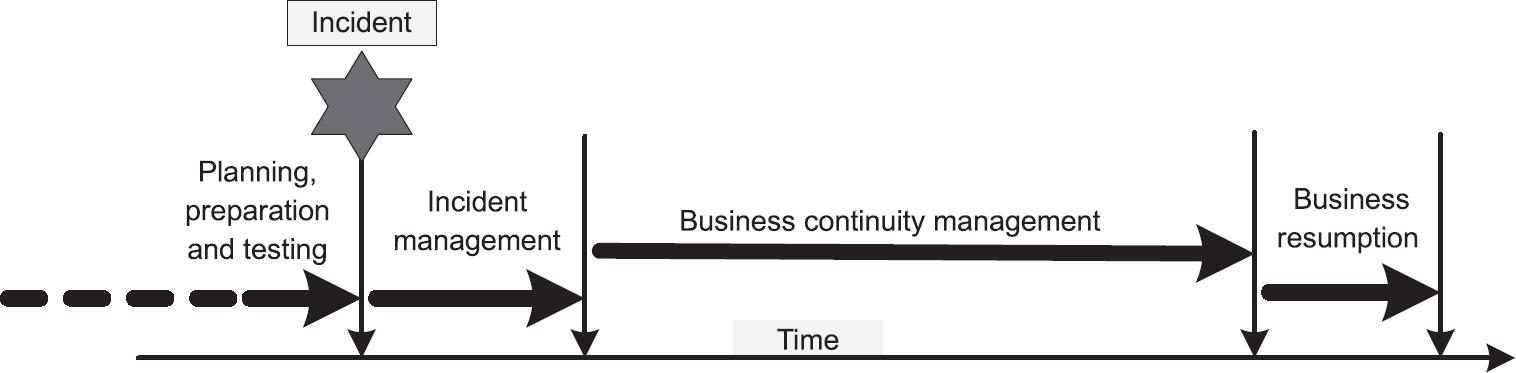
Next, the processes and procedures that have been developed (which may include disaster recovery mechanisms) will be brought into action, and depending upon the nature of the situation as seen in Table 7.1, may be in progress for some time. If this is the case, follow-up media statements will be required.
Finally, once the situation has been resolved, business can be returned to normal, or if the impacts have been considerable, to a new level of normality.
The international standard ISO 22301:2019 – Societal security – Business continuity management systems – Requirements covers all aspects of business continuity.
DISASTER RECOVERY
One of the main features of a business continuity plan is in providing the availability determined by the analysis stage of the business continuity process. Disaster recovery is perhaps a misnomer, since it implies that systems, applications and services have failed catastrophically and need to be brought back online. While this might be the case for some services, it is not necessarily true for all, since an element of proactive work can (and usually should) be carried out, and it may be the case that just one component in the service has failed but that this causes a chain reaction and requires a disaster recovery process to be invoked.
As with any business continuity work, there are both proactive and reactive sides to disaster recovery, and since there are no ‘one size fits all’ solutions, we’ll discuss some of the options in general terms.
Standby systems
Conventionally, there are three basic types of standby system – cold, warm and hot – although there are variants within these. Most well-designed standby operations will ensure that there is an effective physical separation between the ‘active’ and ‘standby’ systems since the loss of a data centre or computer room containing both systems would clearly result in no recovery capability.
Traditionally, organisations work on the basis that a minimum separation of 30 km is sufficient to guarantee that a major incident affecting one data centre will not affect the other.
Systems, as we refer to them here, can mean any system that is involved in providing the organisation’s service and can include web servers at the front end of the operation as well as back-end servers and support systems, and essential parts of the interconnecting networks.
Cold standby systems frequently make use of hardware platforms that are shared by a number of organisations. They may have power applied, and may also have an OS loaded, but they are unlikely to have much, if any, user application software installed, since each organisation’s requirements will be subtly different. There will also be no data loaded.
This is the least effective method of restoration, since it may take a significant amount of time and effort to load the operating system (if not already done), to load and configure the user applications and to restore the data from backup media. It will, however, invariably be the lowest cost solution for those organisations who are able to tolerate a longer RTO.
Another disadvantage of cold standby systems is that if they are shared with other organisations there may be a conflict of resources if more than one organisation declares an incident at, or around, the same time. An example of this was the situation on 11 September 2001, when the attacks on the World Trade Center in New York took place. Most organisations had disaster recovery plans, but a number of them relied on the same providers, which completely overwhelmed their capabilities.
Warm standby systems will generally be pre-loaded with operating systems, some or all user applications, and possibly also data up to a certain backup point. This means that the main task is to bring the data fully up to date and this will therefore much reduce the restoration time required.
Warm standby systems are invariably costlier to provide than cold standby, and it is common practice for organisations to use one warm standby system to provide restoration capability for a number of similar systems where this provides an economy of scale. Additionally, those organisations who regularly update their application software may make use of their warm standby systems as training, development and testing platforms before a new or updated application is taken into live service.
Hot standby systems come in several flavours, but increasingly, and especially where no outage time can be tolerated at all, hot standby or high availability systems are becoming the norm. A basic hot standby system will be as similar as possible in design to a warm standby system, except that the data will be fully up to date, requiring a real-time connection between the active and standby systems.
Two slightly different methods of synchronising the systems are in common use – the first (and faster) method is known as asynchronous working, in which the active system simply transmits data to the standby but continues processing without waiting for confirmation that the data has been written to disk. The second, slightly slower (but more reliable) method is known as synchronous working, in which the active system transmits data to the standby and waits for confirmation that the data has been written to disk before it continues processing.
In the first method, there is always the possibility that some data will not be received by the standby system, and in cases where nothing less than 100 per cent reliability is required (for example in financial transactions) this will not be sufficiently robust.
In the second method, there will always be a slight time lag between transactions since this method will provide 100 per cent reliability at the expense of speed. It will also be costlier to implement, since very fast transmission circuits will be required – usually point-to-point optical fibre.
Networks and communications
While the emphasis tends to be on the recovery of key systems, organisations should not overlook the networks and communications technology that support them. Wherever possible, key elements of the communications network should be duplicated so that the failure of one does not cause a total loss of connectivity. Many organisations now use two different transmission providers to ensure that if one has a major network failure, the other should still be able to provide service. This will of course depend on whether one is acting as a carrier for the other, in which case a failure of the main provider’s network could result in the other losing service as well.
Larger organisations make use of load balancing systems to ensure that in peak demands on their websites they are able to spread the load across a number of servers, and many also duplicate their firewall infrastructure as added insurance.
Separacy is also a wise consideration – the scenario in which a road repair takes out an organisation’s communications is all too familiar, and by providing diverse communications cables on routes separated by 30 m or more and using entry points on opposite sides of a building, the likelihood of failure is much reduced.
Naturally, all this costs money, but when compared with the potential losses that would be incurred in the event of a total infrastructure failure, it is a vital form of insurance – and one that can reduce the cost of revenue loss insurance premiums.
In the mid-1990s, the author had arranged to have two fibre optic cables laid between two key buildings about 2 km apart – one cable for normal use, and the second (with a different provider, and diversely routed) to provide resilience, and the chief financial officer (CFO) complained bitterly at the expense. Two days after the installation of both cables had been completed, major roadworks caused a break in the first cable. The routers at either end of the link switched seamlessly to the backup cable with no disruption to service, and the CFO agreed that the cost of the additional cable had been justified.
Power
Power is at the heart of everything. Without it, the systems and networks cannot run, and business would grind very quickly to a halt.
Those organisations that suffer regular power outages will probably already have invested in a standby generator or at least an uninterruptible power supply (UPS) system that will continue to deliver sufficient power for a defined period of time.
More frequently nowadays, the two are combined, so that a UPS system will continue to deliver power and remove any power spikes from the supply, after which the standby generator will cut in and deliver power as long as the fuel supply lasts.
The international standard ISO/IEC 27031:2011 – Information technology – Security techniques – Guidelines for information and communication technology readiness for business continuity covers many aspects of disaster recovery.
Fire prevention and smoke detection
While this may not immediately appear to be a cyber security issue, access to a fire prevention system could affect an organisation’s ability to deliver service. No computer room or data centre would be complete without having smoke detection systems and fire prevention facilities. Systems such as Very Early Smoke Detection Apparatus (VESDA) can identify the release of smoke (and therefore the possibility of fire) before it takes hold and causes real problems.
The system works by sucking air from the area through pipes and sampling the quality of air passing through a laser detection chamber. If the quality falls below acceptable levels, a response can be triggered, and this is often as a result of detection by more than one detector. The gas, normally nowadays an inert gas called Inergen, is discharged to the affected area, and works by reducing the oxygen content to less than 12.5 per cent, at which point combustion cannot occur.
An interesting example of a problem with Inergen was highlighted in September 2016, when ING Bank tested the system in their data centre in Bucharest. The gas discharge produced sound levels in excess of 130 decibels, which caused excessive vibrations and head crashes in disk drives. The entire data centre was out of action for an extended period of time, preventing access to ING’s customers.
1. See www.thebci.org/index.php/resources/the-good-practice-guidelines
2. The RTO is the duration of time within which business processes must be restored after a disruptive incident in order to avoid unacceptable consequences to the business.
3. The MAO is the time a system can be unavailable before its loss will compromise the organisation’s business objectives.
4. The MTDL is the maximum loss of data or information (whether electronic and otherwise) that an organisation can tolerate.