
CHAPTER 15
From Data‐Driven to Reason‐Driven
The precepts of management taught in business and engineering schools are that the only good decision is a data‐based decision.
—Roger Martin
Data‐driven is an adjective that means “determined by or dependent on the collection or analysis of data.”
The earliest documented collection of data in the workplace began in the late nineteenth century, when Frederick Taylor and his team of experts used stopwatches to collect information about the time it took laborers to achieve tasks—the first application of the scientific method in the context of business.
With the integration of machines in the workplace, the rise of computing power, and significant increases in methods of collecting, storing, and processing data, the term data‐driven has become a mantra in leadership publications, management theory, and within and across organizations.
Data‐driven decisions can begin with observed patterns in data trending in an undesired direction, or they can begin with a hypothesis, a need, or a question, but they always end with a set of numbers that justify a decision.
In other words, data‐driven is an inherently mechanistic paradigm.
While consulting a large telecommunications company, I observed a data‐driven decision that began with a need. The customer service organization needed to reduce costs.
What ensued was a data‐driven process, breaking down and analyzing the costs of the customer service department. It was determined that the most basic and important unit of variable cost in the department was increments of time an agent spent on the phone with a customer.
The next step was analyzing all the reasons customers called in and therefore required time spent on the phone with an agent. Once the categorized data came back, the data was first ranked by the number of calls, then by the average amount of time taken to resolve calls within each category. One of the most expensive categories was callers dialing in to make a late payment over the phone.
It was hypothesized that if the automated system that first answered the phone call checked the incoming number against an internal database and, if the customer was late on their payment, provided an automated option to make a late payment, it could reduce costs on the order of tens of millions of dollars.
The solution was implemented and the hypothesis was proven correct. The organization saved tens of millions of dollars a year from implementing a few lines of code.
Examples like this tend to excite managers and leaders, who turn to their team members and direct that all decisions henceforth will only be data‐driven decisions.
Aristotle's Conundrum
Aristotle was the first scientist. His invention of the scientific method has become the basis not only for the field of science, but also for organizational decision‐making.
If a decision‐maker is asked to invest in a given initiative, the ensuing questions will gather data about the proposed initiative, including measures such as the projected length of time, financial investment, and return on investment. The degree to which a data‐driven answer can be provided to these questions is commensurate with the amount of historical data exists or is available.
If a company wanted to launch a new marketing website, for example, the skill set required, the cost of hosting the website on a server, the projected costs if there is a surge in traffic to the website, the development time—each of these can be calculated because of the decades of previous web development initiatives and the ubiquity of web development skills and expertise.
In the arena of emerging technologies, autonomous or otherwise, the more groundbreaking and differentiating a technological application, the less there will be historical data against which to make predictions and therefore base decisions.
Within the context of maintenance mode or a reformational initiative, data‐driven analysis is well‐suited for identifying opportunities for incremental improvement of an existing system.
Where data‐driven analysis becomes not only less effective but counterproductive is in its rigorous application across all initiatives as a gate‐keeping mechanism, leading to a form of organizational empiricism.
Returning to the context of science, scientists cannot prove a hypothesis and a projected return on investment before they have received funding to execute the scientific method of defining the question, gathering information, forming hypotheses, conducting experiments to test hypotheses, analyzing the data, interpreting data, and publishing their results.
Translating that context into initiatives that involve the application of advanced technologies, such as artificial intelligence, technology initiatives tend to fall into four categories. The first category is when a given technology is unknown or new to the organization and is therefore treated as an experiment with little to no investment, visualized in Figure 15.1 as the “Technology Proving Ground (PoCs [Proofs of Concept]).” The second category is high‐value initiatives with low levels of complexity, meaning it has been become a well‐established application of the technology in the industry, such as web development. These kinds of investments fit neatly into return‐on‐investment calculations and organizational leaders are encouraged and incented to pursue them. The third category is high‐value initiatives that are highly complex. These initiatives are discouraged and disincentivized in most organizations for fear that they ultimately end up in the “Career Threatening” square of the quadrant, yielding low value after considerable investment.
In Figure 15.2, additional distinctions are added to the top two squares in the quadrant. In order to have high confidence that a technology initiative will add high value in a low amount of time, or, put another way, the only way to have a data‐driven justification for investment in a new technological application is if other organizations have already invested in and realized value from it, the differentiation of which decreases with each subsequent implementation in parallel with a decrease in complexity and uncertainty until it moves into the “Catching Up” square of the quadrant. Few leaders who manage their organizations in this manner would replace their organization’s tagline with “Chasing the wake of others,” but this is the reality of this approach, as the data on which to base data‐driven decisions is only formed in the wake of another organization leading the way into the unknown and generating that data.

Figure 15.1 Data‐Driven Justification Matrix
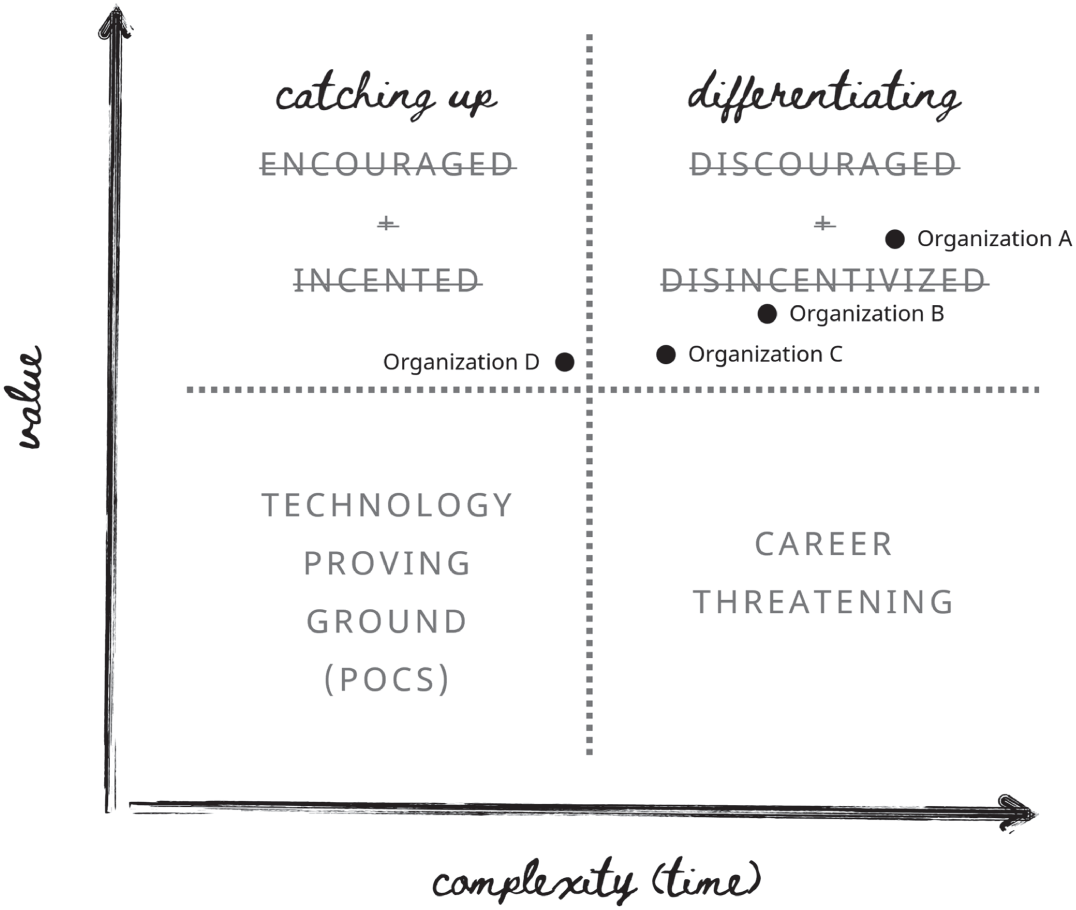
Figure 15.2 Data‐Driven Justification Matrix (Plotted)
Organizational Empiricism
Empiricism is a philosophical theory that all knowledge originates in experience. Organizations around the world, in the process of embedding data‐driven principles into every aspect of decision‐making, have developed a form of organizational empiricism, in which the only way a new product, service line, or initiative can be funded is if the future value can be empirically proven.
This is a logical fallacy, as you cannot have empirical proof of something that has yet to occur, and it is self‐preserving in the case that the initiative is not successful. Leaders can justify that they approved the initiative based on the empirically sound proposal, and the logical end is that the blame lay on the person or team who formed the proposal, either through failure to adequately gather and analyze the necessary data or failure in execution.
Leaders who only understand and are able to reward data‐driven decisions will curate their organizations to optimize their existing core value propositions. Data‐driven decision‐making is a foundational capability for any effective leader or manager, but it only allows for tuning and fixing that which already exists. In order for leaders and organizations to innovate and create, especially in the context of the unknowable, such as with new technologies, data‐driven decision‐making must be extended and augmented with reason.
Organizational Reasoning (from Data‐Driven to Reason‐Driven)
The antidote to the inherently mechanistic nature of being data‐driven can be found in the human discipline of reasoning. Reasoning is the drawing of inferences or conclusions through the use of reason, which is defined as the power of comprehending, inferring, or thinking, especially in orderly rational ways.1,2
Replacing organizational empiricism with organizational reasoning adds humans back into the equation of decision‐making. In the empirical paradigm, the person or team forming the proposal only serves in a data‐gathering and computational capacity. The decision is then based on the mathematics, and not the opinions or reasoning of the people who researched the options or created the proposal. In practice, many leaders will pause after reviewing the numbers and ask their team members what they think. If they agree with the team's logic, but do not feel that the logic is substantiated by data in the proposal, they may ask their teams to update the proposal in specific ways they feel they will be able to justify to their leadership, but the process itself does not support decisions that must be justified based on something other than data.
Organizational reasoning is a step in unwinding and replacing the mechanistic worldview with a social systems worldview, as it places human reasoning at the top of the hierarchy of decision‐making, on the foundation of data‐driven methodologies where appropriate. This begins with the knowledge that empiricism in the context of a new initiative is a logical fallacy, and pivots to rely on the logic and reasoning of an organization's experts, supported by data where available. This can be represented rigorously in a proposal, and there have already been steps in this direction, such as documented assumptions.
An example of the applicability of this approach would be in the context of a leadership directive to eliminate carbon emissions across the organization by 2030. Since the organization has not already eliminated carbon emissions, proposed solutions cannot be empirically proven. Furthermore, neither the cost of elimination of carbon emissions nor its ensuing impact to customer acquisition and retention can be accurately predicted.
A proposal in accordance with the process of organizational reasoning would begin with an examination of that which is known and can be represented based on empirical data, such as the current carbon emissions, broken down by scopes one, two, and three, and across categories such as lines of business, geographies, facilities, and travel. Other areas that can be represented empirically in this context are the benchmarking of the organization's emissions against other organizations within the industry vertical, the top methods being applied to reduce emissions within the industry with readouts of the results where available, governmental grant programs to assist with reducing carbon emissions, the state of science and research on developing further methods, and the current guidance and recommendations from research institutes, governmental agencies, advisors, partners, and academic leaders.
From the edges of what is known in the above, the person or team developing this plan can begin conducting reasoning experiments, working backwards from the future point in which the organization has no carbon emissions by the year 2030 to determine a set of theories that would need to be true to reach this future, and the successive theories and hypotheses that would also need to be true. Through this process, an organizational reasoning tree begins to take shape, based on logical inferences against which hypotheses can be shared, developed, and further explored to determine the degrees of confidence of different paths. This creates a foundation on which creative discussion can be bridged with rigor and documentation, and pivots the conversation from solely discussing the validity of conclusions to a higher order of human thought and experience, in the discussion of hypotheses. Forming strategies through this approach brings others into the entire thread of reasoning, which is much more difficult to do verbally than visually, and can be shared with stakeholders and team members to generate consensus, which will improve the likelihood of positive collaboration and follow‐through.
This is arguably a more scientific process than the established processes for data‐driven decision‐making as it includes the process of asking questions and generating theories.
The organizational reasoning tree, as demonstrated in Figure 15.3, developed through this process could then be updated as the organization engaged in initiatives to test and validate hypotheses, and new theories, hypotheses and branches of successive logical inferences could be added continuously (see Figure 15.4). This presents a foundation for a new bridge between the centuries of reasoning theory and methodological development and the practical environment of organizations, creating a dynamic representation of the organization's strategy, assumptions, knowns, and unknowns as the organization progresses boldly into a future driven by reason.

Figure 15.3 Organizational Reasoning Tree

Figure 15.4 Organizational Reasoning Tree (Plotted)
Notes
- 1 “Reasoning,” Merriam‐Webster Dictionary, https://www.merriam-webster.com/dictionary/reasoning (accessed January 10, 2023).
- 2 “Reason,” Merriam‐Webster Dictionary, https://www.merriam-webster.com/dictionary/reason (accessed January 10, 2023).