
CHAPTER 23
A Deeper Dive into Artificial Intelligence
The story of artificial intelligence began in 1956. Researchers and academics set out to achieve the impossible for the betterment of humankind. Over the years, artificial intelligence has been met with optimism, skepticism, falling in and out of the public eye, and in the past decade has risen to join the most prominent topics of modern discourse.
For some, it poses the greatest threat to humankind of the twenty‐first century. For others, it holds the promise of improving the human experience and addressing some, if not many, of the world's biggest challenges.
These points of view could not be more disparate, and yet they represent a small glimpse into the wide variety of discussions taking place in the media, boardrooms, academic halls, at whiteboards, and across industries and social classes about artificial intelligence. Job loss. Job creation. Economic potential. Reshoring. Universal basic income. The end of humanity. Lights‐out factories. Ethics. Responsibility. Bias. Augmenting human potential.
At its core, it is a story of humans and machines. It begins with the question of what it means to be human, and as machines have evolved and their prevalence in modern life has increased, artificial intelligence has become the symbolic figurehead of the machine element in this story of humans and machines.
The Components of Artificial Intelligence
There is a significant degree of semantic satiation facing artificial intelligence and interchangeable references to analytics, statistics, data science, machine learning, reinforcement learning, and autonomous artificial intelligence (to name a few). There are many great resources and technology leaders endeavoring to provide clarity on this topic. If you are a technologist looking for the definitive guide to the technical nuances of this field and its related disciplines, my colleagues and peers in the technology industry have published books, articles, and research papers that speak to that technological, domain‐specific altitude. The goal of this chapter is to describe each discipline within and closely related to the field of artificial intelligence at the accessible‐with‐guidance altitude for business and industry leaders. By the end of this chapter, you as a leader should be able to decipher the difference between each. Figure 23.1 provides a visual reference.
Analytics
Analytics is the systematic computational analysis of data. It is used for the discovery, interpretation, and communication of meaningful patterns in data. There are four categories of analytics: descriptive, diagnostic, predictive, and prescriptive.
Descriptive Analytics: What does my data tell me has happened/is happening?
Much like it sounds, descriptive analytics provides a description of the data, often within a specific period of time, or broken down by category. This type of analytics is the most basic, as it only requires the aggregation, sanitization, and interpretation of data as text or visualization. An example would be a visualization of sales revenue by product in a given month.
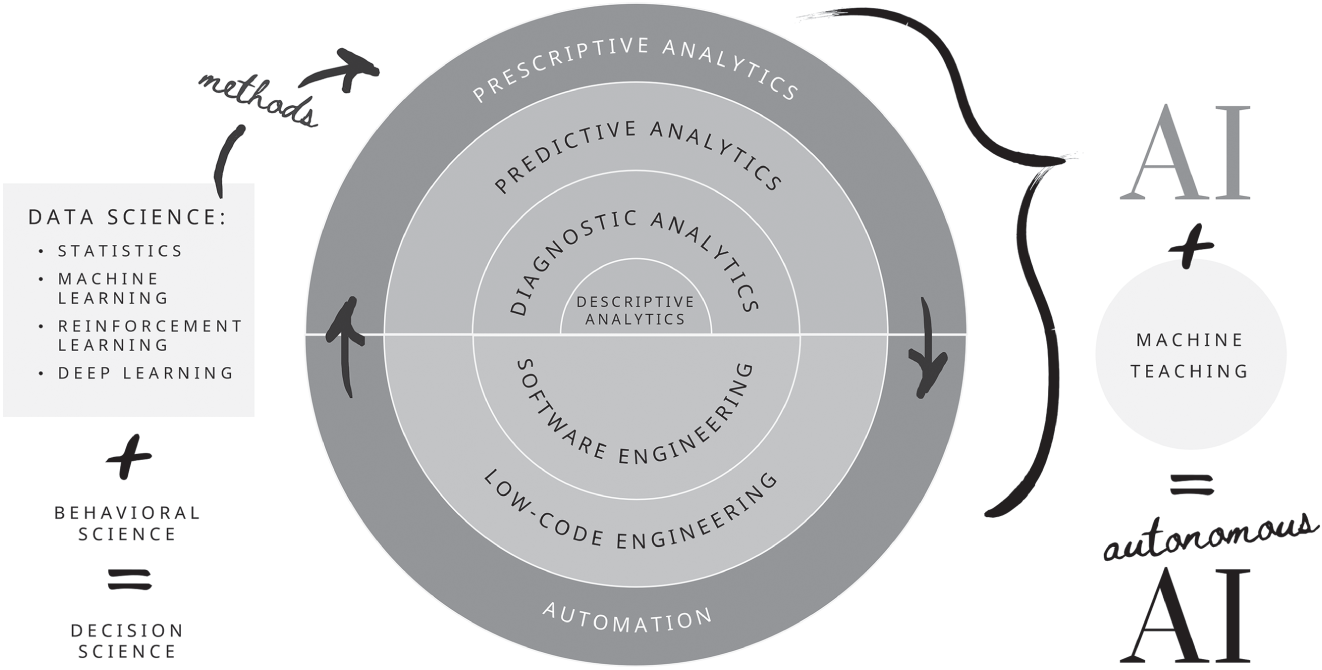
Figure 23.1 Components of Artificial Intelligence
Diagnostic Analytics: Why does my data say that it happened/is happening?
Diagnostic analytics combines several points of analysis together with synthesis, examining data to generate and test hypotheses to illuminate why a particular event occurred or is occurring. Why are sales down? Without diagnostic analytics, an assumption may be made that sales are down because the sales teams are not performing, but a dashboard including diagnostic analytics would be able to introduce the hypothesis that, for instance, customers are not converting from the trial plan to the premium plan because of the high number of incidents and latencies they are experiencing. Synthesis in this context requires an understanding of the domain, which therefore requires the domain expert. There are many organizations that have found that balance within diagnostic analytics through persistent trial and error, but it should be noted that the formal definitions of diagnostic analytics from credible and widely acknowledged resources do not include any references to synthesis, and most explanations of the process only mention the need for technical resources.
Predictive Analytics: What does my data tell me is likely to happen in the future?
Predictive analytics provides predictions of what may happen in the future. For example, based on a high number of incidents and latencies, leading to a reduction in usage from high‐paying customers, one can predict the likelihood that those customers will churn. This analytic method is only capable of predicting what may happen in the future if the context of the future is the same as the context from which the data was sampled. An example of this can be observed in the case of predicting churn based on the number of incidents and latencies and decreases in usage; the model does not account for the entrant of a new competitor or an economic downturn.
Prescriptive Analytics: What do my data and business logic tell me I should do next?
Prescriptive analytics prescribe actions based on predictive analytics paired with business logic. To continue in the sales analogy, an example of prescriptive analytics would be assignments in a customer relationship management (CRM) system for salespeople to proactively reach out to customers who, based on a predictive analysis, have a high likelihood to churn. A step further would be a prescriptive recommendation that salespeople offer those customers temporary pricing discounts due to the latencies they have experienced. Without prescriptive analytics, this analysis would have to be done by a consulting firm or an internal team over the course of several weeks or months, and often as a point‐in‐time exercise. Prescriptive analytics changes this paradigm to predictive analytics that run constantly in the background, searching for patterns when sales numbers start to dip or as soon as a customer begins churning, providing recommendations to business, industry, and technology leaders as soon as they recognize meaningful patterns.
These categories of analytics form an ecosystem that depends on each other's answers to continue to grow and add value. If leaders learn that customers are likely to churn, but they are not provided an explanation as to why or what can be done about it, they will not be able to take informed action to resolve the situation.
Statistics, machine learning, deep learning, reinforcement learning, and other branches within the field of artificial intelligence are methods by which these four categories of analytics can be performed. Machine learning, for example, is often conflated with predictive analytics, but one of the applications of machine learning, classification, can be used to separate customers into categories, thus answering a descriptive analytics question: What are the logical categories of this business's customers based on x, y, and z parameters?
Statistics
Statistics, as defined by the Merriam‐Webster dictionary, is “a branch of mathematics dealing with the collection, analysis, interpretation, and presentation of masses of numerical data.”1 At first glance, this is similar to the definition of analytics. The key distinction lies in the process, as indicated in the first portion of the definitions of analytics and statistics. Analytics is “the systematic computational analysis of data” and statistics is “a branch of mathematics dealing with […] data.”
In other words, statistics is a method by which analytics can be performed. A data analyst who is not a statistician can identify meaningful patterns in data, such as a decline in profitability, and can pose hypotheses as to the reason, but may not be able to draw definitive conclusions, depending on the complexity of the underlying data. In partnership with a statistician, however, who can test those hypotheses using statistical (i.e., mathematical) models, conclusions can be drawn with enough confidence to inform decisions.
Statisticians who have the skills of analysis and synthesis and can speak the language of the business and/or industry are elite team members, as they can pose meaningful questions, focus their analyses on business objectives, and communicate at the universal or accessible‐with‐guidance altitude.
Statisticians who do not have the skill of analysis, on the other hand, tend to have an orientation toward theory and mathematical methods that can present challenges in interfacing directly with business and industry leaders, as they are less likely to be able to raise the altitude of discussions above the domain‐specific language of mathematics. When organizations identify these kinds of team members or candidates, they can pair them with data analysts to handle the hypotheses, give feedback to ensure that the output of analyses will meaningfully inform decisions, and create effective communications translating the output of those analyses into the accessible‐with‐guidance altitude.
Data Science
Data science was introduced as a new concept by Chikio Hayashi in 1998, defined as “not only a synthetic concept to unify statistics, data analysis and their related methods but also [comprising] its results. It includes three phases, design for data, collection of data, and analysis on data.”2 Although the discipline and its subfields—analytics, statistics, and machine learning—have evolved considerably since 1998, its focus has remained the same: to derive value out of data.
According to a Gartner research paper, as of 2018, there were only 10,000 scientists worldwide. This figure is staggeringly low, especially when contrasted with the 400 million businesses worldwide, not including the number of public organizations or research and academic institutions.3 Based on the number of businesses alone, if each could only hire a single data scientist, that means that .000025% of businesses could employ a data scientist.
Organizations around the world have been scrambling to solve this problem. Bootcamps have sprung up, offering to teach data science and assist in landing an entry‐level data science job in a number of months. General Electric has addressed this challenge by reengineering the Six Sigma model to fit the discipline of data science, where a “black belt” data scientist can train a number of green belts (typically self‐elected from a group of process experts) to drive cost out of operations. The team's success is measured against a targeted cost reduction number.
Cloud providers are attempting to help address this problem by creating increasingly simplified tools to empower elite data scientists to be more effective and junior data scientists to be supported by technological guardrails as they develop their skills and expertise. They are also bundling common data science scenarios, such as object detection within an image, into off‐the‐shelf services that can be leveraged by software developers.
In addition, new capabilities are being developed that focus on democratizing data science tasks to enable “data science–adjacent” experts in engineering, typically with advanced degrees, to incorporate data science into their work by abstracting the algorithms from the view of the engineer. Machine teaching (discussed later in this chapter) is a new methodology with this focus.
For the purpose of defining data scientists within the list of fields and disciplines in this chapter, a data scientist is an analyst, statistician, and machine learning practitioner. Data scientists are generally capable of building all of the components of artificial intelligence except the automation of the prescribed actions. At this point of the process, data scientists partner with engineers to pair data science with automation to implement artificial intelligence.
If a retail leader, for example, wanted to test different storefront displays and sales advertisements across geographies, a data science team could build the analytical models, data pipelines, dashboards, and prescriptive models to analyze outcomes of these tests and recommend changes to individual stores, analyzing the subsequent results, and further refining those recommendations in a continuing loop of testing and optimization. Partnership with software engineering would come into play when confidence in the prescriptive recommendations reached a point that the business leaders wanted to implement automated prescriptive directives to store leaders—in other words, an artificially intelligent storefront advertising optimization system. Software engineers would then build automation around the prescriptive analytics by devising an alert system through whichever channels would be most efficient for the business. This could take the shape of automated emails, alerts within an application that store leaders were already using, or the creation of a new application to house this specific function.
Decision Science
Decision science combines data science with the behavioral sciences, such as economics, management, neuroscience, and psychology. It takes data science a step further through the orientation of not only optimizing a recommendation that would inform a decision, but also including the science of decision‐making within its scope. Extending the storefront example above to include decision science would expand the scope to include analyses such as the science of decision‐making of consumers, the economics of the local area, factoring the managerial effect on employees of rotating storefront displays into the cost/benefit analysis, and psychological impacts on customers of various colors in the storefront. This is a relatively new field with exciting implications for combining the richness of the behavioral sciences, previously relegated solely to human expertise, together with data science to create more meaningful and ethical analyses and outcomes.
Decision science is a practitioner's discipline shifted away from a purely mechanistic worldview to a social systems worldview.
Machine Learning
Machine learning is a data science technique that allows computers to use existing data to forecast future behaviors, outcomes, and trends. By using machine learning, computers can learn without being explicitly programmed. Machine learning engineers explore datasets with algorithmic approaches such as deep learning, neural networks, and random forests. A key distinction between a machine learning engineer and a statistician is that the machine learning engineer relies on the algorithm to learn the pattern (hence, machine learning) within the data and to generate its own model for replicating that learning. A statistician, in contrast, designs a model, tests the model to see if it matches the desired outcome, redesigns the model, and so on. In the context of artificial intelligence, the model at the center of the prediction that informs the prescribed decision or action could be either a human‐written statistical model or a machine‐learned algorithmic model.
As children learn, there are some things they are explicitly taught and some they infer. For example, in the United States, children are often taught the phrase “Stop, Drop, and Roll” in case their clothing ever catches fire. This is in large part because they cannot be afforded the opportunity to test the scenario multiple times to see which approach is most effective without suffering bodily harm. This could be likened to the statistical approach, where a machine is provided a “recipe” for how to properly analyze a dataset to reach the desired outcome. Unlike teaching children about fire safety, the skill of climbing a tree is not explicitly taught or prescribed. Children take iterative approaches, forming their own neural pathways and muscle memories, and developing their own skills. This is similar to the machine learning approach, where machines understand the desired outcome and endeavor to reach that outcome, iterating over existing data or generating synthetic data (more on that in the following section) in order to accomplish the prescribed goal.
Generative Artificial Intelligence (Generative AI)
Generative AI is a subdiscipline of machine learning that identifies patterns between inputs and content, which it can then leverage to generate new content, such as images, text, audio files, or videos. Two of the most well‐known applications of generative artificial intelligence both launched across the global stage in 2022: DALL·E 2 and ChatGPT.
In the case of DALL·E 2, it has “learned the relationship between images and the text used to describe them.”4 It generates imagery through the use of a technique referred to as “diffusion.” This method involves the initial presentation of a random set of dots, which is progressively altered toward the intended image. More specifically, a diffusion model, inspired by nonequilibrium thermodynamics, adds random noise (or “dots”) to data and then reverses the diffusion process to construct the desired image from the noise. Although the analogy is not an exact match, this is analogous to a painter dousing their canvas with thousands of little dots, then being able to remove and add individual dots until they reached the desired image.
An important distinction in the discussion around DALL·E 2 and other generative AI models that generate images is that they are only able to replicate patterns based on existing imagery and artistic styles. When Salvador Dali painted his surrealist masterpiece, The Persistence of Memory, featuring a new imagining of melting clocks, he was expressing ideological principles based on a writer and poet's definition of surrealism through painting. Generative AI can create new imagery in the style of Salvador Dali or Caspar David Friedrich, but it does not invent new styles of painting or imagery based on ideological principles or personal expression. This remains a distinctly human trait.
ChatGPT is a Large Language Model (LLM) based on GPT that engages in written conversational dialogue and can appear surprisingly human. It was trained on a massive amount of data, at 175 billion parameters and 570 gigabytes of text.5 One of the aspects that sets ChatGPT apart from traditional LLMs is that it was also trained using human feedback (a technique called Reinforcement Learning with Human Feedback) so that the AI learned what humans expected when they asked a question. Training the LLM this way enabled the model to break away from the rut of predicting the next word.
The hype surrounding ChatGPT provides rich examples of the perceived value of technological breakthroughs, as well as the need to continuously clear the digital fog by separating truth from speculation, identifying logical fallacies, and discerning the credibility and trustworthiness of advisors. There will be another excellent opportunity for navigating digital fog with each new version of GPT or similar advancements from other organizations.
Reinforcement Learning
Reinforcement learning is among the most exciting developments of the past decade, and has paved the way for machines to learn without historical data. Imagine if leaders, after presenting their plan to the board, could hit restart and try again an infinite number of times until they perfected the outcome. This is reinforcement learning in layman's terms. A scenario is defined, along with positive and negative reinforcements for various outcomes, and the machine is set loose, exploring the space and starting over as soon as it finds a path that would determine a positive or negative reinforcement. After thousands, hundreds of thousands, or even millions of iterations, depending on the complexity of the scenario and the platform, the machine either indicates the degree of progress it has made and gives its programmer the option to stop, or has learned an optimal path to achieving the desired outcome consistently without explicit directions. An example of this is Mario. Imagine explicitly programming Mario to beat a single level. Go forward x steps, jump, now go forward, now duck, now jump forward y steps, and so on. Reinforcement learning replaces this with experimentation and often identifies paths that surprise humans. This is how AlphaGo was able to beat the reigning human champion in the game of Go, not by analyzing previous games, but by playing millions of games against itself. This technology can also be used to test net‐new scenarios to determine the best path forward.
An example of reinforcement learning paired with robotics is in learning a new task. The grasp‐and‐stack task is a common training and proving ground for new technologies. A robotic arm reaches out, grasps the block, lifts the block, positions it over a stack of other blocks, and places it gently down on top of the stack. The traditional engineering approach to this problem would require a significant investment of a human engineer's time, with precise directional calculations including factors such as velocity, arc, rotation, and stability. The reinforcement learning approach to the same problem is defining the state, or the physical properties of the robot, the block, and the stack, setting the goal, and determining the positive and negative reinforcements (the reward function). While the engineer attends to other tasks, the machine would methodically test various approaches to achieving its goal in a simulated environment. If it knocks the ball over in the virtual environment, that approach is logged as the wrong approach, and the simulation is reset. With the computational power of parallel computing, which allows for a task to share the processing power of many underlying systems, many hundreds of simulations can be run in parallel, updating the shared model at the end of each attempt.
Two key benefits of this technology are the safety afforded by testing in a simulated environment and the lack of dependence on historical data. A significant set of use cases that have not been addressable for previous machine learning methods can now be approached with reinforcement learning.
Autonomous Artificial Intelligence
Autonomous artificial intelligence is easy to conflate with artificial intelligence. The key distinction is found in its application. To return to the retail storefront application, the artificial intelligence solution is in a cycle of continuously learning from feedback loops across all stores, monitoring and tuning to improve outcomes. A central application is stored in the cloud that is then sharing and receiving information back and forth with hundreds of stores. The risk in this solution is extremely low, as an outage in the system would only result in a failure to generate additional recommendations for updating storefront advertising, with no damage to goods or risk to human safety.
Imagine this same approach for landing drones using artificial intelligence. Latency (or data transfer delays) would result in expensive and dangerous crashes. The same approach in manufacturing, if the machine chose to test a slightly different approach, could result in damaging millions of dollars of equipment and danger to humans.
Autonomous artificial intelligence has to be “complete” and its results validated through real‐world trials before being placed into production. This does not mean that it cannot continue to be optimized, but the approach to retraining, validation, and deployment are stage‐gated due to the higher stakes involved.
Machine Teaching: A New Paradigm
Machine teaching is a technique introduced in 2015 by Microsoft Research. While machine learning is focused on algorithms and improving the ability of machines to learn, machine teaching focuses on the opposite side of the paradigm, namely, the ability of humans to teach machines.
This discipline arose to address the problem mentioned previously in the data science section: there are not enough experts to build machine learning systems based on the current approaches and the requirement of machine learning expertise. The imbalance of the demand for machine learning systems and the ability for organizations to build them is a leading contributor to the high percentage (87%) of data science projects that never make it into production.
Machine teaching provides a methodology for meeting the growing demand for machine learning systems not only by increasing the ability of machines to learn, but by significantly increasing the number of individuals who can teach machines by making the process of teaching machines accessible.6,7
There are 10,000 times the number of domain experts in the world as data scientists. Machine teaching creates the ability for these experts to teach machines with less reliance on data scientists.
There will likely be several approaches to implementing machine teaching. Current applications start with human expertise, defining curricula as if a human were going to teach another human. Simulations are created based on a dataset or a physics‐based representation of the machine, environment, or process. Reinforcement learning references the curriculum instead of blindly searching and relying solely on positive or negative reinforcement.
In the previous example of drones, this approach has been used to teach machines using the expertise of pilots. In the example of grasp‐and‐stack, this approach enabled the machine to learn the task 45 times faster than reinforcement learning without machine teaching. PepsiCo has used machine teaching to teach humans how expert operators make the perfect Cheeto. The system leveraged reinforcement learning with the addition of the curricula set by human experts, and has been tested and certified as an expert‐level operator.
Automation versus Artificial Intelligence
Many companies have implemented decision tree–based automation. Call centers, automated checkout machines at grocery stores, robots that grasp and stack items in factories, motion‐controlled doors, and ATM machines are all examples of automation, but not artificial intelligence.
Decision tree–based automation is a list of if‐then rules. If the customer presses 1, that input directs the next step, and so on. This is “third‐industrial‐revolution‐level” automation, and it is not artificial intelligence. Artificial intelligence, in this example, still references rules and decision trees. The key differences in the artificial intelligence example are machine learning for voice‐to‐text translation (i.e., the input is enabled by machine learning), machine learning to predict customer lifetime value to determine whether to offer a discount, and the machine having the authority to offer a discount based on the result of this analysis.
There are several definitions of artificial intelligence. The Merriam‐Webster dictionary defines artificial intelligence as “a branch of computer science dealing with the simulation of intelligent behavior in computers” or “the capability of a machine to imitate intelligent human behavior.”8 Microsoft's Cloud Computing dictionary defines it as “the capability of a computer system to mimic human‐like cognitive functions such as learning and problem‐solving.”9 Google describes it as “a field of science concerned with building computers and machines that can reason, learn, and act in such a way that would normally require human intelligence or that involves data whose scale exceeds what humans can analyze.10
Automation, on the other hand, is defined by the Merriam‐Webster dictionary as “the technique of making an apparatus, a process, or a system operate automatically.”11
Automation without artificial intelligence is a script composed of decision‐trees and corresponding commands programmed by a human. When motion is detected, turn on the floodlights. When I say this command to my digital assistant, turn off all the lights in the house, lock all the doors, and start playing my bedtime playlist.
Artificial intelligence, on the other hand, cannot exist without automation. In the definitions above, you see the words imitate, mimic, and act. Artificial intelligence, broadly speaking, intakes data, applies a statistical model or machine learning algorithm to the data to predict and recommend actions, takes action, then learns from the results of those actions. In other words, artificial intelligence without automation is reduced to predictions and reports, and therefore not actual artificial intelligence.
Automation versus Autonomy
Automation and autonomy are often used interchangeably, but they are not the same. Automation, as a set of explicitly programmed instructions, is not possible if either the environment, the input, or any other variables are dynamic. This is when autonomy is required.
Imagine two machines side by side in 2010. One machine cuts stacks of paper into two pieces. The second machine bakes paper. Assuming the output of that baked paper is consistent, the machine that cuts the paper follows approximately four steps:
- Step 1: Pull the paper into the machine.
- Step 2: Make sure the paper is aligned to the prescribed parameters.
- Step 3: Cut the paper.
- Step 4: Feed the paper back out of the machine.
There are only a handful of variables in this process and in the paper‐cutting machine that could possibly change: the blade could become dull, the system that aligns the paper could get out of alignment, the feeders for pulling paper into the machine or pushing it out of the machine could malfunction. Each of these variables is extremely noticeable, and becomes a matter of repairing the machine, which is addressed by ongoing maintenance. The only real variable is the consistency of the paper fed into the machine.
Now let us examine the machine that makes the paper. This machine ingests raw materials, fits them into a mold, bakes that material into paper, and uses coloring to account for the variability of the pulp. In 2010, this machine and its process must be operated by a person, because there is not another method of managing the variability across all the factors required, such as the humidity taken together with the temperature of the pulp. The coloring of each batch contains so much variability that a human must review the variables, exercise judgment, and learn from the outcome; this is work that cannot be automated into a script. There are too many variables to be taken into account, not to mention unknowns.
Autonomy can be achieved in this scenario by creating a first principles (or “true‐to‐physics”) simulation of the machine and if each batch of pulp was examined first for coloring, then viscosity, then temperature, and so on, together with the humidity in the environment and the expertise of the operators who spent many years, if not decades, fine‐tuning their approach, which can be programmed as skills. Deep reinforcement learning can then experiment within the confines of the simulation, executing trial‐and‐error experiments safely away from the machine and the materials within a digital simulation. Framed by the programmed expertise, it can practice and learn the skill to the degree that it can be certified to run a machine autonomously. This has been demonstrated at PepsiCo, where an autonomous agent has been trained and subsequently certified to run an extruder that makes Cheetos, a process that could never be scripted/automated.12
How to Tell When Someone Is Lying about Artificial Intelligence
One of the greatest contemporary societal harms associated with the field of artificial intelligence is in the misrepresentation, through ignorance or malice, of knowledge, applications, or capabilities in artificial intelligence.
An advertisement of a product or technology, in today's market, all but falls flat without the mention of artificially intelligent features. For many discerning leaders, the din around the topic of artificial intelligence has resulted in a degree of skepticism. The economic potential trapped within this paradigm is astounding. Cutting through misinformation around artificial intelligence will naturally focus market investments in technologies that are creating powerful and impactful applications of artificial intelligence, and has the power to create more top‐ and bottom‐line revenue, leading to more jobs and greater job security.
The ability to tell whether someone is lying about artificial intelligence can be achieved through the application of two of the concepts introduced previously in this book in combination with one new method.
First, by applying the economic incentive test (Chapter 13), it is possible to gain an understanding of an advisor's credibility and trustworthiness.
The second method for determining a person's credibility in the field of artificial intelligence is through the three altitudes of inputs and outputs framework (Chapter 14). At whichever altitude the discussion lands, introduce the framework and ask the person to adjust the altitude up or down accordingly. An expert in artificial intelligence should be able to transition altitudes, although some may be more clunky in communicating at an altitude in which they are less versed. It should become clear in relatively short order whether the issue is in trying to explain something complex in common language (i.e., they are an expert technologist but not an expert communicator) or whether they are unable to explain anything beyond the verbiage or pitch they have memorized. It should be noted that the latter case reflects on the person communicating, and not necessarily the underlying technology. If the application or capability is intriguing enough to test for further depth, leaders should feel comfortable requesting a technical demonstration and invite technology leaders from within the organization to review the demonstration and probe to verify the technical depth of the team and the solution.
The third method is for leaders to listen closely and ask questions regardless of their knowledge of the answer. Leaders can then pose questions at each ambiguous or inconsistent juncture in the presentation, such as at the mention of “proprietary algorithms” or that a team of data scientists would be needed to implement a solution that has been presented as off‐the‐shelf. If the presenter is an expert, it presents a learning opportunity. If they are not, it saves the organization time and resources to identify this as early as possible.
Quiz
If you can correctly answer all 10 of the following questions, you will be ready to navigate many conversations around artificial intelligence, ask the right questions, make informed decisions, and start on the journey of building and leading data and decision science teams and machine teaching programs across your business. Additional industry and technology‐specific reading can be found at brianevergreen.com/booklist.
- What percentage of data science projects make it into production?
- 7%
- 42%
- 13%
- 21%
- Which type of analytics would best answer the following question: “Why are customers leaving us for our competitors?”
- Descriptive analytics
- Diagnostic analytics
- Predictive analytics
- Prescriptive analytics
- Which data science subfield involves the fine‐tuning of mathematical models to improve predictions?
- Statistics
- Machine learning
- Data mining
- Which of these examples would be automation, but not artificial intelligence?
- Recommending products online based on usage patterns and demographic information
- Notifying a customer service manager of an agitated customer based on sentiment analysis
- A driver's seat in a car recognizing a specific driver based on their weight and adjusting temperature, steering wheel, and seat orientation to that driver's preferences
- Logging into a phone using facial recognition
- Which of these examples would be an application of artificial intelligence?
- Alerting factory workers of a chemical spill based on camera feeds
- A chatbot that references a lookup table to answer frequently asked questions
- Auto‐filling online forms with name, email, and phone number
- Stopping a manufacturing line when a person gets too close to the machine
- In which use case would it be necessary to use autonomous artificial intelligence?
- Reviewing sensitive patient data to detect cancer
- Controlling the temperature in an office building
- Playing Mario
- Controlling a high‐speed machine in a factory
- Which of these examples extends beyond data science into decision science?
- Predicting the percentage increase in sales that will result from a proposed marketing campaign
- An artificially intelligent chatbot that uses natural language processing to translate technical documentation into customer‐friendly language
- Assessing customers for the degree of uncertainty they feel when they see a marketing ad and predicting the resultant impact to sales
- An application that writes poetry in 20 different languages
- Which use case would be the best for reinforcement learning?
- Breaking customers into categories
- Calibrating a thermal reactor
- Predicting customer churn
- Designing a new shoe based on preexisting shoe designs, sales, and physical and anatomical science
- Which subdiscipline of artificial intelligence is the most capable of translating human expertise to machines?
- Machine learning
- Statistics
- Decision science
- Machine teaching
- If a business has never analyzed any of their data and is just getting started, whom should they hire first?
- A data scientist
- A decision scientist
- A data analyst
- A machine learning engineer
Answers: C, B, A, C, A, D, C, B, D, C
Notes
- 1 “Statistics,” Merriam‐Webster Dictionary, https://www.merriam-webster.com/dictionary/statistics (accessed February 11, 2023).
- 2 C. Hayashi, C. (1998). “What Is Data Science? Fundamental Concepts and a Heuristic Example,” Data Science, Classification, and Related Methods: Studies in Classification, Data Analysis, and Knowledge Organization, edited by C. Hayashi, K. Yajima, H. H. Bock, N. Ohsumi, Y. Tanaka, and Y. Baba (Tokyo: Springer, 1998), https://doi.org/10.1007/978-4-431-65950-1_3.
- 3 Dun and Bradstreet, “D&B Data Cloud Surpasses 400M Businesses,” press release, November 5, 2020.
- 4 OpenAI, DALL·E 2, https://openai.com/dall-e-2 (accessed February 22, 2023).
- 5 A. Tamkin and D. Gangul, “How Large Language Models Will Transform Science, Society, and AI,” Stanford University, Human‐Centered Artificial Intelligence, February 5, 2021, https://hai.stanford.edu/news/how-large-language-models-will-transform-science-society-and-ai (accessed February 22, 2023).
- 6 J. Carter, “Going beyond Data Scientists: What Is Machine Teaching?,” Techradar, August 11, 2015, https://www.techradar.com/news/world-of-tech/going-beyond-data-scientists-what-is-machine-teaching-1301201/2 (accessed February 24, 2023).
- 7 Gudimella et al., “Deep Reinforcement Learning for Dexterous Manipulation with Concept Networks.”
- 8 “Artificial intelligence,” Merriam‐Webster Dictionary, https://www.merriam-webster.com/dictionary/artificial intelligence (accessed 24 February 24, 2023).
- 9 Microsoft Azure, “What Is Artificial Intelligence?,” https://azure.microsoft.com/en-in/resources/cloud-computing-dictionary/what-is-artificial-intelligence (accessed February 24, 2023).
- 10 Google Cloud, “What Is Artificial Intelligence (AI)?,” https://cloud.google.com/learn/what-is-artificial-intelligence (accessed February 26, 2023).
- 11 “Automation,” Merriam‐Webster Dictionary, https://www.merriam-webster.com/dictionary/automation (accessed February 26, 2023).
- 12 Leah Culler, “More Perfect Cheetos: How PepsiCo Is Using Microsoft's Project Bonsai to Raise the (Snack) Bar,” Microsoft Blogs, December 17, 2020, https://blogs.microsoft.com/ai-for-business/pepsico-perfect-cheetos/ (accessed February 26, 2023).