
CHAPTER 18
Security Assessments
This chapter presents the following:
• Test, assessment, and audit strategies
• Testing technical security controls
• Conducting or facilitating security audits
Trust, but verify.
You can hire the best people, develop sound policies and procedures, and deploy world-class technology in an effort to secure your information systems, but if you do not regularly assess the effectiveness of these measures, your organization will not be secure for long. Unfortunately, thousands of well-intentioned organizations have learned the truth of this statement the hard way, realizing only after a security breach has occurred that the state-of-the-art controls they put into place initially have become less effective over time. So, unless your organization is continuously assessing and improving its security posture, that posture will become ineffective over time.
This chapter covers some of the most important elements of security assessments and testing. It is divided into three sections. We start by discussing assessment, test, and audit strategies, particularly how to design and assess them. From there, we get into the nitty-gritty of various common forms of testing with which you should be familiar. The third and final section discusses the various kinds of formal security audits and how you can conduct or facilitate them.
Test, Assessment, and Audit Strategies
Let’s start by establishing some helpful definitions in the context of information systems security. A test is a procedure that records some set of properties or behaviors in a system being tested and compares them against predetermined standards. If you install a new device on your network, you might want to test its attack surface by running a network scanner against it, recording the open ports, and then comparing them against the appropriate security standards used in your organization. An assessment is a series of planned tests that are somehow related to each other. For example, we could conduct a vulnerability assessment against a new software system to determine how secure it is. This assessment would include some specific (and hopefully relevant) vulnerability tests together with static and dynamic analysis of its software. An audit is a systematic assessment of significant importance to the organization that determines whether the system or process being audited satisfies some external standards. By “external” we mean that the organization being audited did not author the standards all by itself.
 EXAM TIP
EXAM TIP
You don’t have to memorize these definitions. They are presented simply to give you an idea of the different scopes. Many security professionals use the terms almost interchangeably.
Each of these three types of system evaluations plays an important role in ensuring the security of our organizations. Our job as cybersecurity leaders is to integrate them into holistic strategies that, when properly executed, give us a complete and accurate picture of our security posture. It all starts with the risk management concepts we discussed in Chapter 2. Remember that risks determine which security controls we use, which are the focus of any tests, assessments, or audits we perform. So, a good security assessment strategy verifies that we are sufficiently protected against the risks we’re tracking.
The security assessment strategy guides the development of standard testing and assessment procedures. This standardization is important because it ensures these activities are done in a consistent, repeatable, and cost-effective manner. We’ll cover testing procedures later in this chapter, so let’s take a look at how to design and validate a security assessment.
Designing an Assessment
The first step in designing anything is to figure out what it is that we are trying to accomplish. Are we getting ready for an external audit? Did we suffer a security incident because a control was not properly implemented? The answers to these sample questions point to significantly different types of assessment. In the first case, the assessment would be a very broad effort to verify an external standard with which we are supposed to be compliant. In the second case, the assessment would be focused on a specific control, so it would be much narrower in scope. Let’s elaborate on the second case as we develop a notional assessment plan.
Suppose the security incident happened because someone clicked a link on a phishing e-mail and downloaded malware that the endpoint detection and response (EDR) solution was able to block. The EDR solution worked fine, but we are now concerned about our e-mail security controls. The objective of our assessment, therefore, is to determine the effectiveness of our e-mail defenses.
Once we have the objective identified, we can determine the necessary scope to accomplish it. When we talk about the scope of an assessment, we really mean which specific controls we will test. In our example, we would probably want to look at our e-mail security gateway, but we should also look at our staff members’ security awareness. Next, we have to decide how many e-mail messages and how many users we need to assess to have confidence in our results.
The scope, in turn, informs the methods we use. We’ll cover some of the testing techniques shortly, but it’s important to note that it’s not just what we do but how we do it that matters. We should develop standardized methodologies so that different tests are consistent and comparable. Otherwise, we won’t necessarily know whether our posture is deteriorating from one assessment to the next.
Another reason to standardize the methodologies is to ensure we take into account business and operational impacts. For example, if we decide to test the e-mail security gateway using a penetration test, then there is a chance that we will interfere with e-mail service availability. This could present operational risks that we need to mitigate. Furthermore, on the off-chance that we break something during our assessment, we need to have a contingency plan that allows for the quick restoration of all services and capabilities.
A key decision is whether the assessment will be performed by an internal team or by a third party. If you don’t have the in-house expertise, then this decision may very well already have been made for you. But even if your team has this expertise, you may still choose to bring in external auditors for any of a variety of reasons. For example, there may be a regulatory requirement that an external party test your systems; or you may want to benchmark your own internal assets against an external team; or perhaps your own team of testers is not large enough to cover all the auditing requirements and thus you want to bring in outside help.
Finally, once the assessment plan is complete, we need to get it approved for execution. This doesn’t just involve our direct bosses but should also involve any stakeholders that might be affected (especially if something goes wrong and services are interrupted). The approval is not just for the plan itself, but also for any needed resources (e.g., funding for an external assessor) as well as for the scheduling. There is nothing worse than to schedule a security assessment that we later find out coincides with a big event like end-of-month accounting and reporting.
Validating an Assessment
Once the tests are over and the interpretation and prioritization are done, management will have in its hands a compilation of many of the ways the organization could be successfully attacked. This is the input to the next cycle in the remediation strategy. Every organization has only so much money, time, and personnel to commit to defending its network, and thus can mitigate only so much of the total risk. After balancing the risks and risk appetite of the organization and the costs of possible mitigations and the value gained from each, management must direct the system and security administrators as to where to spend those limited resources. An oversight program is required to ensure that the mitigations work as expected and that the estimated cost of each mitigation action is closely tracked by the actual cost of implementation. Any time the cost rises significantly or the value is found to be far below what was expected, the process should be briefly paused and reevaluated. It may be that a risk-versus-cost option initially considered less desirable now makes more sense than continuing with the chosen path.
Finally, when all is well and the mitigations are underway, everyone can breathe easier…except the security engineer who has the task of monitoring vulnerability announcements and discussion mailing lists, as well as the early warning services offered by some vendors. To put it another way, the risk environment keeps changing. Between tests, monitoring may make the organization aware of newly discovered vulnerabilities that would be found the next time the test is run but that are too high risk to allow to wait that long. And so another, smaller cycle of mitigation decisions and actions must be taken, and then it is time to run the tests again.
Table 18-1 provides an example of a testing schedule that each operations and security department should develop and carry out.

Table 18-1 Example Testing Schedules for Each Operations and Security Department
Testing Technical Controls
A technical control is a security control implemented through the use of an IT asset. This asset is usually, but not always, some sort of software or hardware that is configured in a particular way. When we test our technical controls, we are verifying their ability to mitigate the risks that we identified in our risk management process (see Chapter 2 for a detailed discussion). This linkage between controls and the risks they are meant to mitigate is important because we need to understand the context in which specific controls were implemented.
Once we understand what a technical control was intended to accomplish, we are able to select the proper means of testing whether it is being effective. We may be better off testing third-party software for vulnerabilities than attempting a code review. As security professionals, we must be familiar, and ideally experienced, with the most common approaches to testing technical controls so that we are able to select the right one for the job at hand.
Vulnerability Testing
Vulnerability testing, whether manual, automated, or—preferably—a combination of both, requires staff and/or consultants with a deep security background and the highest level of trustworthiness. Even the best automated vulnerability scanning tool will produce output that can be misinterpreted as crying wolf (false positive) when there is only a small puppy in the room, or alert you to something that is indeed a vulnerability but that either does not matter to your environment or is adequately compensated for elsewhere. There may also be two individual vulnerabilities that exist, which by themselves are not very important but when put together are critical. And, of course, false negatives will also crop up, such as an obscure element of a single vulnerability that matters greatly to your environment but is not called out by the tool.
 NOTE
NOTE
Before carrying out vulnerability testing, a written agreement from management is required! This protects the tester against prosecution for doing his job and ensures there are no misunderstandings by providing in writing what the tester should—and should not—do.
The goals of the assessment are to
• Evaluate the true security posture of an environment (don’t cry wolf, as discussed earlier).
• Identify as many vulnerabilities as possible, with honest evaluations and prioritizations of each.
• Test how systems react to certain circumstances and attacks, to learn not only what the known vulnerabilities are (such as this version of the database, that version of the operating system, or a user ID with no password set) but also how the unique elements of the environment might be abused (SQL injection attacks, buffer overflows, and process design flaws that facilitate social engineering).
• Before the scope of the test is decided and agreed upon, the tester must explain the testing ramifications. Vulnerable systems could be knocked offline by some of the tests, and production could be negatively affected by the loads the tests place on the systems.
Management must understand that results from the test are just a “snapshot in time.” As the environment changes, new vulnerabilities can arise. Management should also understand that various types of assessments are possible, each one able to expose different kinds of vulnerabilities in the environment, and each one limited in the completeness of results it can offer:
• Personnel testing includes reviewing employee tasks and thus identifying vulnerabilities in the standard practices and procedures that employees are instructed to follow, demonstrating social engineering attacks and the value of training users to detect and resist such attacks, and reviewing employee policies and procedures to ensure those security risks that cannot be reduced through physical and logical controls are met with the final control category: administrative.
• Physical testing includes reviewing facility and perimeter protection mechanisms. For instance, do the doors actually close automatically, and does an alarm sound if a door is held open too long? Are the interior protection mechanisms of server rooms, wiring closets, sensitive systems, and assets appropriate? (For example, is the badge reader working, and does it really limit access to only authorized personnel?) Is dumpster diving a threat? (In other words, is sensitive information being discarded without proper destruction?) And what about protection mechanisms for manmade, natural, or technical threats? Is there a fire suppression system? Does it work, and is it safe for the people and the equipment in the building? Are sensitive electronics kept above raised floors so they survive a minor flood? And so on.
• System and network testing are perhaps what most people think of when discussing information security vulnerability testing. For efficiency, an automated scanning product identifies known system vulnerabilities, and some may (if management has signed off on the performance impact and the risk of disruption) attempt to exploit vulnerabilities.
Because a security assessment is a point-in-time snapshot of the state of an environment, assessments should be performed regularly. Lower-priority, better-protected, and less-at-risk parts of the environment may be scanned once or twice a year. High-priority, more vulnerable targets, such as e-commerce web server complexes and the middleware just behind them, should be scanned nearly continuously.
To the degree automated tools are used, more than one tool—or a different tool on consecutive tests—should be used. No single tool knows or finds every known vulnerability. The vendors of different scanning tools update their tools’ vulnerability databases at different rates, and may add particular vulnerabilities in different orders. Always update the vulnerability database of each tool just before the tool is used. Similarly, from time to time different experts should run the test and/or interpret the results. No single expert always sees everything there is to be seen in the results.
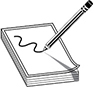
Most networks consist of many heterogeneous devices, each of which will likely have its own set of potential vulnerabilities, as shown in Figure 18-1. The potential issues we would seek in, say, the perimeter router (“1.” in Figure 18-1) are very different than those in a wireless access point (WAP) (“7.” in Figure 18-1) or a back-end database management server (DBMS) (“11.” in Figure 18-1). Vulnerabilities in each of these devices, in turn, will depend on the specific hardware, software, and configurations in use. Even if you were able to find an individual or tool who had expert knowledge on the myriad of devices and device-specific security issues, that person or tool would come with its own inherent biases. It is best to leverage team/tool heterogeneity in order to improve the odds of covering blind spots.
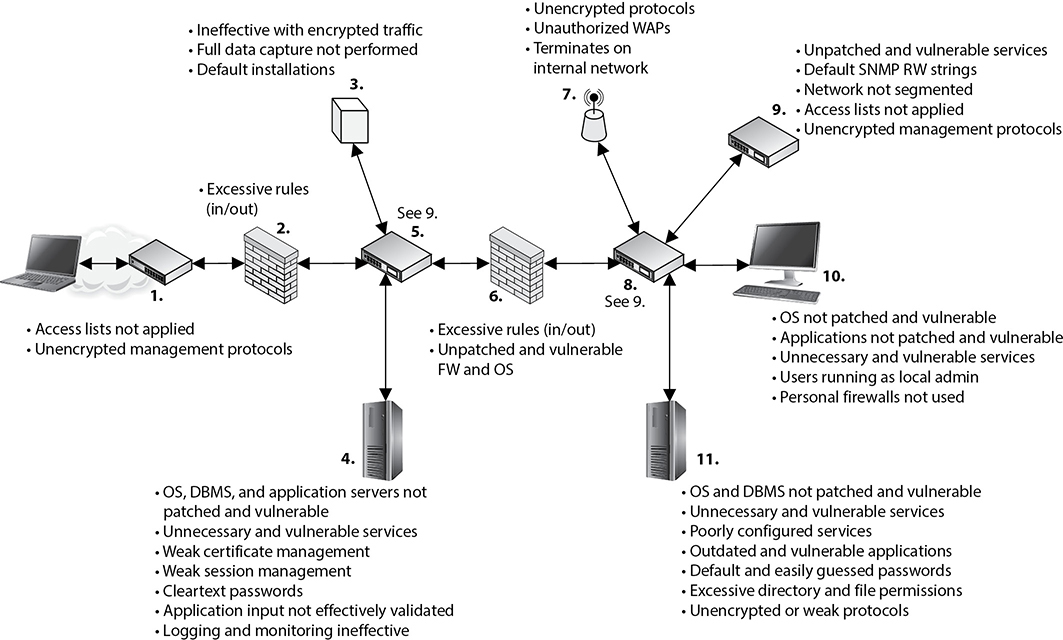
Figure 18-1 Vulnerabilities in heterogeneous networks
Other Vulnerability Types
As noted earlier, vulnerability scans find the potential vulnerabilities. Penetration testing is required to identify those vulnerabilities that can actually be exploited in the environment and cause damage.
Commonly exploited vulnerabilities include the following:
• Kernel flaws These are problems that occur below the level of the user interface, deep inside the operating system. Any flaw in the kernel that can be reached by an attacker, if exploitable, gives the attacker the most powerful level of control over the system.
Countermeasure: Ensure that security patches to operating systems—after sufficient testing—are promptly deployed in the environment to keep the window of vulnerability as small as possible.
• Buffer overflows Poor programming practices, or sometimes bugs in libraries, allow more input than the program has allocated space to store it. This overwrites data or program memory after the end of the allocated buffer, and sometimes allows the attacker to inject program code and then cause the processor to execute it. This gives the attacker the same level of access as that held by the program that was attacked. If the program was run as an administrative user or by the system itself, this can mean complete access to the system.
Countermeasure: Good programming practices and developer education, automated source code scanners, enhanced programming libraries, and strongly typed languages that disallow buffer overflows are all ways of reducing this extremely common vulnerability.
• Symbolic links Though the attacker may be properly blocked from seeing or changing the content of sensitive system files and data, if a program follows a symbolic link (a stub file that redirects the access to another place) and the attacker can compromise the symbolic link, then the attacker may be able to gain unauthorized access. (Symbolic links are used in Unix and Linux systems.) This may allow the attacker to damage important data and/or gain privileged access to the system. A historical example of this was to use a symbolic link to cause a program to delete a password database, or replace a line in the password database with characters that, in essence, created a password-less root-equivalent account.
Countermeasure: Programs, and especially scripts, must be written to ensure that the full path to the file cannot be circumvented.
• File descriptor attacks File descriptors are numbers many operating systems use to represent open files in a process. Certain file descriptor numbers are universal, meaning the same thing to all programs. If a program makes unsafe use of a file descriptor, an attacker may be able to cause unexpected input to be provided to the program, or cause output to go to an unexpected place with the privileges of the executing program.
Countermeasure: Good programming practices and developer education, automated source code scanners, and application security testing are all ways of reducing this type of vulnerability.
• Race conditions Race conditions exist when the design of a program puts it in a vulnerable condition before ensuring that those vulnerable conditions are mitigated. Examples include opening temporary files without first ensuring the files cannot be read or written to by unauthorized users or processes, and running in privileged mode or instantiating dynamic link library (DLL) functions without first verifying that the DLL path is secure. Either of these may allow an attacker to cause the program (with its elevated privileges) to read or write unexpected data or to perform unauthorized commands. An example of a race condition is a time-of-check to time-of-use (TOC/TOU) attack, discussed in Chapter 2.
Countermeasure: Good programming practices and developer education, automated source code scanners, and application security testing are all ways of reducing this type of vulnerability.
• File and directory permissions Many of the previously described attacks rely on inappropriate file or directory permissions—that is, an error in the access control of some part of the system, on which a more secure part of the system depends. Also, if a system administrator makes a mistake that results in decreasing the security of the permissions on a critical file, such as making a password database accessible to regular users, an attacker can take advantage of this to add an unauthorized user to the password database or an untrusted directory to the DLL search path.
Countermeasure: File integrity checkers, which should also check expected file and directory permissions, can detect such problems in a timely fashion, hopefully before an attacker notices and exploits them.
Many, many types of vulnerabilities exist, and we have covered some, but certainly not all, here in this book. The previous list includes only a few specific vulnerabilities you should be aware of for exam purposes.
Penetration Testing
Penetration testing (also known as pen testing) is the process of simulating attacks on a network and its systems at the request of the owner, senior management. Penetration testing uses a set of procedures and tools designed to test and possibly bypass the security controls of a system. Its goal is to measure an organization’s level of resistance to an attack and to uncover any exploitable weaknesses within the environment. Organizations need to determine the effectiveness of their security measures and not just trust the promises of the security vendors. Good computer security is based on reality, not on some lofty goals of how things are supposed to work.
A penetration test emulates the same methods attackers would use. Attackers can be clever, creative, and resourceful in their techniques, so penetration test attacks should align with the newest hacking techniques along with strong foundational testing methods. The test should look at each and every computer in the environment, as shown in Figure 18-2, because an attacker will not necessarily scan one or two computers only and call it a day.
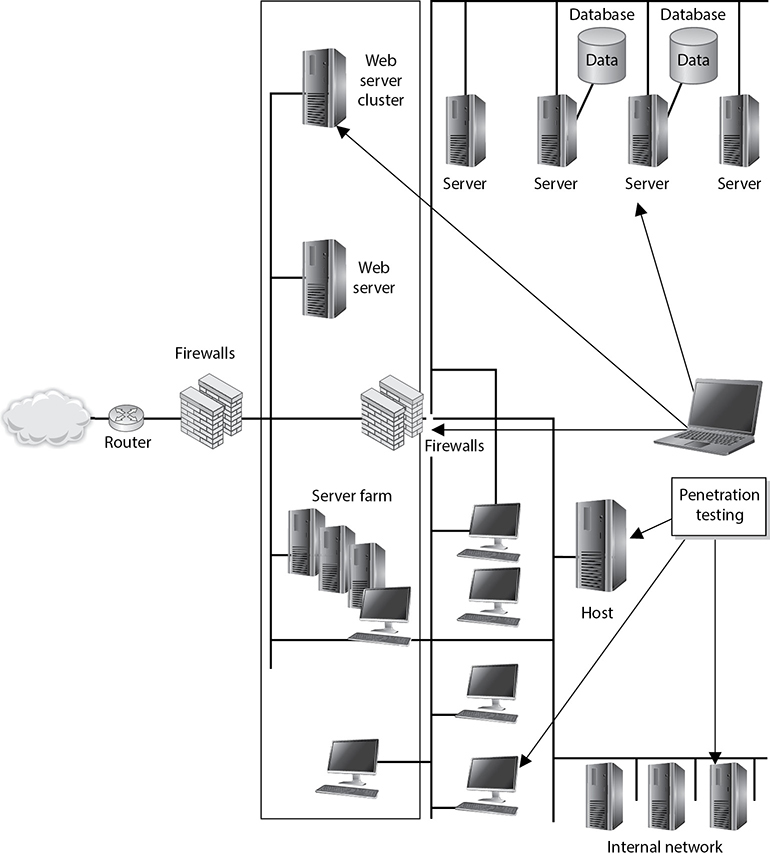
Figure 18-2 Penetration testing is used to prove an attacker can actually compromise systems.
The type of penetration test that should be used depends on the organization, its security objectives, and the management’s goals. Some organizations perform periodic penetration tests on themselves using different types of tools. Other organizations ask a third party to perform the vulnerability and penetration tests to provide a more objective view.
Penetration tests can evaluate web servers, Domain Name System (DNS) servers, router configurations, workstation vulnerabilities, access to sensitive information, open ports, and available services’ properties that a real attacker might use to compromise the organization’s overall security. Some tests can be quite intrusive and disruptive. The timeframe for the tests should be agreed upon so productivity is not affected and personnel can bring systems back online if necessary.
NOTE
Penetration tests are not necessarily restricted to information technology, but may include physical security as well as personnel security. Ultimately, the purpose is to compromise one or more controls, which could be technical, physical, or administrative.
The result of a penetration test is a report given to management that describes the vulnerabilities identified and the severity of those vulnerabilities, along with descriptions of how they were exploited by the testers. The report should also include suggestions on how to deal with the vulnerabilities properly. From there, it is up to management to determine how to address the vulnerabilities and what countermeasures to implement.
It is critical that senior management be aware of any risks involved in performing a penetration test before it gives the authorization for one. In rare instances, a system or application may be taken down inadvertently using the tools and techniques employed during the test. As expected, the goal of penetration testing is to identify vulnerabilities, estimate the true protection the security mechanisms within the environment are providing, and see how suspicious activity is reported—but accidents can and do happen.
Security professionals should obtain an authorization letter that includes the extent of the testing authorized, and this letter or memo should be available to members of the team during the testing activity. This type of letter is commonly referred to as a “Get Out of Jail Free Card.” Contact information for key personnel should also be available, along with a call tree in the event something does not go as planned and a system must be recovered.
NOTE
A “Get Out of Jail Free Card” is a document you can present to someone who thinks you are up to something malicious, when in fact you are carrying out an approved test. More than that, it’s also the legal agreement you have between you and your customer that protects you from liability, and prosecution.
When performing a penetration test, the team goes through a five-step process:
1. Discovery Footprinting and gathering information about the target
2. Enumeration Performing port scans and resource identification methods
3. Vulnerability mapping Identifying vulnerabilities in identified systems and resources
4. Exploitation Attempting to gain unauthorized access by exploiting vulnerabilities
5. Report to management Delivering to management documentation of test findings along with suggested countermeasures

The penetration testing team can have varying degrees of knowledge about the penetration target before the tests are actually carried out:
• Zero knowledge The team does not have any knowledge of the target and must start from ground zero.
• Partial knowledge The team has some information about the target.
• Full knowledge The team has intimate knowledge of the target.
Security testing of an environment may take several forms, in the sense of the degree of knowledge the tester is permitted to have up front about the environment, and also the degree of knowledge the environment is permitted to have up front about the tester.
Tests can be conducted externally (from a remote location) or internally (meaning the tester is within the network). Combining both can help better understand the full scope of threats from either domain (internal and external).
Penetration tests may be blind, double-blind, or targeted. A blind test is one in which the testers only have publicly available data to work with (which is also known as zero knowledge or black box testing). The network security staff is aware that this type of test will take place, and will be on the lookout for pen tester activities. Part of the planning for this type of test involves determining what actions, if any, the defenders are allowed to take. Stopping every detected attack will slow down the pen testing team and may not show the depths they could’ve reached without forewarning to the staff.
A double-blind test (stealth assessment) is also a blind test to the assessors, as mentioned previously, but in this case the network security staff is not notified. This enables the test to evaluate the network’s security level and the staff’s responses, log monitoring, and escalation processes, and is a more realistic demonstration of the likely success or failure of an attack.
Targeted tests can involve external consultants and internal staff carrying out focused tests on specific areas of interest. For example, before a new application is rolled out, the team might test it for vulnerabilities before installing it into production. Another example is to focus specifically on systems that carry out e-commerce transactions and not the other daily activities of the organization.
It is important that the team start off with only basic user-level access to properly simulate different attacks. The team needs to utilize a variety of different tools and attack methods and look at all possible vulnerabilities because actual attackers only need to find one vulnerability that the defenders missed.
Red Teaming
While penetration testing is intended to uncover as many exploitable vulnerabilities as possible in the allotted time, it doesn’t really emulate threat actor behaviors all that well. Adversaries almost always have very specific objectives when they attack, so just because your organization passed its pen test doesn’t mean there isn’t a creative way for adversaries to get in. Red teaming is the practice of emulating a specific threat actor (or type of threat actor) with a particular set of objectives. Whereas pen testing answers the question “How many ways can I get in?” red teaming answers the question “How can I get in and accomplish this objective?”
Red teaming more closely mimics the operational planning and attack processes of advanced threat actors that have the time, means, and motive to defeat even advanced defenses and remain undetected for long periods of time. A red team operation begins by determining the adversary to be emulated and a set of objectives. The red team then conducts reconnaissance (typically with a bit of insider help) to understand how the systems work and locate the team’s objectives. The next step is to draw up a plan on how to accomplish the objectives while remaining undetected. In the more elaborate cases, the red team may create a replica of the target environment inside a cyber range in which to perform mission rehearsals and ensure the team’s actions will not trigger any alerts. Finally, the red team launches the attack on the actual system and tries to reach its objectives.
As you can imagine, red teaming as described here is very costly and beyond the reach of all but the most well-resourced organizations. Most often, what you’ll see is a hybrid approach that is more focused than pen testing but less intense than red teaming. We all have to do what we can with the resources we have. This is why many organizations (even very small ones) establish an internal red team that periodically comes together to think like an adversary would about some aspect of the business. It could be a new or critical information system, or a business process, or even a marketing campaign. Their job is to ask the question “If we were adversaries, how would we exploit this aspect of the business?”
EXAM TIP
Don’t worry about differentiating penetration testing and red teaming during the exam. If the term “red team” shows up on your test, it will most likely describe the group of people who conduct both penetration tests and red teaming.
Breach Attack Simulations
One of the problems with both pen testing and red teaming is that they amount to a point-in-time snapshot of the organizational defenses. Just because your organization did very well against the penetration testers last week doesn’t necessarily mean it would do well against a threat actor today. There are many reasons for this, but the two most important ones are that things change and the test (no matter how long it takes) is never 100 percent thorough. What would be helpful as a complement to human testing would be automated testing that could happen periodically or even continually.
Breach and attack simulations (BAS) are automated systems that launch simulated attacks against a target environment and then generate reports on their findings. They are meant to be realistic but not cause any adverse effect to the target systems. For example, a ransomware simulation might use “defanged” malware that looks and propagates just like the real thing but, when successful, will only encrypt a sample file on a target host as a proof of concept. Its signature should be picked up by your network detection and response (NDR) or your endpoint detection and response (EDR) solutions. Its communications with a command-and-control (C2) system via the Internet will follow the same processes that the real thing would. In other words, each simulation is very realistic and meant to test your ability to detect and respond to it.
BAS is typically offered as a Software as a Service (SaaS) solution. All the tools, automation, and reporting take place in the provider’s cloud. BAS agents can also be deployed in the target environment for better coverage under an assumed breach scenario. This covers the cases in which the adversary breached your environment using a zero-day exploit or some other mechanism that successfully evaded your defenses. In that case, you’re trying to determine how well your defense in depth is working.
Log Reviews
A log review is the examination of system log files to detect security events or to verify the effectiveness of security controls. Log reviews actually start way before the first event is examined by a security specialist. In order for event logs to provide meaningful information, they must capture a very specific but potentially large amount of information that is grounded on both industry best practices and the organization’s risk management process. There is no one-size-fits-all set of event types that will help you assess your security posture. Instead, you need to constantly tune your systems in response to the ever-changing threat landscape.
Another critical element when setting up effective log reviews for an organization is to ensure that time is standardized across all networked devices. If an incident affects three devices and their internal clocks are off by even a few seconds, then it will be significantly more difficult to determine the sequence of events and understand the overall flow of the attack. Although it is possible to normalize differing timestamps, it is an extra step that adds complexity to an already challenging process of understanding an adversary’s behavior on our networks. Standardizing and synchronizing time is not a difficult thing to do. The Network Time Protocol (NTP) version 4, described in RFC 5905, is the industry standard for synchronizing computer clocks between networked devices.
Now that you have carefully defined the events you want to track and ensured all timestamps are synchronized across your network, you still need to determine where the events will be stored. By default, most log files are stored locally on the corresponding device. The challenge with this approach is that it makes it more difficult to correlate events across devices to a given incident. Additionally, it makes it easier for attackers to alter the log files of whatever devices they compromise. By centralizing the location of all log files across the organization, you address both issues and also make it easier to archive the logs for long-term retention.
Efficient archiving is important because the size of these logs will likely be significant. In fact, unless your organization is extremely small, you will likely have to deal with thousands (or perhaps even millions) of events each day. Most of these are mundane and probably irrelevant, but we usually don’t know which events are important and which aren’t until we’ve done some analysis. In many investigations, the seemingly unimportant events of days, weeks, or even months ago turn out to be the keys to understanding a security incident. So while retaining as much as possible is necessary, we need a way to quickly separate the wheat from the chaff.
The Network Time Protocol (NTP) is one of the oldest protocols used on the Internet and is still in widespread use today. It was originally developed in the 1980s in part to solve the problem of synchronizing trans-Atlantic network communications. Its current version, 4, still leverages statistical analysis of round-trip delays between a client and one or more time servers. The time itself is sent in a UDP datagram that carries a 64-bit timestamp on port 123.
Despite its client/server architecture, NTP employs a hierarchy of time sources organized into strata, with stratum 0 being the most authoritative. A network device on a lower stratum acts as a client to a server on a higher stratum, but could itself be a server to a node further downstream from it. Furthermore, nodes on the same stratum can and often do communicate with each other to improve the accuracy of their times.
Stratum 0 consists of highly accurate time sources such as atomic clocks, global positioning system (GPS) clocks, or radio clocks. Stratum 1 consists of primary time sources, typically network appliances with highly accurate internal clocks that are connected directly to a stratum 0 source. Stratum 2 is where you would normally see your network servers, such as your local NTP servers and your domain controllers. Stratum 3 can be thought of as other servers and the client computers on your network, although the NTP standard does not define this stratum as such. Instead, the standard allows for a hierarchy of up to 16 strata wherein the only requirement is that each strata gets its time from the higher one and serves time to the lower strata if it has any.

Fortunately, many solutions, both commercial and free, now exist for analyzing and managing log files and other important event artifacts. Security information and event management (SIEM) systems enable the centralization, correlation, analysis, and retention of event data in order to generate automated alerts. Typically, a SIEM provides a dashboard interface that highlights possible security incidents. It is then up to the security specialists to investigate each alert and determine if further action is required. The challenge, of course, is ensuring that the number of false positives is kept fairly low and that the number of false negatives is kept even lower.
Synthetic Transactions
Many of our information systems operate on the basis of transactions. A user (typically a person) initiates a transaction that could be anything from a request for a given web page to a wire transfer of half a million dollars to an account in Switzerland. This transaction is processed by any number of other servers and results in whatever action the requestor wanted. This is considered a real transaction. Now suppose that a transaction is not generated by a person but by a script. This is considered a synthetic transaction.
The usefulness of synthetic transactions is that they allow us to systematically test the behavior and performance of critical services. Perhaps the simplest example is a scenario in which you want to ensure that your home page is up and running. Rather than waiting for an angry customer to send you an e-mail saying that your home page is unreachable, or spending a good chunk of your day visiting the page on your browser, you could write a script that periodically visits your home page and ensures that a certain string is returned. This script could then alert you as soon as the page is down or unreachable, allowing you to investigate before you would’ve otherwise noticed it. This could be an early indicator that your web server was hacked or that you are under a distributed denial-of-service (DDoS) attack.
Synthetic transactions can do more than simply tell you whether a service is up or down. They can measure performance parameters such as response time, which could alert you to network congestion or server overutilization. They can also help you test new services by mimicking typical end-user behaviors to ensure the system works as it ought to. Finally, these transactions can be written to behave as malicious users by, for example, attempting a cross-site scripting (XSS) attack and ensuring your controls are effective. This is an effective way of testing software from the outside.
Code Reviews
So far, all the security testing we have discussed looks at the behaviors of our systems. This means that we are only assessing the externally visible features without visibility into the inner workings of the system. If you want to test your own software system from the inside, you could use a code review, a systematic examination of the instructions that comprise a piece of software, performed by someone other than the author of that code. This approach is a hallmark of mature software development processes. In fact, in many organizations, developers are not allowed to push out their software modules until someone else has signed off on them after doing a code review. Think of this as proofreading an important document before you send it to an important person. If you try to proofread it yourself, you will probably not catch all those embarrassing typos and grammatical errors as easily as someone else could who is checking it for you.
Code reviews go way beyond checking for typos, though that is certainly one element of it. It all starts with a set of coding standards developed by the organization that wrote the software. This could be an internal team, an outsourced developer, or a commercial vendor. Obviously, code reviews of commercial off-the-shelf (COTS) software are extremely rare unless the software is open source or you happen to be a major government agency. Still, each development shop will have a style guide or a set of documented coding standards that covers everything from how to indent the code to when and how to use existing code libraries. So a preliminary step to the code review is to ensure the author followed the team’s style guide or standards. In addition to helping the maintainability of the software, this step gives the code reviewer a preview of the magnitude of the work ahead; a sloppy coder will probably have a lot of other, harder-to-find defects in his code.
After checking the structure and format of the code, the reviewer looks for uncalled or unneeded functions or procedures. These lead to “code bloat,” which makes it harder to maintain and secure the application. For this same reason, the reviewer looks for modules that are excessively complex and should be restructured or split into multiple routines. Finally, in terms of reducing complexity, the reviewer looks for blocks of repeated code that could be refactored. Even better, these could be pulled out and turned into external reusable components such as library functions.
An extreme example of unnecessary (and dangerous) procedures are the code stubs and test routines that developers often include in their developmental software. There have been too many cases in which developers left test code (sometimes including hard-coded credentials) in final versions of software. Once adversaries discover this condition, exploiting the software and bypassing security controls is trivial. This problem is insidious, because developers sometimes comment out the code for final testing, just in case the tests fail and they have to come back and rework it. They may make a mental note to revisit the file and delete this dangerous code, but then forget to do so. While commented code is unavailable to an attacker after a program is compiled (unless they have access to the source code), the same is not true of the scripts that are often found in distributed applications.
Defensive programming is a best practice that all software development operations should adopt. In a nutshell, it means that as you develop or review the code, you are constantly looking for opportunities for things to go badly. Perhaps the best example of defensive programming is the practice of treating all inputs, whether they come from a keyboard, a file, or the network, as untrusted until proven otherwise. This user input validation can be a bit trickier than it sounds, because you must understand the context surrounding the input. Are you expecting a numerical value? If so, what is the acceptable range for that value? Can this range change over time? These and many other questions need to be answered before we can decide whether the inputs are valid. Keep in mind that many of the oft-exploited vulnerabilities we see have a lack of input validation as their root cause.
Code Testing
We will discuss in Chapters 24 and 25 the multiple types of tests to which we must subject our code as part of the software development process. However, once the code comes out of development and before we put it into a production environment, we must ensure that it meets our security policies. Does it encrypt all data in transit? Is it possible to bypass authentication or authorization controls? Does it store sensitive data in unencrypted temporary files? Does it reach out to any undocumented external resources (e.g., for library updates)? The list goes on, but the point is that security personnel are incentivized differently than software developers. The programmer gets paid to implement features in software, while the security practitioner gets paid to keep systems secure.
Most mature organizations have an established process to certify that software systems are secure enough to be installed and operated on their networks. There is typically a follow-on to that process, which is when a senior manager (hopefully after reading the results of the certification) authorizes (or accredits) the system.
Misuse Case Testing
Use cases are structured scenarios that are commonly used to describe required functionality in an information system. Think of them as stories in which an external actor (e.g., a user) wants to accomplish a given goal on the system. The use case describes the sequence of interactions between the actor and the system that result in the desired outcome. Use cases are textual but are often summarized and graphically depicted using a Unified Modeling Language (UML) use case diagram such as the one shown in Figure 18-3. This figure illustrates a very simple view of a system in which a customer places online orders. According to the UML, actors such as our user are depicted using stick figures, and the actors’ use cases are depicted as verb phrases inside ovals. Use cases can be related to one another in a variety of ways, which we call associations. The most common ways in which use cases are associated are by including another use case (that is, the included use case is always executed when the preceding one is) or by extending a use case (meaning that the second use case may or may not be executed depending on a decision point in the main use case). In Figure 18-3, our customer attempts to place an order and may be prompted to log in if she hasn’t already done so, but she will always be asked to provide her credit card information.
Figure 18-3 UML use case diagram
While use cases are very helpful in analyzing requirements for the normal or expected behavior of a system, they are not particularly useful for assessing its security. That is what misuse cases do for us. A misuse case is a use case that includes threat actors and the tasks they want to perform on the system. Threat actors are normally depicted as stick figures with shaded heads and their actions (or misuse cases) are depicted as shaded ovals, as shown in Figure 18-4. As you can see, the attacker in this scenario is interested in guessing passwords and stealing credit card information.

Figure 18-4 UML misuse case diagram
Misuse cases introduce new associations to our UML diagram. The threat actor’s misuse cases are meant to threaten a specific portion or legitimate use case of our system. You will typically see shaded ovals connected to unshaded ones with an arrow labeled <<threaten>> to denote this relationship. On the other hand, system developers and security personnel can implement controls that mitigate these misuses. These create new unshaded ovals connected to shaded ones with arrows labeled <<mitigate>>.
The idea behind misuse case testing is to ensure we have effectively addressed each of the risks we identified and decided to mitigate during our risk management process and that are applicable to the system under consideration. This doesn’t mean that misuse case testing needs to include all the possible threats to our system, but it should include the ones we decided to address. This process forces system developers and integrators to incorporate the products of our risk management process into the early stages of any system development effort. It also makes it easier to quickly step through a complex system and ensure that effective security controls are in the right places without having to get deep into the source code, which is what we describe next.
Test Coverage
Test coverage is a measure of how much of a system is examined by a specific test (or group of tests), which is typically expressed as a percentage. For example, if you are developing a software system with 1,000 lines of code and your suite of unit tests executes 800 of those, then you would have 80 percent test coverage. Why wouldn’t we just go for 100 percent? Because it likely would be too expensive for the benefit we would get from it. We normally only see this full coverage being required in safety-critical systems like those used in aviation and medical devices.
Test coverage also applies to things other than software. Suppose you have 100 security controls in your organization. Testing all of them in one assessment or audit may be too disruptive or expensive (or both), so you schedule smaller evaluations throughout the year. Each quarter, for instance, you run an assessment with tests for one quarter of the controls. In this situation, your quarterly test coverage is 25 percent but your annual coverage is 100 percent.
Interface Testing
When we think of interfaces, we usually envision a graphical user interface (GUI) for an application. While GUIs are one kind of interface, there are others that are potentially more important. At its essence, an interface is an exchange point for data between systems and/or users. You can see this in your computer’s network interface card (NIC), which is the exchange point for data between your computer (a system) and the local area network (another system). Another example of an interface is an application programming interface (API), a set of points at which a software system (e.g., the application) exchanges information with another software system (e.g., the libraries).
Interface testing is the systematic evaluation of a given set of these exchange points. This assessment should include both known good exchanges and known bad exchanges in order to ensure the system behaves correctly at both ends of the spectrum. The real rub is in finding test cases that are somewhere in between. In software testing, these are called boundary conditions because they lie at the boundary that separates the good from the bad. For example, if a given packet should contain a payload of no more than 1024 bytes, how would the system behave when presented with 1024 bytes plus one bit (or byte) of data? What about exactly 1024 bytes? What about 1024 bytes minus one bit (or byte) of data? As you can see, the idea is to flirt with the line that separates the good from the bad and see what happens when we get really close to it.
There are many other test cases we could consider, but the most important lesson here is that the primary task of interface testing is to dream up all the test cases ahead of time, document them, and then insert them into a repeatable and (hopefully) automated test engine. This way you can ensure that as the system evolves, a specific interface is always tested against the right set of test cases. We will talk more about software testing in Chapter 24, but for now you should remember that interface testing is a special case of something called integration testing, which is the assessment of how different parts of a system interact with each other.
Compliance Checks
We have framed our discussion of security tests in terms of evaluating the effectiveness of our technical controls. That really should be our first concern. However, many of us work in organizations that must comply with some set of regulations. If you are not in a (formally) regulated sector, you may still have regulations or standards with which you voluntarily comply. Finally, if you have an information security management system (ISMS) in place like we discussed in Chapter 1 (and you really should), you want to ensure the controls that are listed in there are actually working. In any of these three cases you can use the testing techniques we’ve discussed to demonstrate compliance.
Compliance checks are point-in-time verifications that specific security controls are implemented and performing as expected. For example, your organization may process payment card transactions for its customers and, as such, be required by PCI DSS to run annual penetration tests and quarterly vulnerability scans by an approved vendor. Your compliance checks would be the reports for each of these tests. Or, you may have an SPF record check as one of the e-mail security controls in your ISMS. (Recall from Chapter 13 that the Sender Policy Framework mitigates the risk of forged e-mail sources.) You could perform a log review to perform and document a compliance check on that control. If your e-mail server performed SPF checks on all e-mail messages in a selected portion of its logs, then you know the control is in place and performing as expected.
Conducting Security Audits
While compliance checks are point-in-time tests, audits tend to cover a longer period of time. The question is not “Is this control in place and working?” but rather “Has this control been in place for the last year?” Audits, of course, can leverage compliance checks. In the SPF record check example at the end of the previous section, the auditor would simply look through the compliance checks and, if they were performed and documented regularly, use those as evidence of compliance during an audit.
As simple as it sounds, establishing a clear set of goals is probably the most important step of planning a security audit. Since we usually can’t test everything, we have to focus our efforts on whatever it is that we are most concerned about. An audit could be driven by regulatory or compliance requirements, by a significant change to the architecture of the information system, or by new developments in the threat facing the organization. There are many other possible scenarios, but these examples are illustrative of the vastly different objectives for our assessments.
Once our goals are established, we need to define the scope of the assessment:
• Which subnets and systems are we going to test?
• Are we going to look at user artifacts, such as passwords, files, and log entries, or at user behaviors, such as their response to social engineering attempts?
• Which information will we assess for confidentiality, integrity, and availability?
• What are the privacy implications of our audit?
• How will we evaluate our processes, and to what extent?
If our goals are clearly laid out, answering these questions should be a lot easier.
The scope of the audit should be determined in coordination with business unit managers. All too often security professionals focus on IT and forget about the business cases. In fact, business managers should be included early in the audit planning process and should remain engaged throughout the event. This not only helps bridge the gap between the two camps but also helps identify potential areas of risk to the organization brought on by the audit itself. Just imagine what would happen if your assessment interfered with a critical but nonobvious business process and ended up costing the organization a huge amount of money. (We call that an RGE, or résumé-generating event.)
Having decided who will actually conduct our audit, we are now in a position to plan the event. The plan is important for a variety of reasons:
• We must ensure that we are able to address whatever risks we may be introducing into the business processes. Without a plan, these risks are unknown and not easily mitigated.
• Documenting the plan ensures that we meet each of our audit goals. Audit teams sometimes attempt to follow their own scripted plan, which may or may not address all of the organization’s goals for a specific audit.
• Documenting the plan will help us remember the items that were not in the scope of the assessment. Recall that we already acknowledged that we can’t possibly test everything, so this specifies the things we did not test.
• The plan ensures that the audit process is repeatable. Like any good science experiment, we should be able to reproduce the results by repeating the process. This is particularly important because we may encounter unexpected results worth further investigation.
Having developed a detailed plan for the audit, we are finally in a position to get to the fun stuff. No matter how much time and effort we put into planning, inevitably we will find tasks we have to add, delete, change, or modify. Though we clearly want to minimize the number of these changes, they are really a part of the process that we just have to accept. The catch is that we must consciously decide to accept them, and then we absolutely must document them.
NOTE
In certain cases, such as regulatory compliance, the parameters of the audit may be dictated and performed by an external team of auditors. This means that the role of the organization is mostly limited to preparing for the audit by ensuring all required resources are available to the audit team.
The documentation we start during the planning process must continue all the way through to the results. In all but the most trivial assessments, we are likely to generate reams of data and information. This information is invaluable in that it captures a snapshot in time of our security posture. If nothing else, it serves to benchmark the effectiveness of our controls so that we can compare audits and determine trends. Typically, however, this detailed documentation allows the security staff to drill into unexpected or unexplainable results and do some root cause analysis. If you capture all the information, it will be easier to produce reports for target audiences without concern that you may have deleted (or failed to document) any important data points.
Ultimately, the desired end state of any audit is to effectively communicate the results to the target audiences. The manner in which we communicate results to executives is very different from the manner in which we communicate results to the IT team members. This gets back to the point made earlier about capturing and documenting both the plan and the details and products of its execution. It is always easier to distill information from a large data set than to justify a conclusion when the facts live only in our brains. Many a security audit has been ultimately unsuccessful because the team has not been able to communicate effectively with the key stakeholders.
Internal Audits
In a perfect world, every organization would have an internal team capable of performing whatever audits were needed. Alas, we live in a far-from-perfect world in which even some of the best-resourced organizations lack this capability. But if your organization does have such a team on hand, its ability to implement continuous improvement of your organization’s security posture offers some tremendous advantages.
One of the benefits of using your own personnel to do an audit is that they are familiar with the inner workings of your organization. This familiarity allows them to get right to work and not have to spend too much time getting oriented to the cyber terrain. Some may say that this insider knowledge gives them an unrealistic advantage because few adversaries could know as much about the systems as those who operate and defend them. It is probably more accurate to state that advanced adversaries can often approach the level of knowledge about an organization that an internal audit team would have. In any case, if the purpose of the audit is to leave no stone unturned and test the weakest, most obscure parts of an information system, then an internal team will likely get closer to that goal than any other.
Using internal assets also allows the organization to be more agile in its assessment efforts. Since the team is always available, all that the leadership would need to do is to reprioritize their tests to adapt to changing needs. For example, suppose a business unit is scheduled to be audited yearly, but the latest assessment’s results from a month ago were abysmal and represent increased risk to the organization. The security management could easily reschedule other tests to conduct a follow-up audit three months later. This agility comes at no additional cost to the organization, which typically would not be true if engaging a third-party team.
The downsides of using an internal team include the fact that they likely have limited exposure to other approaches to both securing and exploiting information systems. Unless the team has some recent hires with prior experience, the team will probably have a lot of depth in the techniques they know, but not a lot of breadth, since they will have developed mostly the skills needed to test only their own organization.
A less obvious disadvantage of using internal auditors is the potential for conflicts of interest to exist. If the auditors believe that their bosses or coworkers may be adversely affected by a negative report or even by the documented presence of flaws, the auditors may be reluctant to accurately report their findings. The culture of the organization is probably the most influential factor in this potential conflict. If the climate is one of openness and trust, then the auditors are less likely to perceive any risk to their higher-ups or coworkers regardless of their findings. Conversely, in very rigid bureaucratic organizations with low tolerance for failures, the potential for conflicts of interest will likely be higher.
Another aspect of the conflict-of-interest issue is that the team members or their bosses may have an agenda to pursue with the audit. If they are intent on securing better funding, they may be tempted to overstate or even fabricate security flaws. Similarly, if they believe that another department needs to be taught a lesson (perhaps to get them to improve their willingness to “play nice” with the security team), the results could deliberately or subconsciously be less than objective. Politics and team dynamics clearly should be considered when deciding whether to use internal audit teams.
External Audits
When organizations come together to work in an integrated manner, special care must be taken to ensure that each party promises to provide the necessary level of protection, liability, and responsibility, which should be clearly defined in the contracts each party signs. Auditing and testing should be performed to ensure that each party is indeed holding up its side of the bargain. An external audit (sometimes called a second-party audit) is one conducted by (or on behalf of) a business partner.
External audits are tied to contracts. In today’s business and threat environments, it is becoming commonplace for contracts to have security provisions. For example, a contract for disposing of computers may require the service provider to run background checks on all its employees, to store the computers in secure places until they are wiped, to overwrite all storage devices with alternating 1’s and 0’s at least three times, and to agree to being audited for any or all of these terms. Once the contract is in place, the client organization could demand access to people, places, and information to verify that the security provisions are being met by the contractor.
To understand why external audits are important, you don’t have to go any further than the Target data breach of 2013. That incident was possible because Target was doing business with Fazio Mechanical Services, who provided Target with heating, ventilation, and air conditioning (HVAC) services. The security postures of both organizations were vastly different, so the attackers targeted the weaker link: Fazio. Admittedly, Target made some costly mistakes that got it into that mess, but had its IT security personnel understood the information system security management practices of its partner, they may have been able to avoid the breach. How could they have learned of Fazio’s weaknesses? By auditing them.
Third-Party Audits
Sometimes, you have no choice but to bring in a third party to audit your information systems’ security. This is most often the case when you need to demonstrate compliance with some government regulation or industry standard. Even if you do have a choice, bringing in external auditors has advantages over using an internal team. For starters, the external auditors probably have seen and tested many information systems in different organizations. This means that they will almost certainly bring to your organization knowledge that it wouldn’t otherwise be able to acquire. Even if you have some internal auditors with prior experience, they are unlikely to approach the breadth of experience that contractors who regularly test a variety of organizations will bring to the table.
Another advantage of third-party auditors is that they are unaware of the internal dynamics and politics of the target organization. This means that they have no favorites or agendas other than the challenge of finding flaws. This objectivity may give them an edge in testing, particularly if the alternative would’ve been to use internal personnel who played a role in implementing the controls in the first place and thus may overlook or subconsciously impede the search for defects in those controls.
The obvious disadvantage of hiring an external team is cost. Price tags in the tens of thousands of dollars are not uncommon, even on the low end of the scale. If nothing else, this probably means that you won’t be able to use external auditors frequently (if at all). Even at the high end of the pay scale, it is not uncommon to find testers who rely almost exclusively on high-end scanners that do all the work (and thinking) for them. It is truly unfortunate when an organization spends a significant amount of money only to find out the tester simply plugs his laptop into the network, runs a scanner, and prints a report.
Even if you find an affordable and competent team to test your information systems, you still have to deal with the added resources required to orient them to the organization and supervise their work. Even with signed nondisclosure agreements (NDAs), most companies don’t give free rein to their external auditors without some level of supervision. In addition, the lack of knowledge of the inner workings of the organization typically translates into the auditors taking a longer time to get oriented and be able to perform the test.
NOTE
Signing a nondisclosure agreement is almost always a prerequisite before a third-party team is permitted to audit an organization’s systems.
While there is no clear winner between using internal auditors and third-party auditors, sometimes the latter is the only choice where regulatory requirements such as the Sarbanes-Oxley Act force an organization to outsource the test. These are called compliance audits and must be performed by external parties.
EXAM TIP
You will most likely see questions on external audits in the context of supply-chain risk management. Third-party audits will show up in questions dealing with compliance issues.
Chapter Review
As security professionals, evaluating the security posture of our organizations is an iterative and continuous process. This chapter discussed a variety of techniques that are helpful in determining how well you are mitigating risks with your technical and administrative controls. Whether you are doing your own audits or validating the audit plans provided by a third party, you should now know what to look for and how to evaluate proposals. Along the way, this chapter also covered some specific threats and opportunities that should play a role in your assessment plan. It is important to keep in mind that everything covered in this chapter is grounded in the risk management discussed in Chapter 2. If you do not keep in mind the specific threats and risks with which your organization is concerned, then it is very difficult to properly address them.
Quick Review
• An audit is a systematic assessment of the security controls of an information system.
• Setting a clear set of goals is probably the most important step of planning a security audit.
• A vulnerability test is an examination of a system for the purpose of identifying, defining, and ranking its vulnerabilities.
• Penetration testing is the process of simulating attacks on a network and its systems at the request of the owner.
• Red teaming is the practice of emulating a specific threat actor (or type of threat actor) with a particular set of objectives.
• Black box testing treats the system being tested as completely opaque.
• White box testing affords the auditor complete knowledge of the inner workings of the system even before the first scan is performed.
• Gray box testing gives the auditor some, but not all, information about the internal workings of the system.
• A blind test is one in which the assessors only have publicly available data to work with and the network security staff is aware that the testing will occur.
• A double-blind test (stealth assessment) is a blind test in which the network security staff is not notified that testing will occur.
• Breach and attack simulations (BAS) are automated systems that launch simulated attacks against a target environment and then generate reports on their findings.
• A log review is the examination of system log files to detect security events or to verify the effectiveness of security controls.
• Synthetic transactions are scripted events that mimic the behaviors of real users and allow security professionals to systematically test the performance of critical services.
• A code review is a systematic examination of the instructions that comprise a piece of software, performed by someone other than the author of that code.
• A misuse case is a use case that includes threat actors and the tasks they want to perform on the system.
• Test coverage is a measure of how much of a system is examined by a specific test (or group of tests).
• Interface testing is the systematic evaluation of a given set of exchange points for data between systems and/or users.
• Compliance checks are point-in-time verifications that specific security controls are implemented and performing as expected.
• Internal audits benefit from the auditors’ familiarity with the systems, but may be hindered by a lack of exposure to how others attack and defend systems.
• External audits happen when organizations have a contract in place that includes security provisions. The contracting party can demand to audit the contractor to ensure those provisions are being met.
• Third-party audits typically bring a much broader background of experience that can provide fresh insights, but can be expensive.
Questions
Please remember that these questions are formatted and asked in a certain way for a reason. Keep in mind that the CISSP exam is asking questions at a conceptual level. Questions may not always have the perfect answer, and the candidate is advised against always looking for the perfect answer. Instead, the candidate should look for the best answer in the list.
1. Internal audits are the preferred approach when which of the following is true?
A. The organization lacks the organic expertise to conduct them.
B. Regulatory requirements dictate the use of a third-party auditor.
C. The budget for security testing is limited or nonexistent.
D. There is concern over the spillage of proprietary or confidential information.
2. All of the following are steps in the security audit process except
A. Document the results.
B. Convene a management review.
C. Involve the right business unit leaders.
D. Determine the scope.
3. Which of the following is an advantage of using third-party auditors?
A. They may have knowledge that an organization wouldn’t otherwise be able to leverage.
B. Their cost.
C. The requirement for NDAs and supervision.
D. Their use of automated scanners and reports.
4. Choose the term that describes an audit performed to demonstrate that an organization is complying with its contractual obligations to another organization.
A. Internal audit
B. Third-party audit
C. External audit
D. Compliance audit
5. Which of the following is true of a vulnerability assessment?
A. The aim is to identify as many vulnerabilities as possible.
B. It is not concerned with the effects of the assessment on other systems.
C. It is a predictive test aimed at assessing the future performance of a system.
D. Ideally it is fully automated, with no human involvement.
6. An assessment whose goal is to assess the susceptibility of an organization to social engineering attacks is best classified as
A. Physical testing
B. Personnel testing
C. Vulnerability testing
D. Network testing
7. Which of the following is an assessment that affords the auditor detailed knowledge of the system’s architecture before conducting the test?
A. White box testing
B. Gray box testing
C. Black box testing
D. Zero knowledge testing
8. Vulnerability scans normally involve all the following except
A. The identification of active hosts on the network
B. The identification of malware on all hosts
C. The identification of misconfigured settings
D. The identification of operating systems
9. Security event logs can best be protected from tampering by which of the following?
A. Encrypting the contents using asymmetric key encryption
B. Ensuring every user has administrative rights on their own workstations
C. Using remote logging over simplex communications media
D. Storing the event logs on DVD-RW
10. Synthetic transactions are best described as
A. Real user monitoring (RUM)
B. Transactions that fall outside the normal purpose of a system
C. Transactions that are synthesized from multiple users’ interactions with the system
D. A way to test the behavior and performance of critical services
11. Suppose you want to study the actions an adversary may attempt against your system and test the effectiveness of the controls you have emplaced to mitigate the associated risks. Which of the following approaches would best allow you to accomplish this goal?
A. Misuse case testing
B. Use case testing
C. Real user monitoring (RUM)
D. Fuzzing
12. Code reviews include all of the following except
A. Ensuring the code conforms to applicable coding standards
B. Discussing bugs, design issues, and anything else that comes up about the code
C. Agreeing on a “disposition” for the code
D. Fuzzing the code
13. Interface testing could involve which of the following?
A. The application programming interface (API)
B. The graphical user interface (GUI)
C. Both of the above
D. None of the above
Answers
1. C. Third-party auditors are almost always fairly expensive, so if the organization’s budget does not support their use, it may be necessary to use internal assets to conduct the audit.
2. B. The management review is not a part of any audit. Instead, this review typically uses the results of one or more audits in order to make strategic decisions.
3. A. Because they perform audits in multiple other organizations, and since their knowledge is constantly refreshed, third-party auditors almost always have knowledge and insights that would otherwise be unavailable to the organization.
4. C. External audits are used to ensure that contractors are meeting their contractual obligations, so that is the best answer. A compliance audit would apply to regulatory or industry standards and would almost certainly be a third-party audit, which makes answer D a poor fit in most cases.
5. A. One of the principal goals of a vulnerability assessment is to identify as many security flaws as possible within a given system, while being careful not to disrupt other systems.
6. B. Social engineering is focused on people, so personnel testing is the best answer.
7. A. White box testing gives the tester detailed information about the internal workings of the system under study. Gray box testing provides some information, so it is not the best answer to this question.
8. B. Vulnerability testing does not normally include scanning hosts for malware. Instead, it focuses on finding flaws that malware could potentially exploit.
9. C. Using a remote logging host raises the bar for attackers because if they are able to compromise one host, they would have to compromise the remote logger in order to tamper with the logs. The use of a simplex channel further hinders the attackers.
10. D. Synthetic transactions are those that simulate the behavior of real users, but are not the result of real user interactions with the system. They allow an organization to ensure that services are behaving properly without having to rely on user complaints to detect problems.
11. A. Misuse case testing allows us to document both an adversary’s desired actions on a system and the controls that are meant to thwart that adversary. It is similar to developing use cases, but with a malicious user’s actions in mind instead of those of legitimate users.
12. D. Fuzzing is a technique for detecting flaws in the code by bombarding it with massive amounts of random data. This is not part of a code review, which focuses on analyzing the source code, not its response to random data.
13. C. Interface testing covers the exchange points within different components of the system. The API is the exchange point between the system and the libraries it leverages, while the GUI is the exchange point between the system and the users. Testing either of these would constitute an interface test.